New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Machine Learning and Real-Time Analytics in Apache Kafka Applications
The relationship between Apache Kafka® and machine learning (ML) is an interesting one that I’ve written about quite a bit in How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning.
This blog post addresses a specific part of building a machine learning infrastructure: the deployment of an analytic model in a Kafka application for real-time predictions.
Model training and model deployment can be two separate processes. However, you can also use many of the same steps for integration and data preprocessing because you often need to perform the same integration, filter, enrichment, and aggregation of data for model training and model inference.
We will discuss and compare two different options for model deployment: model servers with remote procedure calls (RPCs), and natively embedding models into Kafka client applications. Our example specifically uses TensorFlow, but the underlying principles are also valid for other machine learning/deep learning frameworks or products, such as H2O.ai, Deeplearning4j, Google’s Cloud Machine Learning Engine, and SAS.
TensorFlow – An open source library for machine learning/deep learning
TensorFlow is an open source software library for high-performance numerical computation. Its flexible architecture allows for the easy deployment of computation across a variety of platforms (CPUs, GPUs, TPUs, etc.), from desktops to clusters of servers to mobile and edge devices. Originally developed by researchers and engineers from the Google Brain team within Google’s AI organization, it comes with strong support for machine learning and deep learning, and is used across many domains. TensorFlow is a whole ecosystem, and not just a single component.
Given that this blog post focuses on model serving, we are primarily interested in the SavedModel object, which stores a trained model and TensorFlow Serving as the model server:
A SavedModel is essentially a binary file, serialized with Protocol Buffers (Protobuf). Generated classes in C, Python, Java, etc., can load, save, and access the data. The file format is either human-readable TextFormat (.pbtxt) or compressed binary Protocol Buffers (.pb). The graph object is the foundation of computation in TensorFlow. Weights are held in separate checkpoint files.
Since we are focusing on the deployment of a TensorFlow model, how the model was trained beforehand does not matter. You can either leverage a cloud service and integration pipeline like Cloud ML Engine and its Google Cloud Platform (GCP) ecosystem, or build your own pipeline for model training. Kafka can play a key role not just in model deployment, but also in data integration, preprocessing, and monitoring.
Stream processing with model servers and RPC
A model server is either self-managed or hosted by an analytics vendor or cloud provider. Model servers do not just deploy and cache models for model inference but they also provide additional features like versioning or A/B testing. Communication from your application to the model server is typically done with an RPC via HTTP or gRPC. This request-response communication between the Kafka application and the model server happens for every single event.
Many model servers are available. You can choose from open source model servers like Seldon Server, PredictionIO, and Hydrosphere.io, or leverage model servers from an analytics vendor like H2O.ai, DataRobot, IBM, or SAS.
This articles uses TensorFlow Serving, the model server from TensorFlow. It can either be self-hosted, or you can use the Cloud ML Engine service. TensorFlow Serving possesses the following characteristics:
- Contains gRPC and HTTP endpoints
- Performs model versioning without changing any client code
- Schedules grouping individual inference requests into batches for joint execution
- Optimizes inference time for minimal latency
- Supports many servables (a servable is either a model or a task for serving the data that goes along with your model):
- TensorFlow models
- Embeddings
- Vocabulary lookup tables
- Feature transformations
- Non-TensorFlow-based models
- Is capable of canarying and A/B testing
Here is how a Kafka application and model server communicate:
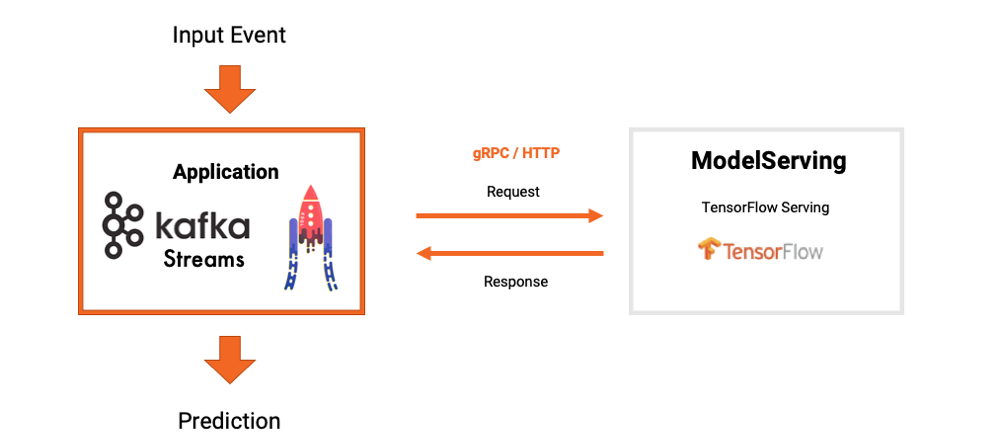
The process for implementing a Kafka application is straightforward. Here are the code snippets for a Kafka Streams application and the RPC to TensorFlow Serving:
1. Import Kafka and the TensorFlow Serving API:
2. Configure the Kafka Streams application:
3. Perform an RPC to TensorFlow Serving (and catch exceptions if the RPC fails):
4. Start the Kafka application:
You can find the full example of model inference with Apache Kafka and Kafka Streams using TensorFlow Serving on GitHub.
