[Webinar] How to Implement Data Contracts: A Shift Left to First-Class Data Products | Register Now
Sysmon Security Event Processing in Real Time with KSQL and HELK
During a recent talk titled Hunters ATT&CKing with the Right Data, which I presented with my brother Jose Luis Rodriguez at ATT&CKcon, we talked about the importance of documenting and modeling security event logs before developing any data analytics while preparing for a threat hunting engagement. Defining relationships among Windows security event logs such as Sysmon, for example, helped us to appreciate the extra context that two or more events together can provide for a hunt. It caused me to wonder if there was anything that I could do with my project HELK to apply some of the relationships presented in our talk, and enrich the data collected from my endpoints in real time. HELK is a free threat hunting platform built on various components including the Elastic stack, Apache Kafka® and Apache Spark™.
KSQL can be used in numerous real-time security detection and alerting tasks. One example of this is against the lateral movement technique. By taking data from a tool such as Sysmon and streaming it into Kafka for processing in KSQL, you can rapidly detect suspicious behavior by looking for a process spawning a new process that makes an external network connection. Using KSQL we can join Sysmon event 1 (ProcessCreate) and Sysmon event 3 (NetworkConnect) in real time. The result allows us to have context not only about a process making an external network connection but also about the parent process that initially created the process calling out to the Internet. This is very helpful for our basic detection use case. You can read a worked example here of simulating such behavior with the Empire Project.
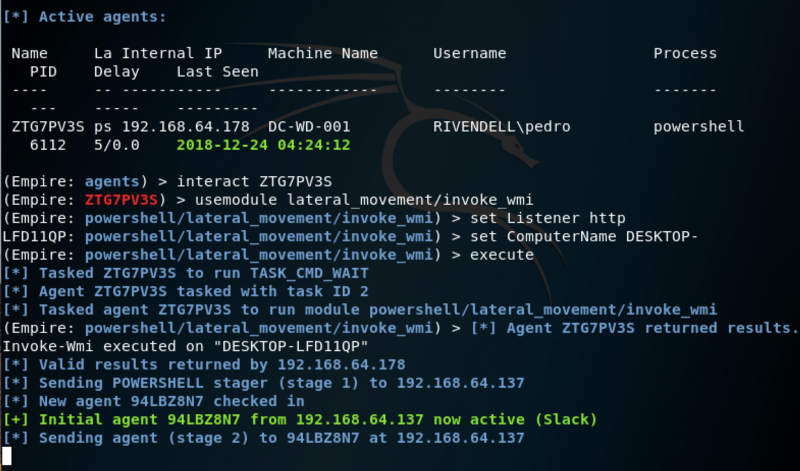
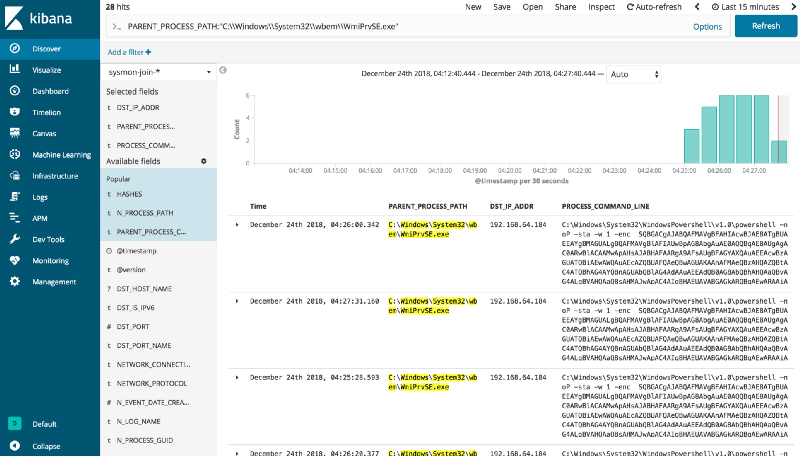
One well-known lateral movement technique is performed via the WMI object—class Win32_Process and its method Create. This is because the Create method allows a user to create a process either locally or remotely. One thing to note is that when the Create method is used on a remote system, the method is run under a host process named Wmiprvse.exe. Therefore, the new process created remotely will have Wmiprvse.exe as a parent. This is easy to look for using KSQL:
SELECT PARENT_PROCESS_PATH, DST_IP_ADDR, PROCESS_COMMAND_LINE FROM SYSMON_JOIN WHERE PARENT_PROCESS_PATH LIKE '%WmiPrvSE.exe%';
![]()
The results of the KSQL query can be written to a Kafka topic, which in turn can drive real-time monitoring or alerting dashboards and applications. You can see an example of a simple alerting application in an article written by Robin Moffatt here. This is one of advantage over rule-based systems that query data every couple of minutes or hours or days from a database, since KSQL alerting is event driven, happening at the pipeline level as the messages come through.
