New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Applying Data Pipeline Principles in Practice: Exploring the Kafka Summit Keynote Demo
Real-time data streaming necessitates a new way to think about modern data system design. In the keynote at Kafka Summit London 2022, Confluent CEO Jay Kreps described five principles of modern data flow:
- Streaming: Interact with the real world as it’s happening, instead of just batch processing with ad hoc pipelines
- Decentralized: Move and process data scalably and autonomously, versus sequential processing to a centralized data warehouse or with a large number of point-to-point connections
- Declarative: Build data transformations by describing what you need to do and let the infrastructure figure out the right way to do it, instead of more complex development
- Developer-oriented: Leverage modern toolchains in the ecosystem, thereby reducing user friction or exceptions that interfere with development workflows
- Governed and observable: Discover data through catalogs, maintain evolution of schemas, and provide data lineage, which provides enormous benefits over solutions that have ungoverned data and a lack of visibility
This blog post examines the keynote demo presented by Amit Gupta, director of product management at Confluent, in which an airline company merges with another airline company, and wants a data pipeline built on Confluent to enable analytical and operational workstreams (e.g., data science teams can do analytics, customer service teams can notify passengers of delayed flights, etc.). This blog post deconstructs the demo through excerpts of real code that were used to build it, and connects it to the five modern data principles outlined above. After reading, feel free to run this recipe in Confluent Developer which is loosely based on the demo.

Infrastructure as code
In the demo scenario, the airline company has already adopted infrastructure as code (IaC) where all infrastructure is modeled in code. IaC is declarative by nature whereby the user defines the desired state for the resources, allowing the tooling to determine dependencies and execution order, and be eventually consistent. These workflows are developer-oriented and GitOps friendly, meaning the code workflow is checked into a GitHub repository and CI/CD processes can automatically update the infrastructure. It’s especially valuable for managing graduated environments (for example, development → staging → production) so that critical applications can be validated prior to being deployed into production.
The official Confluent Terraform provider enables infrastructure management with declarative configuration files. All changes are documented, approved, and version controlled within the change management process to streamline deployments with timely and effective audits, and ensures security and compliance across environments. Terraform works across multiple cloud providers so that a company can use the best cloud provider given their other business application requirements (or use Cluster Linking to mirror data between cloud providers if they have a multicloud deployment). For example, there may be a core infrastructure team that uses the Confluent Terraform provider to set up an Apache Kafka® cluster in Confluent Cloud:
resource "confluentcloud_kafka_cluster" "flight-data-system" {
display_name = "flight-data-system"
availability = "MULTI_ZONE"
cloud = "${var.cloud_provider}"
region = "${var.cloud_provider_region}"
standard {}
environment {
id = confluentcloud_environment.stream-jet.id
}
}
Once the core infrastructure is provisioned, it can be managed and monitored from the Confluent Cloud console and the health of the cluster is readily observable through integrations with other monitoring solutions like Datadog. Out-of-the-box dashboards provide visibility into the most important metrics for your Kafka clusters.
