[Webinar] How to Implement Data Contracts: A Shift Left to First-Class Data Products | Register Now
Using Kafka Streams API for Predictive Budgeting
At Pinterest, we use Kafka Streams API to provide inflight spend data to thousands of ads servers in mere seconds. Our ads engineering team works hard to ensure we’re providing the best experience to our advertising partners. As part of this, it’s critical we build systems to prevent instances of ads overdelivery. In this post, we’ll explain overdelivery and share how we built a predictive system using Apache Kafka Streams API to reduce overdelivery in our ads system and provide near-instant information about inflight spend.
Overdelivery
Overdelivery occurs when free ads are shown for out-of-budget advertisers. This reduces opportunities for advertisers with available budget to have their products and services discovered by potential customers.
Overdelivery is a difficult problem to solve for two reason:
- Real-time spend data: Information about ad impressions needs to be fed back into the system within seconds in order to shut down out-of-budget campaigns.
- Predictive spend: Fast, historical spend data isn’t enough. The system needs to be able to predict spend that might occur in the future and slow down campaigns close to reaching their budget. That’s because an inserted ad could remain available to be acted on by a user. This makes the spend information difficult to accurately measure in a short timeframe. Such a natural delay is inevitable, and the only thing we can be sure of is the ad insertion event.
Here’s an example of how this works. Imagine that advertiser X pays an internet-based company $0.10 per impression with $100 total daily budget. This yields a maximum of 1,000 daily impressions.

The company quickly implements a straightforward system for the advertiser:
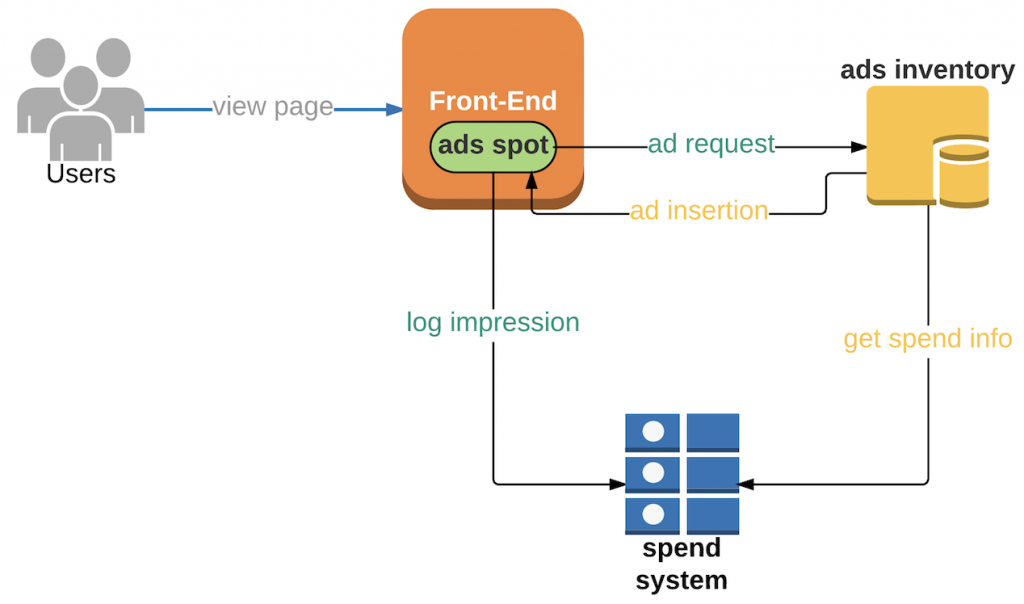
When a new ad spot (i.e. an opportunity to display an ad) appears in the company’s website, the frontend sends an ad request to ads inventory. Ads inventory then decides whether to show ads for advertiser X based on their remaining budget. If budget is still available, the ads inventory will make an ad insertion (i.e. an ad entry that’s embedded in a user’s app) to the frontend. After the user views the ad, an impression event is sent to the spend system.
However, when the company checked their revenue that didn’t happen.
