[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Apache Kafka® vs Pub/Sub: Choosing the Right Platform for Real-Time Architectures
When it comes to building real-time, event-driven systems, two technologies often come up in conversation, Apache Kafka® and Google Pub/Sub. But while both are designed to help applications communicate through events, they take very different paths to get there.
In this guide, we’ll unpack the key differences between distributed, log-based event streaming with Kafka and serverless, asynchronous messaging with Google Pub/Sub.



By the end, you’ll have a clear sense of how each compares against your needs for speed, low latency, and high fault tolerance and why these two technologies often coexist in modern data architectures.
A Concise Comparison Kafka vs. Google Pub/Sub Across 9 Key Dimensions
|
Feature |
Apache Kafka |
Google Pub/Sub |
|
Architecture |
Distributed log-based system |
Managed push-pull message service |
|
Message Retention |
Configurable, can retain indefinitely |
Limited (7–31 days), deleted after acknowledgment |
|
Ordering |
Strong ordering within partitions |
Best-effort ordering (ordering keys available, but not global) |
|
Delivery Semantics |
Exactly-once, at-least-once, at-most-once |
At-least-once or at-most-once |
|
Performance |
Predictable high throughput |
Scales automatically, less tuning control |
|
Persistence |
Durable log; events can be replayed anytime |
Temporary storage focused on delivery, not replay |
|
Integrations |
Open ecosystem, connectors, Flink, ksqlDB, Schema Registry |
Tight integration within GCP (BigQuery, Dataflow) |
|
Deployment |
Self-managed or managed (e.g. Confluent Cloud) |
Fully managed by Google |
|
Cost Model |
Infrastructure-based or managed service |
Pay-per-message or data volume |
For an in-depth architectural walkthrough of Kafka’s design and ecosystem by taking the Kafka architecture course on Confluent Developer.
An Overview: How Does Kafka’s Architecture Differ From Google Pub/Sub?
Apache Kafka acts as a continuous log that stores events in order and lets multiple systems read them whenever they need. In contrast, Google Cloud Pub/Sub is a fully managed messaging service. You publish an event, and Google delivers it to whoever needs it, no servers, clusters, or scaling headaches.
Think of it like this:
-
Kafka is the heavy-duty engine that keeps all events and/or real-time data flowing across the company.
-
Pub/Sub is the easy, plug-and-play messaging layer for applications and services running in Google Cloud.
When Should You Choose Event Streaming vs. Simple, Lightweight Messaging?
Even though Kafka and Pub/Sub can be used on their own, a lot of companies actually run them side-by-side. It usually happens when a team wants the streaming power of Kafka, but also loves the convenience and serverless scale that Pub/Sub gives them inside Google Cloud.
Imagine you're building a payment system. All your payments, fraud alerts, and transaction logs flow through Kafka for durability, replay, and analytics. At the same time, your mobile app backend runs on Google Cloud and uses Pub/Sub to send user notifications or account updates since it’s lightweight, fast, and fully managed.
To bring everything together, you connect the two systems so that key events from Pub/Sub are also streamed into Kafka to enable real-time analytics and reporting.