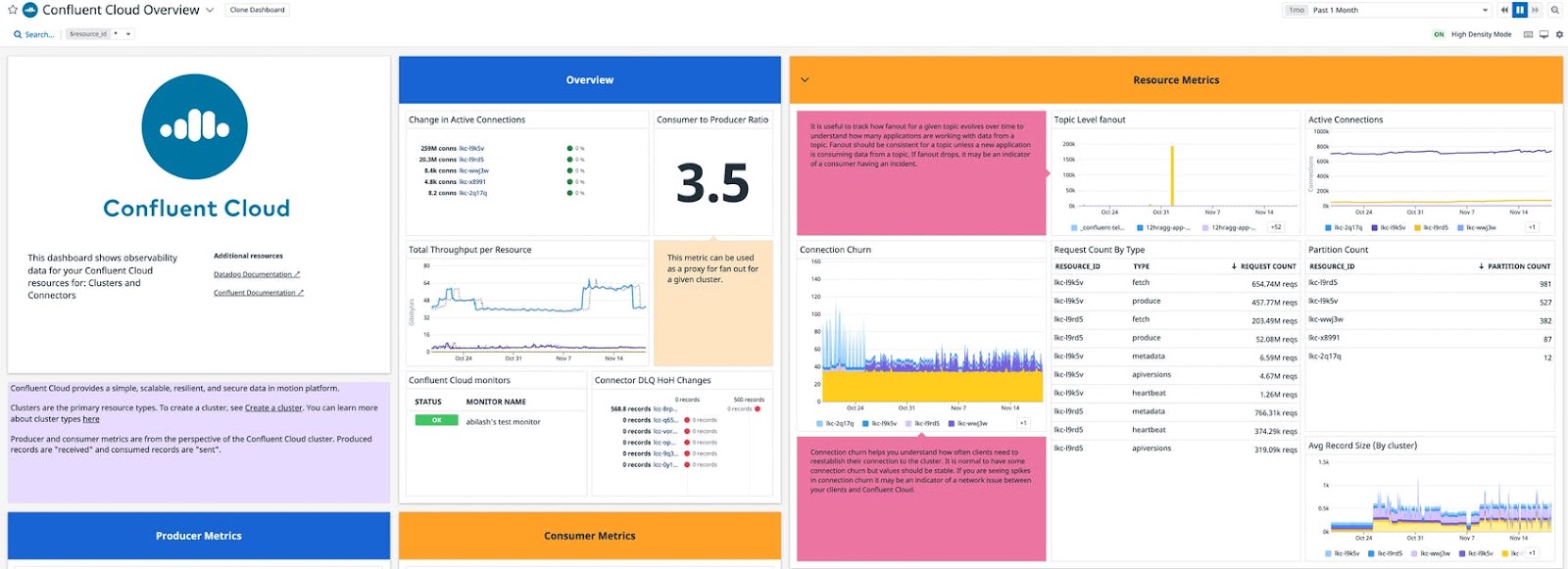
Then the flight data application team uses this cluster to publish real aircraft data, and it does so by using Terraform to set up the application’s Kafka topic called flight-updates with appropriate security access. Then it streams real-time aircraft data (as depicted in the demo at Kafka Summit, it used real aircraft location data from OpenSky Network).
resource "confluentcloud_kafka_topic" "flight-updates" {
kafka_cluster {
id = confluentcloud_kafka_cluster.flight-data-system.id
}
topic_name = "flight-updates"
partitions_count = 4
config = {}
http_endpoint = confluentcloud_kafka_cluster.flight-data-system.http_endpoint
credentials {
key = confluentcloud_api_key.flight-data-system-admin-api-key.id
secret = confluentcloud_api_key.flight-data-system-admin-api-key.secret
}
}
From the Confluent Cloud console, you can see the messages flow into the Kafka topic, including the payload, partition, offset, and timestamp info:
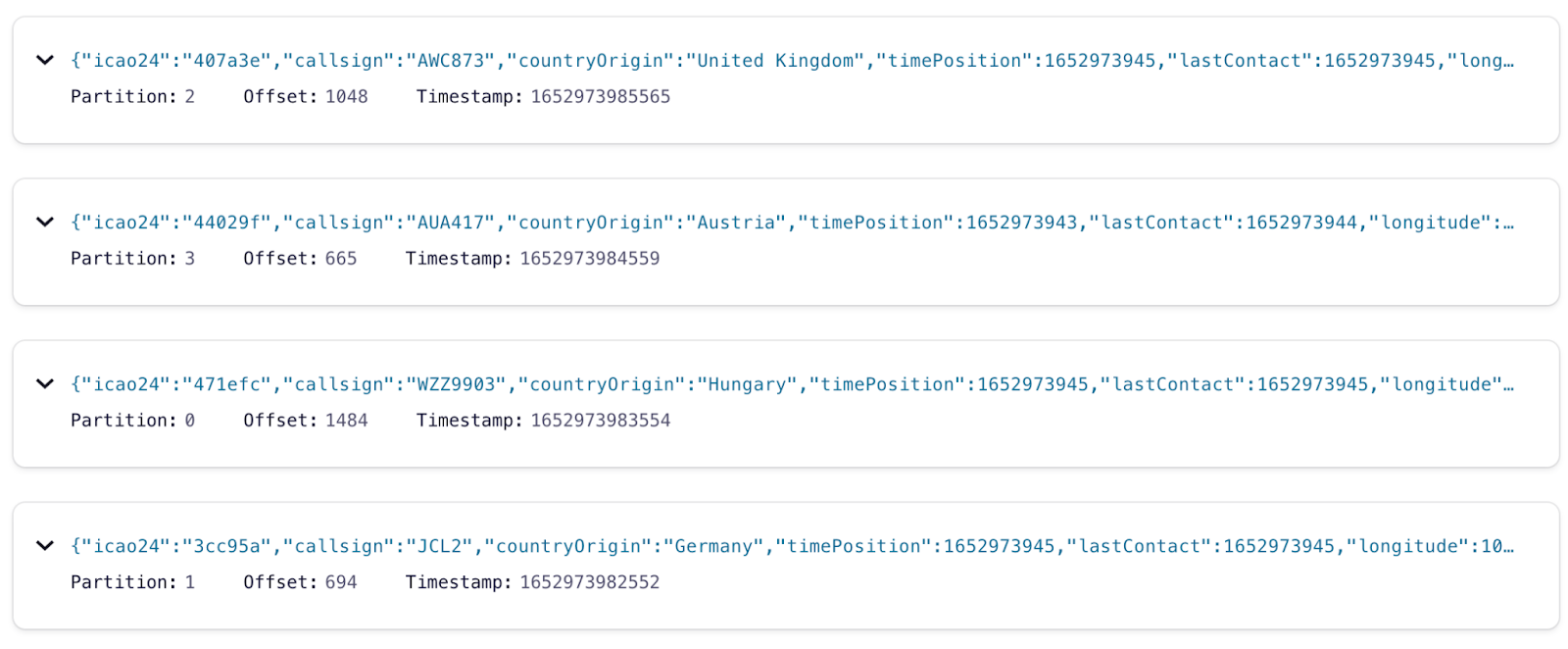
Analytical use cases
The airline company’s data science team wants to process all flight data to make business decisions (e.g., computing flight delays). Their analytics workflow can no longer be relegated to batch processes because it relies on real-time