New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Broadcom Modernizes Machine Learning and Anomaly Detection with ksqlDB
Mainframes are still ubiquitous, used for almost every financial transaction around the world—credit card transactions, billing, payroll, etc. You might think that working on mainframe software would be dull, requiring us to use only old languages and tools, but our experience has been just the opposite. Since joining the mainframe division at Broadcom, we’ve had the opportunity to work with many newer technologies, including Kafka, ksqlDB, Apache Cassandra™, graph databases, Docker, machine learning, and others. Our product, Mainframe Operational Intelligence (MOI), is a collection of services that collects performance and health metrics from various products running on mainframes. This helps customers detect and diagnose mainframe issues.
Products running on mainframes can easily generate more than a million metrics per minute. Obviously, most metric values can vary a great deal. Sometimes the variability is caused by expected events, such as increased transactions at Christmastime or employees arriving at work in the morning. Sometimes it’s caused by predictable one-off events, such as tickets going on sale for a concert. And sometimes it’s caused by unpredictable yet still very normal events. For example, somebody might run an ad hoc report that causes a spike in database reads. Filtering out the noise and detecting only meaningful issues are a major challenge.
With MOI, we are working on reducing false positives in this filtering by improving anomaly detection, as well as developing a system that supports customized alarm filtering. We wanted to see whether we could use ksqlDB as the filtering tool, so we built a prototype to try it out.
Overview of MOI
MOI consists of several microservices that work in series. These microservices communicate over Apache Kafka® and use Confluent Schema Registry to manage the Apache Avro™ schemas.
Each microservice has a unique Kafka topic and only consumes messages from that topic. After consuming a message, the microservice then produces a message to send to the next service in the series. Each service’s metrics have a single Avro schema.
Our ksqlDB prototype involves three MOI services:
- Metric Enrichment Service: an upstream service ingests metrics from the mainframe and sends each raw Avro metric to the Metric Enrichment Service, which fills in additional information in the message
- Machine Learning Service: the Machine Learning Service analyzes the enriched metric message, scoring the information and setting a flag to indicate whether the metric is in an alert state
- Alarm Lifecycle Management Service: the Alarm Lifecycle Management Service checks the flag, determining whether an alert state indicates an existing or new incident; if there is no alert state, it closes any appropriate existing incident
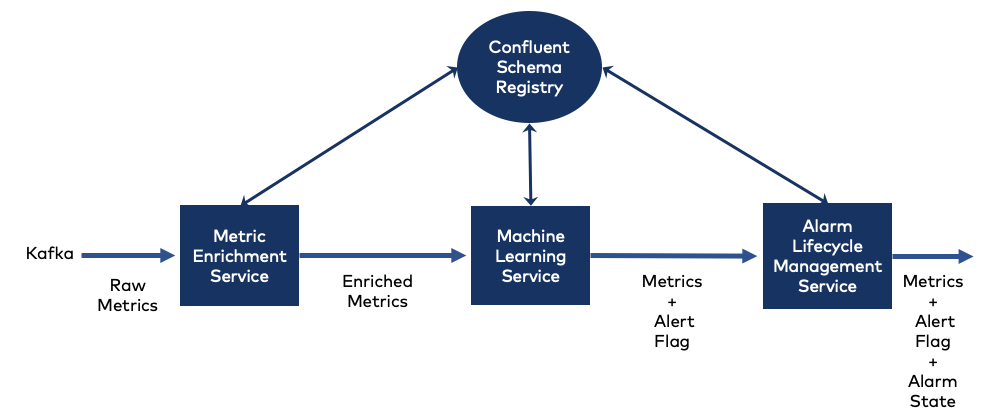
Each message in MOI represents a single time series observation of a specific metric instance at a particular point in time. The metric message includes several types of information, indicating:
- Metric type and unit of measurement (e.g. percentage of CPU usage)
- Instance information identifying the specific component being measured (e.g. the specific CPU)
- Metric value and the observation time
MOI’s metric Avro format is complex, with multiple substructures. One of the substructures, MetricSource, contains the observation data, including the value of the metric and the time at which the value was measured. (The other substructures aren’t relevant to this discussion.)
The prototype
We wanted the prototype to demonstrate that ksqlDB can be used to create metric filters. To do this, we needed to show that we could base filter rules on a combination of metric instance information, values, and types.
The prototype inserts a ksqlDB server between the Machine Learning Service and the Alarm Lifecycle Management Service. ksqlDB filters then the alert flag. The filters are based on metric values for one or more metric instances.
