New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Using logs to build a solid data infrastructure (or: why dual writes are a bad idea)
This is an edited transcript of a talk I gave at the Craft Conference 2015. The video and slides are also available.
How does your database store data on disk reliably? It uses a log.
How does one database replica synchronise with another replica? It uses a log.
How does a distributed algorithm like Raft achieve consensus? It uses a log.
How does activity data get recorded in a system like Apache Kafka? It uses a log.
How will the data infrastructure of your application remain robust at scale? Guess what…
Logs are everywhere. I’m not talking about plain-text log files (such as syslog or log4j) – I mean an append-only, totally ordered sequence of records. It’s a very simple structure, but it’s also a bit strange at first if you’re used to normal databases. However, once you learn to think in terms of logs, many problems of making large-scale data systems reliable, scalable and maintainable suddenly become much more tractable.
Drawing from the experience of building scalable systems at LinkedIn and other startups, this talk explores why logs are such a fine idea: making it easier to maintain search indexes and caches, making your applications more scalable and more robust in the face of failures, and opening up your data for richer analysis, while avoiding race conditions, inconsistencies and other ugly problems.

Hello! I’m Martin Kleppmann, and I work on large-scale data systems, especially the kinds of systems that you find at internet companies. I used to work at LinkedIn, contributing to an open source stream processing system called Samza.
In the course of that work, my colleagues and I learnt a thing or two about how to build applications such that they are operationally robust, reliable and perform well. In particular, I got to work with some fine people like Jay Kreps, Chris Riccomini and Neha Narkhede. They figured out a particular architectural style for applications, based on logs, that turns out to work really well. In this talk I will describe that approach, and show how similar patterns arise in various different areas of computing.
What I’m going to talk about today isn’t really new — some people have known about these ideas for a long time. However, they aren’t as widely known as they should be. If you work on a non-trivial application, something with more than just one database, you’ll probably find these ideas very useful. At the moment, I’m taking a sabbatical to write a book for O’Reilly, called “Designing Data-Intensive Applications”. This book is an attempt to collect the important fundamental lessons we’ve learnt about data systems in the last few decades, covering the architecture of databases, caches, indexes, batch processing and stream processing.
At the moment, I’m taking a sabbatical to write a book for O’Reilly, called “Designing Data-Intensive Applications”. This book is an attempt to collect the important fundamental lessons we’ve learnt about data systems in the last few decades, covering the architecture of databases, caches, indexes, batch processing and stream processing.
The book is not about any one particular database or tool – it’s about the whole range of different tools and algorithms that are used in practice, and their trade-offs, their pros and cons. This talk is partly based on my research for the book, so if you find it interesting, you can find more detail and background in the book. The first seven chapters are currently available in early release.
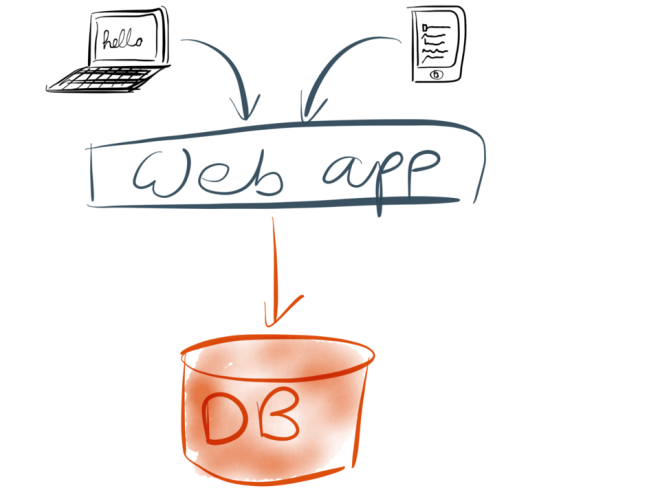
Anyway, let’s get going. Let’s assume that you’re working on a web application. In the simplest case, it probably has the stereotypical three-tier architecture: you have some clients (which may be web browsers, or mobile apps, or both), which make requests to a web application running on your servers. The web application is where your application code or “business logic” lives.
Whenever the application wants to remember something for the future, it stores it in a database. And whenever the application wants to look up something that it stored previously, it queries the database. This approach is simple to understand and works pretty well.