Stream processing with embedded models
Instead of using a model server and RPC communication, you can also embed a model directly into a Kafka application. This can either be a Kafka-native stream processing application leveraging Kafka Streams or KSQL, or you can use a Kafka client API like Java, Scala, Python, or Go.
In this case, there is no dependency on an external model server. The model is loaded within the application, for instance using the TensorFlow Java API within a Kafka Streams application:
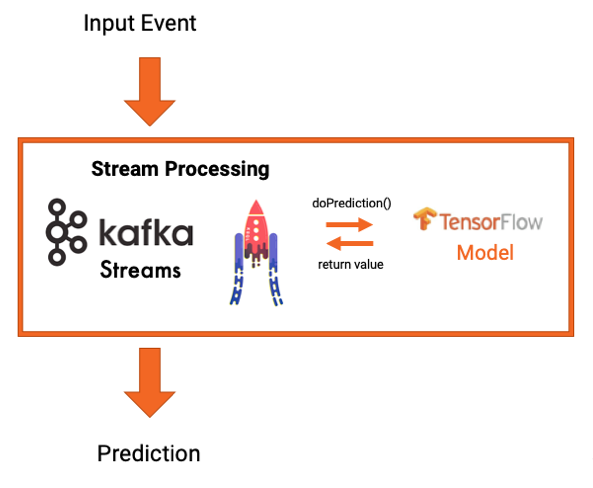
Again, implementing a Kafka application is straightforward. Here are the code snippets for embedding a TensorFlow model within a Kafka Streams application for real-time predictions:
1. Import Kafka and the TensorFlow API:
2. Load the TensorFlow model—either from a datastore (e.g., Amazon S3 link) or from memory (e.g., received from a Kafka topic):
3. Configure the Kafka Streams application:
4. Apply the TensorFlow model to streaming data:
5. Start the Kafka application:
Additional examples of embedding models built with TensorFlow, H2O, and Deeplearning4j into a Kafka Streams application are available on GitHub.
You can even write unit tests by using well-known testing libraries, as shown in this example of a unit test using JUnit and Kafka Streams test libraries.
And below is an example of model deployment using a KSQL user-defined function (UDF):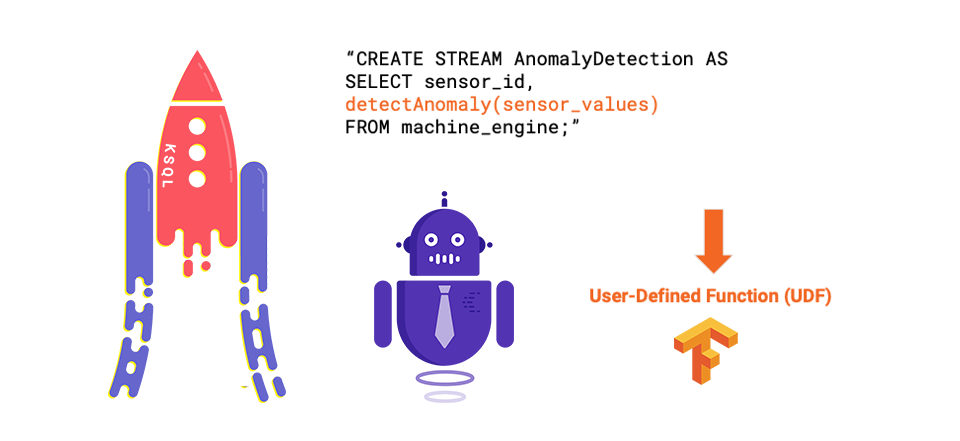
All you need to do is implement the KSQL UDF Java interface and then deploy the UDF to the KSQL server. A detailed explanation of how to build your own KSQL UDF is described in a previous blog post. With this approach, the end user writes SQL queries to apply the analytic model in real time.
