Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies or Frenemies?
Typically, an enterprise service bus (ESB) or other integration solutions like extract-transform-load (ETL) tools have been used to try to decouple systems. However, the sheer number of connectors, as well as the requirement that applications publish and subscribe to the data at the same time, mean that systems are always intertwined. As a result, development projects have lots of dependencies on other systems and nothing can be truly decoupled.
This blog post shows why so many enterprises leverage the ecosystem of Apache Kafka® for successful integration of different legacy and modern applications, and how this differs but also complements existing integration solutions like ESB or ETL tools.
The need for integration is a never-ending story. No matter in which enterprise you work, no matter when your company was founded, you will have the requirement to integrate your applications to implement your business processes.
This includes many different factors:
- Technologies (standards like SOAP, REST, JMS, MQTT, data formats like JSON, XML, Apache Avro or Protocol Buffers, open frameworks like Nginx or Kubernetes, and proprietary interfaces like EDIFACT or SAP BAPI)
- Programming languages and platforms like Cobol, Java, .NET, Go or Python
- Application architectures like Monolith, Client Server, Service-oriented Architecture (SOA), Microservices or Serverless
- Communication paradigms like batch processing, (near) real-time, request-response, fire-and-forget, publish-subscribe, continuous queries, and rewinding
Many enterprise architectures are a bit messy—something like this:
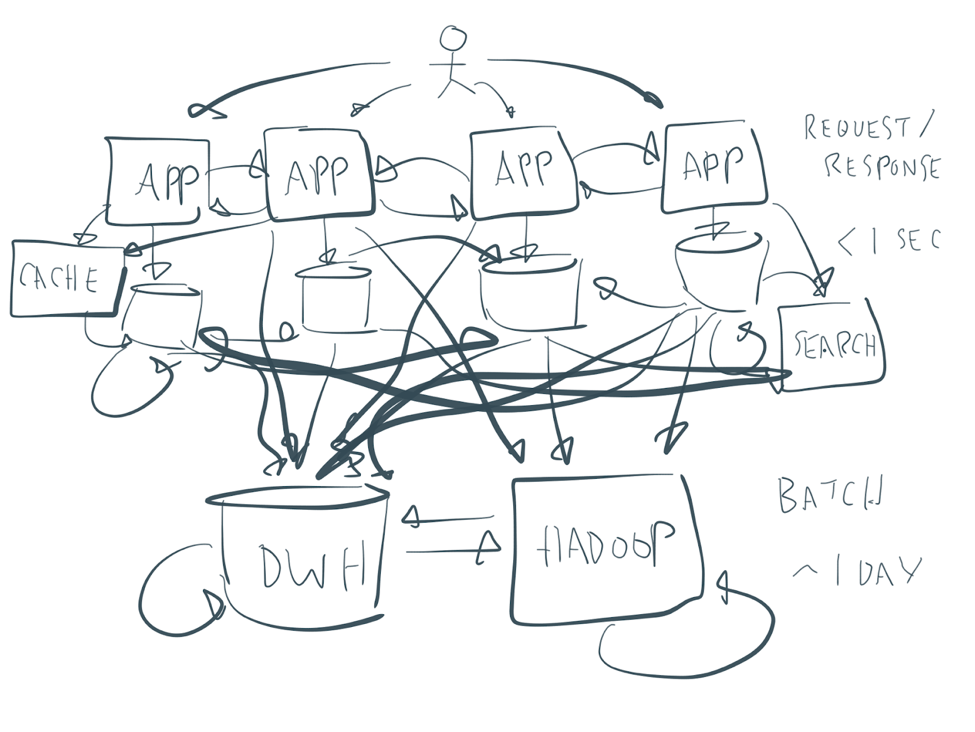 Every company needs to solve these spaghetti architectures. Depending on the decade, you either bought something like an ETL tool to build batch pipelines or an ESB to design an SOA. Some products also changed their names. Today, you are offered things like middleware messaging, an integration platform, a microservice gateway, or API management. The branding and product name do not matter.