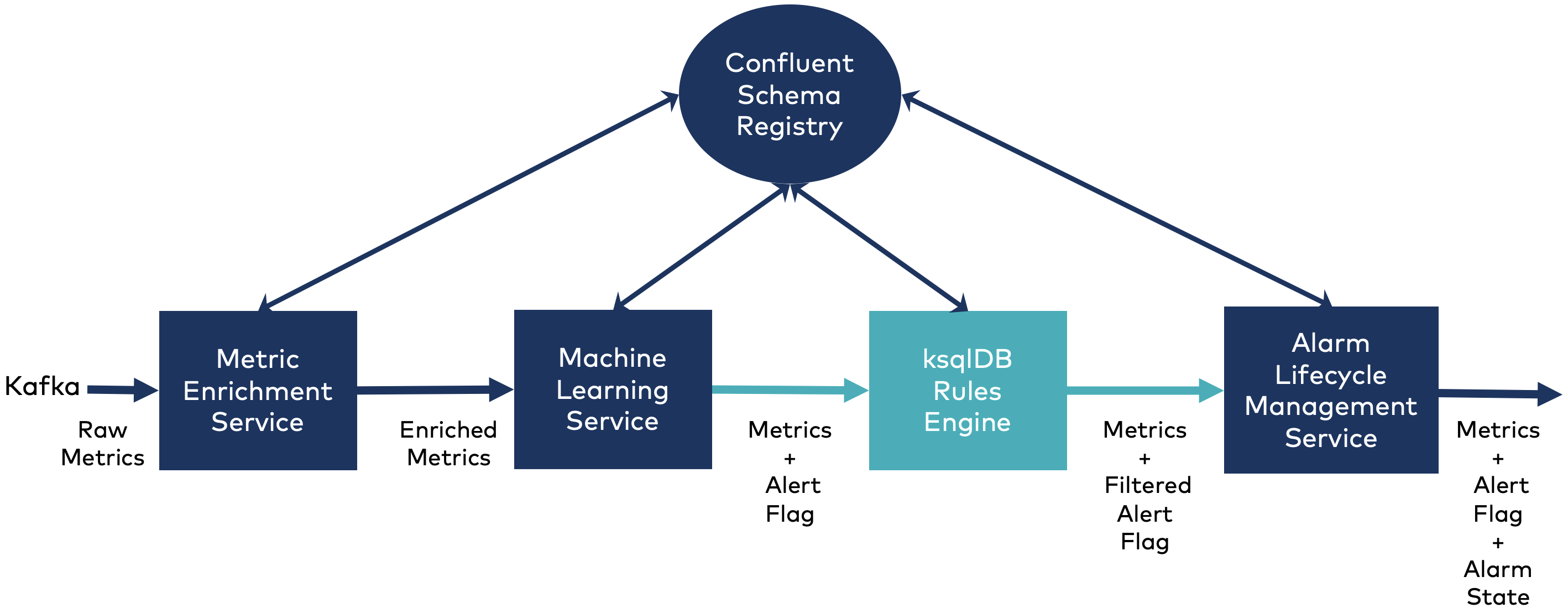
Our goal was to modify the current implementation as little as possible, only making changes that helped define rule conditions. We modified the Metric Enrichment Service to make some of the properties easier to use in ksqlDB. The Machine Learning Service publishes metrics to a new Kafka topic, called ALERT_FILTERING, which the ksqlDB server consumes. We also adapted the Alarm Lifecycle Management service to receive the Avro metric messages from the ksqlDB server, to translate those messages back to the original schema used by both the Alarm Lifecycle Management Service and downstream services (we’ll also discuss this more later on).
Installing ksqldb-server to MOI – A great first impression!
Each service in MOI runs inside its own Docker container. A MOI tool looks for docker-compose files in a particular directory structure and starts or stops the relevant containers.
We downloaded the ksqlDB Docker configuration and modified the docker-compose.yml file to point to MOI’s Schema Registry. Then we placed the file in the proper directory and restarted the MOI system. Less than 10 minutes after the download, we had the ksqldb-server and ksqldb-cli containers running in MOI! So often solution providers assert, “It’s so easy!” in this case, it’s true!
Creating the first stream
ksqlDB uses time to manage windowing information. By default, it uses the time set by the Kafka broker. However, ksqlDB has a very nice feature that lets the developer override the default and use the WITH clause to specify a domain time from the message. This is particularly useful for MOI, especially since, MOI may process metrics that have been delayed for days or even months.
To create a stream, our first step is to use the proper time field:
CREATE STREAM metrics_stream WITH ( kafka_topic = 'ALARM_FILTERING', value_format = 'AVRO', value_avro_schema_full_name = 'com.ca.oi.engine.common.avro.Metric', timestamp = 'time');
Message ---------------- Stream created ----------------
Selecting metric instances
The next step is to create new streams for specific metric instances. allowing us to create filters to support the many rules MOI requires. We can create a stream by adding a new field, rule, to contain the name of the rule. The rule name is used to join the streams when creating the actual filter rule.
Below, we create two streams for an example rule called fred, where each stream contains metrics for a single metric instance:
CREATE STREAM metric1 AS
SELECT *, 'fred' AS rule
FROM metrics_stream
WHERE MetricSource->category='Type74Subtype1DeviceDataSectionVolumeSerialNumber' AND
MetricSource->subSystemValue='PSG119' AND MetricSource->metricClass='DCTAVG_VOLSER'
PARTITION BY rule;
CREATE STREAM metric2 AS
SELECT *, 'fred' AS rule
FROM metrics_stream
WHERE MetricSource->category='Type74Subtype1DeviceDataSectionVolumeSerialNumber' AND
MetricSource->subSystemValue='PSG119' AND MetricSource->metricClass='DART_VOLSER'
PARTITION BY rule;
Finally, the filter rules
Now that we have a stream for two different metric instances, we can create a filter rule. The prototype rule is a toy example—it sets the alert field to 1 if the metric values in the metric1 and metric2 streams are each greater than 0. (Since both metrics come from the same product, they have the same time value.)
