Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Building Real-Time Hybrid Architectures with Cluster Linking and Confluent Platform 7.0
Companies are increasingly moving to the cloud, undergoing a transition that is often a multi-year journey across incremental stages. Along this journey, many companies embrace hybrid cloud architectures, either temporarily or permanently, where some applications run on-premises and some run in the cloud. However, unifying data across on-premises and cloud environments is immensely challenging, as most legacy applications are not cloud-ready and have many dependencies and integrations with existing on-premises infrastructure.
With the release of Confluent Platform 7.0, we’re excited to announce the general availability of Cluster Linking to provide an easy-to-use, secure, and cost-effective data migration and geo-replication solution to seamlessly and reliably connect applications and data systems across your hybrid architectures. Cluster Linking delivers three primary benefits to move your data in real time to wherever it suits your business:
- Accelerate the enterprise journey to cloud by securely, reliably, and effortlessly creating a bridge between cloud and on-prem environments
- Enable self-service access to data in real time across the business with globally connected clusters that perfectly and reliably mirror data across all of your environments
- Reduce total cost of ownership (TCO) and operational burdens with seamless and cost-effective data geo-replication across Kafka clusters everywhere they reside
In this blog post, we’ll explore each of these benefits of Cluster Linking, along with additional enhancements in this release that accelerate the time to value for your streaming infrastructure with expanded API-driven operations, reduce infrastructure costs by offloading monitoring to a cloud-based solution, and expedite the development of stream processing applications. As with previous Confluent Platform releases, you can always find more details about the features in the release notes and in the video below.
Keep reading to get an overview of what’s included in Confluent Platform 7.0, or download Confluent Platform now if you’re ready to get started.
Download Confluent Platform 7.0
Accelerated journey to the cloud with hybrid architectures
Getting on-prem data into the cloud is challenging. Traditional approaches typically require manual data transfers or brittle point-to-point connections between environments, which creates architectural complexity, increases operational overhead, and delays time to value. Out-of-date processes like these hold organizations back from realizing the full benefits of cloud with rising costs, growing risks, and increasing security vulnerabilities.
Some organizations have turned to Kafka to aggregate data into clusters for each environment and then connect those clusters using geo-replication tools like MirrorMaker 2. This pattern has accelerated the move to the cloud for many enterprises who have leveraged Kafka’s scalability and rich connector and data integration ecosystem to break apart monolithic legacy platforms into microservices that can be individually migrated.
However, this approach is not without its own challenges. Operationally, a separate Connect cluster needs to be deployed and managed to run MirrorMaker 2 for every pair of Kafka clusters that are connected, which increases management overhead and complexity. And when applications migrate to the cloud, they need to deal with complex topic offset translations to ensure data consistency.
Cluster Linking solves these challenges with globally consistent geo-replication that is built directly into Confluent clusters out of the box. This makes it easy to create a persistent and seamless bridge from Confluent Platform clusters in on-prem environments to Confluent Cloud clusters in cloud environments. Instead of having many point-to-point connections, you can create a single cluster link between multiple environments, which can be used by hundreds of different applications and data systems.
Having a single hybrid data backbone accelerates hybrid cloud delivery times and removes risk and security vulnerabilities from hybrid cloud architectures. It offers each application team the flexibility to easily migrate workloads to wherever it best suits your business. Additionally, for organizations that rely on Schema Registry to manage their metadata, Cluster Linking is complemented by Schema Linking—in preview state in 7.0—to quickly migrate your schemas from an on-premises Schema Registry into a fully managed Schema Registry in Confluent Cloud. Confluent supports these hybrid architectures for all of the leading public clouds, whether you are operating in AWS, Azure, or Google Cloud.
Also, because cluster links can originate from the source cluster, you can safely and securely send data between Confluent Platform and Confluent Cloud without opening up on-prem firewalls to Confluent Cloud’s IP addresses. This is the best practice in secure data migration and geo-replication, which eases the information security review process and improves delivery time for hybrid cloud workloads and on-prem to cloud migrations.
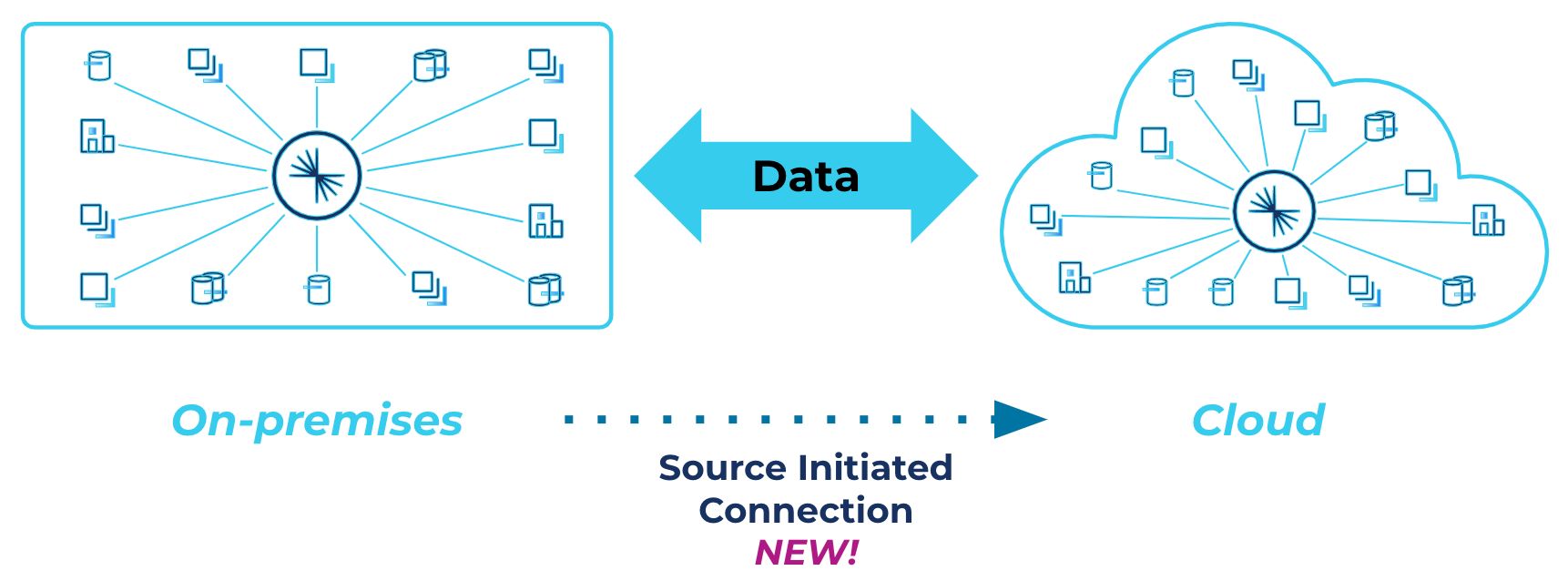
Source-initiated links ensure secure data migration and replication
And in a planned migration, consumers reading from a topic in one environment can start reading from the same topic in a different environment without any risk of reprocessing duplicate data or missing critical messages. This grants operators flexibility to promote topics and applications to the cloud over time using dynamic APIs—rather than manual configuration changes and connector restarts—facilitating smoother migrations with no data loss and minimal downtime and business disruption.
