New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
How to Build a UDF and/or UDAF in ksqlDB 5.0
ksqlDB is the event streaming database purpose-built for stream processing applications that enables real-time data processing against Apache Kafka®. ksqlDB makes it easy to read, write and process streaming data in real time, at scale, using SQL-like semantics. ksqlDB already has plenty of available functions like SUBSTRING, STRINGTOTIMESTAMP or COUNT. Even so, many users need additional functions to process their data streams.
ksqlDB now has an official API for building your own functions. As of the release of Confluent Platform 5.0, ksqlDB supports creating user-defined scalar functions (UDF) and user-defined aggregate functions (UDAF). All it takes to write your own is just one Java class. The UD(A)F can embed any additional dependencies (like additional JARs or other binaries) if needed.
In this blog post, we’ll discuss the main need and motivation for UD(A)Fs in ksqlDB, show an advanced example with a deep-learning UDF, prove how easy it is to build even something that is very powerful and identify some issues that you might face during development and testing.
Motivation for ksqlDB UDFs/UDAFs
Let’s first discuss what UD(A)Fs are and why you might need to build your own ones.
Built-in ksqlDB functions to process streaming data
Functions are one of the key components in ksqlDB. Functions in ksqlDB are like functions, operations or methods in other SQL engines or programming languages, such as Java, Python or Go. They accept parameters, perform an action—such as a complex calculation—and return the result of that action as a value. They are used within a KSQL query to filter, transform or aggregate data.
Many functions are already built into ksqlDB, and more are added with every release. We distinguish them into two categories: stateless ksqlDB scalar functions and stateful ksqlDB aggregate functions.
But what do you do if you miss a specific function in the ksqlDB syntax? Pretty simple: You build your own one with the official ksqlDB API. Let’s see how easy it is to write your own stateless UDF or stateful UDAF.
UD(A)Fs in ksqlDB
In contrast to built-in functions, UD(A)Fs are functions provided by the user of a program or environment. A UD(A)F provides a mechanism for extending the functionality of the ksqlDB engine by adding a function that can be evaluated in a standard query language statement. Using a UD(A)F in ksqlDB looks exactly like using built-in functions in ksqlDB. Both are registered to the ksqlDB engine before startup. They expect input parameters and return output values.
Here is an example of the built-in function STRINGTOTIMESTAMP to convert a string value in the given format into the BIGINT value representing the timestamp:
This function takes the timestamp 2017-12-18 11:12:13.111 (data type: String) and converts it to 1513591933111 (data type: BigInt).
Now let’s take a look at the steps to build your own UDF to use it in your ksqlDB statements the same way as the STRINGTOTIMESTAMP function does above.
Deep-learning UDFs for anomaly detection
Building ksqlDB UDFs is easy, no matter if they are simple or powerful. With that in mind, let’s take a look at the steps to develop, test and deploy a new ksqlDB UDF.
Steps to create, deploy and test a ksqlDB UDF
You can build very simple ksqlDB functions like a specific scalar function for multiplication (see Confluent documentation to find out how), a really powerful function with many computations or aggregations, or anything in between these two extremities. Creating a stateful UDAF works the same way, of course.
The example below shows you how to build a more advanced UDF, which embeds an analytic model (i.e., an external dependency). This sounds complex, but in reality the implementation is simple. We write one Java class, add the dependency, write our business logic and build an uber JAR which includes the UDF and its dependency. This UDF can be deployed to the ksqlDB server(s) and then used in ksqlDB statements by end users without any coding in a programming language.
Java source code of the deep-learning UDF
Develop a UDF is quite easy, too. Just implement the function in a Java method within a Java class and add the corresponding Java annotations:
Here is the full source code for the anomaly detection ksqlDB UDF:
As you can see, you can really focus on implementing the business logic. In my example, I consume new events and do stateless processing by applying an analytic model. The prediction is returned immediately. Under the hood, ksqlDB receives events from a Kafka topic and sends the output to another Kafka topic.
The wrapper code for the UDF is minimal. You only need to add two annotations and the corresponding import statements to your POJO (plain old Java object):
- Import io.confluent.ksql.function.udf.Udf and io.confluent.ksql.function.udf.Udf
- @UDFDescription: class annotation to describe the name and functionality of the UDF
- @UDF: method annotation to describe the functionality of the specific method (there can be more than one of these methods in a UDF class to process different interface signatures)
And that’s it. The annotations in this class make sure the ksqlDB server interprets this class correctly and loads the UDF into the runtime engine during startup.