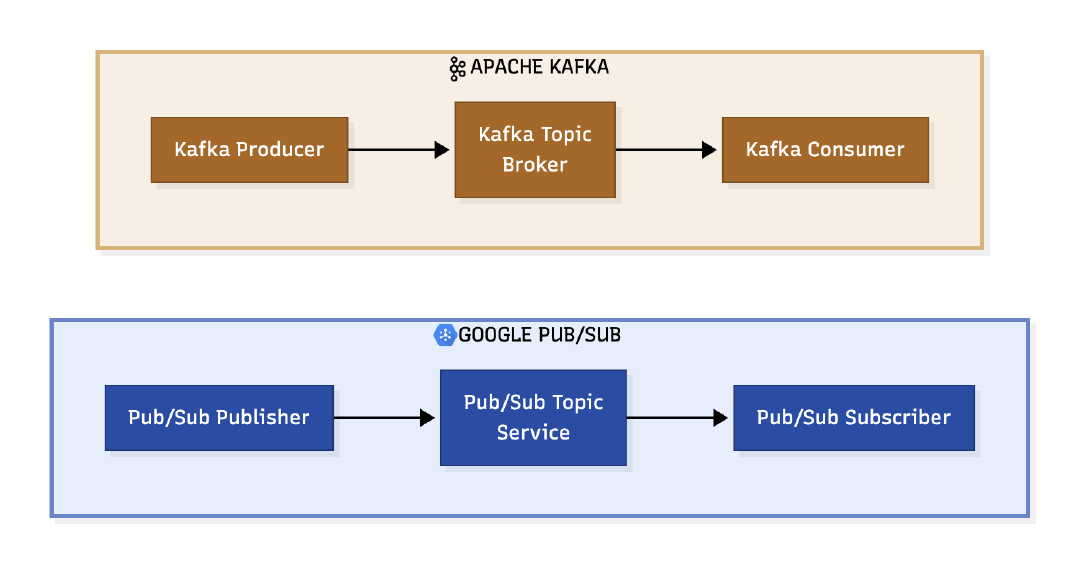
Architecture and Design: When Are Event Logs vs. Messages Right for Asynchronous Communication?
Although Kafka and Pub/Sub are both used for asynchronous communication, they are built on very different foundations, and that shapes how each behaves in real-world systems.
Kafka is fundamentally a log-based, partitioned storage system. When events come in, they are written to a durable, append-only log or topic that is split into multiple partitions, stored on disk across brokers. Kafka consumers read from that log at their own pace, and data can be replayed at any time, whether minutes or months later. Each partition acts as an independent, ordered log, and different consumer groups read from these partitions for parallel processing.
This distributed design gives Kafka a few important characteristics:
-
Event order is deterministic within a partition
-
Data is durable and retained as long as you configure it
-
Consumers control their own offsets and can re-read data
-
Ideal for stream processing, audit trails, and long-lived pipelines
If you think of events as a sequence that needs to be stored, processed, and replayed, Kafka behaves like a high-performance distributed log system rather than a simple message broker.
Google Pub/Sub is a managed push-pull messaging service designed for simple, scalable event delivery with a fan-out delivery pattern. A publisher sends events to a topic that fans out to multiple subscriptions. And as messages are delivered to subscribers, acknowledgements are tracked, and then messages eventually expire from the system. Each subscription receives a full copy of the event stream, and each subscriber consumes from its own subscription independently.
Key traits of this architecture include:
-