data processing. But as is often the case, organizationally these teams are totally separate: the flight data team is in a totally different part of the business from the data science team. Fortunately, once the flight data is published to Kafka, the data becomes democratized and is available to be acted upon by decentralized streaming applications. The data science team can now run a Snowflake sink connector to read the flight data from Kafka and stream it to their Snowflake data warehouse.

This works as long as there is a proverbial “contract” between the teams so they can consume the same well-shaped data. This agreement on Kafka and schema combination is critical for a decentralized and evolving solution, so there needs to be governance around its usage. Confluent Cloud Schema Registry stores schemas in its repository, and if the schema evolves, it can validate compatibility between versions. This enables the data science team to read anything the flight data team publishes.
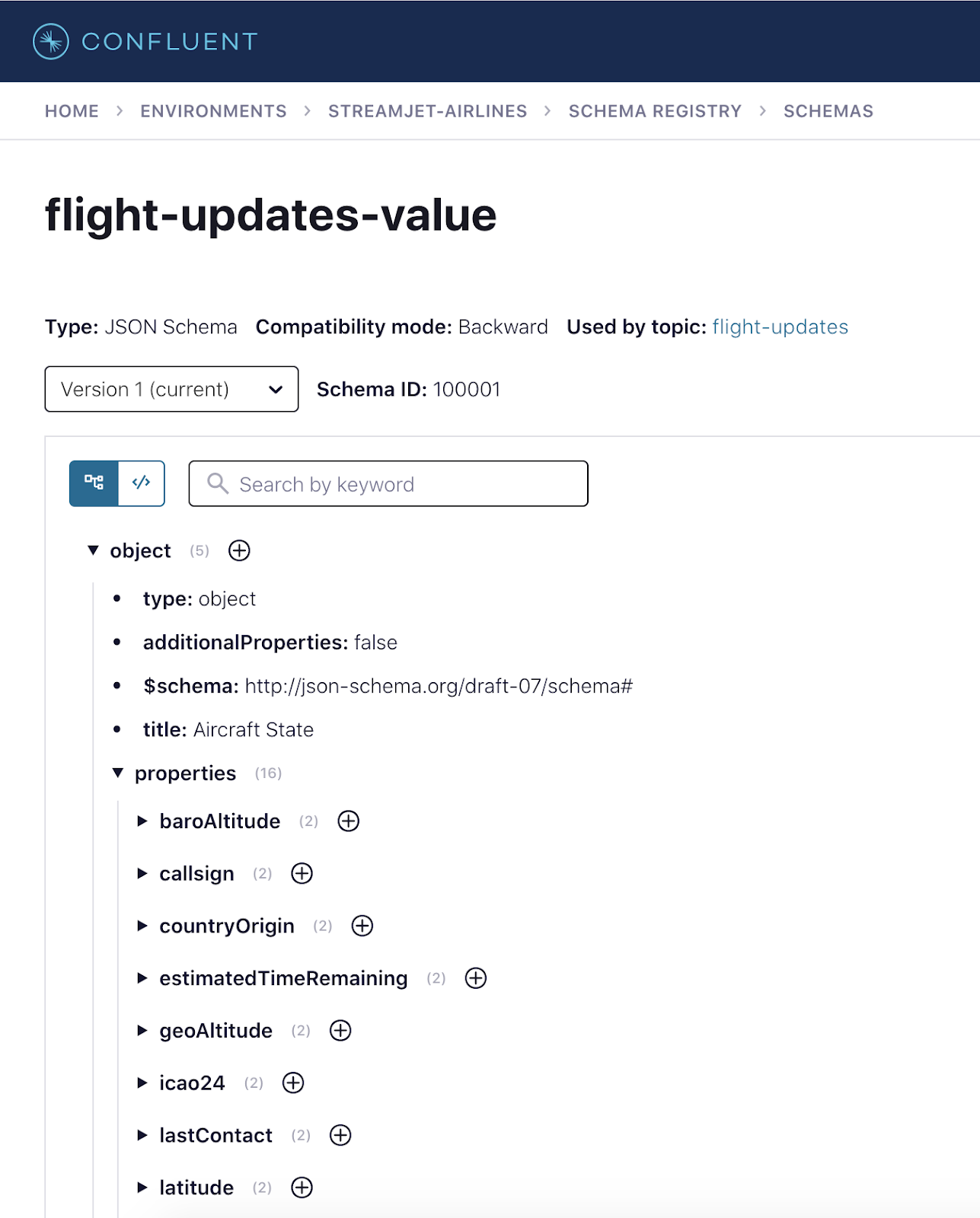
To deploy a connector that writes data from Kafka to Snowflake, the data science team can choose from multiple mechanisms such as the Confluent Cloud console, CLI, or API. Below shows the declarative way using ksqlDB, which should make