[Webinar] How to Implement Data Contracts: A Shift Left to First-Class Data Products | Register Now
Managing Hybrid Cloud Data with Cloud-Native Kubernetes APIs
Confluent for Kubernetes (CFK) has added declarative API support for Cluster Linking, allowing you to connect public and private cloud environments with a declarative API.
Confluent for Kubernetes provides a complete, declarative API-driven experience for deploying and self-managing Confluent Platform as a cloud-native system. Cluster Linking is an easy-to-use, secure, and cost-effective data migration and geo-replication solution to seamlessly and reliably connect applications and data systems across your hybrid architectures. With the release of Confluent Platform 7.0, Confluent announced the general availability of Cluster Linking in Confluent Platform and Confluent Cloud. Using CFK’s declarative API for Cluster Linking, you can now create hybrid cloud environments with the infrastructure as code (IaC) model.
This blog details the technical challenges faced while developing a declarative API for Cluster Linking and the opinionated choices made to deliver the best user experience. This post also shows how simple and clean it is to set up a hybrid cloud environment with CFK’s Cluster Linking API by setting up a cluster link between an Apache Kafka® cluster in Confluent Cloud—a fully managed, cloud-native service for connecting and processing all of your real-time data—and a local Confluent cluster on Kubernetes managed by CFK to migrate data from am on-prem cluster to cloud cluster, demonstrating the movement of data between private and public cloud infrastructure.
Declarative API for Cluster Linking
CFK’s declarative APIs enable you to leave the infrastructure management to Confluent’s intelligent, software-based automation, thereby freeing you to focus solely on your real-time business applications. These APIs enable you to express the state of your infrastructure and application state as code in the form of a collection of YAML files. You can check the YAML files into a Git repository so that your teams can collaborate on managing these environments. With CI/CD systems, the YAML files can be pulled from Git to deploy updates to the Confluent environments in development, QA, and then production. This entire paradigm is referred to as GitOps.
Confluent for Kubernetes provides a declarative ClusterLink API to configure and manage Cluster Linking. This declarative API allows you to define the desired state of your cluster links by defining a ClusterLink CustomResource (CR) based on the ClusterLink CustomResourceDefinition (CRD). Confluent for Kubernetes then creates the cluster link and ensures that it maintains the desired state defined by the CustomResource.
These are the components that define a cluster link in the ClusterLink declarative API:
- Destination Kafka cluster: This defines the destination cluster for the cluster link. The cluster link is managed by the destination cluster, and is simply a consumer from the source cluster perspective. To create the cluster link, you need access to the REST API endpoint information on the destination cluster along with authentication information, if any. The KafkaRestClass declarative API encapsulates all the configurations including authentication and certificates to access REST APIs. The ClusterLink CR references the KafkaRestClass under kafkaRestClassRef in this API. This can be maintained in a Git repository and can be reused across any other CFK declarative APIs that need a REST Admin client with just a reference to its name.
- Source Kafka cluster: This describes the source cluster for the cluster link where the data will be synced from. It takes in the bootstrap endpoint for the source cluster and optional authentication configs. The power of declarative APIs is evident here where you are able to define authentication and SSL certificates for the source cluster with a few readable lines rather than a list of configs including certificates that need to be set while creating a cluster link with an admin client command.
There were a few opinionated choices that were made while implementing this API in order to achieve the best user experience. One of the important components of source configuration is authentication and TLS information. TLS certificates can be configured for clusters by either placing them in the destination cluster and adding that path to configuration or by passing the raw certificates as a configuration. The choice was made to pass the certificates directly via secrets or HashiCorp Vault because it eliminates the extra step to ensure the certificates are present in the Kafka cluster and avoids changes to the Kafka CR to mount the certificates into Kafka brokers which would in turn require rolling of the Kafka cluster. Another decision was to accept a clusterID in this API. While the clusterID for the source cluster can be obtained from sourceKafkaCluster.kafkaRestClassRef, we decided to accept clusterID in the API for the use cases where the source cluster would not open up the REST admin endpoints outside their network.
- Mirror topics: Messages in Kafka are organized into topics. Each topic has a name that is unique across the entire Kafka cluster. In the cluster link terminology, source clusters refer to these objects simply as “topics,” whereas the destination cluster to which the topics are mirrored refers to them as “mirror topics.” These are read-only topics on destination clusters maintained by cluster link. Mirror topics can be in one of the following states: ACTIVE, PAUSED, PENDING_STOPPED, STOPPED, SOURCE_UNAVAILABLE, LINK_FAILED, FAILED. Refer to the mirror topics documentation for more details on mirror topic states. Without a declarative API, you would have to run an admin client command to create each of the required mirror topics (and potentially a second command to set the mirror topic’s state). But with CFK’s declarative API, you are able to just list the topics to mirror and desired state (PAUSE, ACTIVE, etc.) and let Confluent for Kubernetes automate the rest. Internally, this topic change API is a state machine that needs to translate the desired topic state (ACTIVE, PAUSE, etc.) to a topic action (RESUME, FAILOVER, etc.) based on the current state of mirror topics and throw errors to handle invalid state transitions. Like other Kubernetes constructs, ClusterLink CRD maintains the current state of the cluster link in its status, including mirror topics and its states. The state machine gets the current mirror topic state from the status, and the desired state from the CR, and comes up with actions to be taken to get mirror topics to the desired state. To ensure the best user experience, the decision was made to remove the mirror topic from the YAML file translates to mirror topic deletion in the internal state machine, while deleting the entire cluster link translates to failover for all the mirror topics for the cluster link.
