New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Log Compaction – Highlights in the Apache Kafka® and Stream Processing Community – May 2017
We are very excited to share a wealth of streaming news from the past month!
If you are looking for an ideal streaming data service that delivers the resilient, scalable streaming platform that is Apache Kafka® and is deployable within minutes, then look no further. Confluent launched Confluent CloudTM targeted to cloud-first developers and enterprises transitioning to the cloud. Confluent Cloud will be shipping as a generally available service later this year. If you’re excited about trying it out on your application, you can apply for early access.

Where did we announce this news? Well, at the Kafka Summit in NYC, of course! You can catch up on all the Kafka Summit sessions from the conference website.
The next Kafka Summit is in San Francisco on August 28, 2017, and it has a packed speaker schedule across several technical tracks. We have closed the call for papers and have received 176 submissions, seven times the number of available speaking slots, which means the Summit committee is now busy selecting the best from the best! Please register for Kafka Summit SF before the conference sells out.
Feature freeze for Kafka release 0.11.0.0 happened on May 17 and the GA is fast approaching. There were many Kafka Improvement Proposals (KIPs) discussed. Among those planned for the upcoming release are:
- Exactly Once Semantics (EOS), which enables Kafka to become a replacement for traditional messaging systems where no duplicates and delivery guarantees are paramount—something historically difficult in a distributed messaging system
- Java AdminClient provides an API for Kafka administrative operations
- KIP-117: Add a public AdminClient API for Kafka admin operations: top-level KIP for the Java AdminClient
- KIP-133: Describe and Alter Configs Admin API – adds DescribeConfig and AlterConfig Request/Response messages to the wire protocol
- KIP-140: Add administrative RPCs for adding, deleting, and listing ACLs – introduces a wire format representation for ResourceType and AclOperation
- Kafka Connect improvements
- KIP-146: Classloading Isolation in Connect – offers a transparent resolution of dependency conflicts that may arise between the framework and the plugins, as well as between the plugins themselves
- KIP-154: Add Kafka Connect configuration properties for creating internal topics – explicitly creates Kafka Connect internal topics when they don’t already exist, instead of relying on users manually creating them
- Operational Improvements
- KIP-143: Controller Health Metrics – provides metrics to reliably detect controller issues like slow progress or deadlocks
- KIP-156: Add option “dry run” to Streams application reset tool – provides information about the actions which will be performed, without taking the action
Meanwhile, Kafka 0.10.2.1 was released April 27. It provides numerous important bug fixes as documented in the release notes, and it is very easy to upgrade. If you prefer to do rapid development on containers, you can also use our Confluent Docker images.
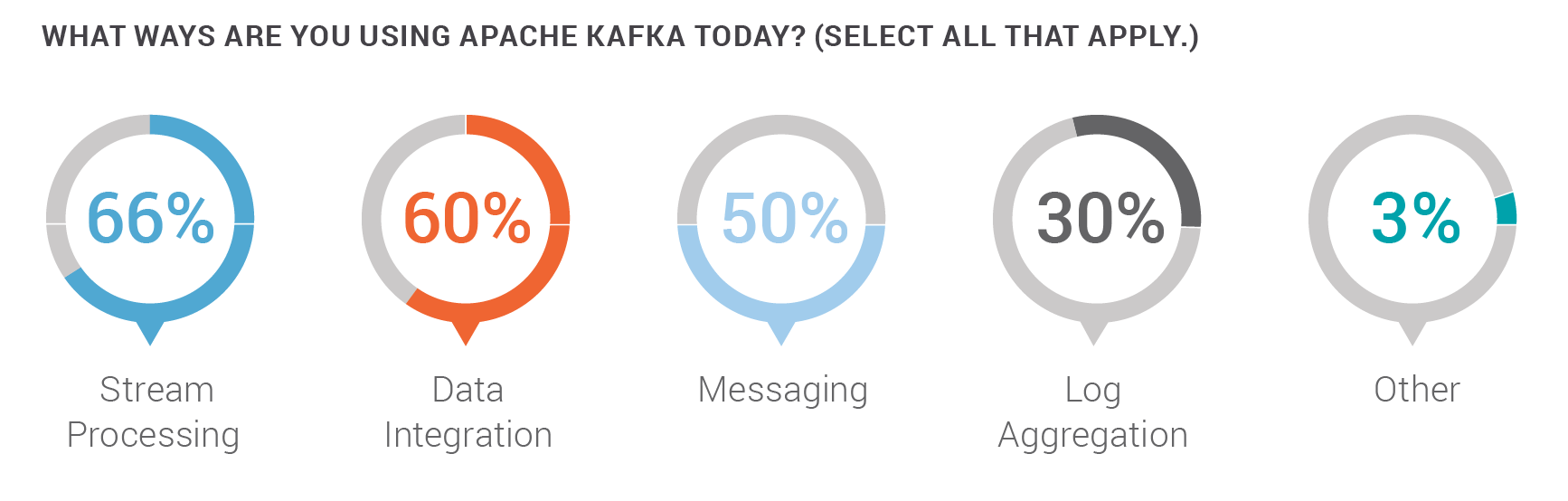
Finally, check out the 2017 Apache Kafka report in which 1 in 4 of the survey respondents work for organizations with more than $1 billion in annual sales, illustrating how quickly this open source technology has gained traction across large enterprises for building data pipelines, microservices, etc. From the report: “This year, we’re seeing organizations use Apache Kafka in many ways: two-thirds (66%) use it for stream processing and three out of five (60%) use it for data integration.”
Notable Blog Posts:
- Microservices are important, Go is deservedly ascendent, and event sourcing continues to come into its own as an architectural paradigm. Hence this post from Semaphore CI.
- WalMart Labs describes an appropriately cautious upgrade to 0.10.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