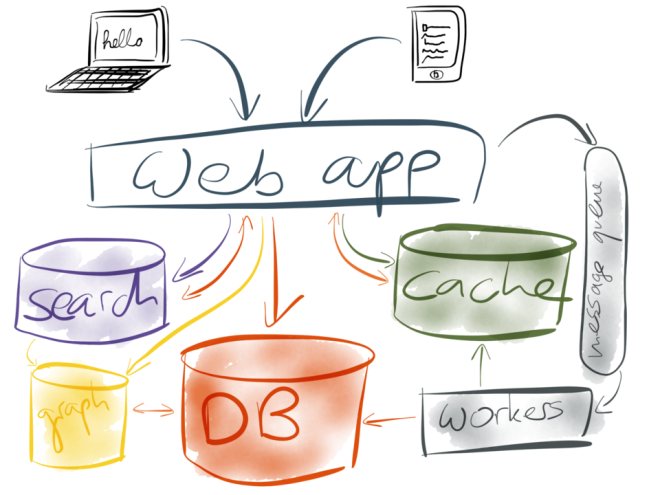
However, things usually don’t stay so simple for long. Perhaps you get more users, making more requests, your database gets slow, and you add a cache to speed it up – perhaps memcached or Redis, for example. Perhaps you need to add full-text search to your application, and the basic search facility built into your database is not good enough, so you end up setting a separate indexing service such as Elasticsearch or Solr.
Perhaps you need to do some graph operations that are not efficient on a relational or document database, for example for social features or recommendations, so you add a separate graph index to your system. Perhaps you need to move some expensive operations out of the web request flow, and into an asynchronous background process, so you add a message queue which lets you send jobs to your background workers.
And it gets worse…
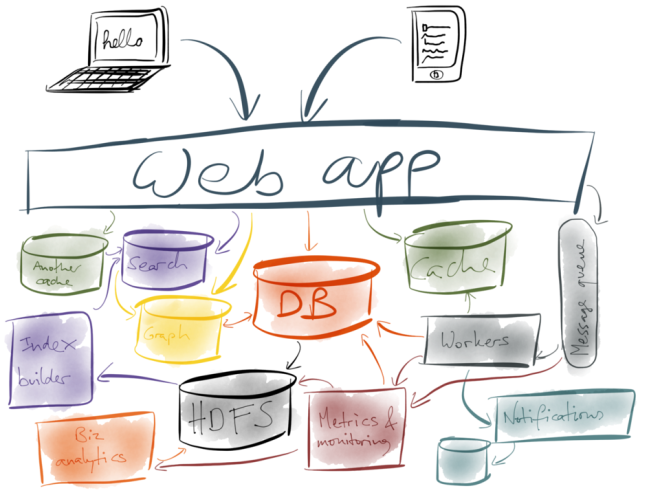
By now, other parts of the system are getting slow again, so you add another cache. More caches always make things faster, right? But now you have a lot of systems and services, so you need to add metrics and monitoring so that you can see whether they are actually working, and the metrics system is another system in its own right.
Next, you want to send notifications, such as email or push notifications to your users, so you chain a notification system off the side of the job queue for background workers, and it perhaps needs some kind of database of its own to keep track of stuff. But now you’re generating a lot of data that needs to be analysed, and you can’t have your business analysts running big expensive queries on your main database, so you add Hadoop or a data warehouse, and load the data from the database into it.
Now that your business analytics are working, you find that your search system is no longer keeping up… but you realise that since you have all the data in HDFS anyway, you could actually build your search indexes in Hadoop and push them out to the search servers, and the system just keeps getting more and more complicated…
…and the result is complete and utter insanity.

How did we get into that state? How did we end up with such complexity, where everything is calling everything else, and nobody understands what is going on?
It’s not that any particular decision we made along the way was bad. There is no one database or tool that can do everything that our application requires – we use the best tool for the job, and for an application with a variety of features that implies using a variety of tools.
Also, as a system grows, you need a way of decomposing it into smaller components in order to keep it manageable. That’s what microservices are all about. But if your system becomes a tangled mess of interdependent components, that’s not manageable either.
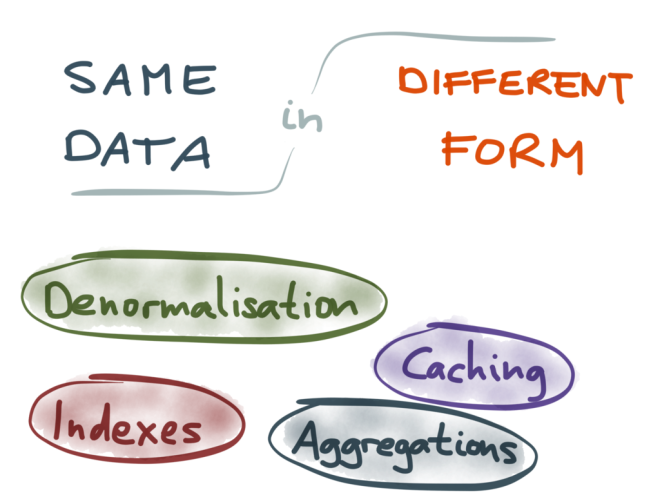
Simply having many different storage systems is not a problem in itself: if they were all independent from each other, it wouldn’t be a big deal. The real trouble here is that many of them end up containing the same data, or related data, but in different forms.