Self-serve access to data across all of your environments
With existing data integration solutions, it’s difficult to create a consistent data layer because of data sprawl across different environments, with each source having their own data schema and requirements for data sharing. Ultimately, this leads to data locked away in silos at rest, restricting developer agility and access to business-critical information in real time. This also results in disparate and disconnected customer experiences and inefficient backend operations.
Cluster Linking simplifies real-time access to data across different regions, clouds, environments, and teams with global data sharing and perfectly mirrored geo-replication of data between clusters. It provides efficient and simple bi-directional connectivity between Confluent Platform and Confluent Cloud.
With a single mirror command, you can create a byte-for-byte read-only copy of a topic and replicate it from your on-prem environment to different cloud regions or other on-prem environments. Likewise, any relevant cloud topics can also be imported on-prem. Using a write-once, read-many paradigm—also known as a “fan-out”—mirror topics can be safely and cost-effectively consumed by as many consumers as needed without increasing load on the original source cluster or incurring extra network charges. This ensures mission-critical applications have easy and reliable access to all of the data they need to run your business. In this way, you can break data silos and create a globally consistent data layer across your entire architecture in real time.
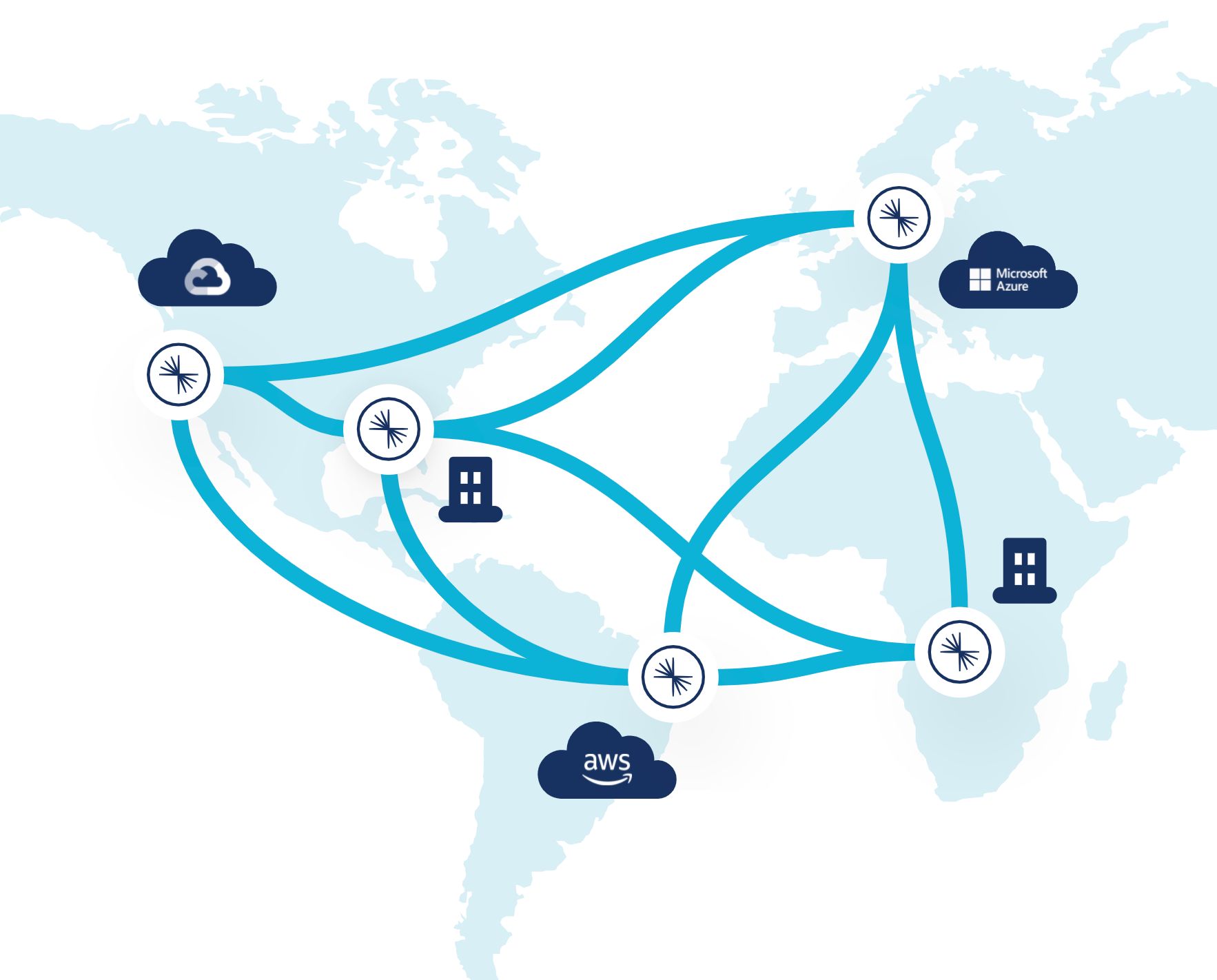
Cluster Linking enables a real-time bridge across environments
With a few simple commands, data is readily available throughout an entire business. This gives teams and developers across autonomous domains real-time access to the data they need in the environments they want.
Reduced TCO and operational burdens
Using Connect-based methods like MirrorMaker 2 to manage geo-replication increases infrastructure costs, operational burden, and architectural complexity. This is in large part because you need to manage additional infrastructure components, run extra virtual machines or servers, and use complex client-side code or manual processes for offset preservation. On the other hand, non-Kafka methods require bespoke, point-to-point connections that create technical debt and are expensive to manage, secure, maintain, and scale.