Deployment to ksqlDB server(s)
The deployment of the UDF is pretty straightforward, no matter if you’re using a local installation on your laptop or a cluster of remote ksqlDB servers:
- Build an uber JAR that includes the ksqlDB UDF and any dependencies. Typically, you use a build tool like Apache Maven™ or Gradle to do this. See the pom.xml of my GitHub project for an example using Maven.
- Copy the uber JAR to the ext/ directory that is part of the ksqlDB distribution. The ext/ directory can be configured via the property ksql.extension.dir in ksqlDB configuration file ksql-server.properties. If this directory does not exist yet, simply create a new directory.
- Start/restart your ksqlDB server instance(s) to pick up new UD(A)Fs.
- Try out the new UDF in ksqlDB command line interface via Confluent REST Proxy or Confluent Control Center’s KSQL user interface, which has nice features like autocompletion.
- If the UDF does not work, check the log’s errors. They will appear in the ksqlDB server log (ksql.log).
Working demo: MQTT sensor analytics with Apache Kafka and ksqlDB
Let’s now think about a practical example for a powerful UDF: continuous processing of millions of events from connected devices, specifically in the case of car sensors.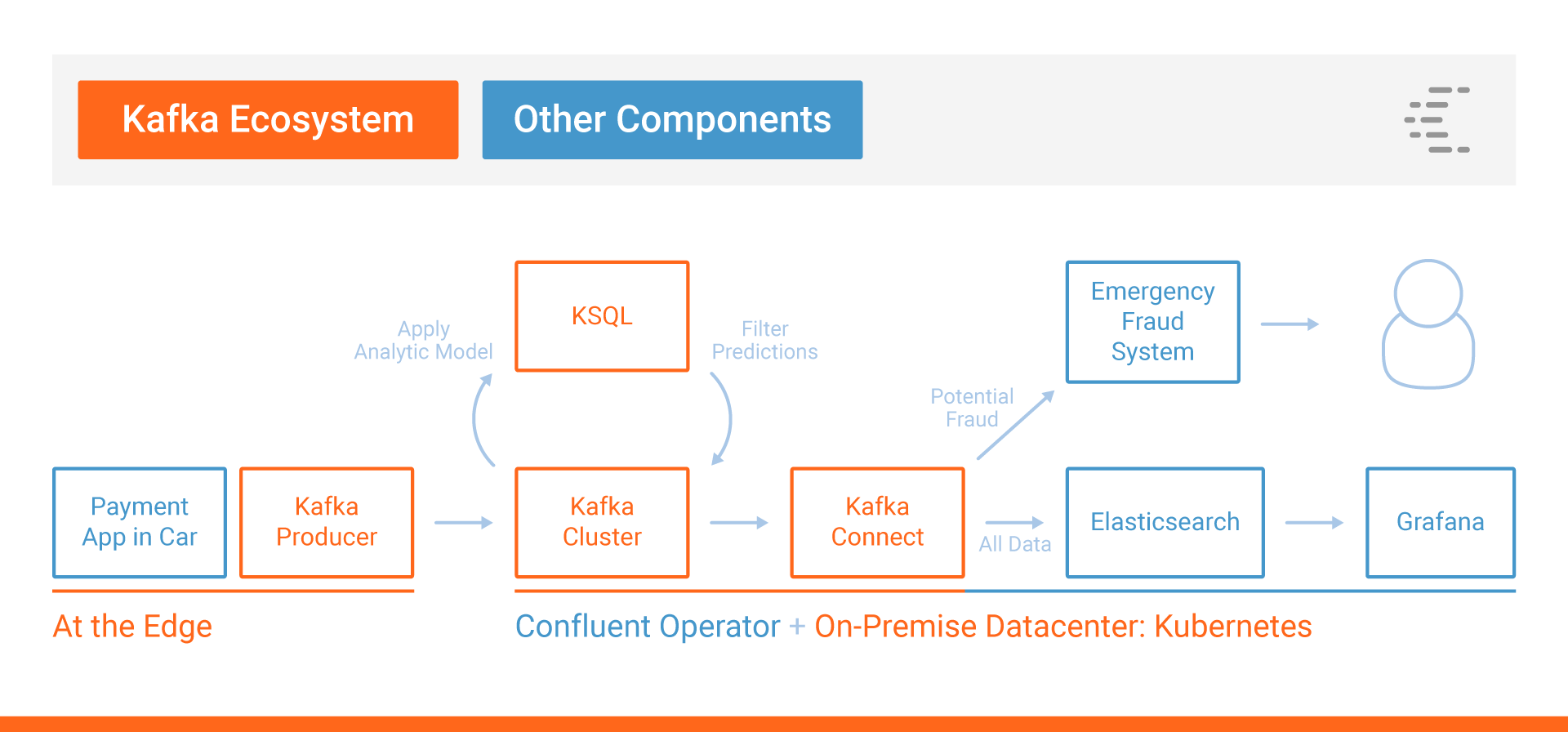
This use case leverages a UDF that does real-time predictions using an autoencoder neural network to detect anomalies. You can apply the analytic model by executing the ksqlDB statement in which “anomaly” is the UDF:
You can also create a new ksqlDB stream to deploy the statement for continuous processing. The following example filters values over a specific threshold of five to send alerts if an anomaly occurs:
This ksqlDB stream AnomalyDetectionWithFilter scales like any other ksqlDB or Kafka Streams application. It is built for S, M, L, X and XXL scenarios. If you need higher scalability or better throughput, simply create additional instances on ksqlDB servers.