For example, the documents in your full-text indexes are typically also stored in a database, because search indexes are not intended to be used as systems of record. The data in your caches is a duplicate of data in some database (perhaps joined with other data, or rendered into HTML, or something) – that’s the definition of a cache.
Also, denormalization is just another form of duplicating data, similar to caching – if some value is too expensive to recompute on reads, you may store that value somewhere, but now you need to also keep it up-to-date when the underlying data changes. Materialized aggregates, such as the count, sum or average of a bunch of records (which you often get in metrics or analytics systems) are again a form of redundant data.
I’m not saying that this duplication of data is bad – far from it. Caching, indexing and other forms of redundant data are often essential for getting good performance on reads. However, keeping the data in sync between all these various different representations and storage systems becomes a real challenge.
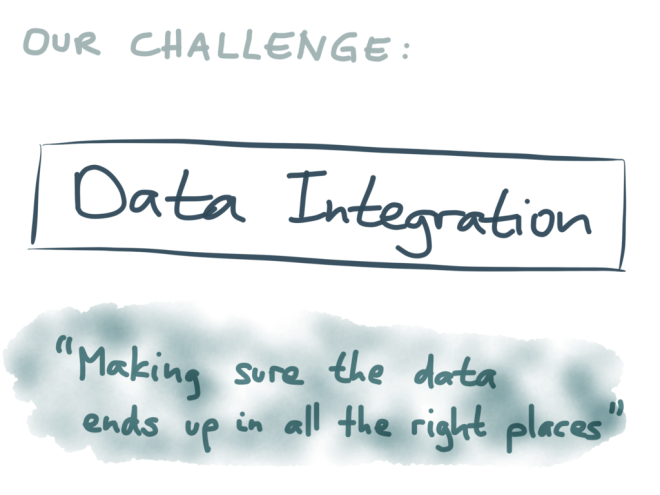
For lack of a better term I’m going to call this the problem of “data integration”. With that I really just mean “making sure that the data ends up in all the right places”. Whenever a piece of data changes in one place, it needs to change correspondingly in all the other places where there is a copy or derivative of that data.
So how do we keep these different data systems in sync? There are a few different techniques.
A popular approach is so-called dual writes:
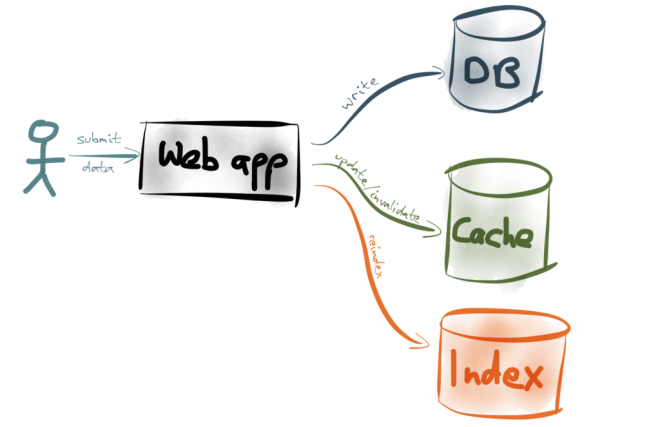
Dual writes is simple: it’s your application code’s responsibility to update data in all the right places. For example, if a user submits some data to your web app, there’s some code in the web app that first writes the data to your database, then invalidates or refreshes the appropriate cache entries, then re-indexes the document in your full-text search index, and so on. (Or maybe it does those things in parallel – doesn’t matter for our purposes.)
The dual writes approach is popular because it’s easy to build, and it more or less works at first. But I’d like to argue that it’s a really bad idea, because it has some fundamental problems. The first problem is race conditions.
The following diagram shows two clients making dual writes to two datastores. Time flows from left to right, following the black arrows:
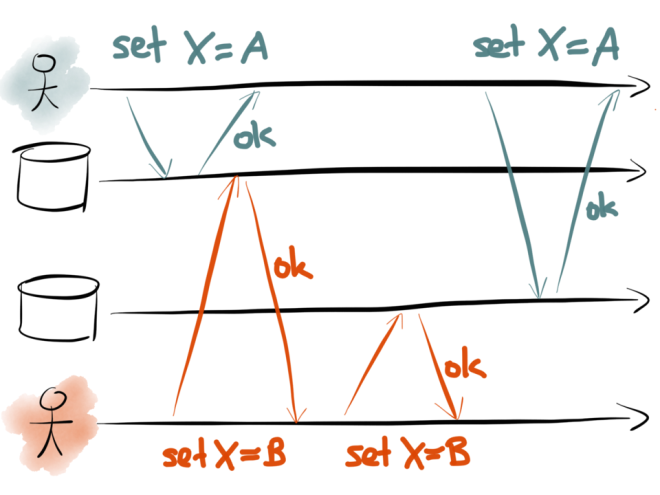
Here, the first client (teal) is setting the key X to be some value A. They first make a request to the first datastore – perhaps that’s the database, for example – and set X=A. The datastore responds saying the write was successful. Then the client makes a request to the second datastore – perhaps that’s the search index – and also sets X=A.