With this latest release, Cluster Linking offers cost-effective data geo-replication across your hybrid environments. Cluster Linking eliminates the need to deploy a separate Connect-based system to manage geo-replication or disaster recovery, which means less software to operate and maintain and fewer infrastructure components required to establish connectivity. This reduces infrastructure costs, operational burden, and architectural complexity.
Instead of requiring multiple deployments of MirrorMaker 2 to establish bidirectional data flow between clusters, you can easily create cluster links to directly replicate data securely, bidirectionally, and consistently between clusters and save costs. Reduced architectural complexity also means fewer resources are required to keep the system up and running, which means a lower overall TCO.
This is especially true for organizations with large multi-region Kafka deployments. Because a single deployment of MirrorMaker 2 can only replicate data unidirectionally between two clusters, geo-replicating data in each direction between three different clusters would require six different MirrorMaker 2 deployments. Thus, the more clusters you have in your global event mesh, the more Cluster Linking’s TCO savings are compounded.
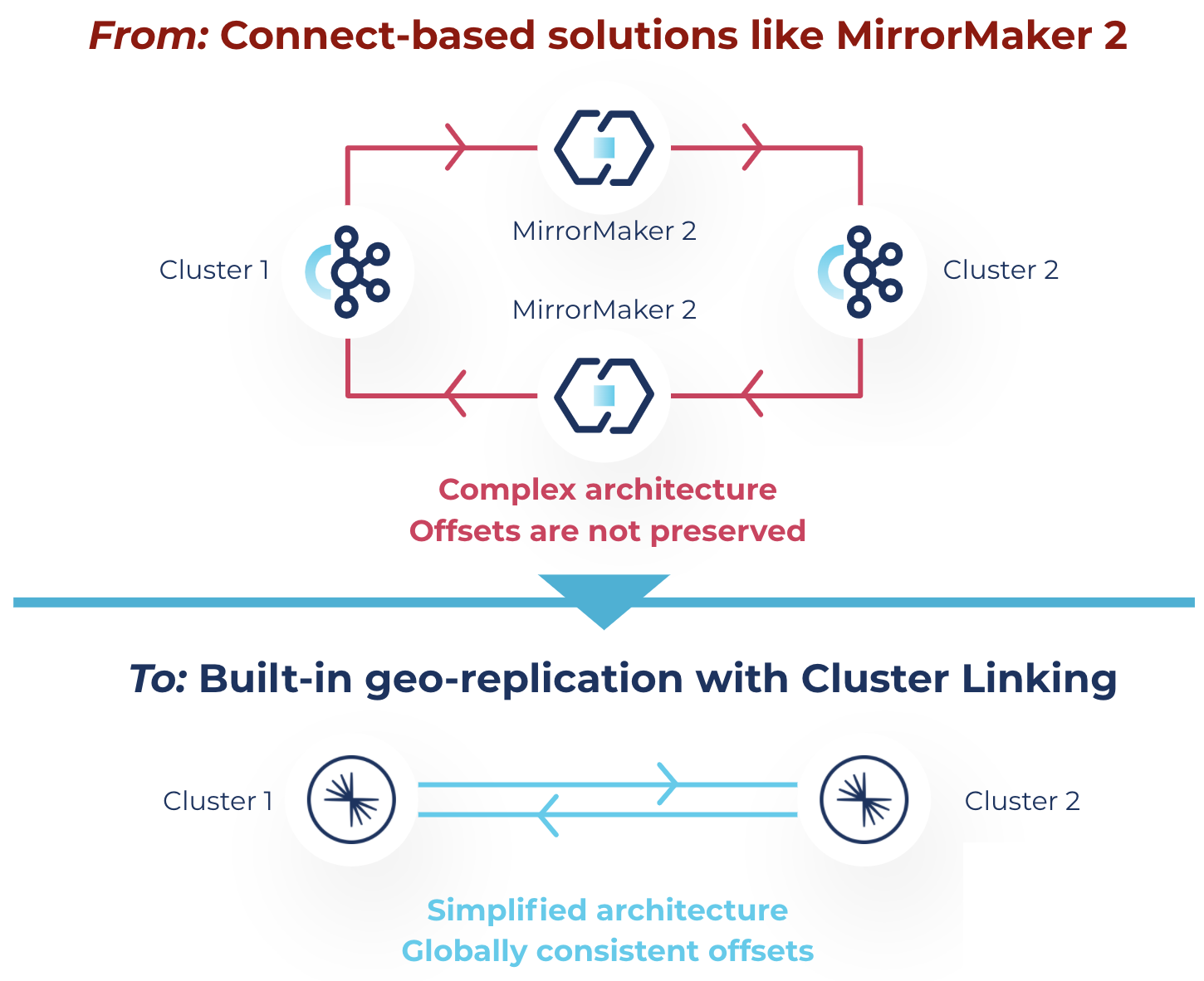
Simplify your architecture to reduce costs and remove technical debt
And instead of having many point-to-point connections that are typical for non-Kafka approaches, Cluster Linking allows you to create a single connection that can be secured, monitored, and audited. As your hybrid cloud footprint expands, this also means reduced networking costs and a more scalable platform to support all of your company’s streaming and real-time needs.
Additional enhancements
In addition to Cluster Linking, Confluent Platform 7.0 comes with several other major enhancements, bringing some of the cloud-native experience of Confluent Cloud to your self-managed environments and also bolstering it as a more complete platform to implement mission-critical use cases end to end. Here are some highlights.