Yeah…I can do that already!
I have seen some of these join capabilities in other security information and event management (SIEM) solutions. However, almost all the SIEMs that I have worked with do it at QUERY TIME, which might take longer than expected and load the SIEM with heavy computations when done through terabytes of data at rest.
I’d rather do the joins as the messages come through my pipeline and let the load be handled by a stream processing application, not my SIEM itself.
Alternative approaches such as running some Python scripts as the data flows through your pipe will often not scale the way KSQL does with native Kafka Streams API translations and direct compatibility with Kafka. Doing more complex tasks such as joining data streams and analyzing the data at scale before the data even gets stored into your SIEM are possible easily using Kafka and KSQL.
KSQL: SQL interface for stream processing
KSQL allows you to easily execute SQL-like queries on the top of streams flowing from Kafka topics. KSQL queries get executed as Kafka Streams applications by the KSQL server, removing the necessity of writing Java code for real-time stream processing. Our basic design looks like the following:
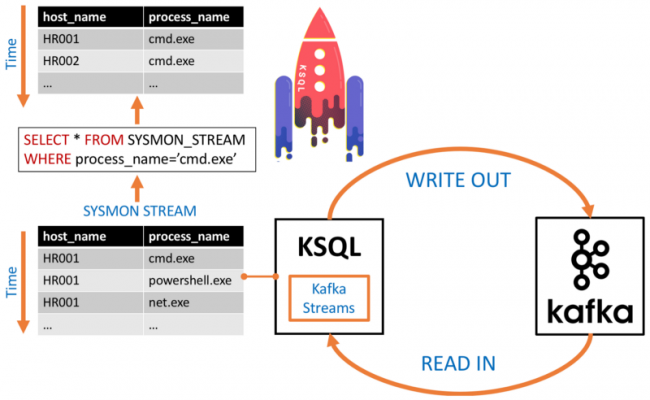 Streams vs. tables
Streams vs. tables
Streams and tables are a semantic model provided through Kafka Streams and KSQL for reasoning about data in a Kafka topic. Which one you use depends on the particular use to which you are putting the data.
A stream is an unbounded sequence of data records ordered by time that represents the past and the present state of data ingested into a Kafka topic. One can access a stream from the beginning of its time all the way to the most recently recorded values.
Tables, on the other hand, represent the current state of data records. For example, if DHCP logs are being collected, you can have a table that keeps the most up-to-date mapping between an IP address and a domain computer in your environment. Meanwhile, you can query the DHCP logs stream and access past IP addresses assigned to workstations in your network. Using the stream you could answer useful questions such as the number of times that a DHCP allocation has changed in a given time window.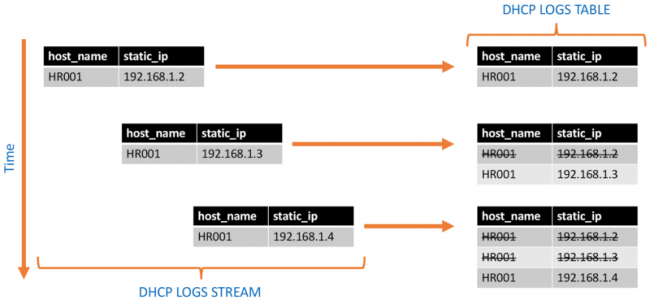
There are several ways in which streams and tables can be joined in KSQL:
| Join Sources | Description |
| Stream-Stream | Stream-stream joins are always time-windowed joins and support INNER, LEFT OUTER and FULL OUTER joins |
| Stream-Table | Stream-table joins are always non-time-windowed joins and support INNER and LEFT joins |
| Table-Table | Table-table joins are always non-time-windowed joins and support INNER, LEFT OUTER and FULL OUTER joins |
INNER, LEFT OUTER and FULL OUTER joins
INNER join: returns data records that have matching values in both sources

LEFT OUTER join: returns data records from the left source and the matched data records from the right source

FULL OUTER join: returns data records when there is a match in either the left or right source

Why KSQL and HELK?
