Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
What is Apache Flink®?
Apache Flink® is an open source data processing framework that offers unique capabilities in both stream processing and batch processing. It is a popular tool for building high-performance, scalable event-driven architectures and applications.
Confluent enables developers to easily build high-quality, reusable data streams, bringing together the capabilities of cloud-native Flink and Apache Kafka®. Learn how Flink how works, it key architectural components, its advantages, and the use cases it unlocks when used with Kafka.
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments and perform computations at in-memory speed, at any scale. Developers build applications for Flink using APIs such as Java or SQL, which are executed on a Flink cluster by the framework.
While other popular data processing systems like Apache Spark and Kafka Streams are limited to data streaming or batch processing, Flink supports both. This makes it a versatile tool for businesses in industries such as finance, e-commerce, and telecommunications who can now perform both batch and stream processing in one unified platform. Businesses can use Apache Flink for modern applications such as fraud detection, personalized recommendations, stock market analysis, and machine learning.
Apache Flink® Architecture and Key Components
While Kafka Streams is a library that runs as part of your application, Flink is a standalone stream processing engine that is deployed independently. Apache Flink runs your application in a Flink cluster that you deploy. It provides solutions to the hard problems faced by distributed stream processing systems, such as fault tolerance, exactly-once delivery, high throughput, and low latency. These solutions involve checkpoints, savepoints, state management, and time semantics.
Flink's architecture is designed for both stream and batch processing. It can handle unbounded data streams and bounded data sets, allowing for real-time data processing and data analysis. Flink also ensures data integrity and consistent snapshots, even in complex event processing scenarios.
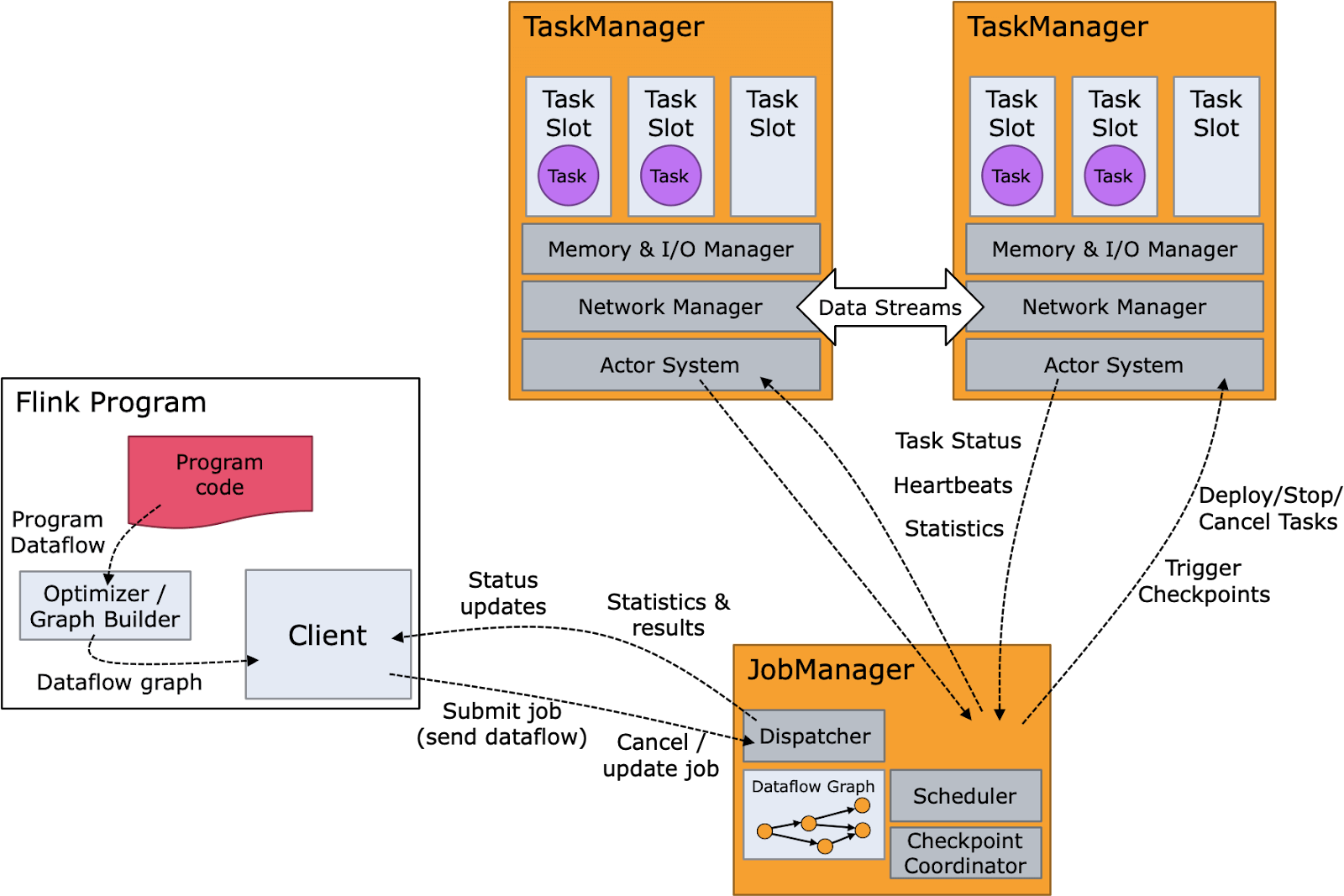
The diagram below shows the Flink components as well as the Flink runtime flow. The program code or SQL query is composed into an operator graph which is then submitted by the client to a job manager. The job manager breaks the job into operators which execute as tasks on nodes that are running task managers. These tasks process streaming data and interact with various data sources, such as the Hadoop Distributed File System (HDFS) and Apache Kafka.