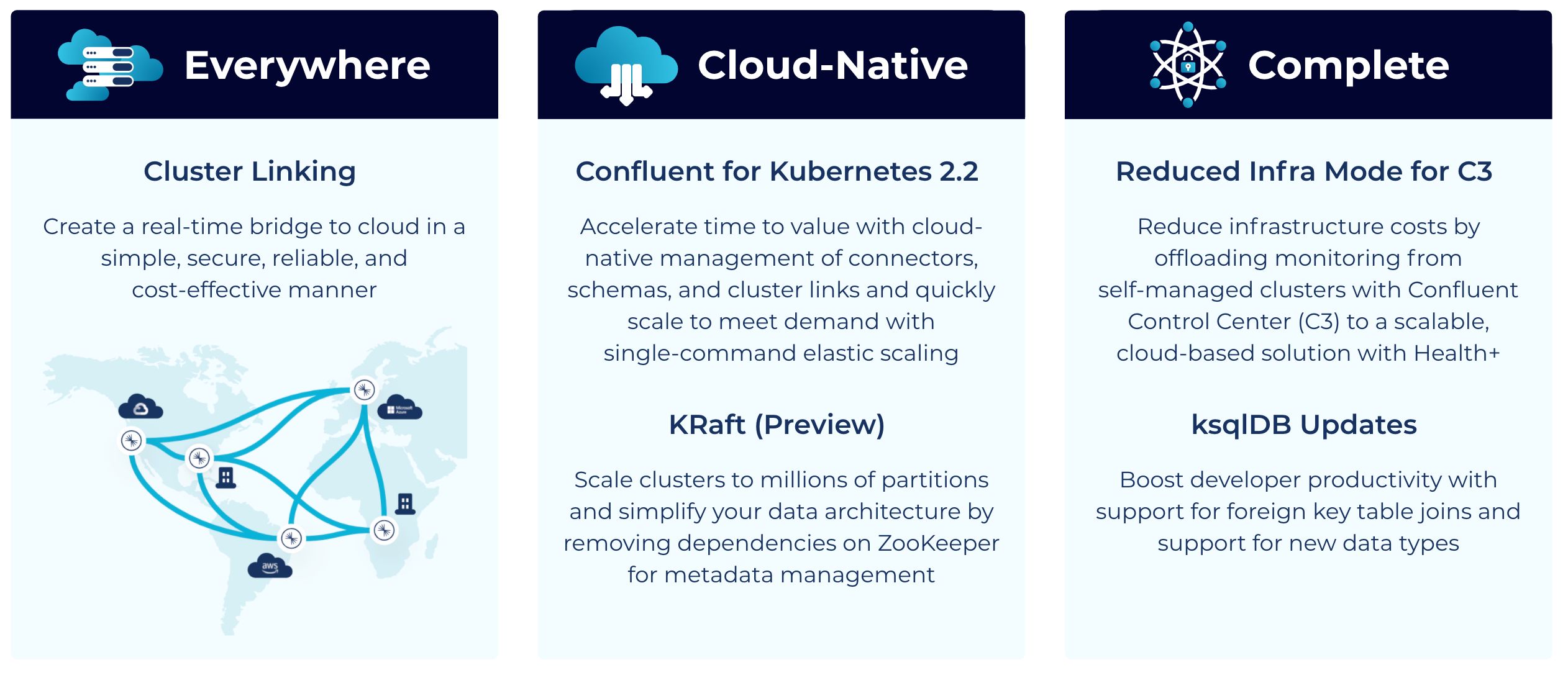
Confluent Platform 7.0 reinforces our key product pillars
Confluent for Kubernetes 2.2
In May of this year, we released Confluent for Kubernetes, which allows you to build your own private cloud Kafka service using a complete, declarative API to deploy and operate Confluent. We support enterprise Kubernetes distributions such as VMware Tanzu Kubernetes Grid (TKG) and Red Hat OpenShift or any distribution meeting the Cloud Native Computing Foundation’s (CNCF) conformance standards.

Confluent for Kubernetes supports all major enterprise Kubernetes distributions
In this latest release, we’re completing the declarative API by adding cloud-native management of connectors, schemas, and cluster links. This means that you can declaratively define the desired high-level state of these components of the platform rather than manage all the low-level details. This reduces operational burden and achieves a faster time to value, as you can provision, configure, update, delete, and conduct management tasks for these components through APIs rather than through manual and error-prone processes.
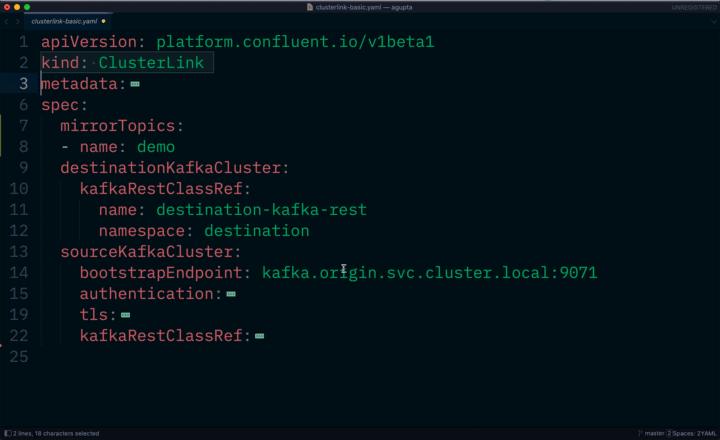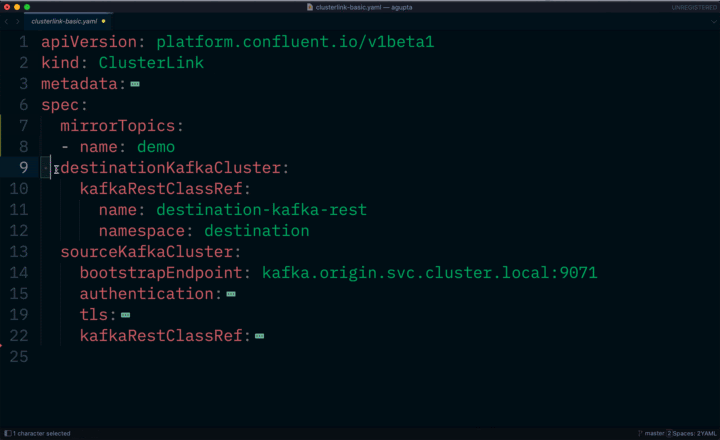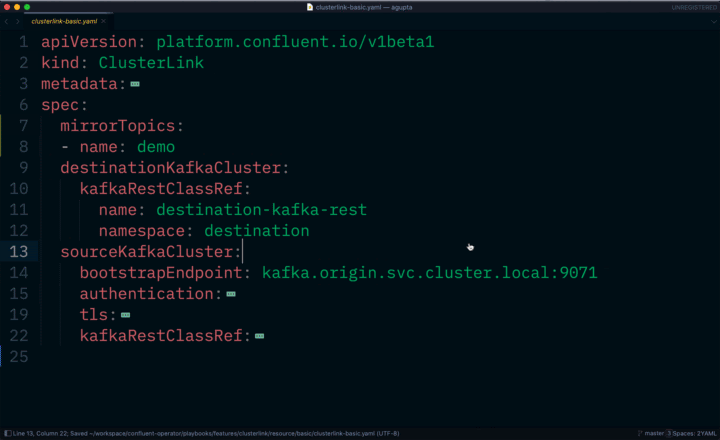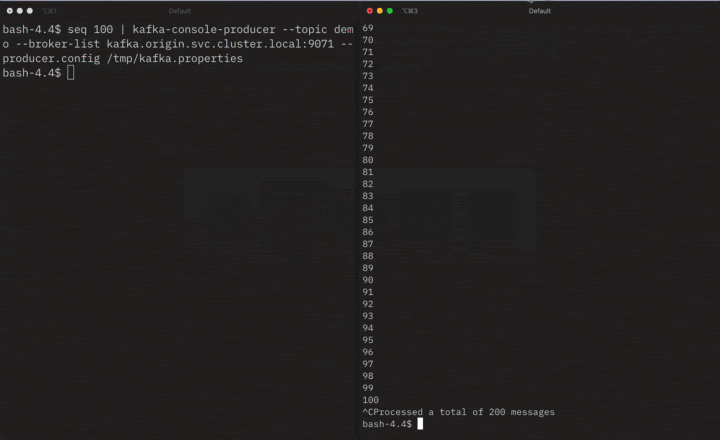
Declarative cluster link management with Confluent for Kubernetes
Another operational challenge that companies commonly face is scaling Kafka clusters, which is a manual, time-consuming, and error-prone process that distracts engineering teams from more important strategic projects. Teams often have to decide between overprovisioning infrastructure to avoid this pain point or taking on the ongoing operational risk and burden. Confluent for Kubernetes helps eliminate this tradeoff by enhancing elastic scaling through the Shrink API. With single command scaling up or down, organizations can now abstract this scaling process away completely while reducing its associated costs to their business.