As I mentioned at the beginning of this post, I wanted to find a way to enrich Windows Sysmon event logs by materializing the relationships identified within the information it provides. From an infrastructure perspective, I already collect Sysmon event logs from my Windows endpoints and publish them directly to a Kafka topic named winlogbeat in HELK. Using KSQL, it is very easy to apply a Sysmon data model via join operations in real time.
What is a data model?
A data model in general describes the structure of data objects present in a dataset and the relationships identified among each other. From a security events perspective, data objects can be entities provided in event logs such as a user, host, process, file or even an IP address.
As any other data object, they also have properties such as user_name, host_name, process_name or file_name, and depending on the information provided by each event log, relationships can be defined among those data objects as shown below:
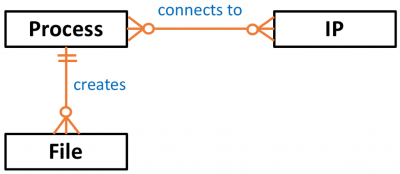
Modeling data objects identified in security event logs help security analysts to identify the right data sources and correlations that can be used for the development of data analytics.
What is the Sysmon data model?
Windows Sysmon event logs provide information about several data objects such as processes, IP addresses, files, registry keys and named pipes. In addition, most of their data objects have a common property named ProcessGUID that defines direct relationships among specific Sysmon events.
According to the recent white paper Subverting Sysmon, the ProcessGUID is a unique value derived from the machine GUID, process start time and process token ID that can be used to correlate other related events. After documenting the relationships among Sysmon events and data objects based on their ProcessGUID property, the following data model is possible:
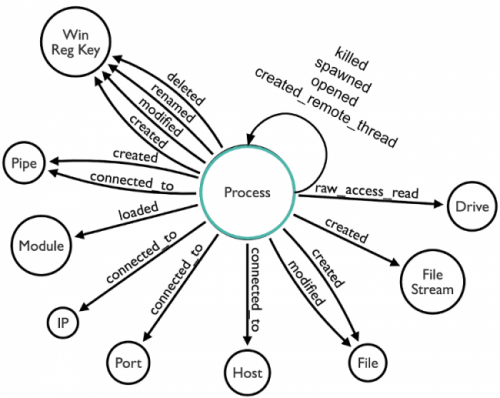
Based on this, we can use the ProcessGUID property to join Sysmon events in KSQL. For the purpose of this post, we will join ProcessCreate (Event ID 1) and NetworkConnect (Event ID 3) events. By doing this we can spot evidence of possible lateral movement behavior on the system.
HELK and KSQL integration
HELK is deployed via Docker images; you can find a full installation guide for HELK in the longer version of this article here. Once installed, we can check the metadata of topics available on the Kafka broker with the SHOW TOPICS command:
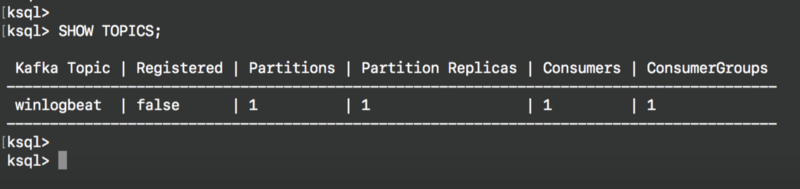
What the HELK is going on so far?