If you want to try out this machine-learning UDF, just go to my GitHub project. It includes the source code and a step-by-step guide to test it using Confluent CLI and Confluent MQTT Proxy. The project also includes a MQTT sensor generator.
The story around building and deploying analytic models with ksqlDB is a very interesting and compelling use case worth discussing in further detail, but I’ll save that discussion for a future blog post that covers model training, deployment and inference in greater depth.
Potential issues during development and testing
During development and testing, I faced some challenges when creating my first UDF with the new ksqlDB REST API. If your UDF does not work, check for the following:
- Compile errors? Did you include ksqlDB JAR into your project to use the classes and annotations? Either add ksql-udf.jar, which you get from a ksqlDB project build, or add it via Maven dependency (groupId: io.confluent.ksq; artifactId: ksql-udf).
- Classpath errors at runtime? Are dependencies missing in the generated uber JAR? Extract the JAR and see if all needed dependencies are included (e.g., the analytic model in my example) and in the expected directory. Maybe your build process is not working well yet.
- UDF not found at runtime? Do you see the error, “Can’t find any functions with the name XYZ”? Did you restart the ksqlDB server after you added the uber JAR to the /ext directory? UDFs are only loaded during the startup of the ksqlDB engine. Or, perhaps you have the wrong path? Did you configure the right path in property ksql.extension.dir in ksql-server.properties? Maybe start with an absolute path first. If that works, you can try a relative path.
- Still experiencing problems? Check the logs—not just the ksqlDB log (ksql.log) but also other Kafka-related log files.
Please let us know if you face any other issues during development and testing of ksqlDB UDFs. All feedback is appreciated. While this blog post focused on building a stateless UDF, the development process is the same for a stateful UDAF.
What’s next for ksqlDB UD(A)Fs?
The foundation is here. You’ve learned how easy it is to create and deploy a new UD(A)F for ksqlDB, involving only a few steps to implement, register and execute a ksqlDB UDF. Once the developer builds it, then every end user of your ksqlDB instances can leverage it whether they’re a data engineer or data scientist.
The example of building a deep-learning UDF shows how you can even include other dependencies, such as an analytic model, to build very powerful functions. The end user just has to call the function in the ksqlDB statement—no need to understand what is going on under the hood.
The next step in the ksqlDB UD(A)F roadmap is to support building UD(A)Fs with programming languages other than Java. This way, even a data scientist who only understands Python or JavaScript can write and deploy their own functions. In addition to this, there are many new and exciting features to come, so be sure to keep an eye out for the next ksqlDB releases.
Interested in more?
- Download Confluent Platform and follow the quick start
- Learn about ksqlDB, the successor to KSQL
- Ask questions in the community Slack group
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Real-Time Hyper-Personalization in 2026: Architecture Guide
Batch CDPs can't capture user intent as it forms. By the time a nightly sync runs, the moment is gone. This guide covers the streaming architecture behind real-time personalization, from sub-100ms ad bidding to cross-channel orchestration, with recommendation patterns built on Kafka and Flink.
How to Eliminate Training-Serving Skew With a Unified Real-Time Streaming ML Pipeline (2026 Guide)
Separate batch and streaming pipelines for ML features cause training-serving skew. DoorDash measured a 35.7% feature mismatch in their dual setup. This guide covers a unified kappa architecture using Flink to compute features once for both training and serving, plus a 2026 tooling comparison.