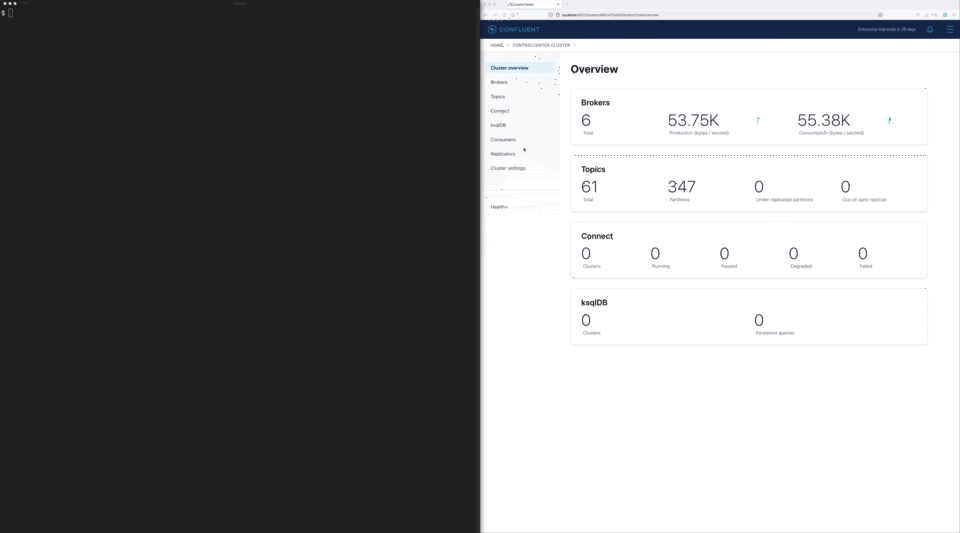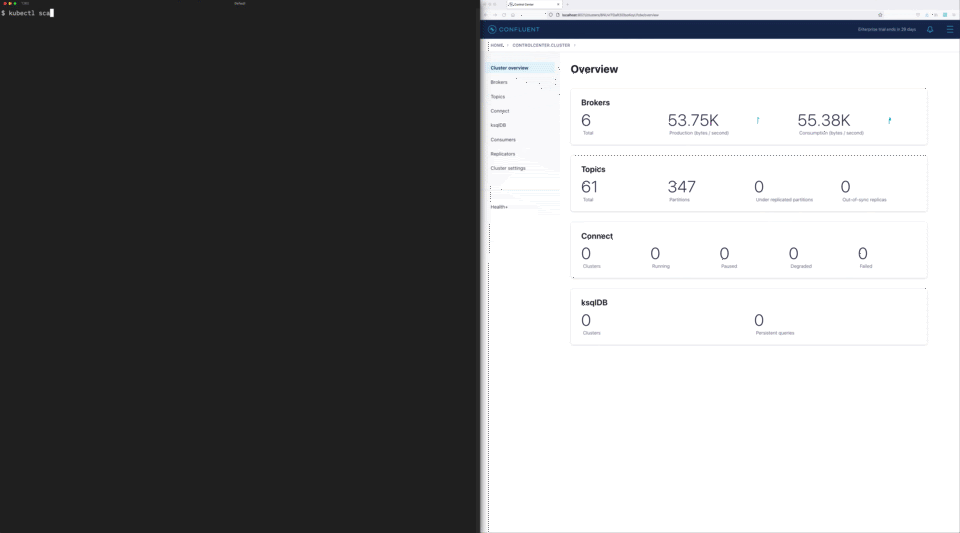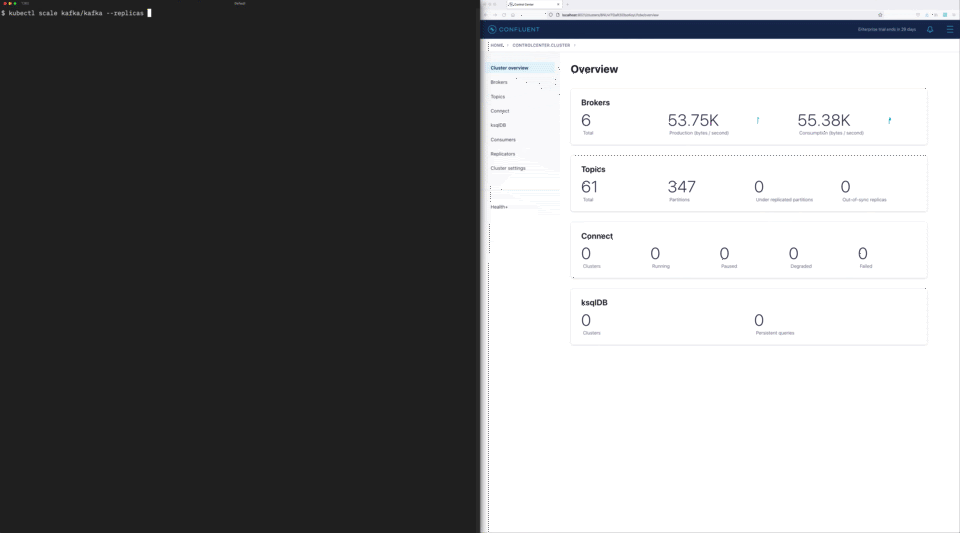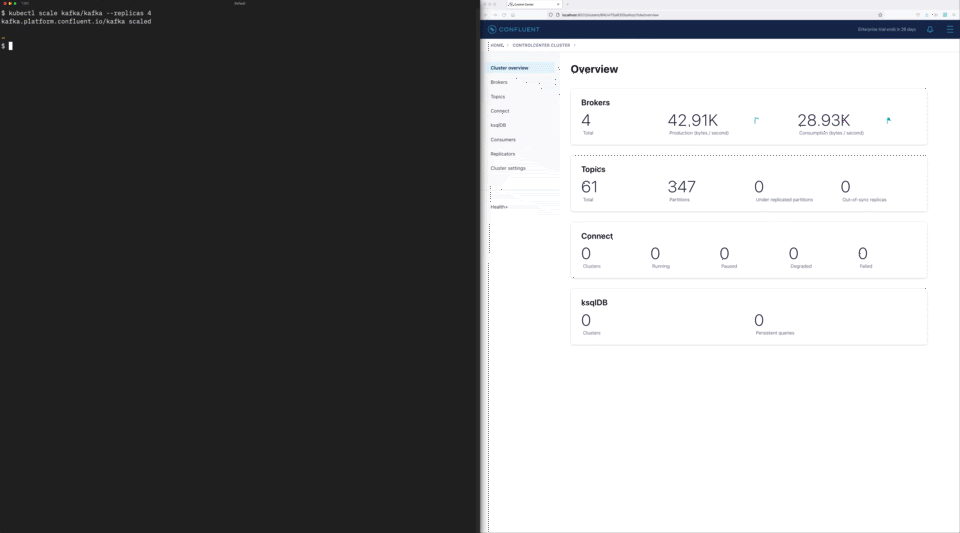
Single-command cluster shrinking and automated rebalancing with Confluent for Kubernetes
KRaft
Confluent Platform 7.0 offers a preview of Apache Kafka® Raft Metadata mode (KRaft), which is a modern, high-performance consensus protocol. Part of KIP-500, KRaft was introduced to remove Apache Kafka’s dependency on ZooKeeper for metadata management. Replacing external metadata management with KRaft greatly simplifies Kafka’s architecture by consolidating responsibility for metadata into Kafka itself, rather than splitting it between two different systems: ZooKeeper and Kafka.