At the same time as this is happening, another client (red) is also active. It wants to write to the same key X, but it wants to set the key to a different value B. The client proceeds in the same way: it first sends a request X=B to the first datastore, and then sends a request X=B to the second datastore.
All these writes are successful. However, look at what value is stored in each database over time:
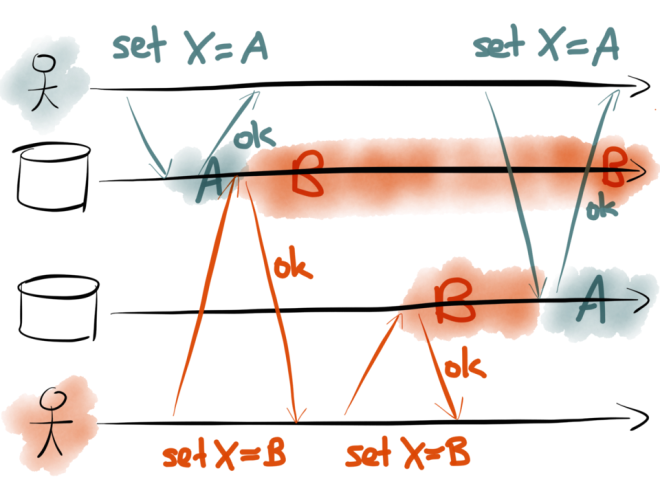
In the first datastore, the value is first set to A by the teal client, and then set to B by the red client, so the final value is B.
In the second datastore, the requests arrive in a different order: the value is first set to B, and then set to A, so the final value is A. Now the two datastores are inconsistent with each other, and they will permanently remain inconsistent until sometime later someone comes and overwrites X again.
An the worst thing: you probably won’t even notice that your database and your search indexes have gone out of sync, because no errors occurred. You’ll probably only realize six months later, while you’re doing something completely different, that your database and your indexes don’t match up, and you’ll have no idea how that could have happened.
That alone should be enough to put anyone off dual writes. But wait, there’s more…
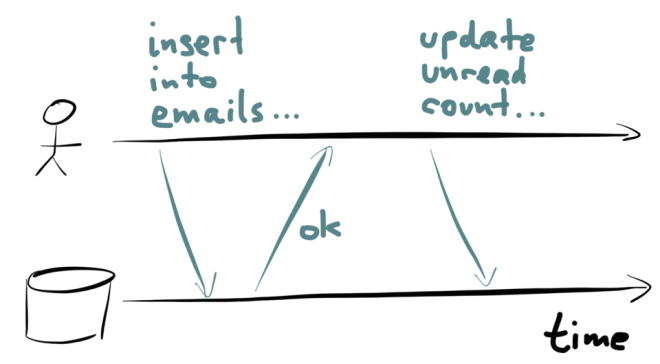
Let’s look at denormalized data. Say, for example, you have an application where users can send each other messages or emails, and you have an inbox for each user. When a new message is sent, you want to do two things: add the message to the list of messages in the user’s inbox, and also increment the user’s count of unread messages.
You keep a separate counter because you display it in the user interface all the time, and it would be too slow to query the number of unread messages by scanning over the list of messages every time you need to display the number. However, this counter is denormalized information: it’s derived from the actual messages in the inbox, and whenever the messages change, you also need to update the counter accordingly.
Let’s keep this one simple: one client, one database. Think about what happens over time: first the client inserts the new message into the recipient’s inbox. Then the client makes a requiest to increment the unread counter.
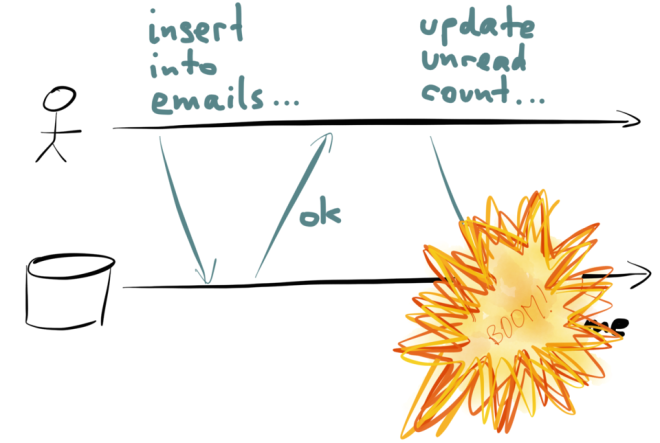
However, just in that moment, something goes wrong – perhaps the database goes down, or a process crashes, or the network gets interrupted, or someone unplugs the wrong network cable. Whatever the reason, the update to the unread counter fails.