What models should be directly embedded into an application?
Not every model is ideal for embedding into an application. Considerations to think about when deciding whether or not embedding makes sense include:
- Model performance: faster is better
- Model binary format: in the best case, it is compiled Java bytecode
- Model size: less MB and less memory is preferred
- Model server features: out of the box vs. build it yourself vs. not needed
Models written in Python code are slow because it is a dynamic language that has to interpret many variables and commands at runtime.
H2O Java classes (e.g., decision trees) execute very fast, often in microseconds.
A small TensorFlow Protobuf neural network with with just a few MB or less loads quickly.
A large TensorFlow Protobuf neural network with 100 MB or more requires lots of memory and provides relatively slow execution.
Standards-based models (e.g., XML/JSON, based on PMML or ONNX) include other steps beyond model processing like data preprocessing. It often presents organizational challenges and technical limitations/constraints to use these standards, and performance is typically worse than the natively serialized models like TensorFlow’s SavedModel.
Ultimately whether or not a model should be embedded directly into your application depends on the model itself, your hardware infrastructure, and the requirements of your project.
Rebuilding the features of a model server in a Kafka application is not hard
Embedding the model into an application means that you do not have the features of a model server out of the box. You would have to implement them by yourself. The first question to ask yourself is: do I need the features of a model server? Do I need to update my model dynamically? What about versioning? A/B testing? Canary?
The good news is that implementing these features is not hard. Depending on your requirements and toolset, you can:
- Start a new version of the application (e.g., a Kubernetes pod)
- Send and consume the model or weights via a Kafka topic
- Load the new version dynamically via the API (e.g., the TensorFlow Java API)
- Leverage a service mesh (e.g., Envoy, Linkerd, or Istio) instead of a model server for A/B testing, green/blue deployments, dark launches, etc.
Let’s evaluate the tradeoffs of both approaches to leveraging analytic models in a Kafka application.
Tradeoffs of a model server vs. embedding a model
You can deploy analytic models into a model server and use RPC communication, or you can embed them directly into your application. There is no best option, because it depends on your infrastructure, requirements, and capabilities.
Why use a model server and RPC together with an event streaming application?
- Simple integration with existing technologies and organizational processes
- Easier to understand if you come from the non-event-streaming world
- Migration later on to real streaming is made possible
- Built-in model management for different models, versioning, and A/B testing
- Built-in monitoring
Why embed a model into an event streaming application?
- Better latency with the local inference instead of needing to do a remote call
- Offline inference (devices, edge processing, etc.)
- No coupling of the availability, scalability, and latency/throughput of your Kafka Streams application with the SLAs of the RPC interface
- No side effects (e.g., in case of failure)—Kafka processing covers everything (e.g., exactly once)
Both options have their pros and cons and are recommended in different cases, depending on the scenario.
Cloud-native model deployment with Kubernetes
In cloud-native infrastructures, it is possible to gain the benefits of both approaches. Let’s use Kubernetes as our cloud-native environment, though other cloud-native technologies can provide similar features.
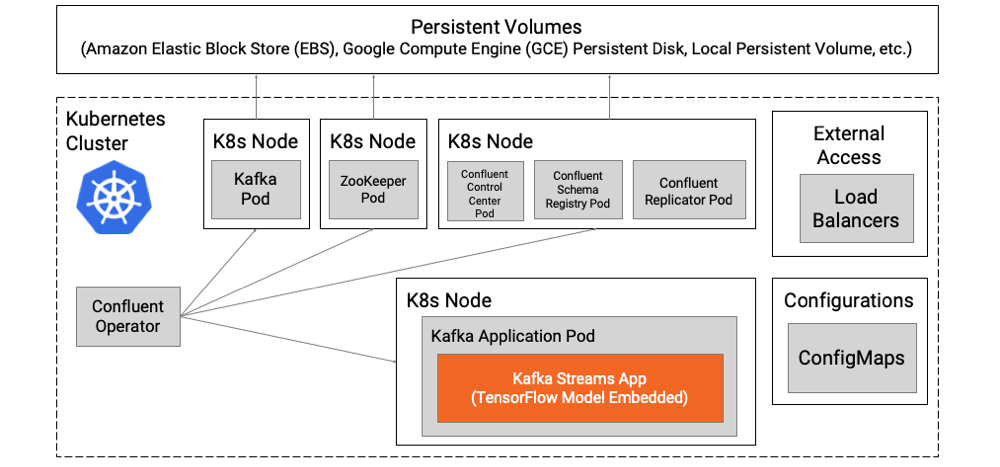
If you embed the analytic model into the Kafka application, you get all the advantages of a separate pod, which has a container for stream processing and model inference. There is no external dependency against a model server.
