New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Compare
Spark Streaming vs Apache Flink®: Modern Stream Processing Compared
Both Apache Spark® Structured Streaming and Apache Flink® have distributed stream processing capabilities. However, they approach the problem of how to process data continuously from fundamentally different architectural standpoints.
Spark Streaming, rooted in the world of batch processing, utilizes a highly effective micro-batch mode. Apache Flink—engineered from the start as a native stream processor—specializes in true event-at-a-time execution for ultra-low latency.
Choosing between them requires a deep understanding of your operational requirements, cloud environment, and critical factors like state management and latency tolerance.



Spark Streaming vs Flink at a Glance
Spark’s massive, batch-based ecosystem and dominance in the batch world of extract-transform-load (ETL) pipelines has made it the default choice for many analytics and AI/ML use cases. Spark Streaming (based on Discretized Streams or DStreams) and more recently Spark Structured Streaming have enabled users to process data streams while staying within the Spark ecosystem.
On the other hand, Flink's native streaming capabilities are rapidly gaining ground, especially for mission-critical, low-latency applications for use cases like fraud detection and prevention, real-time personalization, and predictive maintenance.
Evaluating these processing frameworks isn’t about which one is “better” overall—it’s about answering the critical questions for your specific architecture:
-
When does it make sense to use Spark Streaming instead of Flink? Or Flink over Spark Streaming?
-
What existing or future use cases should I use to build my list of requirements and business objectives?
-
Which engine fits best in my hybrid or multicloud environment and my organization’s long-term IT strategy?
This guide will help you understand Flink vs Spark Streaming in terms of their architectural design, core use cases, cloud-native features, and performance metrics.
Summary of Spark Streaming vs. Apache Flink Comparison
|
Feature |
Spark Streaming (DStream - Legacy) |
Spark Structured Streaming (Modern) |
Apache Flink |
|
Primary API |
RDD-based (DStreams): Lower-level, manual RDD manipulations. |
DataFrame/Dataset: High-level, declarative SQL-like API. |
DataStream / Table API: Low-level state control + high-level SQL. |
|
Execution Model |
Micro-batching only: Data is discretized into RDDs over time. |
Micro-batching (default) + Continuous Processing (experimental). |
Native Streaming: True event-at-a-time execution. |
|
Latency |
Seconds: Typically 500ms to several seconds |
Sub-second (Micro-batch) to Milliseconds (Continuous mode) |
Sub-second / Milliseconds: Consistently ultra-low |
|
Fault Tolerance |
WAL + Checkpointing: Replays entire failed RDD batches |
Checkpointing + Replay: Focuses on replayable sources and idempotent sinks |
State Snapshots: Efficient asynchronous checkpoints of global state |
|
State Handling |
Requires enabling checkpointing for state to a fault-tolerant file system (like S3 or HDFS) |
Versioned KV stores typically managed in memory |
External state backends (e.g., RocksDB) independent of memory |
|
Event-Time Support |
Limited: Based on processing time; manual handling for late data |
Built-in: Native support for watermarks and event-time windows |
Advanced: Industry standard for watermarks and out-of-order data |
|
Ideal Use Cases |
Legacy systems, simple high-throughput pipelines not requiring SQL |
Streaming ETL, Spark-integrated ML, and general analytics |
Fraud detection, mission-critical low latency applications, and complex event processing |
|
Developer Skillset |
Highly intuitive for those familiar with Python/SQL |
Highly intuitive for those familiar with Python/SQL |
Steeper learning curve; requires understanding of event-time & watermarks |
|
Managed Services |
Rare (legacy support in EMR or Databricks) |
Databricks, Azure HDInsight, AWS EMR |
Confluent Cloud, AWS Kinesis Data Analytics |
NOTE: For the rest of the guide, Spark Streaming refers to the Structured Streaming API unless otherwise specified.
How Do Spark Streaming and Flink Differ Architecturally?
The core architectural differences between Spark Streaming and Flink stem from their original design philosophies: Spark as a batch processing engine that’s been adapted to streaming, and Flink as a native stream processor.
Execution Model: Micro-Batching vs. Native Streaming
The most immediate impact of these design philosophies is visible in how data traverses the engine.
-
Spark’s model treats an unbounded data stream as a sequence of small, bounded batch jobs, known as micro-batches.