Overall it was an interesting technical challenge to develop a declarative API that provides the best user experience while ensuring it is not too restrictive for Confluent users. Once you have the CustomResource YAML file, all you need to do is to run kubectl apply -f clusterlink.yaml. You can have multiple ClusterLink definitions that link different environments within an organization. All these YAML files can be maintained in a Git repository (GitOps model), allowing your team to collaborate using a readable declarative API.
Hybrid cloud environment with CFK and Confluent Cloud
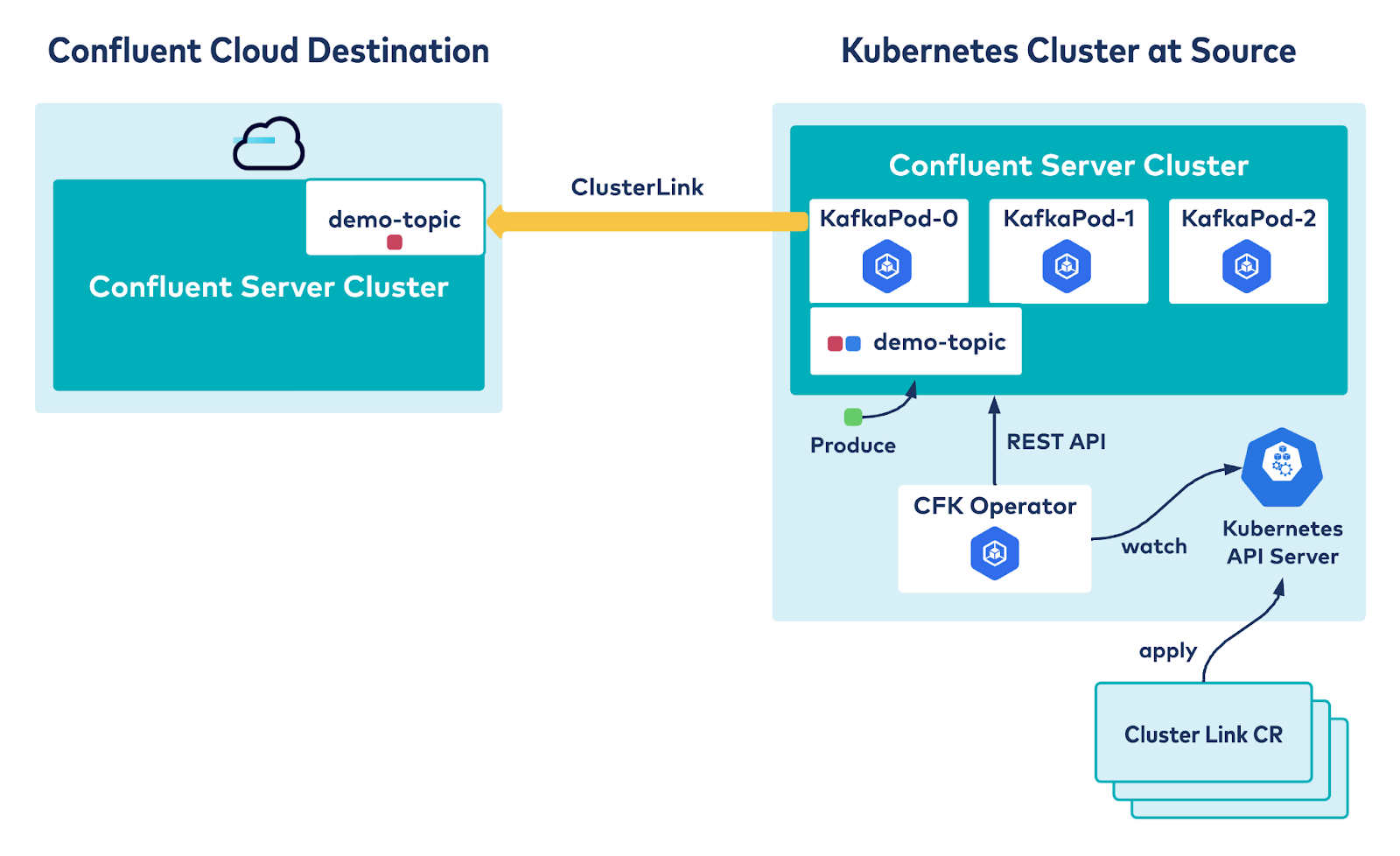
Confluent for Kubernetes brings a cloud-native experience for data in motion workloads to on-premises environments. It provides simplicity, flexibility, and efficiency without the headaches and burdens of complex, Kafka-related infrastructure operations. Cluster Linking allows you to connect on-prem and cloud environments by securely, reliably, and effortlessly creating a bridge between them. The declarative API for Cluster Linking takes this combination one step further by providing a cloud-native way to configure the bridge between on-prem and cloud.