Advantages of Using Apache Flink
Apache Flink is a popular choice due to its robust architecture and extensive feature set. Its features include sophisticated state management, savepoints, checkpoints, event time processing semantics, and exactly-once consistency guarantees for stateful processing.
Flink’s stateful stream processing allows users to define distributed computations over continuous data streams. This enables complex event processing analytics on event streams such as windowed joins, aggregations, and pattern matching.
Flink can:
- Handle both bounded and unbounded streams, unifying batch and stream processing under the same umbrella.
- Run stateful applications at virtually any scale. It can process data parallelized into thousands of tasks distributed across multiple machines and efficiently handle large data sets.
- Use its layered APIs to handle streams at different levels of abstraction. This gives developers the flexibility required to handle common as well as specialized stream processing use cases.
Flink also has connectors for messaging and streaming systems, data stores, search engines, and file systems like Apache Kafka, OpenSearch, Elasticsearch, DynamoDB, HBase, and any database providing a JDBC client. It also provides various programming interfaces, including the high-level Streaming SQL and Table API, the lower-level DataStream API, and the ProcessFunction API for fine control. This flexibility allows developers who use Flink to use the right tool for each problem and supports both unbounded streams and bounded data sets.
It also supports multiple programming languages, including Java, Scala, Python, and other JVM languages like Kotlin, making it a popular choice among developers.
Use Cases of Apache Flink
Although built as a generic data processor, Flink’s native support of unbounded streams contributed to its popularity as a stream processor. Flink’s common use cases are very similar to Kafka’s use cases, although Flink and Kafka serve slightly different purposes. Kafka usually provides the event streaming while Flink is used to process data from that stream. Flink and Kafka are commonly used together for:
- Batch processing: Flink is good at processing bounded data sets, suitable for traditional batch processing tasks.
- Stream processing: Flink handles unbounded data streams for continuous, real-time processing.
- Event-driven applications: Flink’s event stream capabilities make it valuable for fraud detection, credit card systems, and process monitoring.
- Update stateful applications (savepoints): Flink’s stateful processing and savepoints ensure consistency during updates or failures.
- Streaming applications: Real-time data processing to complex event pattern detection.
- Data analytics (batch, streaming): Ideal for real-time and historical data analysis.
- Data pipelines/ETL: Flink is used in building pipelines for ETL processes.
Explore Kafka 101 on Confluent Developer
Challenges With Apache Flink
Apache Flink has a complex architecture. It can be difficult to learn and challenging even for seasoned practitioners to operate and debug.
Perhaps a bit more than most distributed systems, Flink poses difficulties with deployment and cluster operations, such as tuning performance or resolving checkpoint failures.
Organizations using Flink tend to require teams of experts dedicated to developing and maintaining it, making it more feasible for large enterprises.
Flink vs. Kafka vs. Spark and When to Use Them
Kafka Streams is a client library for stream processing, particularly when input and output data are stored in Kafka. Because it's part of Kafka, it leverages the benefits of Kafka natively.
ksqlDB layers SQL simplicity onto Kafka Streams, broadening accessibility for stream processing.
Kafka users and Confluent customers often turn to Apache Flink for stream processing needs for reasons such as large intermediate state, multi-cluster processing, and hybrid stream scenarios.
Because Flink is its own distributed system, its benefits must be weighed against complexity and cost, especially when Kafka Streams or Spark may suffice.
Benefits of Fully Managed Flink with Confluent
By offering Apache Flink as a fully managed cloud service, Confluent removes the operational complexity so developers can focus on logic instead of infrastructure.
This integration brings Flink’s capabilities to Confluent Cloud, enabling broader adoption and flexible, unified stream processing at scale.
Learn More Try Managed Kafka + Flink
Confluent Chronicles: The Force of Kafka + Flink Awakens
Introducing the second issue of the Confluent Chronicles comic book! Inside you’ll find a fun and relatable approach to learn about stream processing, Apache Flink, and why Flink and Kafka are better together.