-
Batch-First Roots: Spark’s robust optimization engine and execution model are inherited directly from its powerful batch capabilities.
-
How it Works: Data is collected from the source over a short, predefined interval (e.g., 500ms to a few seconds).Once the interval ends, the entire collection is processed as a single, discrete batch.
-
Latency: This inherent wait time for the batch boundary creates a periodic delay, leading to near real-time latency (typically in the seconds range) rather than true real-time.
-
-
Flink was designed to handle continuous, unbounded streams natively.
-
Streaming-Native Design: Flink treats data as an endless flow, processing records event-at-a-time (or in a continuous, pipelined fashion).
-
How it Works: Data is immediately consumed and flows through a directed acyclic graph (DAG) of operators without waiting for a time boundary.
-
Latency: This continuous pipeline approach achieves ultra-low latency (often sub-second or millisecond) because there is no enforced waiting time.
-
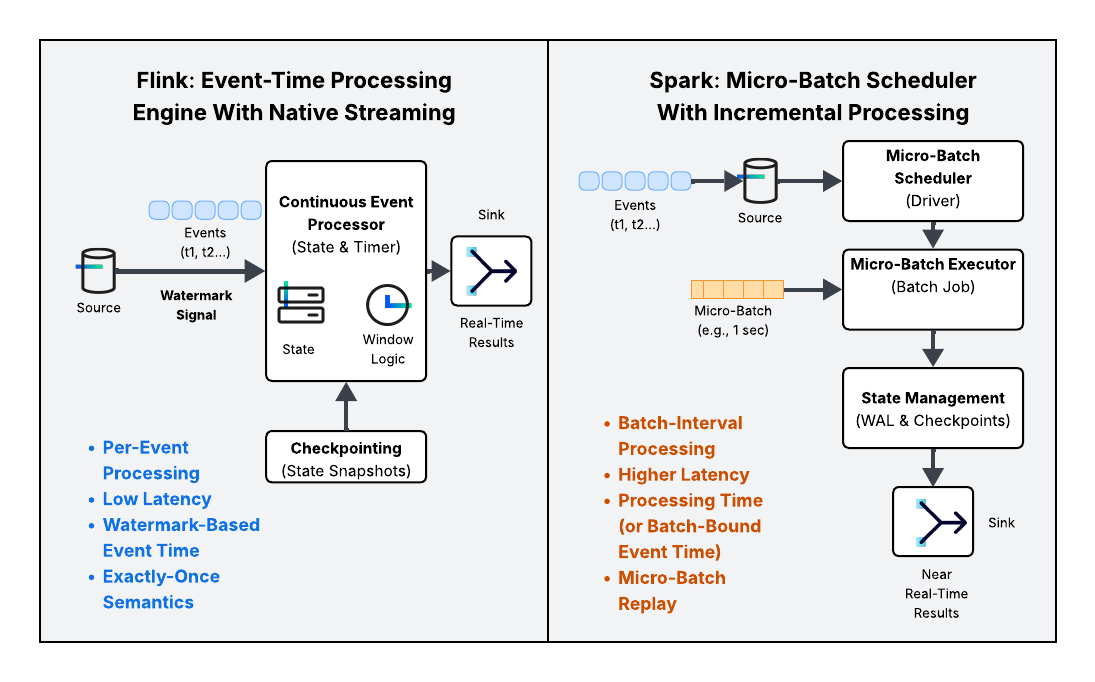
What’s the difference between micro-batching and true streaming?
Micro-batching sacrifices the immediate processing of an event for the efficiency and parallelism of batch processing. True streaming, or native streaming, processes an event as soon as it arrives, eliminating the periodic delay imposed by the batch boundary.
So how does Flink process events differently from Spark?
Flink executes a single, long-running stream job that continuously updates state and output, whereas Spark executes a sequence of short-lived batch jobs.
Time Semantics: Event-Time and Watermarks in Flink vs. Event-Time Adaption in Spark Streaming
Correctly handling time is crucial for accurate stream processing, especially when events arrive out of order.
Flink excels in event-time processing, which is the most accurate way to handle distributed streams.
-
Event Time: The timestamp assigned by the source when the event actually occurred (e.g., when a user clicked a button).
-
Watermarks: Flink uses Watermarks—a logical clock advancement mechanism—to signal when the system believes it has received all events for a particular time window. This allows Flink to correctly process late-arriving data and accurately calculate time-windowed aggregations.