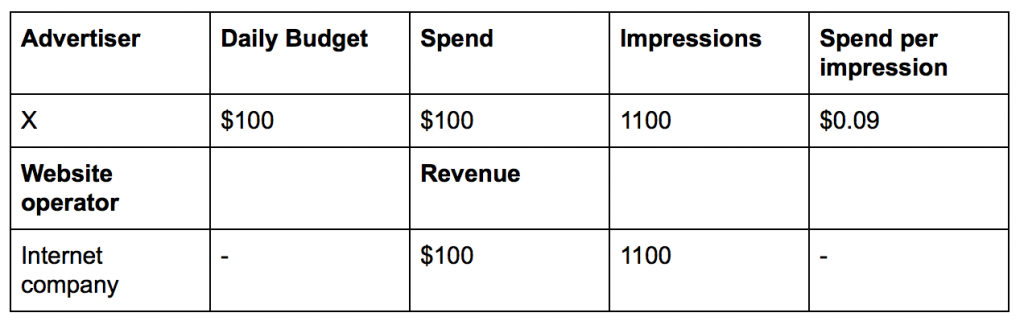
In one day, advertiser X’s ads were shown 1,100 times with $0.09 per impression. The extra 100 impressions were free, and could have been used by another advertiser. This example illustrates the common industry challenge of overdelivery.
So how does overdelivery occur? In this example, let’s say it turned out that the spend system was reacting too slowly. In fact, let’s say there was a delay of five minutes before it accounted for a user impression. Therefore, the internet company in this example did some optimizations to improve the system, resulting in an extra $9! This occurred because the company showed 90 impressions for other budget surplus advertisers, and overdelivery rate is only 10/1000 = 1 percent.

Later on, another advertiser, Y, contacted the same internet company and wanted to spend $100 per day to surface their ads at $2.0 per click (i.e. a user clicking through the ads link and reaching advertiser Y’s website), with 50 daily clicks max. The internet company added advertiser Y to the flow and added click event tracking for them into the system.
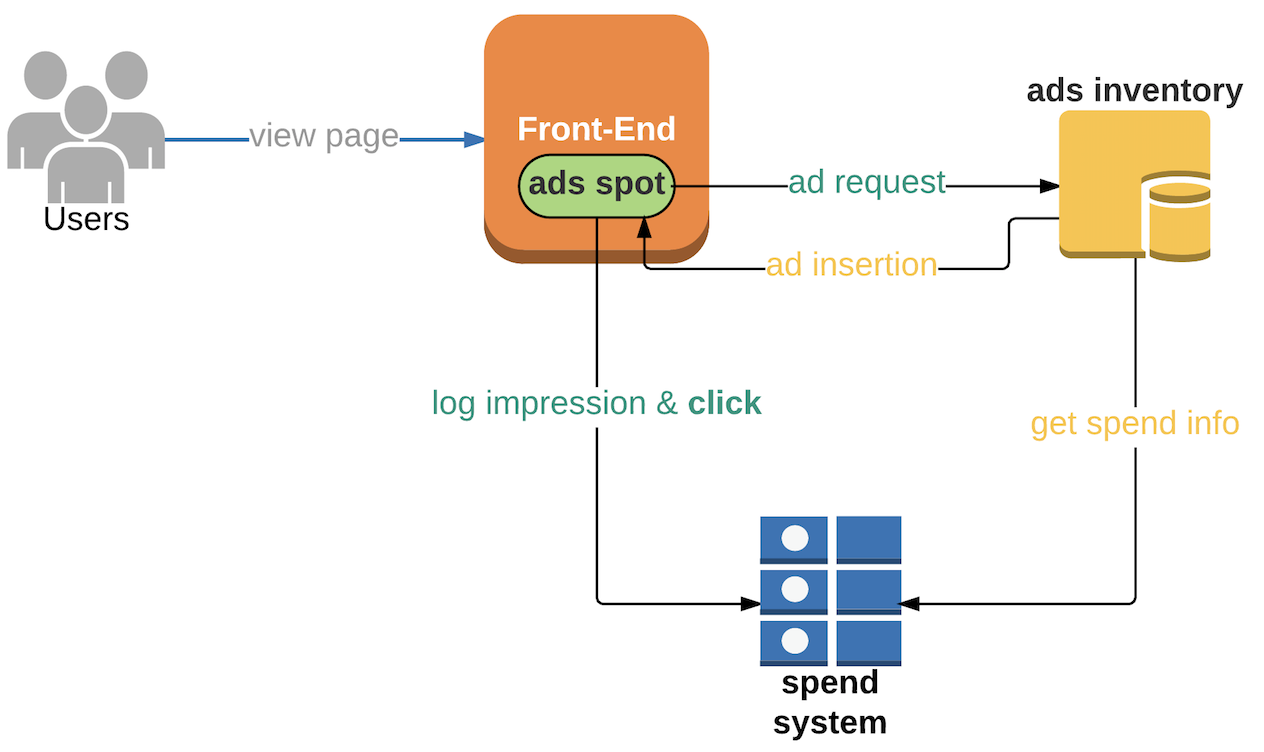
By the end of day, the internet company’s system was over-delivering, again.