Now your database is inconsistent: the message has been added to the inbox, but the counter hasn’t been updated. And unless you periodically recompute all your counter values from scratch, or undo the insertion of the message, it will forever remain inconsistent.
Of course, you could argue that this problem was solved decades ago by transactions: atomicity, the “A” in “ACID”, means that if you make several changes within one transaction, they either all happen or none happen. The purpose of atomicity is to solve precisely this issue – if something goes wrong during your writes, you don’t have to worry about a half-finished set of changes making your data inconsistent.

The traditional approach of wrapping the two writes in a transaction works fine in databases that support it, but many of the new generation of databases don’t, so you’re on your own.
Also, if the denormalized information is stored in a different database – for example, if you keep your emails in a database but your unread counters in Redis – then you lose the ability to tie the writes together into a single transaction. If one write succeeds, and the other fails, you’re going to have a difficult time clearing up the inconsistency.
Some systems support distributed transactions, based on 2-phase commit for example. However, many datastores nowadays don’t support it, and even if they did, it’s not clear whether distributed transactions are a good idea in the first place. So we have to assume that with dual writes, the application has to deal with partial failure, which is difficult.
So, back to our original question. How do we make sure that all the data ends up in all the right places? How do we get a copy of the same data to appear in several different storage systems, and keep them all consistently in sync as the data changes?
As we saw, dual writes isn’t the solution, because it can introduce inconsistencies due to race conditions and partial failures. How can we do better?
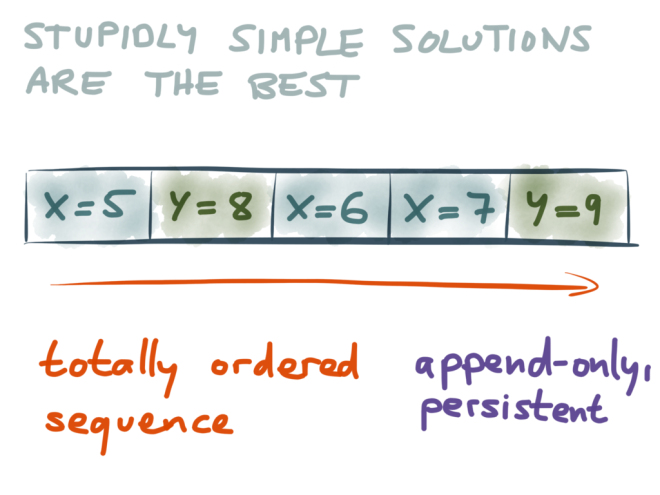 I’m a fan of stupidly simple solutions. The great thing about simple solutions is that you have a chance of understanding them and convincing yourself that they’re correct. And in this case, the simplest solution I can see is to do all your writes in a fixed order, and to store them in that fixed order.
I’m a fan of stupidly simple solutions. The great thing about simple solutions is that you have a chance of understanding them and convincing yourself that they’re correct. And in this case, the simplest solution I can see is to do all your writes in a fixed order, and to store them in that fixed order.
If you do all your writes sequentially, without any concurrency, then you have removed the potential for race conditions. Moreover, if you write down the order in which you make your writes, it becomes much easier to recover from partial failures, as I will show later.
So, the stupidly simple solution that I propose looks like this: whenever anyone wants to write some data, we append that write to the end of a sequence of records. That sequence is totally ordered, it’s append-only (we never modify existing records, only ever add new records at the end), and it’s persistent (we store it durably on disk).
The picture above shows an example of such a data structure: moving left to right, it records that we first wrote X=5, then we wrote Y=8, then we wrote X=6, and so on.

That data structure has a name: we call it a log.
The interesting thing about logs is that they pop up in many different areas of computing. Although it may seem like a stupidly simple idea that can’t possibly work, it actually turns out to be incredibly powerful.

When I say “logs”, the first thing you probably think of is textual application logs of the style you might get from Log4j or Syslog. For example, the above is one line from an nginx server’s access log, telling me that some IP addresses requested a certain file at a certain time. It also includes the referrer, the user-agent, the response code and a few other things.
Sure, that’s one kind of log, but when I talk about logs here I mean something more general. I mean any kind of data structure of totally ordered records that is append-only and persistent. Any kind of append-only file.
 In the rest of this talk, I’d like to run through a few examples of how logs are used in practice. It turns out that logs are already present in the databases and systems you use every day. And once we understand how logs are used in various different systems, we’ll be in a better position to understand how they can help us solve the problem of data integration.
In the rest of this talk, I’d like to run through a few examples of how logs are used in practice. It turns out that logs are already present in the databases and systems you use every day. And once we understand how logs are used in various different systems, we’ll be in a better position to understand how they can help us solve the problem of data integration.