data scientists familiar with SQL very happy because it’s super easy to build data flows. And if you love ksqlDB so much that you never want to leave it, you can deploy an entire app using SQL (see these sample apps for popular use cases). The configuration below shows the input data format as JSON_SR, assuming the flight data team used this serialization format when publishing.
CREATE SINK CONNECTOR IF NOT EXISTS AnalyticsFlightDataSnowSink WITH(
'topics'= 'flight-updates',
'input.data.format'= 'JSON_SR',
'connector.class'= 'SnowflakeSink',
'name'= 'AnalyticsFlightDataSnowSink',
'kafka.api.key'= '{{KAFKA_API_KEY}}',
'kafka.api.secret'= '{{KAFKA_API_SECRET}}',
'snowflake.url.name'= '{{ACCOUNT_ID}}.snowflakecomputing.com',
'snowflake.user.name'= 'analytics',
'snowflake.private.key'= '{{SNOWFLAKE_PRIVATE_KEY}}',
'snowflake.database.name'= 'ANALYTICS',
'snowflake.schema.name'= 'FLIGHT_DATA',
'tasks.max'= '1'
);
So far, what we’ve built is pretty simple. Unrealistically simple. Yes, there are benefits of it being in the cloud, fully managed, with all the security bells and whistles, but the flight data team could have just written entries directly into Snowflake for the data science team. So you’re probably asking yourself, what’s the big deal? Read on.