Spark also supports event-time processing and Watermarks, though this feature was integrated later into its micro-batch model.
-
Processing Time: Spark's initial focus was often on processing time (when the event is processed by the engine), which is simpler but prone to inaccuracies if network latency or system load varies.
- Watermarks in Spark: Structured Streaming now uses watermarks to handle late data, but these checks often occur at the boundary of each micro-batch, tying the event-time logic to the underlying batch execution cadence.
Take the Apache Flink 101 course on Confluent Developer to learn more.
Fault Tolerance and State Management – Asynchronous Checkpointing vs.
Both engines guarantee robust streaming durability and recovery, but their mechanisms are architecturally distinct.
Flink's fault tolerance is based on the Chandy-Lamport distributed snapshot algorithm, leading to efficient state management.
-
Mechanism: Flink takes global, consistent snapshots of the entire application state—including the position in the source stream (offsets), user-defined function (UDF) state, and internal operator state—at regular intervals. These are called Checkpoints.
-
Exactly-Once: This mechanism, combined with appropriate sources and sinks, enables robust, guaranteed exactly-once semantics for stateful operations.
-
Recovery: When a failure occurs, the job is restarted from the last successful checkpoint, which is stored externally (e.g., in HDFS or S3). The lightweight, distributed nature of the snapshot allows for very fast recovery.
Spark's fault tolerance is based on recovering and re-executing its micro-batches.
-
Mechanism: Spark uses checkpointing to save the metadata required for recovery (like stream offsets and the structure of the computation graph) and relies heavily on a Write-Ahead Log (WAL) for reliability. The state is typically saved incrementally per micro-batch.
-
Exactly-Once: Structured Streaming achieves exactly-once semantics by ensuring that it can re-read data from the source (which must be replayable, like Apache Kafka®) and by using transactional/idempotent sinks.
- Recovery: When a failure occurs, Spark restores the job metadata from the checkpoint and re-processes the lost input data by re-executing the last few micro-batches. This process can be generally slower than Flink's direct state restoration, depending on the micro-batch size.
What Are the Key Use Cases for Flink vs. Spark Streaming?
Choosing between Apache Spark Structured Streaming and Apache Flink often comes down to aligning the engine's core architectural strengths (micro-batching vs. native streaming) with your specific application requirements for latency, state complexity, and ecosystem integration.
Flink: The Low-Latency and Event-Driven Specialist
Flink is the fit-for-purpose choice when you need to manage complex application state over time in order to build cloud-native, event-driven pipelines and highly accurate, time-sensitive applications. Its native, event-at-a-time execution model eliminates the periodic delay associated with micro-batching, making it the superior choice for applications where latency must be measured in milliseconds.
|
Use Case Card |
Description |
Flink's Advantage |
|
Analyzing transaction or network data for suspicious patterns that require immediate action (sub-second alerting or blocking). |
Ultra-low latency native streaming and robust state management allow for immediate, highly accurate pattern matching over large volumes of continuously arriving data. |
|
|
Complex Event Processing (CEP) |
Identifying a sequence of events across multiple streams that signify a business pattern (e.g., a login followed by a purchase and then a cart abandonment within a specific window). |
Its native support for event-time processing, Watermarks, and flexible State APIs makes handling complex temporal relationships reliable. |
|
Continuously updating aggregated metrics for live operational dashboards where data freshness is paramount. |
Superior efficiency in stateful aggregation allows for immediate, continuous updates to materialized views and supports unified batch + streaming analytics against the same application logic. |
|
|
Joining a fast-moving data stream (e.g., clicks) with a slowly changing stream (e.g., user profiles) while maintaining long-running state for each key. |
Its dedicated, persistent state backends (like RocksDB) are built to manage massive amounts of application state crucial for complex streaming joins and enrichments in Kafka-native pipelines. |
Spark Structured Streaming: The Ecosystem Workhorse
Spark is ideal for organizations already invested in the broader Spark ecosystem and for workflows where near real-time latency (measured in seconds) is sufficient. It thrives in batch-centric workflows that are incrementally modernized to include a streaming component.