Up to this point, we have all we need to start using KSQL on the top of the HELK project. The following is happening:
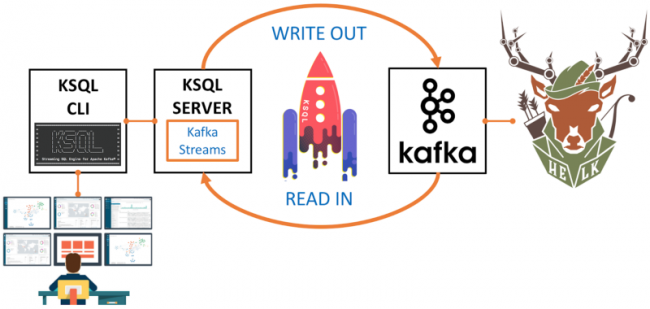
- The Kafka broker with topic winlogbeat is running
- KSQL server is running and configured to read from the Kafka brokers
- KSQL CLI is running and configured to talk to KSQL server and send interactive queries
- Your Ubuntu box hosting the HELK has an interactive connection to the helk-ksql-cli container
- HELK is waiting for Windows Sysmon logs to be published
Get Sysmon data to HELK
You can now install Sysmon and Winlogbeat following the initial instructions in this post. To check if the logs being collected by the Winlogbeat shipper are being published to your Kafka broker, inspect the Kafka topic winlogbeat with the PRINT command:
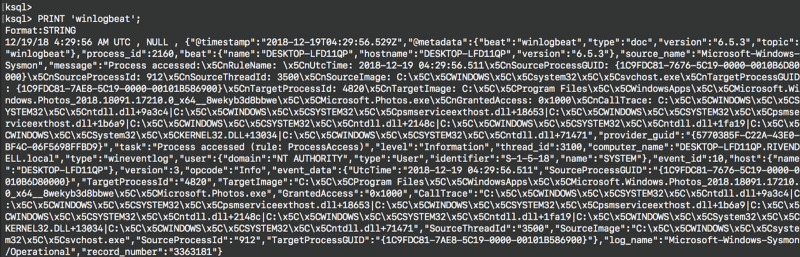
So here we have confirmed that data is flowing from our Windows system to our HELK Kafka broker, and through to our KSQL server and CLI endpoint. At this point, we are ready to start interacting with the Sysmon data flowing through our Kafka broker. Now let’s see how to execute a few KSQL queries to filter Sysmon events and join events 1 and 3 in real time.
Sysmon events schema
Let’s have a look at the schema for Sysmon events 1 and 3 from the logs flowing into Kafka. This will help you know what data fields you will be able to use for your KSQL queries, and enable us to derive two new streams for each Sysmon event (1 and 3).
Sysmon event ID 1 – Process creation:
{
"@timestamp":"2018-12-18T22:42:32.841Z",
"thread_id":3100,
"event_id":1,
"log_name":"Microsoft-Windows-Sysmon/Operational",
"computer_name":"DESKTOP-LFD11QP.RIVENDELL.local",
"task":"Process Create (rule: ProcessCreate)",
"event_data":
{
"ParentImage":"C:\x5C\x5CWindows\x5C\x5CSystem32\x5C\x5Csvchost.exe",
"User":"RIVENDELL\x5C\x5Ccbrown",
[…]
Sysmon event ID 3 – Network connection:
{
"@timestamp":"2018-12-18T22:42:58.788Z",
"thread_id":1972,
"event_id":3,
"computer_name":"DESKTOP-LFD11QP.RIVENDELL.local",
"task":"Network connection detected (rule: NetworkConnect)",
"event_data":
{
"DestinationPort":"443",
"Protocol":"tcp",
"DestinationIp":"172.217.7.174",
"SourcePort":"49737",
[…]
Register the winlogbeat topic in KSQL
In KSQL, register the source topic winlogbeat as a KSQL stream called WINLOGBEAT_STREAM. Remember that we are only focusing on Sysmon events 1 and 3, and the data is in JSON format. Therefore, we only need to specify the column names of the two Sysmon events (1 and 3). Any fields that exist in the payload and are not named in the schema that we declare will just be ignored by KSQL. Notice that nested fields are defined via the STRUCT data type as shown below:
CREATE STREAM WINLOGBEAT_STREAM \
(source_name VARCHAR, \
type VARCHAR, \
task VARCHAR, \
log_name VARCHAR, \
computer_name VARCHAR, \
event_data STRUCT< \
UtcTime VARCHAR, \
ProcessGuid VARCHAR, \
ProcessId INTEGER, \
Image VARCHAR, \
…
event_id INTEGER) \
WITH (KAFKA_TOPIC='winlogbeat', VALUE_FORMAT='JSON');
Rekey WINLOGBEAT_STREAM
In order to perform a join between two streams or a stream and a table, the Kafka messages must be keyed on the field on which we are performing the join. This will prevent the join from failing and returning NULL values. I also take advantage of this step to standardize the field names on the Sysmon events and make sure I am only including Sysmon logs in case I am collecting other logs with the Winlogbeat shipper. The field standardization is usually done by Logstash in HELK, but in this case, it can be done via KSQL as well. The common property between the two Sysmon event types is process_guid so we’ll use that as the partitioning key.