In the following example, you can scale the Kafka Streams application with the embedded model independently, start a new version, engage in A/B testing or other routing, and perform error handling using cloud-native proxies like Envoy or Linkerd:
If you still want to gain the benefits and features of a model server, then the sidecar design pattern can be used. Kubernetes supports adding additional containers with specific tasks to your pod. In the following example, the Kafka Streams application is deployed in one container and the model server as the sidecar in another container within the same pod.
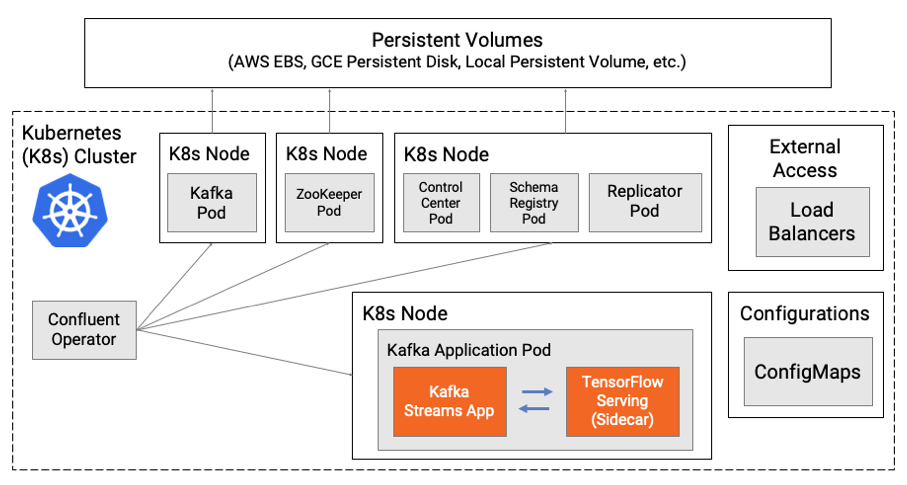
This makes leverage the features of the model server possible, with the robustness and scalability of a single pod. It still has the disadvantage of using an RPC between each container. With both containers deployed in the same pod, you can minimize the latency and potential for error.
Model deployment at the edge
Models are not always deployed in the cloud or in a datacenter. In some cases, models are deployed at the edge. Edge deployment can mean:
- Edge datacenter or edge device/machine
- A Kafka cluster, one Kafka broker, or a Kafka client at the edge
- A powerful client (such as KSQL or Java) or a lightweight client (such as C or JavaScript)
- An embedded or RPC model inference
- Local or remote training
- Legal and compliance implications
For some telecommunication providers, the definition of edge computing is ultra-low latency with under 100 ms of end-to-end communication. This is implemented with frameworks such as the open source cloud infrastructure software stack StarlingX, which requires a full OpenStack and Kubernetes cluster and object storage. For others, edge means a mobile device, lightweight board, or sensor where you deploy very small, lightweight C applications and models.
From the Kafka perspective, there are many options. You can build lightweight edge applications with librdkafka, the native Kafka C/C++ client library that is fully supported by Confluent. It is also possible to embed models within a mobile application using JavaScript and leveraging REST Proxy or WebSocket integration for Kafka communication.
Technology-independent model deployment with Kafka
Model deployment can be completely separated from model training both in terms of the process and technology. The deployment infrastructure can handle different models—even models trained with different machine learning frameworks. Kafka also provides a great foundation for building machine learning monitoring, including technical monitoring of the infrastructure and model-specific monitoring like performance or model accuracy.
Kafka is a great fit and complementary tool for machine learning infrastructure, regardless of whether you’re implementing everything with Kafka—including data integration, preprocessing, model deployment, and monitoring—or if you are just using Kafka clients for embedding models into a real-time Kafka client (which is completely separate from data preprocessing and model training).
Two alternatives exist for model deployment: model servers (RPCs) and embedded models. Understanding the pros and cons of each approach will help you make the right decision for your project. In reality, embedding analytic models into Kafka applications is simple and can be very useful.
For additional details on this topic, have a look at the video recording and slides from my Kafka Summit San Francisco 2019 presentation: Event-Driven Model Serving: Stream Processing vs. RPC with Kafka and TensorFlow.
Interested in more?
To get started with building Kafka applications and deploying analytic models, download the Confluent Platform, a complete event streaming platform built by the original creators of Apache Kafka.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