Exploding end systems
The answer is manyfold. First, the writer is decoupled from the reader so the flight data team doesn’t have to care whether the data science team uses Snowflake, MongoDB, PostgreSQL, Oracle Database, or all of the above. In fact, they don’t even really need to talk aside from agreeing on a schema. The flight data team can publish data as they get it, and the data science team can read it when they want; they don’t need a whole lot of coordination between the teams beyond a “contract” for the data schema. The two teams are decentralized and can make technical decisions independently as it meets their business requirements. Second, this design enables interconnections between a large number of systems. Without some kind of scalable system, the number of point-to-point data connections explodes and becomes incredibly hard to implement and manage.
Now let’s say the data science team wants to take the flight data and normalize it with data from the bookings team, which includes the bookings and customer information. And since there was a merger between two airline companies, there are actually two different sets of bookings and customer information, for a total of four new data sources. As a result, what started as a simple use case with one data source explodes into a more complex scenario with five data sources that need to be intentionally aggregated.
- Flight updates
- Company 1: Bookings
- Company 1: Customers
- Company 2: Bookings
- Company 2: Customers

Given that all these data sources have different schemas, they need to be denormalized and cleansed before they are processed by other teams. First, fully managed Kafka connectors stream the bookings and customer data from all four data sources into Kafka. Below is one connector example for PostgreSQL, but the connector class varies with the database and a connector would be provisioned for one. Notice again that JSON_SR is specified so that the schemas are centrally stored in Confluent Cloud Schema Registry.
CREATE SOURCE CONNECTOR StreamJetCustomersSource WITH (
'connector.class' = 'PostgresSource',
'name' = 'StreamJetCustomersSource',
'kafka.api.key' = '<id>',
'kafka.api.secret' = '<secret>',
'connection.host' = '{{CONNECTION_HOST}}',
'connection.port' = '5432',
'connection.user' = '{{CONNECTION_USER}}',
'connection.password' = '{{CONNECTION_PASSWORD}}',
'db.name' = 'StreamhJetBookings',
'topic.prefix' = 'StreamJet-',
'table.whitelist' = 'customers',
'mode' = 'timestamp+incrementing',
'incrementing.column.name' = 'rowid',
'timestamp.column.name' = 'updated',
'output.data.format' = 'JSON_SR',
'db.timezone' = 'UTC',
'tasks.max' = '1'
);
With four Kafka topics representing bookings and customer data from two different companies, they can now be denormalized with a streaming application. First, each company’s bookings data is combined with its customer data into a new “enriched” bookings stream with a query using an INNER JOIN, and the fields are reformed in a more logical way. Here is code that does it for one company’s data set (and it would be done similarly for the second company):
CREATE STREAM StreamJet_bookings_enriched WITH (KAFKA_TOPIC = 'StreamJet-bookings-enriched') AS SELECT stream_jet_customers.id, stream_jet_bookings.BK_CALL_SGN, stream_jet_bookings.BK_ID, stream_jet_bookings.BK_BOOK_TME, CONCAT(stream_jet_customers.title, ' ', stream_jet_customers.firstName, ' ', stream_jet_customers.lastName) as BK_CUST_NME, stream_jet_customers.email as BK_CUST_EML FROM stream_jet_bookings INNER JOIN stream_jet_customers WITHIN 1 DAY ON stream_jet_bookings.BK_CUST_ID = stream_jet_customers.id EMIT CHANGES;
Then the denormalized data from each company is merged into a single stream bookings that represents both companies. Because the two companies likely have different schemas from one another, at this time the data can be reshaped into a consistent schema to be leveraged by the downstream teams. Here is code that writes one company’s “enriched” data into the unified bookings stream (and it would be done similarly for the second company):
INSERT INTO bookings
SELECT FLIGHT_CALLSIGN as callsign,
concat('StreamJet-', CAST(STREAM_JET_BOOKINGS_ID AS VARCHAR)) as id,
STREAM_JET_BOOKINGS_ID as source_id,
CUSTOMER_NAME as customer_name,
CUSTOMER_EMAIL as customer_email,
BOOK_TIMESTAMP as book_time
FROM streamjet_bookings_enriched
PARTITION BY FLIGHT_CALLSIGN
EMIT CHANGES;
So far we have taken four different tables representing different companies’ bookings and customer info, denormalized it, cleansed it, enriched it, and created a new authoritative stream called bookings. This unified stream could, in fact, be called a data product, because it is well-formed, trustworthy data treated with first-class status, and it can be confidently shared across different teams in the company. Don’t want the data science team to see the customer info? Redact it on the fly by applying a mask function like MASK_KEEP_RIGHT or writing it all out as all stars:
CREATE STREAM bookings_redacted WITH (KAFKA_TOPIC='bookings-redacted', VALUE_FORMAT='JSON_SR') AS SELECT callsign, id, source_id, '*****' as customer_name, '*****' as customer_email, book_time FROM bookings;
Now this unified stream of trustworthy booking data enables the data science team to do richer processing. And this data flow can also be used with IaC, checked into Git, etc., fitting right in with developer-friendly workflows.