This improves stability, simplifies the software, and makes it easier to monitor, administer, and support Kafka. It also allows Kafka to have a single security model for the whole system, along with enabling clusters to scale to millions of partitions and achieve up to a tenfold improvement in recovery times.
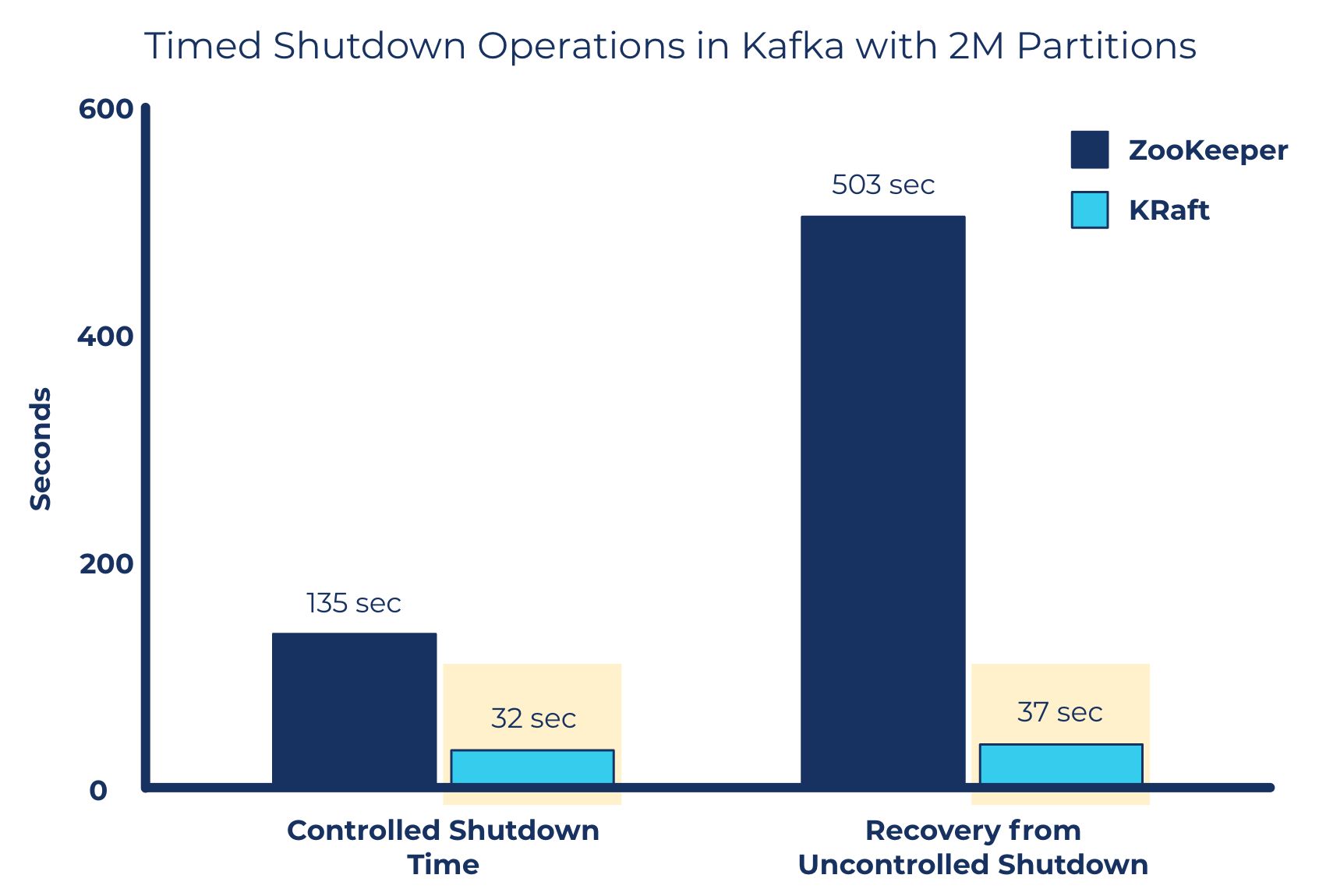
Support millions of partitions without significantly impacting recovery times
To try out KRaft with Confluent Platform 7.0 Docker images, please see cp-all-in-one-kraft. Please note that this feature is in preview and not yet supported for production workloads.