|
Use Case Card |
Description |
Spark's Advantage |
|
Streaming ETL (Data lake Ingestion) |
Efficiently landing high volumes of streaming data into a data lake or lakehouse (e.g., Delta Lake, Apache Hudi) with transactional guarantees. |
Seamless, unified API (DataFrame/Dataset) allows the same code to run batch or stream. Its native integration with Delta Lake and cloud storage is unmatched for high-throughput ingestion. |
|
Log Processing & Simple Enrichment |
Simple transformations, filtering, or routing of logs or clickstream data that do not require complex, long-running state management. |
High throughput and the immense library of SQL functions and UDFs make it perfect for rapid, high-volume data transformation. |
|
Calculating and serving real-time features to a model by operating on a stream, or performing low-latency model inference. |
Unparalleled integration with MLlib and its strong PySpark ecosystem makes it the de facto standard for data scientists building streaming ML pipelines. |
|
|
Architectures where the streaming logic is a direct, incremental extension of the existing, proven batch processing logic. |
Single API for batch and stream significantly simplifies development, deployment, and maintenance for Spark ecosystem users. |
If you are already operating within a managed Spark environment like Databricks or utilizing the full capabilities of the Spark ecosystem (MLlib, Spark SQL, Delta Lake), using Structured Streaming drastically lowers the operational overhead and provides a cohesive platform for all data processing tasks, from batch ETL to streaming.
How Do Spark and Flink Compare in the Cloud Era?
How well each framework manages state, scales elastically, and integrates into a unified data platform is a critical consideration in today’s hybrid and multicloud era. Both are highly capable, but their cloud profiles reflect their original batch-first versus streaming-native architectures.
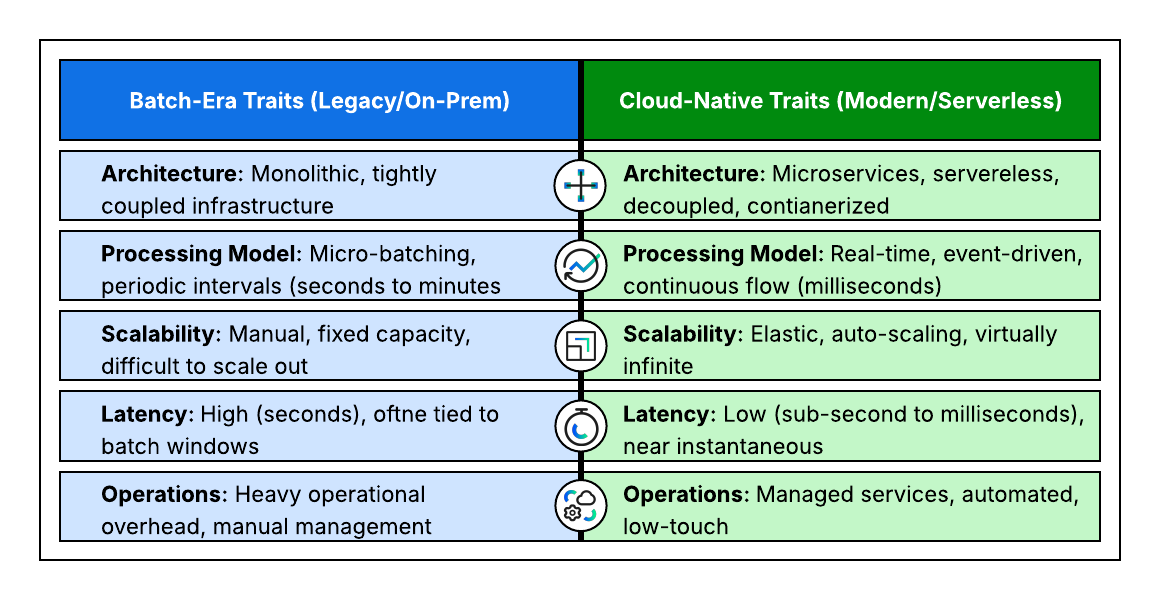
State Handling and Durability
The efficient management of application state is the defining feature of a cloud-native stream processor, influencing cost and recovery time.
Flink is arguably more cloud-native in its state management due to its:
-
Externalized State: Flink's architecture is built around managing complex, application-specific state (e.g., session windows, aggregations) using external state backends like RocksDB (which can spill to disk), making the state size independent of the executor memory.
-
Incremental Checkpointing: Flink supports efficient incremental checkpointing—persisting only the changes since the last snapshot—which drastically reduces I/O and recovery time, a major cost and performance benefit in cloud storage (like S3 or GCS).