I’d like to talk about four different places where logs are used, and the first is in the internals of database storage engines.
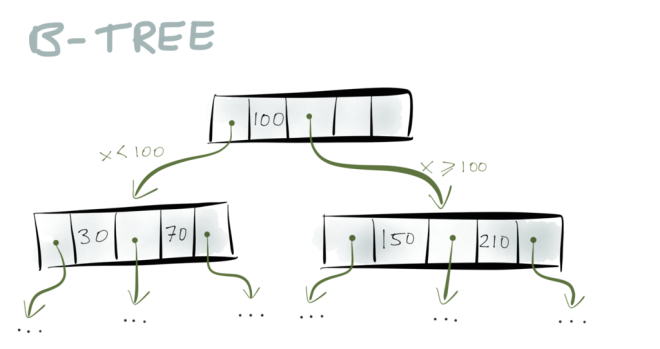
Do you remember B-Trees from your algorithms classes? They are a very widely used data structure for storage engines – almost all relational databases, and many non-relational databases, use them.
To summarize them briefly: a B-Tree consists of pages, which are fixed-size blocks on disk, typically 4 or 8 kB in size. When you want to look up a particular key, you start with one page, which is at the root of the tree. The page contains pointers to other pages, and each pointer is tagged with a range of keys: for example, if your key is between 0 and 100, you follow the first pointer; if your key is between 100 and 300, you follow the second pointer; and so on.
The pointer takes you to another page, which further breaks down the key range into sub-ranges. And eventually you end up at the page containing the particular key you’re looking for.
Now what happens if you need to insert a new key/value pair into a B-tree? You have to insert it into the page whose key range contains the key you’re inserting. If there is enough spare space in that page, no problem. But if the page is full, it needs to be split into two separate pages.
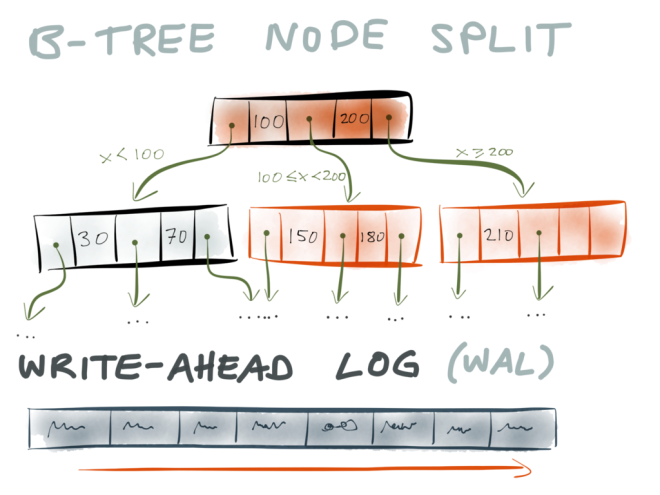
When you split a page, you need to write at least three pages to disk: the two pages that are the result of the split, and the parent page (to update the pointers to the split pages). However, these pages may be stored at various different locations on disk.
This raises the question: what happens if the database crashes (or the power goes out, or something else goes wrong) halfway through the operation, after only some of those pages have been written to disk? In that case, you have the old (pre-split) data in some pages, and the new (post-split) data in other pages, and that’s bad news. You’re most likely going to end up with dangling pointers or pages that nobody is pointing to. In other words, you’ve got a corrupted index.
Now, storage engines have been doing this for decades, so how do they make B-trees reliable? The answer is that they use a write-ahead log (WAL).
A write-ahead log is a particular kind of log, i.e. an append-only file on disk. Whenever the storage engine wants to make any kind of change to the B-tree, it must first write the change that it intends to make to the WAL. Only after it has been written to the WAL, and durably written to disk, it is allowed to modify the actual B-tree.
This makes the B-tree reliable: if the database crashes while data was being appended to the WAL, no problem, because the B-tree hasn’t been touched yet. And if it crashes while the B-tree is being modified, no problem, because the WAL contains the information about what changes were about to happen. When the database comes back up after the crash, it can use the WAL to repair the B-tree and get it back into a consistent state.
This is our first example to show that logs are a really neat idea.