The metric value happens to be stored as a string, so we need to cast it to a double. In the ksqlDB statement below, OI-EVENTS.0 is the name of the topic consumed by the Alarm Lifecycle Management Service:
CREATE STREAM metric1_alerts WITH (
kafka_topic = 'OI-EVENTS.0',
value_format = 'AVRO',
value_avro_schema_full_name = 'com.ca.oi.engine.common.avro.MetricKSQL'
) AS
SELECT
metric1.metricId AS metricId,
metric1.groupId AS groupId,
metric1.product AS product,
metric1.productVersion AS productVersion,
metric1.version AS version,
metric1.documentId AS documentId,
metric1.MetricSource AS MetricSource,
metric1.GreenHighway AS GreenHighway,
metric1.IncidentEvent AS IncidentEvent,
metric1.Notifier AS Notifier,
metric1.isPartOfCluster AS isPartOfCluster,
metric1.metricPath AS metricPath,
metric1.lastState AS lastState,
metric1.time AS time,
CASE
WHEN CAST(metric1.MetricSource->metricValue AS DOUBLE) > 0.0 AND
CAST(metric2.MetricSource->metricValue AS DOUBLE) > 0.0 THEN 1
ELSE 0
END AS alert
FROM metric1
INNER JOIN metric2
WITHIN 5 MINUTES
ON metric1.rule = metric2.rule;
The Alarm Lifecycle Management Service needs to see all of the metrics, not just the metrics impacted by the filter. So we need to create an additional rule stream publishing to the OI-EVENTS.0 topic. This stream passes on those metrics:
CREATE STREAM other_metrics WITH (
kafka_topic = 'OI-EVENTS.0',
value_format = 'AVRO',
value_avro_schema_full_name = 'com.ca.oi.engine.common.avro.MetricKSQL'
) AS
SELECT * FROM metrics_stream
WHERE (NOT (MetricSource->category='Type74Subtype1DeviceDataSectionVolumeSerialNumber' AND
MetricSource->subSystemValue='PSG119' AND
MetricSource->metricClass='DCTAVG_VOLSER'
)
);
And we’re done, right? Well, there is a little bit of magic in these queries. Notice the schema specification in the WITH clause:
value_avro_schema_full_name = 'com.ca.oi.engine.common.avro.MetricKSQL'
This is different from the schema used by the original metrics_stream:
value_avro_schema_full_name = 'com.ca.oi.engine.common.avro.Metric'
This com.ca.oi.engine.common.avro.Metric schema is what the MOI services expect. So why the new schema? There are two reasons, one less obvious than the other.
The first reason is that the ksqlDB producer creates a schema with all of the field names capitalized—MOI’s schema uses camel casing. For example, ksqlDB changes the MetricSource substructure name in MOI’s schema to METRICSOURCE, and it changes the time field to TIME.
The second and more subtle reason is that the MetricSource substructure in MOI’s schema contains a field of type map. Avro maps, unlike ksqlDB, do not support nullable keys. To work around this, ksqlDB changes a map in an Avro schema to an array of key-value pairs. (For a detailed discussion about this, see the ksqlDB FAQ.)
One solution to the first issue—the difference in casing—doesn’t require any coding. When creating the streams, we can specify the field names with the correct casing:
CREATE STREAM foo (
`id` VARCHAR,
`value` VARCHAR
) WITH (
kafka_topic = 'foo',
value_format = 'AVRO'
);
But MOI uses a large and complex schema, so this would be tedious and error prone. It also wouldn’t solve the second issue about maps being converted to arrays.
The solution for us is to retrieve the ksqlDB schema from MOI’s Schema Registry:
curl --silent -X GET http://confluent:8081/subjects/OI-EVENTS.0-value/versions/latest
MOI’s build process uses Apache Maven (by way of the Avro Maven plugin) to generate Plain Old Java Objects (POJOs) from the .avsc Avro schema files used by all MOI services. Using the retrieved schema, we create a new MetricKSQL.avsc, then add it into the build process to generate a MetricKSQL.java POJO. We’ve modified the Alarm Lifecycle Manager Service’s Kafka consumer to use this new POJO. Then we just implement the code to translate from the new POJO to the original POJO. (We did open ksqlDB issue #4147 for a compatibility mode that would simplify integration into existing schemas.)
With these changes in place, everything works!
Conclusion
We haven’t made a final decision yet, but our investigation shows that ksqlDB is a viable option for creating and supporting filters in MOI. ksqlDB provides a familiar SQL-like language for defining filter rules using Kafka Streams. It is surprisingly easy to install and integrate with our product. In addition, there are readily available resources for learning ksqlDB and Kafka Streams, and in our experience, the Confluent community is amazingly helpful and responsive.