To create a new Kafka topic with the amended field names and partitioning key we use the CREATE STREAM AS SELECT statement (known as CSAS). This statement creates a new stream along with a corresponding Kafka topic, and continuously writes the result of the SELECT query into the stream and its corresponding topic. Note the use of -> to reference nested fields, as well as TIMESTAMP to set the timestamp of the generated Kafka messages to the value provided in the event data itself.
CREATE STREAM WINLOGBEAT_STREAM_REKEY \
WITH (VALUE_FORMAT='JSON', \
PARTITIONS=1, \
TIMESTAMP='event_date_creation') \
AS SELECT STRINGTOTIMESTAMP(event_data->UtcTime, 'yyyy-MM-dd HH:mm:ss.SSS') AS event_date_creation, \
event_data->ProcessGuid AS process_guid, \
event_data->ProcessId AS process_id, \
event_data->Image AS process_path,
…
FROM WINLOGBEAT_STREAM \
WHERE source_name='Microsoft-Windows-Sysmon' \
PARTITION BY process_guid;
Verify the rekey operation results
If you query both streams you will see the difference. The new stream has the process_guid column as its key column (exposed through the system field ROWKEY):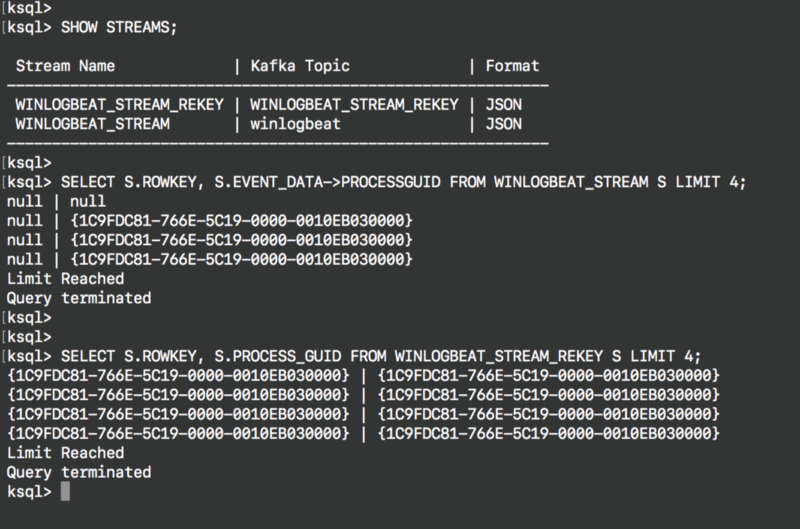
Inspect the derived new stream
You can inspect the new stream by using the command DESCRIBE as shown below: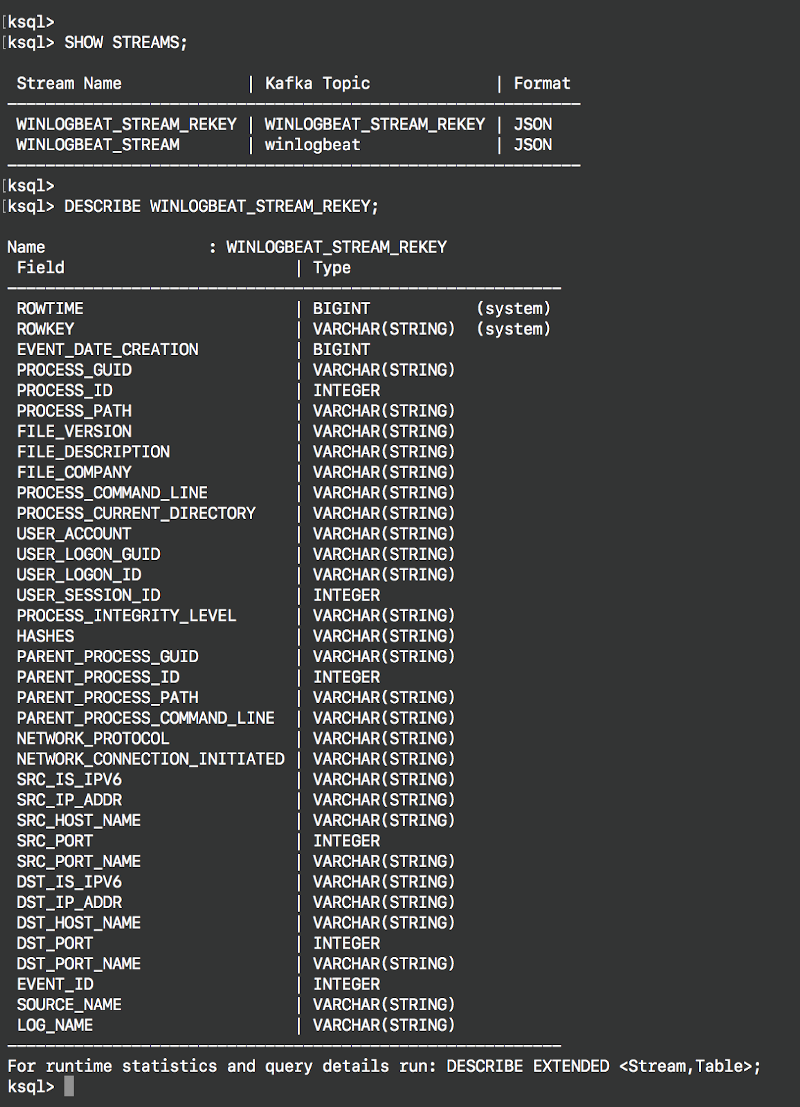
You can also access additional information about the new stream with the command DESCRIBE EXTENDED, showing information such as the query behind the stream and local runtime statistics.