Every company needs to solve these spaghetti architectures. Depending on the decade, you either bought something like an ETL tool to build batch pipelines or an ESB to design an SOA. Some products also changed their names. Today, you are offered things like middleware messaging, an integration platform, a microservice gateway, or API management. The branding and product name do not matter.
You always see the same picture as a solution to move away from your spaghetti architecture to a central integral box in the middle, like this:
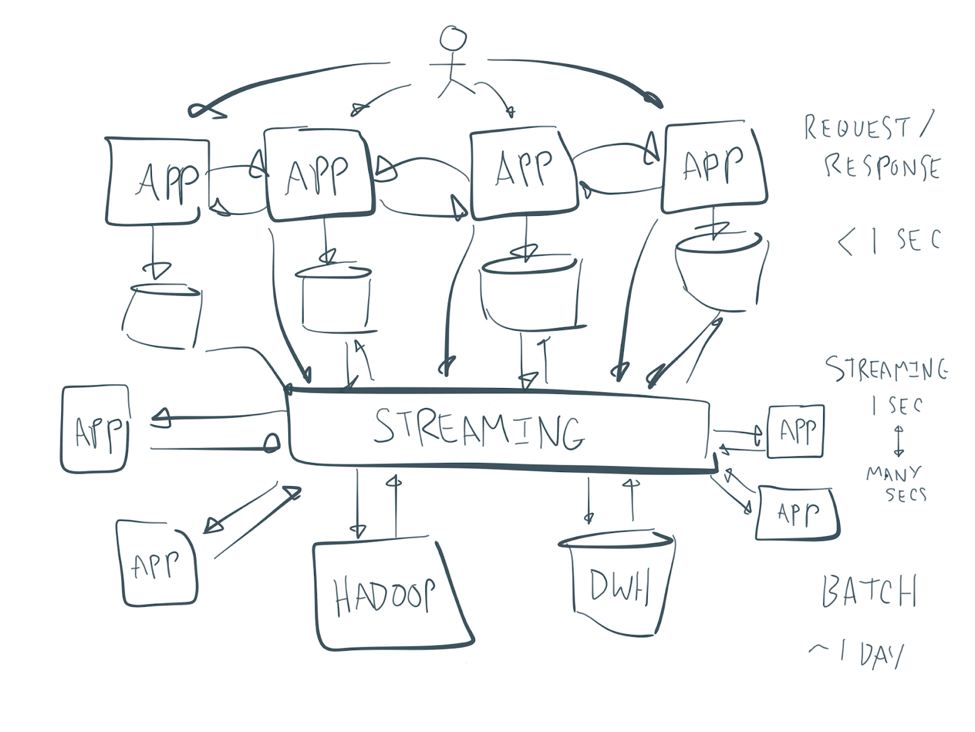
This rarely worked well in practice, unfortunately. Most SOA projects in the last two decades failed. Instead of using an ETL tool or ESB for this, enterprises are now moving on to a streaming platform to solve this issue. Is this the next bubble on the market? Just a new term?
Or, did something change to allow successful integration across an enterprise—whether you integrate legacy mainframes, standard applications like CRM and ERPs, modern microservices built with any programming platform, or public cloud services?
Why are companies now migrating to Apache Kafka to build this streaming platform? Why is everybody happy and talking about this at conferences, tech talks, and blog posts? How does it compare to an ESB or ETL tool?
The next sections will answer all these questions, and explain the reason and differences between the ecosystem of Apache Kafka and other existing integration solutions.
Event-driven processing and streaming as a key concept in the enterprise architecture
An event streaming platform (you can also enter another buzzword here) leverages events as a core principle. You think in data flows of events and process the data while it is in motion.
Many concepts, such as event sourcing, or design patterns such as Enterprise Integration Patterns (EIPs), are based on event-driven architecture. The following are some characteristics of a streaming platform:
- Event-based data flows as a foundation for (near) real-time and batch processing. In the past, everything was built on data stores (data at rest), making it impossible to build flexible, agile services to act on data while it is relevant.
- Scalable central nervous system for events between any number of sources and sinks. Central does not mean one or two big boxes in the middle but a scalable, distributed infrastructure, built by design for zero downtime, handling the failure of nodes and networks and rolling upgrades. Different versions of infrastructure (like Kafka) and applications (business services) can be deployed and managed in an agile, dynamic way.