Ephemeral storage, data isn't meant to live long
-
Best-effort ordering, with optional ordering keys
-
No concept of consumer-controlled offsets
-
Focuses on delivery, fan-out, and serverless simplicity
Instead of replaying long event streams, Pub/Sub is built to get messages to subscribers quickly and reliably without requiring teams to run any infrastructure.
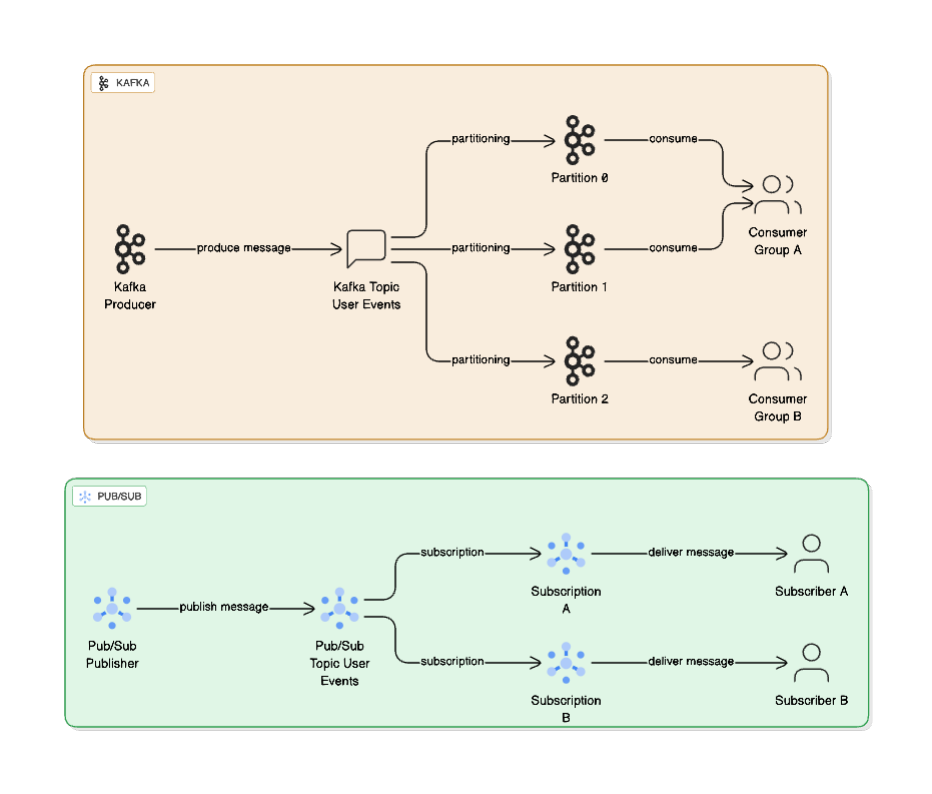
Comparing Data Retention and Replay Capabilities
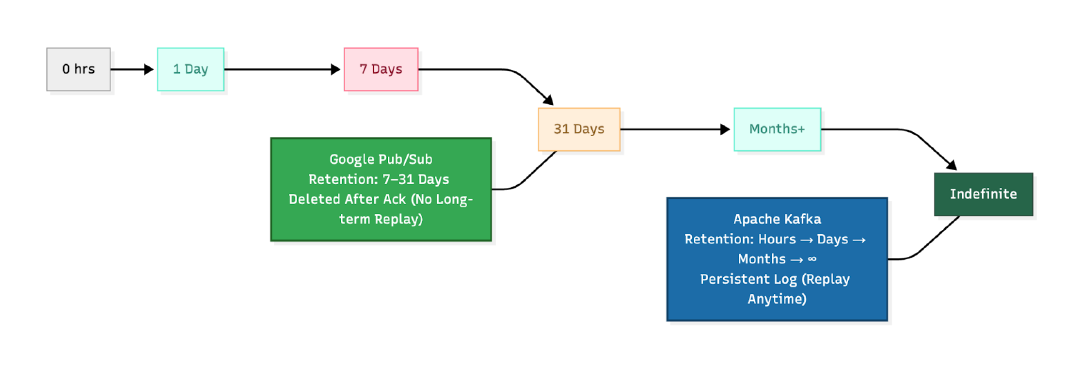
Kafka supports long-term storage and full replay, making it well-suited for systems that need auditing, analytics, or fault recovery. In contrast, Google Pub/Sub provides short-term message retention and focuses on eventual delivery, not historical event access.
Kafka can retain events for any duration you configure, ranging from just a few hours for fast-moving streams to several months or even indefinitely for compliance & auditing use cases.
-
Since Kafka stores events in a persistent log, consumers have the ability to replay data at any time.
-
They can start from the newest event, rewind to a specific point in time, or reprocess the entire stream.
-
This flexibility is invaluable for debugging, maintaining audit trails, re-running analytics jobs, or restoring downstream systems after a failure.
In Google Pub/Sub, once a subscriber acknowledges a message, it’s removed, and retention is short-term
-
Data retention in Pub/Sub is set to 7 days by default and limited to a maximum of 31 days.
-
While Pub/Sub can redeliver unacknowledged messages, it’s not designed for long-term replay or historical processing.
-
Its model is built around timely delivery, not keeping a long archive of events.
If your system needs to rewind data or reprocess events, Kafka’s replay model gives you far more control.