Create Sysmon ProcessCreate stream
The Sysmon stream contains all the events provided by Sysmon. In order to join events 1 and 3, we need to derive a new stream for each event first (1 and 3). Remember that our Sysmon ProcessCreate event (ID 1) will be eventually be a table. This is because process creation events happen first, and network events might not happen immediately after the creation of a process. Having Sysmon events ID 1 as a table greatly helps maintain an up-to-date state of it for as long as the minimum age of a log file is needed to be eligible for deletion on the Kafka broker.
For this step, we also use the CREATE STREAM AS SELECT statement, with a predicate to filter just events for the respective streams:
CREATE STREAM SYSMON_PROCESS_CREATE AS \
SELECT event_date_creation, \
process_guid, \
process_id, \
process_path, \
parent_process_guid, \
parent_process_id, \
parent_process_path, \
…
FROM WINLOGBEAT_STREAM_REKEY \
WHERE event_id=1;
CREATE STREAM SYSMON_NETWORK_CONNECT AS
SELECT event_date_creation,
process_guid,
process_id,
process_path,
network_protocol,
src_ip_addr,
src_port,
…
FROM WINLOGBEAT_STREAM_REKEY
WHERE event_id=3;
Create Sysmon ProcessCreate table
As I mentioned before, we define the Sysmon ProcessCreate events as a table because for each key (process_guid), we want to know its current values (process_name, process_command_line, hashes, etc.) and join them with NetworkCreate events that have the same process_guid value.