- Integrability of any kind of applications and systems. Technology does not matter. Connect anything: programming language, APIs like REST, open standards, proprietary tools, and legacy applications. Speed does not matter. Read once. Read several times. Read again from the beginning (e.g., add a new application, and train different machine learning models with the same data).
- Distributed storage for decoupling applications. Don’t try to build your own streaming platform using your favorite traditional messaging system and in-memory cache/data grid. There is a lot of complexity behind this and a streaming platform simply has it built-in. This allows you to store the state of a microservice instead of requiring a separate database, for example.
- Stateless service and stateful business processes. Business processes typically are stateful processes. They often need to be implemented with events and state changes, not with remote procedure calls and request-response style. Patterns like event sourcing and CQRS help implement this in an event-driven streaming architecture.
Benefits of a streaming platform in the enterprise architecture
A streaming platform establishes huge benefits for your enterprise architecture:
- Large and elastic scalability regarding nodes, volume, and throughput—all on commodity hardware, in any public cloud environments, or via hybrid deployments.
- Flexibility of architecture. Build small services, big services, sometimes still even monoliths.
- Event-driven microservices. Asynchronously connected microservices model complex business flows and move data to where it is needed.
- Openness without commitment to a unique technology or data format. The next new standard, protocol, programming language, or framework is coming for sure. The central streaming platform is open even if some sources or sinks use a proprietary data format or technology.
- Independent and decoupled business services, managed as products, with their own lifecycle regarding development, testing, deployment, and monitoring. Loose coupling allows for independent speed of processing between different producers and consumers, on/offline modes, and handling backpressure.
- Multi-tenancy to ensure that only the right user can create, write to, and read from different data streams in a single cluster.
- Industrialized deployment using containers, DevOps, etc., deployed where needed, whether on-premise, in the public cloud, or in a hybrid environment.
These characteristics build the foundation of a streaming platform, the beginning of your successful digital transformation. With services implementing a limited set of functions, and services being developed, deployed, and scaled independently, you get shorter time to results and increased flexibility. This is only possible with a streaming platform having the above characteristics.
Use cases for a streaming platform
Here are some generic scenarios for how you can leverage a streaming platform with the characteristics discussed above:
- Event-driven processing of big data sets (e.g., logs, IoT sensors, social feeds)
- Mission-critical, real-time applications (e.g., payments, fraud detection, customer experience)
- Decoupled integration between different legacy applications and modern applications
- Microservices architecture
- Analytics (e.g., for data science, machine learning)
Producers and consumers of different applications are decoupled. They scale independently at their speed and requirements. You can add new applications over time, both on the producer and consumer side. Often, one event is required to be consumed by many independent applications to complete the business process. For example, a hotel room reservation needs immediate payment fraud detection in real-time, the ability to process the booking through all backend systems in near real-time, and overnight batch analytics to improve customer 360, aftersales, hotel logistics, and other business processes.
While some processes need real-time processing, you also need to be capable of supporting batch processes. You even need re-consumption of data more often than you would think in the beginning, such as in cases of an application being down for some time, A/B testing with different versions of an application, adding a new application that needs to consume the data from scratch, or building different analytic models via machine learning based on the same data sets.
Think about some more use cases that you can build easily with a real decoupled system that is still a well-integrated and scalable streaming platform:
- Selling before the customer left the store
- Aborting a transaction before the fraud happened
- Replacing a part of a manufacturing machine before it breaks
- Informing customers if a flight or train is late (plus sending updates, rebooking or a voucher)
- You name it—the list goes on.
Big bang from batch to real-time?
Now, you understand the added value of a real decoupled, scalable streaming platform. So, do I have to introduce this as a central data platform for all of our applications?
Caution! No mature enterprise can do a big bang successfully. Legacy applications exist everywhere. Go step by step from pre-streaming to streaming platform. If you come from the mainframe ages, then you might even have batch and non-streaming applications forever (or realistically at least for the next 20-30 years). That’s fine. You just need to bring the events from these systems into the event-driven central nervous system.