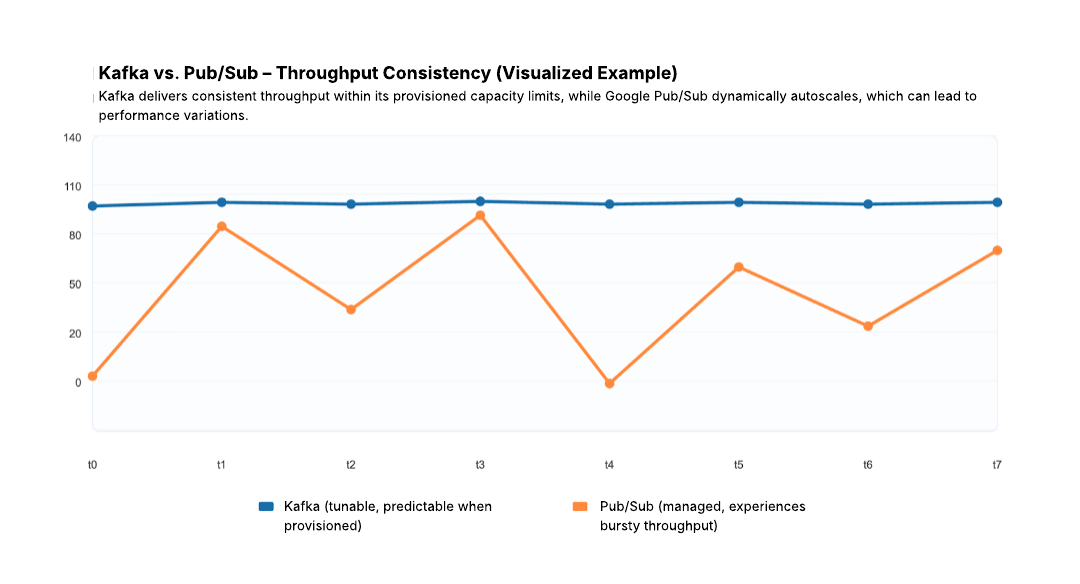
Performance, Scaling, and Latency With Kafka vs. Google Pub/Sub
Both Kafka and Pub/Sub are designed to handle large event volumes, but they take very different approaches to scaling and performance tuning. If your workloads are bursty and cloud-native, Google Pub/Sub is easy and efficient. If they are sustained, high-throughput streams where latency guarantees matter, Kafka tends to perform more consistently.
Kafka scales horizontally through partitioning–if you need more throughput, you add brokers and increase partitions, distributing the load across the cluster.
-
Because you control the resources and configuration, performance is predictable especially when dealing with steady, high-volume workloads.
-
Teams that need consistent latency and tight control over throughput often prefer Kafka for this reason.
-
Kafka is ideal when you need reliable, consistent performance at scale and want control over how the system behaves.
Pub/Sub, on the other hand, scales automatically without any operational effort, no servers, no partitions, no capacity planning.
-
Google Cloud quietly handles scaling behind the scenes.
-
The trade-off is that you don’t get the same visibility or tuning options. You trust the platform to scale, but you can’t always fine-tune behavior under specific patterns or traffic surges.
-
This makes Pub/Sub a great fit when you want hands-off scaling and low operational overhead, even if that means giving up fine-grained tuning.
Ecosystem and Available Integrations for Kafka vs. Google Pub/Sub
This is one of the areas where your broader platform strategy matters a lot.
Kafka sits at the center of a large, open ecosystem.
-
It connects to almost anything: databases, data warehouses, software-as-a-service (SaaS) platforms, and stream processing engines like Apache Flink® and ksqlDB.
-
There are hundreds of ready-to-use Kafka connectors, and the platform works across AWS, Azure, Google Cloud, and on-premises environments.
-
If you're building a hybrid or multicloud data pipeline, Kafka gives you the flexibility to plug into whatever systems you need.
Pub/Sub, on the other hand, fits naturally inside the Google Cloud ecosystem.
- It integrates straight out of the box with services like BigQuery, Dataflow, Cloud Run, Cloud Functions, and GKE.
-
That tight coupling makes it extremely smooth for handling events across GCP services, with no extra setup or connector management.

Reliability and Delivery Guarantees for Kafka vs. Google Pub/Sub
Reliability is one of the biggest deciding factors when choosing between Kafka and Pub/Sub, and the two systems take noticeably different approaches here.