-
Savepoints: Flink uses Savepoints (manually triggered, consistent snapshots) for planned operations like upgrades, debugging, or migration, enhancing Data pipeline modernization by decoupling application changes from infrastructure.
Spark Streaming uses state management that is fundamentally tied to its micro-batch model:
-
Versioned Key-Value Store: Spark manages state using a versioned key-value store, typically stored in memory and checkpointed to cloud storage. While efficient for batch-like state, complex, massive state can be more challenging without careful tuning.
-
State Store Providers: Structured Streaming now supports RocksDB as an external state store provider, moving its capabilities closer to Flink's to handle larger states that don't fit in JVM memory.
Scalability and Elasticity
The ability to scale resources dynamically based on load is essential for cost-efficiency in the cloud.
Flink is highly elastic—its architecture, coupled with cloud orchestrators like the Flink Kubernetes Operator, allows for fine-grained dynamic scaling.
-
Because the state is externalized and consistent, Flink jobs can be scaled up or down (add or remove task slots) using Savepoints with minimal disruption and rapid recovery from the last consistent state.
-
This is ideal for optimizing costs on bursty stream workloads.
Spark Streaming is designed for elastic scaling, leveraging cloud environments and Spark's built-in dynamic allocation to automatically adjust compute resources (executors) up or down based on data volume and processing load
-
Spark's elasticity is often managed by the underlying cloud platform (e.g., Databricks' auto-scaling, EMR, or Kubernetes).
-
Spark also benefits from managing a single cluster that handles both batch and streaming, allowing resources to be shifted quickly between different workload types.
-
While effective, the scaling mechanism is typically applied at the Executor/Cluster level, tied to the micro-batch cadence.
How Do Flink and Spark Streaming Compare on Performance, Latency, and Fault Tolerance?
The performance characteristics of Spark and Flink are direct consequences of their underlying architectures. While Spark prioritizes throughput and unification with batch workloads, Flink is engineered for speed and state consistency in continuous streaming scenarios.
Latency and Processing Speed
The execution model heavily dictates the speed at which data becomes available downstream.
- FlinkSub-Second Latency): As a native streaming engine, Flink processes data row-by-row (event-at-a-time). This pipeline approach eliminates artificial waiting periods, allowing Flink to achieve ultra-low, sub-second end-to-end latency. It is the preferred choice for time-sensitive applications like fraud detection or real-time alerting.
-
Spark Structured Streaming (Seconds Latency): Spark processes data in micro-batches. While this introduces a latency floor in the seconds range (due to the accumulation window), it offers a distinct advantage for valid hybrid use cases: it integrates seamlessly with Spark's massive batch ecosystem. If your priority is unifying batch and stream pipelines rather than immediate speed, Spark provides sufficient performance.
Fault Tolerance and Reliability
Both engines provide strong consistency guarantees, but they achieve them through fundamentally different recovery mechanisms.
- Apache Flink (State Snapshots): Flink is designed for high availability and strict correctness. It utilizes a distributed snapshot algorithm (Chandy-Lamport) to capture the state of the entire stream asynchronously. This allows Flink to guarantee exactly-once semantics with minimal performance overhead, ensuring that every event is accounted for—even during failures—without reprocessing duplicate data.
- Spark Structured Streaming (Micro-Batch Replay): Spark achieves fault tolerance by checkpointing offsets and relying on a Write-Ahead Log (WAL). If a failure occurs, Spark ensures consistency by re-executing the failed micro-batches. While robust, this "replay" method can take longer to recover than Flink's state restoration, potentially causing temporary spikes in latency during downtime.
What Are the Ecosystem and API Differences?
The choice between Apache Spark Structured Streaming and Apache Flink is often influenced by the developer experience, language preference, and integration with the broader data stack. Their APIs and ecosystems reflect their original strengths—Spark in general-purpose big data, and Flink in streaming-native event processing.