CREATE TABLE SYSMON_PROCESS_CREATE_TABLE \ (event_date_creation VARCHAR, \ process_guid VARCHAR, \ process_id INTEGER, \ … WITH (KAFKA_TOPIC='SYSMON_PROCESS_CREATE', \ VALUE_FORMAT='JSON', \ KEY='process_guid');
Test the join with SELECT
We are ready to perform our INNER join between network connections and process creations events on their process_guid common value. We can test if everything that we have done so far works by performing a join without persisting the results on a topic, using a SELECT statement:
SELECT N.DST_IP_ADDR, \
P.PROCESS_PATH, \
P.PROCESS_COMMAND_LINE \
FROM SYSMON_NETWORK_CONNECT N \
INNER JOIN SYSMON_PROCESS_CREATE_TABLE P \
ON N.PROCESS_GUID = P.PROCESS_GUID \
LIMIT 5;

As you can see above, we were able to join the two Sysmon event streams successfully. The recipe is working, and it can now start populating a topic.
Persist enriched stream and populate a topic
We can persist the results of our join query by using the CREATE STREAM AS SELECT statement again. Once the results start populating the new Kafka topic SYSMON_JOIN, a tool such as Logstash or Kafka Connect can subscribe to it and push the data to an Elasticsearch index.
CREATE STREAM SYSMON_JOIN WITH (PARTITIONS=1) AS \
SELECT N.EVENT_DATE_CREATION, \
N.PROCESS_GUID, \
N.USER_ACCOUNT, \
N.SRC_IP_ADDR, \
N.DST_IP_ADDR, \
P.PROCESS_COMMAND_LINE, \
P.PARENT_PROCESS_PATH,\
[…]
FROM SYSMON_NETWORK_CONNECT N \
INNER JOIN SYSMON_PROCESS_CREATE_TABLE P \
ON N.PROCESS_GUID = P.PROCESS_GUID;
Kibana index ready
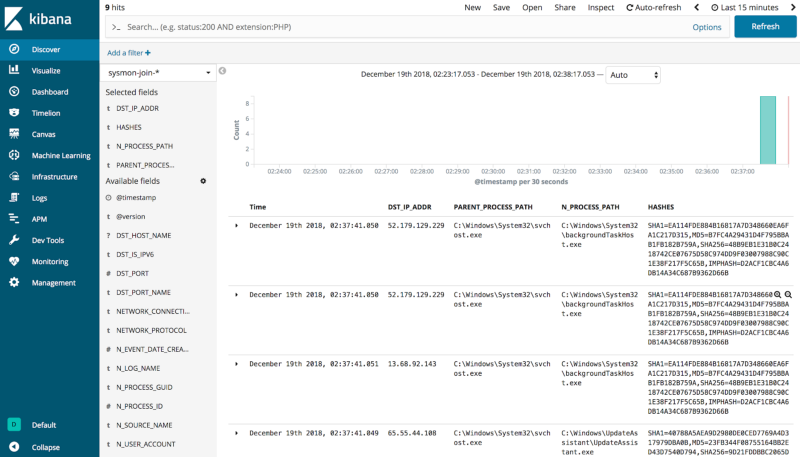
As shown before, the results from the KSQL join operation get sent to the sysmon-join-* index and are made available via Kibana. If you browse your HELK Kibana interface and select the sysmon-join-* index, you can access the enriched data from the KSQL join.