Operational use cases
Next, let’s say there is another team—customer service—and its goals depend entirely on the ability to glean insight from real-time data streams (three in four organizations say they would otherwise lose customers, see Business Impact of Data Streaming: State of Data in Motion Report 2022). They want to operate on the same data as the data science team, because great customer service recognizes that absolutely no one wants to wait at the airport for six hours for a delayed flight. So wouldn’t it be nice if they could notify customers if their flight was going to be delayed…before they leave home? Instead of relying on batch processing for that flight data overnight, it’s important to process it in real time. Fortunately, our data pipeline doesn’t need to be re-engineered to accommodate that task. Customer service can easily process the same flight data from Kafka using whatever logic to determine whether a flight is going to be late. It can be expressed in ksqlDB, as a simple example:
…
WHERE flight_updates.estimatedTimeRemaining IS NOT NULL AND
flight_updates.lastContact > 0 AND
flight_updates.lastContact + flight_updates.estimatedTimeRemaining > routes.scheduled_arrival_time
We can join this streaming late flight data with the unified bookings data to determine the set of customers whose flights are delayed, and write that to a stream called impacted-customers:
CREATE STREAM impacted_customers WITH (KAFKA_TOPIC = 'impacted-customers', VALUE_FORMAT='JSON_SR') AS SELECT bookings.callsign AS callsign, bookings.customer_name as customer_name, bookings.customer_email as customer_email, impacted_flights.delayed_flight_estimated_arrival_time + 1800 as new_estimated_departure_time FROM impacted_flights INNER JOIN bookings WITHIN 1 DAY ON impacted_flights.impacted_callsign = bookings.callsign EMIT CHANGES;
The customer team can run the services of their choice, perhaps an AWS Lambda serverless function that listens for records on the Kafka topic impacted-customers and notifies customers, perhaps Amazon Simple Email Service (SES). All the applications from the ksqlDB applications to the serverless function code can work in their developer-friendly GitOps workflows, use SecretsManager to manage secret data using the same declarative GitOps methodology that is used for all the other resources, and makes customers happy (well, happy to be notified, at least).

From the Confluent Cloud console, developers can trace streams from source to destination. In fact, the more decentralized the architecture is with a federation of data products, the more important governance is to see the streams lineage and validate who has access to which data. The screenshot below shows the entire pipeline and stream processing nodes, from the source connectors to the streams for the data science and customer service teams.
