New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Stories from the Front: Lessons Learned from Supporting Apache Kafka®
Here at Confluent, our goal is to ensure every company is successful with their streaming platform deployments. Oftentimes, we’re asked to come in and provide guidance and tips as developers are getting off the ground with Apache Kafka. Because we’re down in the trenches with users every day, we’re sharing our lessons learned with the community so they can adjust their operational strategy to avoid some of the most common pitfalls. Kafka is a solid product, but any system has its operational pitfalls. In this post, I’m going to describe three scenarios that we frequently see on the front lines:
- Under-replicated partitions continue to grow inexplicably
- Kafka liveness check and automation causes full cluster down
- Adding a new broker results in terrible performance
Each story includes high level recommendations to help you keep your Kafka up and running successfully.
Under-replicated Partitions Continue to Grow Inexplicably
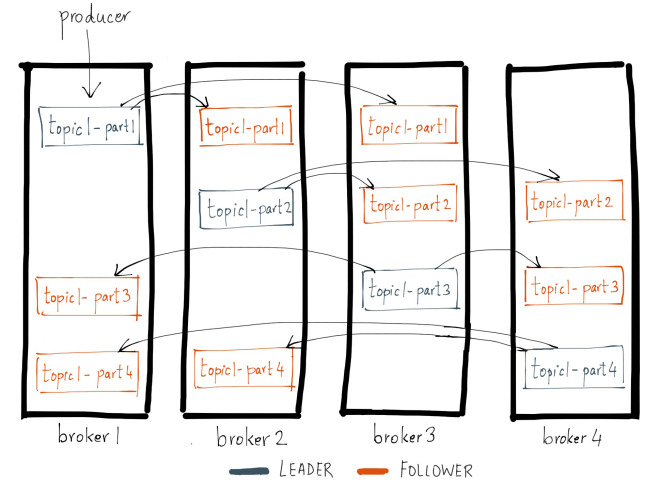
Example of inter-broker replication in a health cluster from Neha Narkhede’s blog.
It’s the middle of the night and the pager goes off. “Kafka In Sync Replica Alert?” Didn’t that happen last week too? Yes, but before, the issue self-corrected before you even opened up the monitoring dashboard. This time, it’s still there. Time to call Confluent support and get things sorted out, because under-replication is a quick hop away from data loss. However, because nothing in the cluster has changed, what will you even tell support? Faithfully, they jump on a call with you. Network threads look stable but processing times are long for some request types. The number of incoming requests had ticked up right before the issue happened. Time to pull in the application teams. Ten people on this call now and no one changed anything. So what happened last week when the first alert came in and went away on its own? A broker upgrade. The downlevel clients are slowing down the broker because of a blocking call that was fixed in a later version. The application team had an uptick in data load tonight, causing the broker to backup with message conversion. In that state, it was unable to serve replication requests efficiently. A fix pack install on the broker side and things run smoothly again.
Moral: Always chase root causes for in-sync replica list shrinks. It’s the “canary in the coal mine,” and understanding the reason for it helps with long term cluster stability.
Kafka Liveness Check and Automation Causes Full Cluster Down
Two months ago, a new initiative came down from the VP to automate all infrastructure operations. Tasked with this for your shiny new cloud deployment of Kafka, you implemented a liveness check simply by seeing if the broker’s client serving port was open. If it’s not open, or the request times out, your automation just restarts the broker. Well, it doesn’t really restart the broker; in reality it’s tearing down the docker container where the broker JVM resides, but this is modern infraops, so it should be ok. But today, the one broker keeps getting restarted by the automation, and is setting off all kinds of alerts. Because it’s getting close to the end of the day, time to just bring down the whole cluster and start fresh. You tell the application team everything will be back up in five minutes and shut down all of the brokers, tearing down each one’s docker container and sending SIGKILL out to any process that will listen.
Next, it’s time to start everything back up. The docker containers provision, the brokers start up, and that one broker keeps on restarting again. However, this time none of the brokers are serving, and without the JMX metrics to monitor liveness, all you can see is the applications aren’t getting their data through. Support jumps on and advises you to wait because the cluster has 10,000 partitions, and the controller needs time to process each one. Meanwhile, the one problematic broker is still restarting. As it turns out, the host where the liveness check is running actually can’t reach that broker’s host at all! You look at the logs, the broker seems fine, so you turn off the liveness check. One hour later, the application team can resume business.
Moral: Stateful distributed systems and blind restarts do not mix. Automate your alerts but let the humans take the action.
Adding a New Broker Results in Terrible Performance
Today you’ve finally gotten the login on that new Linux server you’ve been waiting for and now it’s time to push another Kafka broker into production. What an exciting day! You’ve been preparing in a staging cluster, but you read the cluster expansion documentation thoroughly, and it was a simple enough process. Install the broker software, spin it up, and assign some partitions. Done, and time to grab a coffee! Ten minutes later you return to a dashboard of latency problems, chat alerts from the downstream teams about missing SLAs, and your perfectly happy cluster has become a network-saturated mess. You file a support P1 and cling to sanity while you respond to the thirtieth message in three minutes.
Support comes back with one question: “How many partitions did you reassign?” Well, you just ran the same command as you did in staging, so why should that matter? Frantically, you check the JSON from the partition reassignment tool and do some grep-fu to figure out how many partitions you just reassigned. 2,500? That can’t be right. How many moved in the stage cluster? 48. Support advises you to stay the course and let the reassignment finish. After that, everything will work just fine, but it’s going to take a few hours. You sigh and go grab another cup of coffee. You are going to need it.
Moral: Know how much data you are moving before you move it. Don’t just copy commands. Alternatively, use Confluent auto data balancer to help you move data around the cluster more safely!
In Summary
As simple as these problems may seem, they are some of the most common support calls we receive. The Confluent support team works hard to provide you the means to help run your streaming platform efficiently and effectively. That means sharing both our tooling and our experiences. If you have any tips of your own, we’d love to hear about them, and to help find ways to assist in keeping you off the battlefield so the streams keep flowing.
If you want to avoid these and other challenges faced when operating Kafka in your organization, consider a subscription to Confluent Platform. This subscription gives you access to the engineers and operations teams who can keep your Kafka systems running smoothly.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