The following shows the streaming maturity model that we use to identify the current situation and planning in large enterprises:
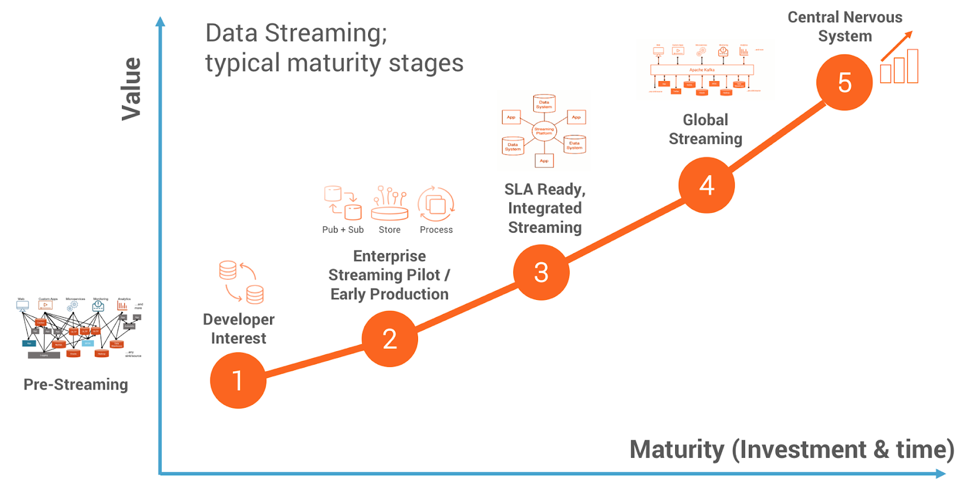
Where you are today?
- Pre-Streaming (Batch or legacy)
- Interest (First proof of concepts or pilots)
- Early Production (Some independent projects in production)
- Integrated Streaming (Streaming platform with different projects in production)
- Event Streaming Platform (Streaming enterprise with mostly event-based applications)
Most traditional enterprises start their journey in the pre-streaming phase. That’s totally fine. The next section explains why almost any successful transformation into a streaming platform leverages the Apache Kafka ecosystem as a key architectural component.
The Apache Kafka ecosystem as a streaming platform
Often people are familiar with Apache Kafka, as it has been a hugely successful open-source project, created at LinkedIn for big data log analytics. That was the beginning of Kafka, and just one of many use cases today. Kafka evolved from a data ingestion layer to a real-time streaming platform for all the use cases previously discussed. Many projects focus on building mission-critical applications around Kafka. It has to be up and performant 24/7. If Kafka is down, their business processes stop working.
Kafka is unique because it combines messaging, storage, and processing of events all in one platform. It does this in a distributed architecture using a distributed commit log and topics divided into multiple partitions, as seen below:
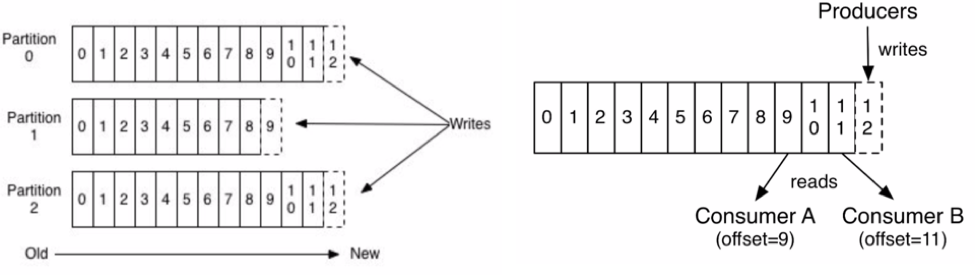
With this distributed architecture, Kafka is different from existing integration and messaging solutions. Not only is it massively scalable and built for high throughput but different consumers can also read data independently of each other and at different speeds.
Applications publish data as a stream of events while other applications pick up that stream and consume it when they want. Because all events are stored, applications can hook into this stream and consume as required—in batch, real-time, or near-real-time. This means that you can truly decouple systems and enable proper agile development. Furthermore, a new system can subscribe to the stream and catch up with historic data up until the present before existing systems are properly decommissioned.