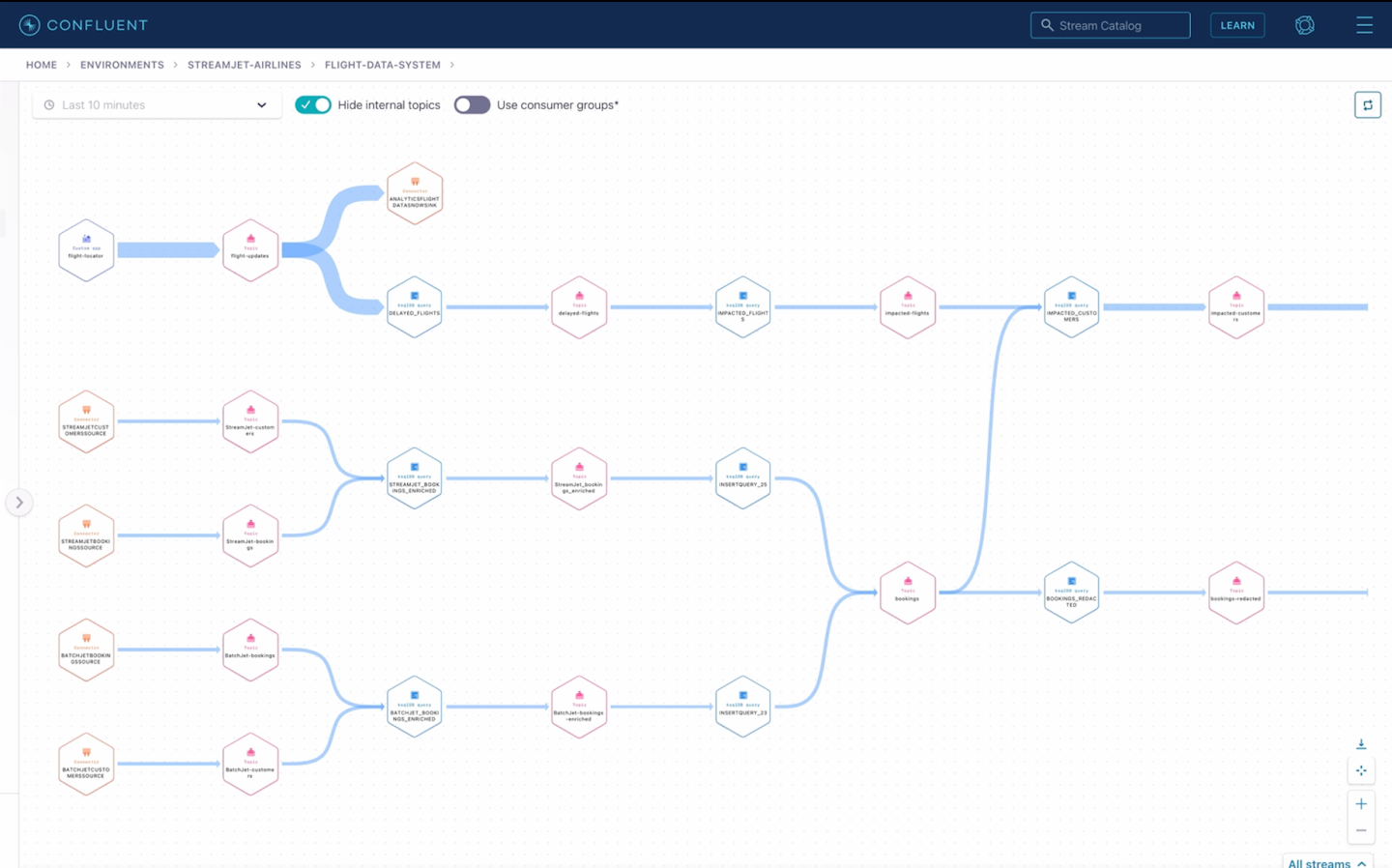
Summary
You can build out analytical and operational workflows based on Confluent with the core principles of modern data flow: streaming, decentralized, declarative, developer-oriented, and governed and observable. To re-create some of the steps described in this blog post, run the recipe “Notify passengers of flight updates” which is loosely based on the demo scenario.

In addition to this recipe, check out the others in the collection of Stream Processing Use Case Recipes which cover a variety of application and pipeline use cases including anomaly and pattern detection, customer 360, cybersecurity, predictive analytics, real-time analytics, logistics and IoT management, real-time alerts and notifications, and infrastructure modernization. The recipes have complete ksqlDB code that is launchable in Confluent Cloud with a click of a button (or adaptable to run on-prem), and you can leverage mock data or real data sources if you’ve got them.
By the way, if you have an interesting use case that showcases these principles and you are inspired to share it with the community, there are several ways to do that:
- Present at Current 2022: The Next Generation of Kafka Summit (the Call for Papers is open until June 26)
- Present at a Kafka Meetup
- Contribute a recipe to the Stream Processing Use Case Recipes
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.