Reduced Infrastructure Mode for Control Center
In Confluent Platform 6.2, we introduced Health+, which offers intelligent alerting and cloud-based monitoring tools to reduce the risk of downtime, streamline troubleshooting, surface key metrics, and accelerate issue resolution. Health+ complements Control Center to provide a comprehensive suite of GUI tools to operate Confluent Platform; Health+ can be used for cluster monitoring, and Control Center can be used for cluster deployment and management.
Confluent Platform 7.0 now offers Reduced Infrastructure Mode for Control Center for those who want to use the GUI tool strictly for management and deployment. This enables you to significantly reduce TCO by offloading monitoring of on-prem clusters to a scalable, cloud-based solution in Health+, reducing your monitoring infrastructure costs by up to 70%.

Reduced Infrastructure Mode in Control Center
With Health+, you can identify and avoid cluster issues before they result in costly downtime by using Confluent’s library of expert-tested rules and algorithms, developed from running thousands of clusters in Confluent Cloud that meet our 99.95% uptime SLA. You can also easily view all of your critical metrics in a single cloud-based dashboard and speed issue resolution with accelerated diagnosis and support from our Confluent Support team of experts. If you are interested in Health+, you can sign up for free.
ksqlDB 0.21
Confluent Platform 7.0 also comes with ksqlDB 0.21, which includes several new enhancements that make it easier for developers to build real-time applications that leverage data in motion.
One of the biggest enhancements is support for foreign key table joins. In previous releases of ksqlDB, users were restricted to only joining tables based on each table’s primary key. Working around this limitation can entail extra code complexity for developers, as well as inefficient resource usage at application runtime.
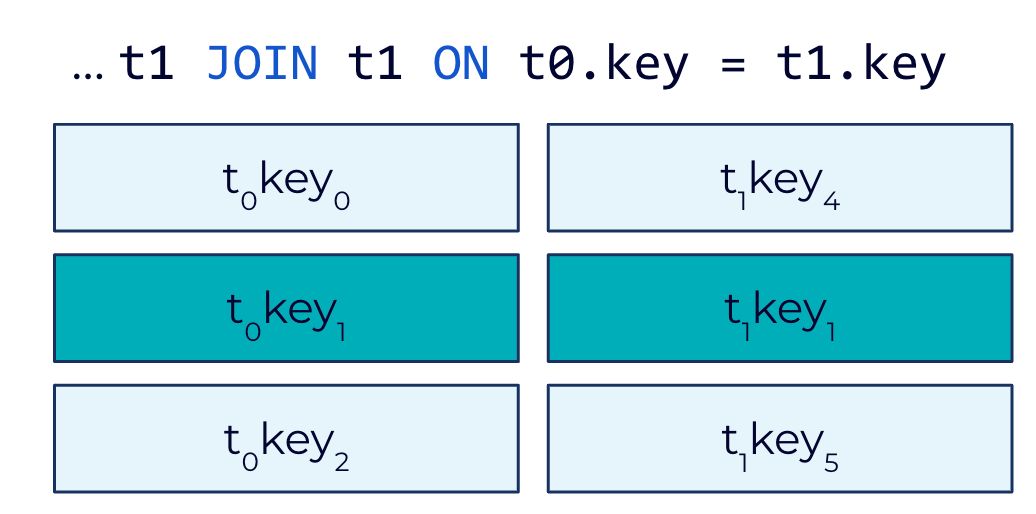
In existing table-to-table joins, rows are matched based on their keys
In Confluent Platform 7.0, ksqlDB now supports 1:N joins, or foreign-key joins for tables. With foreign-key joins, only one side of the join must reference a row key, while the other side of the join may reference any column in the target table. This means that developers no longer have to resort to workarounds for joining streams that add extra steps and are prone to errors. Instead, it provides developers greater ease and flexibility to combine and enrich the data based on their needs.
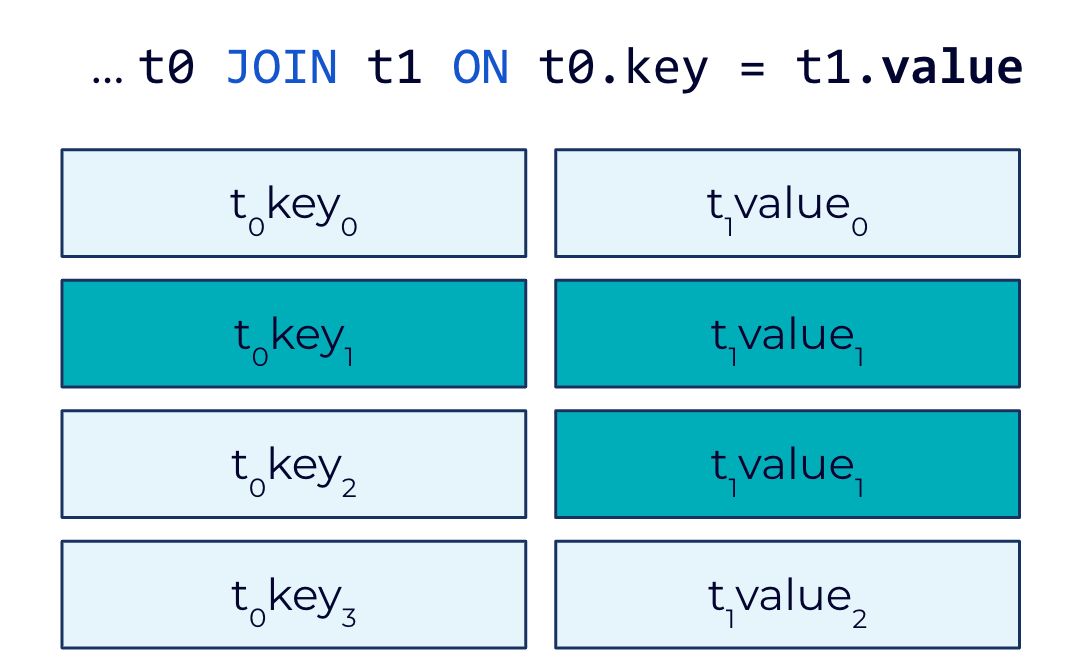
With foreign-key joins, only one side of the join must reference a row key
In addition, ksqlDB now supports DATE, TIME, and BYTES data types, along with the functionality for working with these data types. The DATE type represents a calendar date and the TIME type represents a time of day in millisecond precision. They are useful for representing less specific time values, such as birthdays or the time of a recurring alarm, that would not make as much sense as a TIMESTAMP value. This also means that you can ingest streaming data and maintain consistency with the source without having to convert data types or lose fidelity of your data.