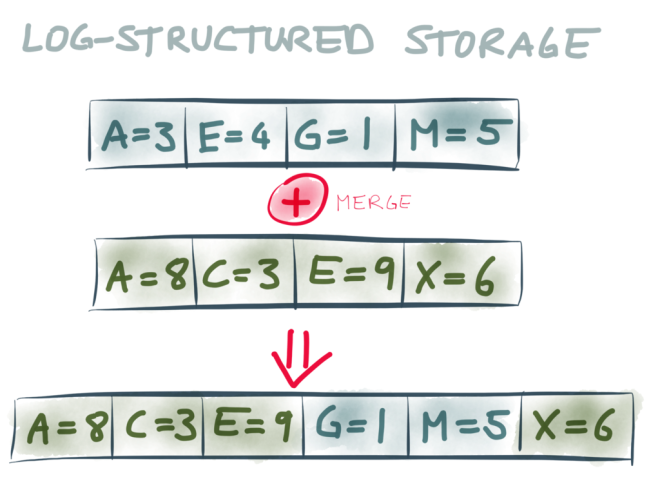
Now, storage engines didn’t stop with B-trees. Some clever folks realized that if we’re writing everything to a log anyway, we might as well use the log as the primary storage medium. This is known as log-structured storage, which is used in HBase and Cassandra, and a variant appears in Riak.
In log-structured storage we don’t always keep appending to the same file, because it would become too large and it would be too difficult to find the key we’re looking for. Instead, the log is broken into segments, and from time to time the storage engine merges segments and discards duplicate keys. Segments may also be internally sorted by key, which can make it easier to find the key you’re looking for, and also simplifies merging. However, these segments are still logs: they are only written sequentially, and they are immutable once written.
As you can see, logs play an important role in storage engines.
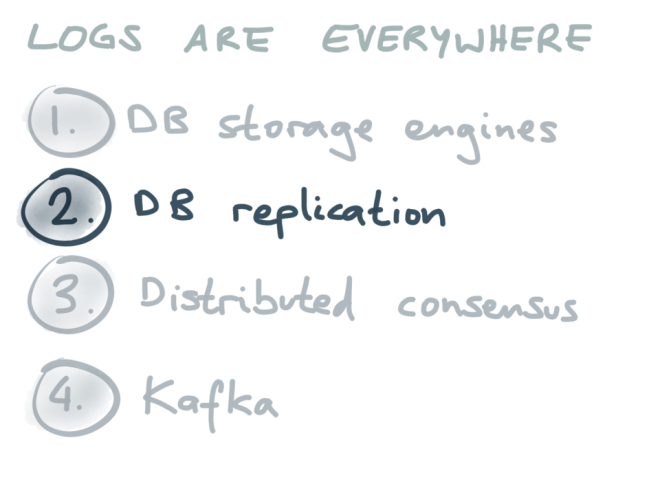 Let’s move on to the second example where logs are used: database replication.
Let’s move on to the second example where logs are used: database replication.
Replication is a feature that you find in many databases: it allows you to keep a copy of the same data on several different nodes. That can be useful for spreading the load, and it also means that if one node dies, you can fail over to another one.
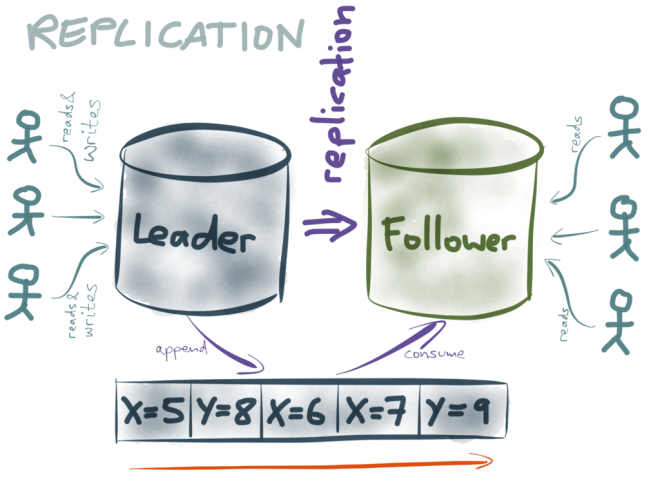
There are a few different ways of implementing replication, but a common choice is to designate one node as the leader (also known as primary or master), and the other replicas as followers (also known as standby or slave). I don’t like the master/slave terminology, so I’m going to stick with leader/follower.
Whenever a client wants to write something to the database, it needs to talk to the leader. Read-only clients can use either the leader or the follower (although the follower is typically asynchronous, so it may have slightly out-of-date information if the latest writes haven’t yet been applied).
When clients write data to the leader, how does that data get to the followers? Big surprise: they use a log! They use a replication log, which may in fact be the same as the write-ahead log (this is what Postgres does, for example) or it may be a separate replication log (MySQL does this).
 The replication log works as follows: whenever some data is written to the leader, it is also appended to the replication log. The followers read that log in the order it was written, and apply each of the writes to their own copy of the data. As a result, each follower processes the same writes in the same order as the leader, and thus it ends up with a copy of the same data.
The replication log works as follows: whenever some data is written to the leader, it is also appended to the replication log. The followers read that log in the order it was written, and apply each of the writes to their own copy of the data. As a result, each follower processes the same writes in the same order as the leader, and thus it ends up with a copy of the same data.