The following example sets up a hybrid cloud environment by configuring a cluster link between Confluent Platform running on-prem and managed by Confluent for Kubernetes, and another Kafka cluster running on fully managed Confluent Cloud. Data produced into topics in the on-prem cluster will be transparently replicated to the corresponding topic in the cloud cluster.
apiVersion: platform.confluent.io/v1beta1
kind: ClusterLink
metadata:
name: clusterlink-demo
namespace: operator
spec:
destinationKafkaCluster:
kafkaRestClassRef:
name: krc-cloud
namespace: operator
sourceKafkaCluster:
authentication:
type: plain
jaasConfig:
secretRef: plainpassjks
bootstrapEndpoint: clink.platformops.dev.gcp.devel.cpdev.cloud:9092
kafkaRestClassRef:
name: krc-cfk
namespace: operator
mirrorTopics:
- name: demo-topic
---
apiVersion: platform.confluent.io/v1beta1
kind: KafkaRestClass
metadata:
name: krc-cloud
namespace: operator
spec:
kafkaClusterRef:
name: kafka
kafkaRest:
endpoint: https://pkc-cloud.us-west4.gcp.confluent.cloud:443
kafkaClusterID: lkc-cloud
authentication:
type: basic
basic:
secretRef: restclass-ccloud
tls:
secretRef: ccloud-tls-certs
You can create a cluster link in the Kafka cluster running on the Confluent Cloud with the CR above. Refer to Create a Kafka Cluster in Confluent Cloud and Manage Topics documentation for instructions on how to create a cluster and required topics. This Kafka cluster is configured with SASL-SSL for external listeners, which means in CFK you need to configure the appropriate authentication and TLS certificate information. Any client of this cluster, including a cluster link, must have the right authentication information and certificates.
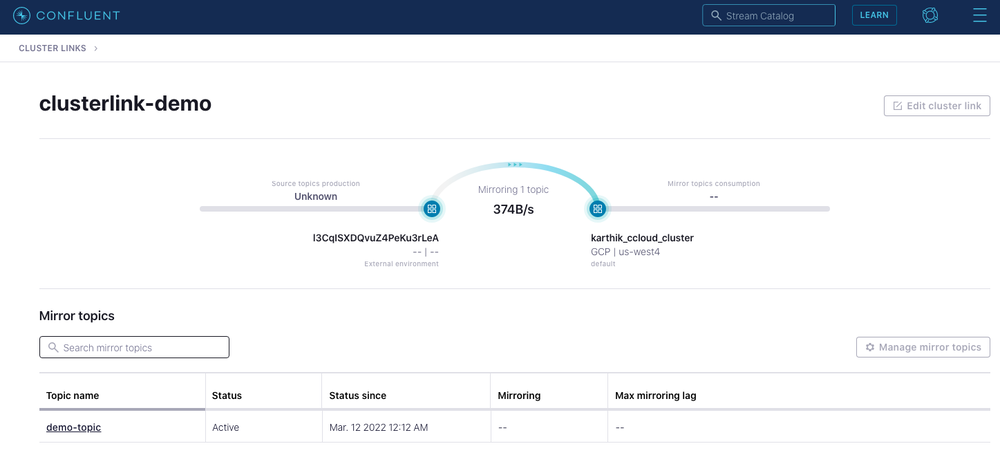
Next, you have Confluent Platform deployed on-prem using CFK. CustomResource files for the Confluent Platform together with the steps to bring up a cluster using CFK are defined in this GitHub repository. This brings up a Kafka cluster and ZooKeeper in SASL plain mode. Once the on-prem cluster is up and running, you can set up the cluster link between the cloud cluster and on-prem cluster. This will set the on-prem cluster as the source cluster and the cloud cluster as the destination cluster to sync the messages from the mirror topics. Here is a quick demo:
With these simple steps, you have a hybrid environment where data is moved from the on-prem cluster to the cloud cluster in a transparent way and on-prem and cloud resources are managed in a cloud-native way with CFK.
Summary
Confluent for Kubernetes was built with the aim of delivering cloud-native Confluent across all your environments. Cluster Linking was built to provide an easy-to-use, secure, and cost-effective data migration and geo-replication solution to seamlessly and reliably connect applications and data systems across your hybrid architectures. With the support of declarative API for Cluster Linking, users have a simple, clean, and cloud-native way to set up a hybrid cloud environment. If you would like to set up a hybrid cloud with CFK, sign up for a free trial of Confluent Cloud and download Confluent Platform and CFK. You can use the promo code CL60BLOG for an additional $60 of free cloud usage.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Confluent and Amazon EventBridge for Broad Event Distribution
Learn how to stream real-time data from Confluent to AWS EventBridge. Set up the connector, explore use cases, and build scalable event-driven apps.


New With Confluent Platform 8.0: Stream Securely, Monitor Easily, and Scale Endlessly
This blog announces the general availability (GA) of Confluent Platform 8.0 and its latest key features: Client-side field level encryption (GA), ZooKeeper-free Kafka, management for Flink with Control Center, and more.