The uniqueness of having messaging, storage, and processing in one distributed, scalable, fault-tolerant, high-volume, technology-independent streaming platform is the reason for the global success of Apache Kafka in almost every bigger company on this planet.
So, what is Apache Kafka and the surrounding ecosystem? Let’s take a high-level look:
Apache Kafka is the core for distributed messaging and storage. High throughput, low latency, high availability, secure.
- Kafka Connect as an integration framework for connecting external sources/destinations into Kafka.
- Kafka Streams as a simple library that enables streaming application development within the Kafka framework.
- Additional clients for non-Java programming languages, including C, C++, Python, .NET, Go, and several others.
- Confluent REST Proxy to provide universal access to Kafka from any network-connected device via HTTP(S).
Confluent Schema Registry as a central registry for the format of Kafka data, guaranteeing that all data is always consumable, including schema evolution.
Confluent KSQL as the streaming SQL engine that enables scalable, high-volume stream processing natively against Apache Kafka without writing source code.
All these components are based on top of the core messaging and storage layer of Apache Kafka, and all leverage its features of high scalability, high volume/throughput, and failover. In addition, Confluent offers 24/7 support and enterprise tooling for end-to-end monitoring, management of Kafka clusters, multi-datacenter replication, and more.
Okay, so we should start evaluating Kafka in a proof of concept (POC)?
POC? Well, the Apache Kafka ecosystem is already battle-tested at a scale that you will probably not reach in the next 5-10 years. Many notable organizations are Kafka users:
- LinkedIn processed over 4.5 trillion messages per day in 2018.
- Netflix processed over 6 petabytes of data per day in 2018.
- Ebay, Uber, Paypal, you-name-it. Just Google your favorite tech giant + Apache Kafka to see how they use Kafka. It is everywhere!
- Even “traditional” companies in banking, insurance, telco, retail, automotive, and manufacturing use Kafka to transform and revolutionize their core business. Public references, including ING Group (banking), Audi (automotive) and Target (retail), to name a few, are available on the web.
Don’t waste your time with POCs about performance, maturity, or scalability. Instead, evaluate how to integrate Kafka into your enterprise architecture to evolve business scenarios and innovate toward digital transformation.
Should we replace our existing MQ and ESB deployments?
Younger companies like Netflix, LinkedIn, and Zalando built their whole infrastructure on Kafka. Older companies are not that fortunate because they have plenty of mainframes, monoliths, and legacy technology. However, as discussed, a Big Bang replacement is not the right way to be successful. It’s a lot like transforming your home. Although it might make sense in theory to rebuild it from the ground up, oftentimes it is more practical to extend the house, change certain rooms, or redecorate.
It’s difficult to just rip and replace mission-critical applications that are deeply integrated with other apps that work and involve a skilled team operating them. That said, sometimes it may be more cost effective to replace legacy architecture, just like it sometimes does make sense to remodel a house from the ground up. This was the case with Sberbank, the biggest bank in Russia, which built their complete core banking system around Kafka as central nervous system.
Apache Kafka and other middleware as complementary components
Legacy apps are typically based on complex data formats like EDIFACT, use complex interfaces like CORBA, or are built with an unmaintainable and inflexible programming language like Cobol. You cannot simply turn it off, or cut it out and replace it. This has to be done step by step. Legacy and modern applications co-exist to run the existing business and add new offerings to augment it.
Innovate by integrating your old systems via a streaming platform—i.e., the Apache Kafka ecosystem. Use concepts like change data capture (CDC) and integration tools, such as an ESB or ETL, with great graphical tooling and connectors for legacy applications.
With this foundation, you can build new applications with modern technologies, big data systems, machine learning, etc., natively around Apache Kafka, and at the same time keep access to your legacy events, which you still need for added value in new projects.
Real decoupling and technology independence also mean that you have dumb pipes and smart endpoints. If you build all the integration logic (or, even worse, some business logic) into the central integration layer, then all your scalability, agility, and independence of the different systems are gone.
This is a key difference to traditional integration solutions in which you put all the logic in the middle layer ESB. It creates a dependency on this (proprietary) technology/API, as well as inflexibility.