Kafka provides stronger delivery and ordering guarantees and is designed for workloads where correctness matters more than convenience. Pub/Sub focuses on reliable, scalable delivery with minimal operational overhead, and works best when applications can tolerate some duplication or handle idempotency logic.
Kafka is built with strong delivery guarantees and strict ordering at its core.
-
It supports exactly-once semantics (EOS) end-to-end, meaning data will not be duplicated and will not be lost, even during retries, failures, or restarts.
-
Combined with deterministic ordering within partitions, it allows applications to trust that events are processed in the correct sequence, and only once.
-
This makes Kafka extremely attractive for financial transactions, fraud detection, regulated data flows, industrial IoT systems, and other environments where a single missed or duplicated event can cause real-world consequences.
Pub/Sub offers at-least-once or at-most-once delivery, depending on how consumers are configured.
-
It prioritizes reliable delivery and scale, but may occasionally deliver duplicates or, in rare cases, drop messages.
-
While this is perfectly acceptable for cloud events, notifications, and microservice communication, it doesn’t guarantee the hard consistency needed for certain mission-critical pipelines.
Core Differences Between Kafka and Google Pub/Sub for Reliability, Delivery Guarantees, Ordering, and Replay Behavior
|
Feature |
Kafka |
Pub/Sub |
|
Ordering |
Strong ordering (per partition) |
Best-effort ordering |
|
Semantics |
Exactly-once, at-least-once, or at-most-once (configurable) |
At-least-once / at-most-once |
|
Replay |
Full replay from log |
Limited replay window |
|
Overhead |
Operational control |
Fully managed |
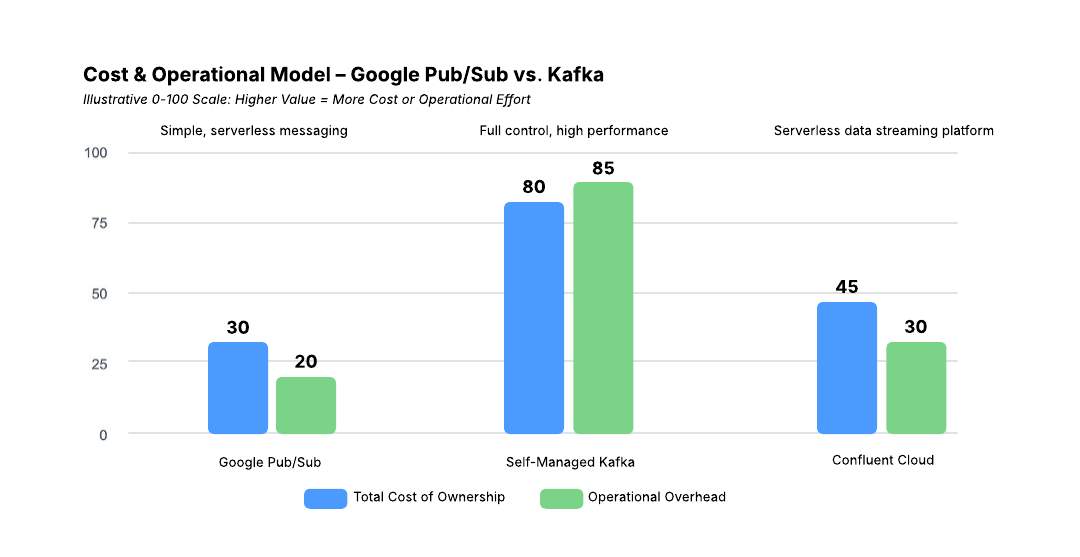
What Are the Cost and Operational Model Tradeoffs for Kafka vs. Google Pub/Sub?
Cost and operations often influence the technology decision as much as features do. If your team wants to avoid infrastructure management entirely and is already using Google Cloud, Pub/Sub can be very appealing. If you need high throughput, durability, and control over data pipelines, Kafka delivers, and with managed services, it can be just as operationally simple.
Kafka gives you more control, but historically, its streaming capabilities come with tradeoffs like more responsibility, feature gaps to fill, and increased overhead.