Advertiser Y ended up with 10 free clicks! The internet company needed to identify why the system couldn’t foresee whether the inserted ad would be clicked, no matter how fast the system. Without the future spend information, they’d always overdeliver.
To finish this example, the company eventually found a brilliant solution: compute the inflight spend of each advertiser. Inflight spend is the cost of ads insertions that haven’t yet been charged. If actual_spend + inflight_spend > daily_budget, don’t show ad for this advertiser.
Building a prediction system
Motivation
Every day we help Pinners discover personalized ideas across our app, from recommendations to search to Promoted Pins. We need a reliable and scalable way to serve ads to Pinners and ensure we respect the budgets of our advertising partners.
Requirements
We began designing a spend prediction system with the following goals:
- Ability to work for different ads types (e.g.impression, click).
- Must be able to handle tens of thousands of events per second.
- Ability to fan out updates to more than 1,000 consumer machines.
- End to end delay should be less than 10 seconds;
- Ensure 100 percent uptime.
- Lightweight and maintainable for engineers.
Why Kafka Streams
We evaluated a variety of streaming services, including Spark and Flink. These technologies meet our scale requirements, but in our case, Apache Kafka Streams API provides extra advantages:
- Millisecond delay: Kafka Streams has a millisecond delay guarantee that beats Spark and Flink.
- Lightweight: Kafka Streams is a Java application with no heavy external dependencies like dedicated clusters which minimizes maintenance costs.
A concrete plan
At a high level, the below diagram illustrates our system with inflight spend:
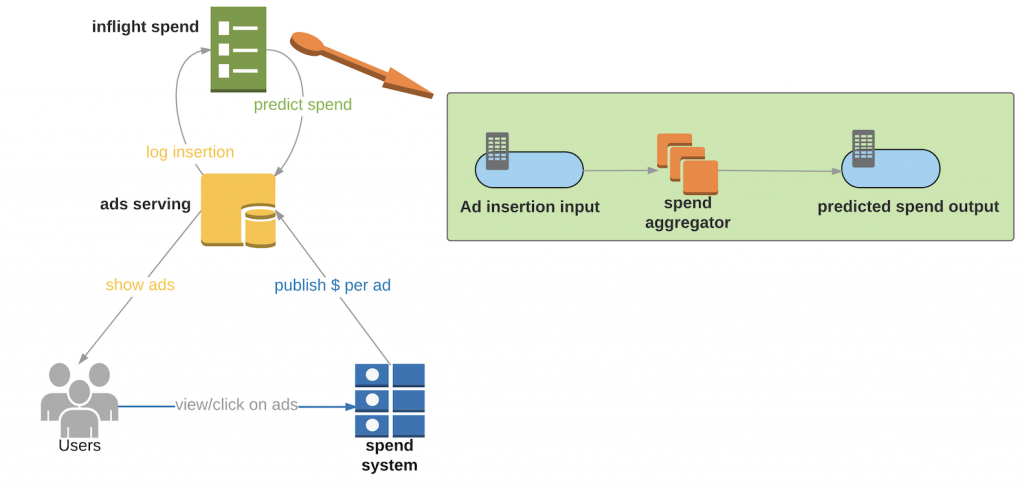
- Ads serving: Distributes ads to users, records ads insertions and gets predicted spend from “inflight spend” service.
- Spend system: Aggregates ads events and keeps ads serving system informed of current spend for each advertiser.
- Inflight spend:
- Ad insertion input: Every time a new insertion occurs the ads serving system communicates with the input topic. The message looks like:
{key: adgroupId, value: inflight_spend}, where- adgroupId = id of the group of ads under same budget constraint.
- Inflight_spend = price * impression_rate * action_rate
- Ad insertion input: Every time a new insertion occurs the ads serving system communicates with the input topic. The message looks like:
- Spend aggregator: Tails input topic and aggregates spends based on adgroup using Kafka Streams. We maintain a 10 second window store of inflight spend per adgroup. The output topic will be consumed by ads serving system. When the new predicted spend is received, the ads servers will update the inflight spend.
*Price: the value of this ad.