Flink vs. Spark Streaming – Ecosystem, API & Language Support
|
Feature |
Flink / Flink SQL |
Spark Structured Streaming / Spark SQL |
|
Integration With Data Sources/Sinks |
Strong focus on real-time messaging systems (Kafka, Pulsar, Kinesis), but supports file systems and databases. |
Broadest integration library: HDFS, cloud storage (S3, GCS), Kafka, databases, and native connectors for file formats (Parquet, ORC). |
|
Integration With Data Lake/Lakehouse |
Excellent for reading and writing data, but does not provide a native transactional storage layer. |
Native integration with the Delta Lake open format, making it the dominant engine for Lakehouse architectures. |
|
Integration With Machine Learning |
Can be used for streaming feature engineering and inference, but generally requires external ML libraries. |
Deep, native integration with MLlib and the broader Python data science ecosystem (Pandas, Scikit-learn). |
|
Integration With Streaming SQL Alternatives |
Often seen alongside or compared to streaming SQL for simpler, stream-centric processing use cases on Kafka. |
The standard for ad-hoc and complex analytical SQL over massive datasets. |
|
Core Languages |
Strongest in Java/Scala. Mature APIs utilizing functional programming paradigms. |
Highly mature in Scala, Java, and Python (PySpark). Strong support for R and SQL. |
|
Primary Abstraction |
DataStream API: Low-level, state-aware API for building complex, event-at-a-time logic. Table API: Higher-level, relational API. |
DataFrame/Dataset API: High-level, declarative, and unified API used for both batch and streaming operations. |
|
Python Support |
Is Flink Python-friendly? Flink offers PyFlink, with the Table API/SQL being the most mature Python interface. Python support for the DataStream API is growing rapidly but still lags behind Java/Scala. |
Extremely Python-friendly. PySpark is the de facto standard for data science and ETL workloads, offering a vast array of libraries and mature UDF support. |
|
SQL Support: Unified Semantics |
Flink's SQL and Table API are inherently unified; the system treats batch as a bounded stream. |
Spark SQL queries run seamlessly against both batch and streaming DataFrames. |
|
SQL Support: Stateful Logic |
Superior native support for advanced, stateful streaming concepts like complex windowing (e.g., Session windows) and temporal joins directly within the SQL dialect. |
Excellent support for basic windowing (e.g., Tumbling and Sliding windows) and standard SQL operations. |
|
SQL Support: Query Flexibility |
The power of Flink SQL overview lies in its ability to handle complex, continuous query logic that runs as a long-lived application. |
Excels at running powerful, ad-hoc, and highly optimized analytical queries on streaming data structures (DataFrames). |
Spark Structured Streaming fully supports Spark SQL. You can write the entire stream logic—from transformations to aggregations—using standard SQL syntax applied to the streaming DataFrames, making it incredibly accessible to analysts and engineers familiar with databases.
Spark’s massive ecosystem, built over a decade of batch dominance, provides a unified platform for ETL, machine learning, and analysis. Flink's ecosystem is more specialized, focused on providing the best possible primitives for stateful, low-latency, and highly reliable event processing.
Streaming SQL and Schema Evolution
Mature declarative APIs are critical for developer productivity and governance in cloud data flows.
Flink SQL is a highly mature, ANSI-compliant SQL layer designed explicitly for unified streaming and batch.
-
Stateful Windowing: It provides superior, native support for complex, stateful streaming concepts directly in SQL (e.g., time-based windows, temporal joins), making it powerful for real-time analytics.
-
Schema Evolution: Flink's data types are robust, offering strong capabilities for handling schema evolution in long-running streaming applications.
Spark SQL (Structured Streaming) is the most widely adopted SQL dialect in big data.
-
Unified API: Structured Streaming allows running streaming queries using the familiar Spark SQL syntax, providing excellent developer experience.
-
Lakehouse Integration: Its true power in the cloud comes from its integration with Delta Lake, where its streaming SQL capabilities are used for incremental ingestion and transformation as part of the medallion architecture (Bronze → Silver → Gold layers).
Flink is more cloud-native for stateful stream processing due to its architecture focusing on externalized, incremental state, dynamic scaling, and ultra-low latency, while Spark offers a cohesive environment for batch, stream, ML, and governance.
Managed Services and Platform Integration
In the cloud, organizations often consume use these technologies through managed service providers like Databricks and Confluent, which abstract the operational complexity.
|
Feature |
Databricks (Powered by Spark) |
|
|
Platform Model |
Lakehouse Platform: Focuses on unifying data warehousing, ETL (batch & stream), BI, and ML on a single platform (Delta Lake) |
Part of a Complete Data Streaming Platform: Focuses on event backbone, low-latency stream processing, and integration with Kafka-native pipelines |
|
Core Offering |
Unified Engine, Delta Lake: The single API for batch/stream and the ACID-compliant, open storage layer (Delta) are the key value propositions |
Serverless Stream Processing: Provides a fully managed, serverless Flink service with simplified deployment and autoscaling, often deeply integrated with Kafka |
|
Cloud-Native Value |
Provides a single environment for all data roles (e.g., data scientist, engineer, analyst) using a unified compute/governance model (Unity Catalog) |
Abstracts away complex Flink operations like checkpoint tuning, state backend management, and Kubernetes orchestration, letting developers focus on stream logic |
Is Spark Easier to Learn Than Flink?
Yes. Spark's unified DataFrame API makes it easier to learn for developers already familiar with SQL or Python/Pandas, bridging the gap between batch and stream with familiar constructs. Flink's complexity is warranted by its low-latency, stateful capabilities.
Using Flink SQL on Confluent Cloud allows you to focus on business logic in familiar SQL syntax while automated infrastructure management, scaling, and integration with Kafka abstract away complex operations.
Try Confluent Cloud for Apache Flink®
What Do Developers and Operators Say About Using Each?
When moving from architectural blueprints to daily reality, the operational and development experience becomes critical. Here is a summarized view of the community sentiment regarding Apache Spark Structured Streaming and Apache Flink, framed around key practical concerns.
Developer Experience and Learning Curve
|
Topic |
Apache Flink Sentiment |
Spark Structured Streaming Sentiment |
|
Learning Curve |
Higher. The core DataStream API is powerful but requires a deeper conceptual understanding of distributed state, event-time processing, and Watermarks. |
Lower. The unified DataFrame/Dataset API(PySpark, Spark SQL) is highly intuitive, especially for developers transitioning from batch ETL or relational databases. |
|
API Abstraction |
Developers gain ultimate control via the DataStream API but must manage complexity manually. Flink SQL offers a simpler, high-level path for many use cases. |
Offers excellent abstraction; developers can often write complex stream logic without deep knowledge of underlying distributed mechanisms. |
|
Schema Handling |
Robust data type system and excellent support for Schema Registry integration for long-running stream applications. |
Mature schema handling, especially when integrated with Delta Lake for enforcement and evolution. |
Operator Experience and Observability
The operational model for stream processors—how they are deployed, monitored, and maintained—is crucial for high availability.
|
Topic |
Apache Flink Sentiment |
Spark Structured Streaming Sentiment |
|
State Debugging |
Challenging but improving. Debugging long-running, complex stateful applications can be tricky. However, tools like Savepoints provide excellent visibility and control for recovery and debugging specific failure points. |
Simpler in many ways due to the micro-batch nature. Debugging is often limited to inspecting the inputs and outputs of the failed batch. |
|
Ops/Monitoring Maturity |
Highly mature for production-grade stream processing. Dedicated tooling focuses on Stream governance and monitoring, especially for resource utilization and latency. |
Excellent maturity, benefiting from years of integration with cluster managers (YARN, Mesos, Kubernetes) and widespread cloud tooling (e.g., Databricks Monitoring, EMR Console). |
|
Resource Efficiency |
Generally regarded as highly efficient for CPU and I/O usage in long-running jobs due to its pipeline execution and incremental checkpointing. |
Can be resource-intensive if batch intervals are very small or if the engine re-processes significant data during failure recovery. |
|
Deployment |
Often deployed via dedicated Flink Operator on Kubernetes or through managed services like Apache Flink on Confluent Cloud. |
Deployed easily on virtually all cloud platforms via managed services or native cluster managers (Kubernetes, YARN). |
Which Tool Is More Operator-Friendly?
This depends on your priorities:
-
Spark is more operator-friendly for organizations managing a unified batch and stream platform due to its integrated tooling and ecosystem maturity.
-
Flink is more operator-friendly for mission-critical, low-latency applications because its architecture is designed for stable, long-running processes with fast, state 0ful recovery and dynamic scaling.
Can Spark and Flink Be Used Together?
In modern data architectures, the choice between Spark and Flink is rarely binary. They are often complementary tools within a larger ecosystem, leveraging the specific strengths of each engine.
A common pattern is a layered architecture, where Spark handles massive historical datasets and Flink handles the immediate, high-velocity ingress.