-
Running Kafka yourself means provisioning brokers, managing storage, handling security, scaling clusters, and monitoring performance.
-
That offers flexibility and tuning power, but increases operational overhead and total cost of ownership (TCO), especially at larger scale.
Google Pub/Sub uses a fully managed, pay-per-use model.
-
You pay based on message volume and data transfer, and Google handles everything behind the scenes, infrastructure, scaling, upgrades, resilience, and failover.
-
This makes it attractive for teams that want fast adoption, predictable operations, and no DevOps burden. There’s nothing to patch, tune, or capacity-plan, which keeps ongoing complexity low and speeds up development.
However, this picture changes when organizations use managed Kafka services, such as Confluent Cloud. These services remove most of the operational burden while preserving Kafka’s strengths, providing a middle ground between full control and full convenience.
When Should You Choose to Use Kafka vs. Google Pub/Sub?
Choosing between Kafka and Pub/Sub really comes down to the type of system you're building and where your data needs to go.
Kafka shines when you're handling continuous streams of data that need to be processed, stored, and replayed. If your architecture spans multiple environments—on-prem, multicloud, or hybrid cloud—Kafka gives you the flexibility and control to move data wherever it needs to be. It’s also the better choice when real-time analytics, event-driven applications, or large-scale data pipelines are the priority.
Pub/Sub, by contrast, fits naturally into cloud-native GCP environments. If your services already run on Google Cloud, and you simply need reliable, low-latency messaging for event-driven microservices or serverless workloads, Pub/Sub is fast to adopt and effortless to maintain.
Kafka vs Google Pub/Sub Evaluated for Common Architectural Scenarios
|
Scenario |
Best Choice |
|
Real-time analytics and streaming pipelines |
Kafka |
|
Cross-cloud or hybrid data movement |
Kafka |
|
Cloud-native Google Cloud workloads |
Pub/Sub |
|
Lightweight messaging for microservices |
Pub/Sub |
|
Long-term retention and replay |
Kafka |
|
Quick setup with no operational complexity |
Pub/Sub |
In many modern architectures, the two even work together: Pub/Sub can ingest events from GCP applications, and Kafka via Confluent integrations can handle enterprise-wide streaming and analytics across environments.
How Does Serverless Kafka Change the Kafka vs. Google Pub/Sub Comparison?
Self-managing Kafka means handling cluster deployment, scaling, upgrades, monitoring, security, storage, and failover. For many teams, that operational overhead competes with the real goal: choosing the right technology for building reliable, real-time data pipelines and applications for use cases that require low latency and high fidelity.
Confluent Cloud delivers serverless Kafka as the core of its fully managed data streaming platform. You get the performance and reliability Kafka is known for, without needing to operate or maintain the underlying infrastructure.
This means:
-
You don’t provision or tune servers the platform scales automatically
-
You don’t install or upgrade components updates are handled for you
-
You don’t need separate tools for governance, processing, and connectors they’re built in
-
You get a consistent streaming platform across cloud providers and regions
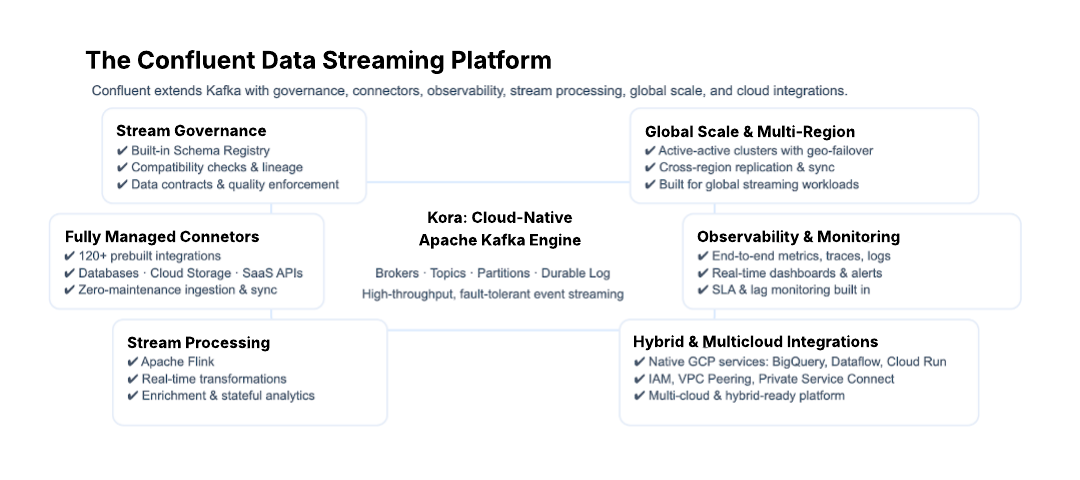
Confluent extends Kafka beyond event streaming and real-time data processing into a complete cloud-native platform capable of quickly bringing complex, high-impact streaming use cases into production.