Smart endpoints can be anything. You can leverage the Kafka ecosystem to build applications around Kafka with Kafka Streams, KSQL, or any Kafka client like Java, .Net, Python, or Go. You can also use any other application to integrate other applications with Kafka. The secret to long-term success is that the infrastructure is open to any technology and architectural pattern.
ETL and ESB have excellent tooling, including graphical mappings for doing complex integration with SOAP, EDIFACT, SAP BAPI, COBOL, etc. (Trust me, you don’t want to write the code for this.) It is already running, paid, and integrated. Therefore, existing MQ and ESB solutions, which already integrate with your legacy world, are not competitive with Apache Kafka. Rather, they are complementary! Leverage them like you did in the past to integrate with the old world. You can use the following:
- Confluent JMS connector for IBM MQ and other JMS brokers
- Kafka Connect CDC connectors for mainframe and databases
- ESB or ETL tools, which integrate with legacy protocols (SOAP, EDIFACT, etc.) and applications (SAP, Siebel, etc.). All these tools also have Kafka connectors in the meantime.
- Traditional messaging brokers also have a proxy to Kafka in the meantime. Even though some time ago they told everybody that you cannot build a universal messaging platform, traditional messaging brokers now integrate into Kafka and other standards like MQTT to not become forgotten
- Kafka’s official low-level client APIs like Java, .NET, Go, and Python implement a direct integration if no other more feasible integration option is available.
As a last note, after explaining the usage of ESB and ETL tools in the Kafka world, I quote ThoughtWorks to remind you not to try building a new ESB around Kafka:
Some organizations recreate ESB antipatterns with Kafka by centralizing the Kafka ecosystem components—such as connectors and stream processors—instead of allowing these components to live with product or service teams.
This reminds us of seriously problematic ESB antipatterns, where more and more logic, orchestration, and transformation were thrust into a centrally managed ESB, creating a significant dependency on a centralized team. We’re calling this out to dissuade further implementations of this flawed pattern.
Source
Apache Kafka and its ecosystem are designed as a distributed architecture with many smart features built-in to allow high throughput, high scalability, fault tolerance, and failover!
Let the product or service teams build their applications with Kafka Streams, KSQL, and any other Kafka client API. Integrate Kafka with ESB and ETL tools if you need their features for specific legacy integration. An ESB or ETL process can be a source or sink to Apache Kafka like any other Kafka producer or consumer API. Oftentimes, the integration with legacy systems using such a tool is built and running already anyway.
Currently, all these tools also have a Kafka connector because the market drives them this way. So, you just need to combine the existing integration with the Kafka connector, and there you have it: flexible, scalable, and highly available integration between legacy and future ecosystems through Kafka.
Apache Kafka as a streaming platform between legacy and the new modern world
Apache Kafka is an open-source streaming platform that allows you to build a scalable, distributed infrastructure that integrates legacy and modern applications in a flexible, decoupled way. It is already battle-tested for processing trillions of messages and petabytes of data per day.
Simply leverage the Apache Kafka ecosystem in your enterprise architecture to make the integration of your various systems successful and dynamic. But whatever you do, do not try to build an ESB around Kafka—it is an anti-pattern that will create inflexibility and unwanted dependencies.
Instead, leverage the distributed architecture of the Apache Kafka ecosystem to build a flexible, event-driven streaming infrastructure with high throughput, high scalability, fault tolerance, and failover.
As a next step, check out my talk on Apache Kafka vs. integration middleware to learn how to build a complete event streaming platform leveraging Apache Kafka and its open-source ecosystem. In this session, I also cover how this differs from middleware like MQ, ETL, and ESBs.
For further proof, you can look at past Kafka Summits in London, New York, and San Francisco, where plenty of tech giants and software vendors have explained how they digitize their business and innovate their products with Apache Kafka.
Interested in more?
If you’re looking for the fastest way to get started with Apache Kafka, you can sign up for fully managed Apache Kafka as a service with Confluent Cloud and receive $400 of free usage during your first 60 days, plus an additional $60 of free usage when you use the promo code CL60BLOG.*
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren