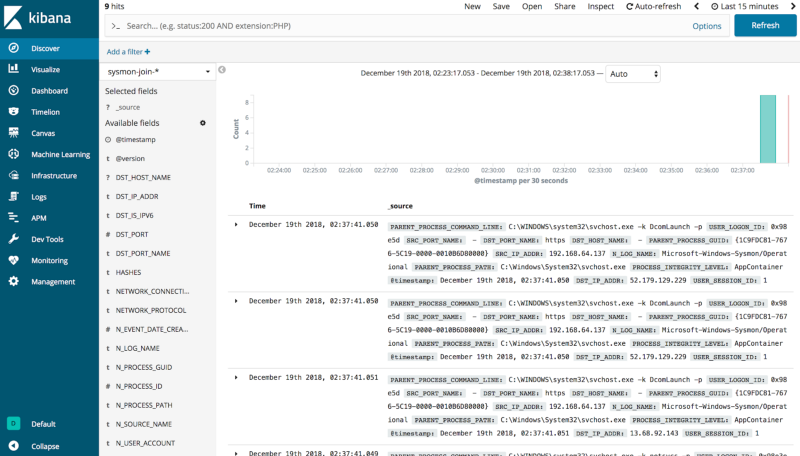
We can now have enriched data with destination IPs mapped to parent processes and even hashes all in the same event. It’s very useful to work with enriched data right away rather than perform the join statements at query time and wait for results.
What the HELK happened?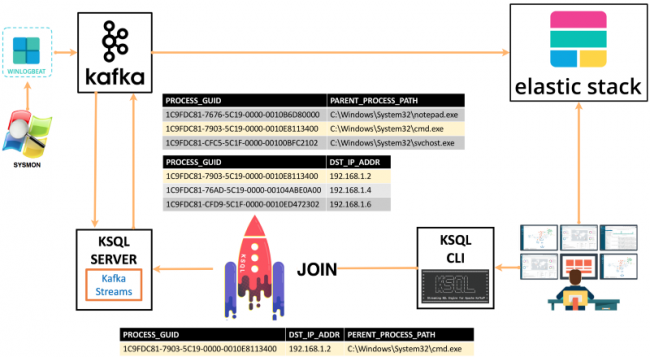
- Winlogbeat shipper (producer) publishes Sysmon event logs to Kafka topic winlogbeat
- A user via the KSQL CLI sends queries to a KSQL server to join Sysmon events 1 (ProcessCreate) and 3 (NetworkConnect)
- The KSQL server processes queries via the Kafka Streams API
- Join results get sent back to the Kafka topic SYSMON_JOIN
- Logstash subscribes to topic SYSMON_JOIN
- Logstash sends data from SYSMON_JOIN topic to Elasticsearch index sysmon-join-*
- User can access results via Kibana index pattern sysmon-join-*
Deploying the KSQL application
You might be asking yourself, how do I deploy this without typing all those KSQL commands manually again? The headless deployment known as the application mode allows you to start your KSQL server with a SQL file as an argument. The idea is to write your queries in the SQL file for the KSQL server to read, compile and execute the KSQL statements. I created a file with all the commands I used and hosted it in this gist for you to use. You can start up the KSQL server and pass it this file (alternatively, define it as ksql.queries.file in the KSQL server properties file):
ksql-start-server ksql-server.properties --queries-file sysmon-join.commands
You can also run the command file via the KSQL CLI console:
ksql> run script '/tmp/sysmon-join.commands';
In this post we’ve seen how with a few simple KSQL commands you can join in real time Sysmon events 1 and 3 in order to spot lateral movement behavior. You can join more than those two events, and even bring other datasets to the mix.
If you use a similar approach to join other datasets with Sysmon events, remember that they have to have a common property value like process_guid to perform accurate join statements.
I had a good time learning about KSQL, and I encourage you to try it too 😃. I wanted to also take the time to thank the awesome Confluent team and Robin Moffatt for the help and great information they have been sharing with the community so far. Feedback is greatly appreciated!
If you’re interested in what KSQL can do, download the Confluent Platform to get started with KSQL.
Resources
Here are some additional resources if you’d like more details:
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Confluent Deepens India Commitment With Major Expansion on Jio Cloud
Confluent Cloud is expanding on Jio Cloud in India. New features include Public and Private Link networking, the new Jio India Central region for multi-region resilience, and streamlined procurement via Azure Marketplace. These features empower Indian businesses with high-performance data streaming.



From Pawns to Pipelines: Stream Processing Fundamentals Through Chess
We will use Chess to explain some of the core ideas behind Confluent Cloud for Apache Flink. We’ve used the chessboard as an analogy to explain the Stream/Table duality before, but will expand on a few other concepts. Both systems involve sequences, state, timing, and pattern recognition and...