Next Steps in Evaluating Kafka and Google Pub/Sub
Apache Kafka and Google Pub/Sub each have strengths they simply serve different needs.
-
Choose Kafka if you need real-time streaming, replay, rich integrations, and cross-cloud flexibility.
-
Choose Pub/Sub if you want simple, reliable, cloud-native messaging inside Google Cloud with zero management.
And if you want Kafka’s durability, replay, and rich ecosystem with the ease of a fully managed service, Confluent Cloud offers a practical middle path especially for teams operating across clouds or scaling streaming workloads globally.
- Sign up for a free trial of Confluent Cloud.
- Get hands-on with Confluent Cloud in minutes with this quick start on Confluent Developer.
- Check out a full comparison of Apache Kafka vs. Confluent.
- Explore the deep dive product comparison of Google Pub/Sub vs. Confluent.
Kafka vs. Pub/Sub – FAQs
What’s the main difference between Kafka and Pub/Sub?
Kafka is a distributed log-based platform built for long-term data streaming and replay. Pub/Sub is a managed messaging service designed for fast, short-lived event delivery.
Which is better for real-time analytics?
Kafka is generally better suited for real-time analytics, event streaming, and continuous data processing because its strict ordering, data durability, and replayability give you the flexibility and control to move real-time and historical data wherever it needs to be analyzed while ensuring accuracy.
Does Pub/Sub support data replay like Kafka?
Not in the same way. Pub/Sub retains messages for a limited time (7–31 days), while Kafka can replay data for as long as you configure retention.
Can Kafka integrate with Google Cloud?
Yes, Kafka integrates well with Google Cloud via the Confluent connector for Pub/Sub, allowing seamless data flow between environments.
Is Kafka more expensive than Pub/Sub?
Self-managed Kafka can be, due to infrastructure and maintenance tasks, as well as hidden operations and engineering costs. Managed services like Confluent Cloud simplify operations by removing self-management responsibilities, automating and optimizing Kafka scaling, ultimately reducing TCO by up to 70%.
Is Kafka more scalable than Google Pub/Sub?
Kafka is technically more scalable for high-performance, low-latency workloads because its partition-based architecture allows for massive parallel processing and deeper hardware tuning, often handling higher throughput with lower latency. However, as a messaging queue service, Google Pub/Sub has a simpler architecture that can automatically scale to handle millions of messages per second without requiring the manual partition management or cluster rebalancing that Kafka demands.
So while Kafka gives organizations that need event streaming or real-time data processing more control to reach extreme scales, Pub/Sub can scale more effortlessly for unpredictable or globally distributed workloads for certain workloads on Google Cloud.
Does Google Pub/Sub support ordering?
Yes, Google Pub/Sub supports message ordering, but it is not enabled by default and requires specific configuration on both the publisher and subscriber sides. To ensure messages are processed in sequence, you must provide an “ordering key” when publishing and explicitly enable "message ordering" on the subscription settings.
When these are active, Pub/Sub guarantees that messages with the same key published in the same region will be delivered in the order they were received by the service. It is important to note that enabling ordering can increase latency and that ordering is only guaranteed within a specific key, not across different keys or regions.