*Impression_rate: historical conversion rate of one insertion to impression. Note that an insertion is not guaranteed to convert to an impression.
*Action_rate: for an advertiser paying by click, this is the probability that user will click on this ad insertion; for advertiser paying by impression, this is 1.
Predicting spend
In practice, our spend predictions are extremely accurate. After applying the predictive budgeting system, we significantly reduced over delivery. Below is an example test of of actual vs. predicted spend.
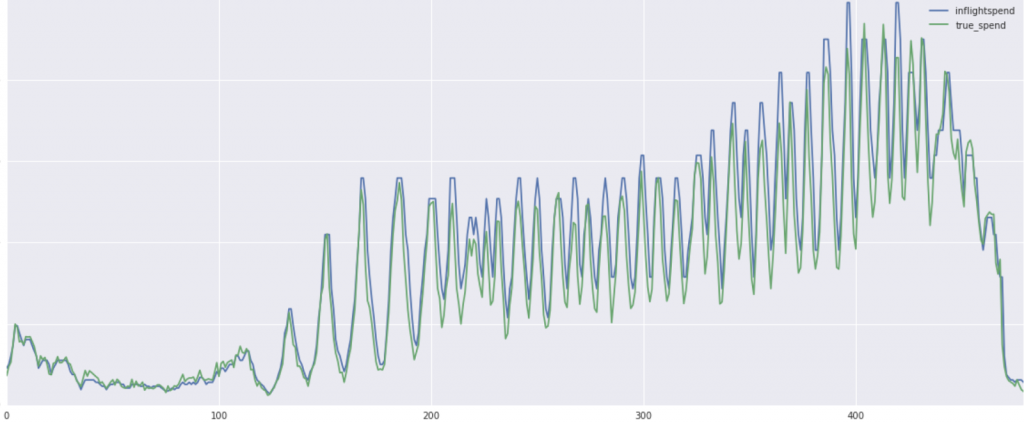
Example: The horizontal axis is three 3-minute wide time interval; the vertical axis is actual spend by time interval. Blue line represents the inflight spend and green line represents actual spend.
Key learnings
- Bad window store design can seriously impact performance. We saw an 18x performance improvement by using tumbling windows instead of hopping windows. Our initial implementation used hopping windows to calculate the previous three minutes of expected spend. As an example, a timeframe could be three minutes long, spaced 10 seconds apart. In this case, there would be 180 seconds / 10 seconds = 18 open windows. Each event processed by Kafka Streams may update all 18 windows, leading to redundant computation. To solve for this, we switched from hopping windows to tumbling windows. Unlike hopping windows, tumbling windows don’t overlap with each other, meaning each event will only update one window at a time. By reducing the number of updates from 18 to 1, the switching to tumbling windows has increased overall throughput by 18x.
- Strategies for message compression. To minimize the high fanout effect on consumers, we used delta encoding for adgroup IDs and lookuptable encoding for spend data. This compression strategy reduced the message size by 4x.
Conclusion
Using Apache Kafka’s Stream API to build a predictive spend pipeline was a new initiative for our ads infrastructure and it turned out to be fast, stable, fault-tolerant and scalable. We plan to continue exploring Kafka 1.0 and KSQL brought by Confluent for future systems design!
About Apache Kafka’s Streams API
If you have enjoyed this article, you might want to continue with the following resources to learn more about Apache Kafka’s Streams API:
- Watch the online talk Apache Kafka and Stream Processing at Pinterest.
- Get started with the Kafka Streams API to build your own real-time applications and microservices.
- Walk through our Confluent tutorial for the Kafka Streams API with Docker and play with our Confluent demo applications.
Acknowledgements: Huge thanks to Tim Tang, Liquan Pei, Zack Drach and Jerry Liu from Pinterest for the overall design, data analysis, performance tuning and encoding logic, and Guozhang Wang from Confluent for Kafka Streams usage elucidation and troubleshooting.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



3 Strategies for Achieving Data Efficiency in Modern Organizations
The efficient management of exponentially growing data is achieved with a multipronged approach based around left-shifted (early-in-the-pipeline) governance and stream processing.



Chopped: AI Edition - Building a Meal Planner
Dinnertime with picky toddlers is chaos, so I built an AI-powered meal planner using event-driven multi-agent systems. With Kafka, Flink, and LangChain, agents handle meal planning, syncing preferences, and optimizing grocery lists. This architecture isn’t just for food, it can tackle any workflow.