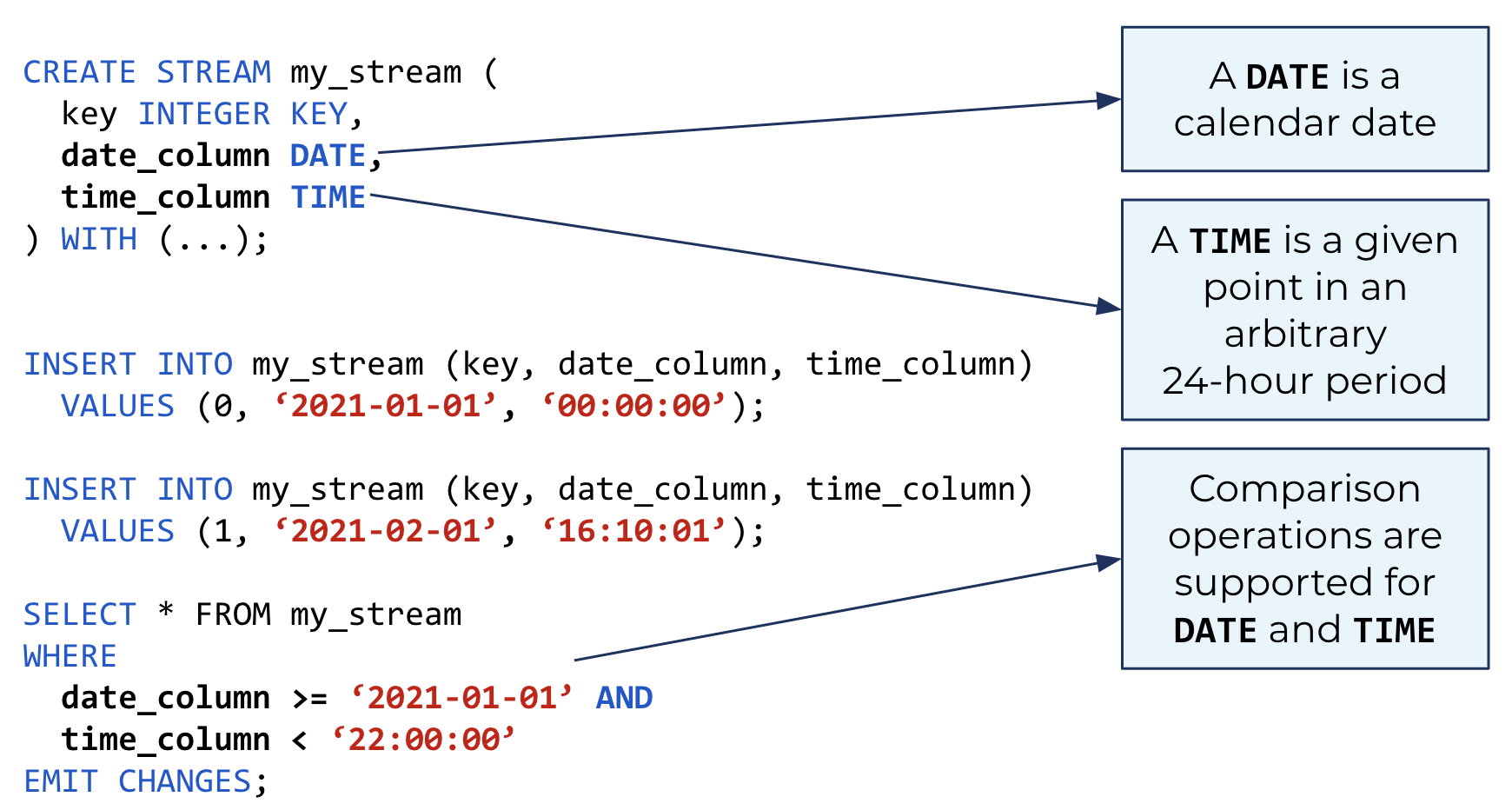
Represent date and time values without having to convert data types
The BYTES data type enables you to represent data that doesn’t fit into other types, like images or BLOB data from other databases. You can operate over the binary strings stored in BYTES columns using string-oriented functions to manipulate their values, decode text, or filter rows based on portions of the byte array, for example.
With Confluent Platform 7.0, ksqlDB also includes a number of additional enhancements that streamline real-time stream processing application development:
- SHOW CONNECTOR PLUGINS command to list all installed connectors available for use
- Support for managing connectors in the Java client
- Idle timeout for push queries
Support for Apache Kafka 3.0
Following the standard for every Confluent release, Confluent Platform 7.0 is built on the most recent version of Apache Kafka, in this case, version 3.0. In addition to the KRaft preview mentioned above, Kafka 3.0 streamlines the process of restarting Connector and Task instances with a single REST API call in KIP-745 and improves Kafka Streams timestamp synchronization with KIP-695.
For more details about Apache Kafka 3.0, please read the blog post by Konstantine Karantasis.
Want to learn more?
Check out Tim Berglund’s video and podcast for an overview of what’s new in Confluent Platform 7.0, and download Confluent Platform 7.0 today to get started with the complete platform for data in motion, built by the original creators of Apache Kafka.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.