-
Spark is often the engine of choice for "at-rest" data. Data Scientists use Spark to train complex Machine Learning models on petabytes of historical data. Large-scale nightly aggregations or reprocessing of data lakes.
-
Flink is the engine of choice for "in-motion" data. Once Spark trains a model, the model artifacts are loaded into Flink. Flink then applies this model to live events (e.g., fraud scoring) with sub-second latency. Detecting patterns across a moving time window (e.g., "3 failures in 10 seconds").
- You typically connect them via an intermediate storage layer like Kafka or a Data Lake (e.g., S3/HDFS). This allows them to operate on the same data at different speeds.
See how Sencrop uses Databricks and Confluent Cloud for Apache Flink® together to decouple data ingestion, processing, and storage and give 35K farmers decision-making with real-time analytics and ML pipelines.
Example: Streaming Pipelines for AI
Consider a fraud detection system for a bank:
-
Ingest: Transaction data flows into Kafka-powered dataflows.
-
Train (Spark): Every night, Spark reads the last 30 days of data from the Data Lake to retrain and improve the fraud detection model.
-
Serve (Flink): The updated model is pushed to the Flink cluster. Flink consumes live transactions from Kafka, applies the new model, and blocks fraudulent cards in milliseconds.
Integration Points – Can Flink Consume Data From a Spark Job Output Directly?
Flink can’t consume data directly from a Spark job as they are separate clusters. You typically connect them via an intermediate storage layer like Kafka or a data lake (e.g., S3 or HDFS). This allows them to operate on the same data at different speeds:
-
Via Kafka: Spark writes results to a Kafka topic; Flink reads from that topic.
-
Via Delta Lake/Hudi: Spark writes to a table; Flink reads the changes (CDC) from that table.
Example: Streaming Pipelines for AI
Consider a fraud detection system for a bank:
-
Ingest: Transaction data flows into Kafka-powered dataflows.
-
Train (Spark): Every night, Spark reads the last 30 days of data from the Data Lake to retrain and improve the fraud detection model.
-
Serve (Flink): The updated model is pushed to the Flink cluster. Flink consumes live transactions from Kafka, applies the new model, and blocks fraudulent cards in milliseconds.
Confluent’s data streaming platform brings Kafka and Flink processing together to unlock exactly these kinds of use cases. Get started for free.
Spark Streaming vs Flink – FAQ
Can I use Flink with Spark?
Yes. They are often used in complementary architectures. For example, Spark might handle batch data preparation and ML model training, while Flink consumes the live event stream to perform real-time feature engineering and inference based on the Spark-trained model.
Which tool is more cloud-native: Spark or Flink?
Flink is generally considered more cloud-native due to its stream-first architecture and robust, built-in state management, which integrates well with modern elastic orchestrators like Kubernetes. While Apache Spark is highly cloud-friendly with mature integrations across all major platforms, Flink's design lends itself more easily to fully serverless and elastic streaming deployments.
Can I run Flink on Kubernetes?
Yes. Flink is highly cloud-native and is often deployed using the Flink Kubernetes Operator, which handles deployment, scaling, and fault management for Flink jobs within a container orchestration environment. This simplifies cluster deployment, management, and resource scaling for long-running, stateful stream processing jobs. With Confluent Cloud for Apache Flink®, you don't need to set up any infrastructure. Everything is handled by Confluent.
Is Flink harder to learn than Spark?
Flink often presents a steeper initial learning curve than Spark. This is because Flink requires a deeper understanding of true stream processing concepts like event time, watermarks, and complex windowing to ensure correct results. Spark's core APIs and the micro-batch model of Structured Streaming are often more immediately intuitive for developers familiar with traditional batch processing.
Can Flink process batch and streaming data together?
Yes, Flink is fundamentally designed for unified batch and stream processing. Its core architecture treats batch data as simply a finite stream, allowing the same API (like the Table/SQL API) to be applied to both bounded (batch) and unbounded (streaming) data. This unified approach is highly efficient for building consistent, modern ETL/ELT pipelines.
How does Spark Structured Streaming compare to Flink SQL?
Spark Structured Streaming uses a micro-batch approach and Spark SQL to provide near real-time results, leveraging a familiar batch-like model. Flink SQL uses true event-at-a-time processing with native support for state, event time, and watermarks, making it superior for achieving very low latency (tens of milliseconds) and correctly handling out-of-order events.