Even if the writes happen concurrently on the reader, the log still contains the writes in a total order. Thus, the log actually removes the concurrency from the writes – it “squeezes all the non-determinism out of the stream of writes”, and on the follower there’s no doubt about the order in which the writes happened.
So what about the dual-writes race condition we discussed earlier?
This race condition cannot happen with leader-based replication, because clients don’t write directly to the followers. The only writes processed by followers are the ones they receive from the replication log. And since the log fixes the order of those writes, there is no ambiguity over which one happened first.
And what about the second problem with dual writes that we discussed earlier? This could still happen: a follower could successfully process the first write from a transaction, but fail to process the second write from the transaction (perhaps because the disk is full, or the network is interrupted).
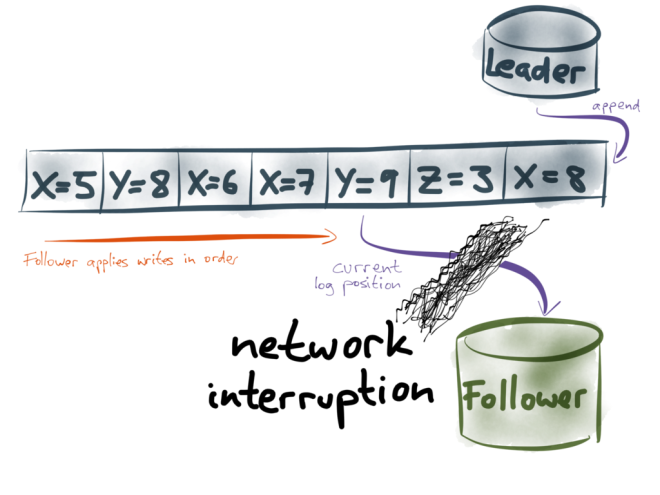 If the network between the leader and the follower is interrupted, the replication log cannot flow from the leader to the follower. This could lead to an inconsistent replica, as we discussed previously. How does database replication recover from such errors and avoid becoming inconsistent?
If the network between the leader and the follower is interrupted, the replication log cannot flow from the leader to the follower. This could lead to an inconsistent replica, as we discussed previously. How does database replication recover from such errors and avoid becoming inconsistent?
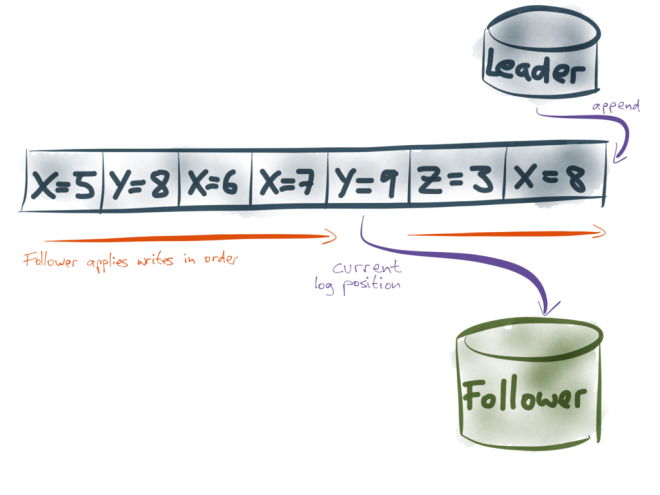
Notice that the log has a very nice property: because the leader only ever appends to it, we can give each record in the log a sequential number that is always increasing (which we might call log position or offset). Furthermore, followers only process it in sequential order (from left to right, i.e. in order of increasing log position), so we can describe a follower’s current state with a single number: the position of the latest record it has processed.
When you know a follower’s current position in the log, you can be sure that all the prior records in the log have already been processed, and none of the subsequent records have been processed.
This is great, because it makes error recovery quite simple. If a follower becomes disconnected from the leader, or it crashes, the follower just needs to store the log position up to which it has processed the replication log. When the follower recovers, it reconnects to the leader, and asks for the replication log starting from the last offset that it previously processed. Thus, the follower can catch up on all the writes that it missed while it was disconnected, without losing any data or receiving duplicates.
The fact that the log is totally ordered makes this recovery much simpler than if you had to keep track of every write individually.
 The third example of logs in practice is in a different area: distributed consensus.
The third example of logs in practice is in a different area: distributed consensus.

Achieving consensus is one of the well-known and often-discussed problems in distributed systems. It is important, but it is also surprisingly difficult to solve.
An example of consensus in the real world would be trying to get a group of friends to agree on where to go for lunch. This is a distinctive feature of a sophisticated civilization, and can be a surprisingly difficult problem, especially if some of your friends are easily distractible (so they don’t always respond to your questions) or if they are fussy eaters.
Closer to our usual domain of computers, an example of where you might want consensus is in a distributed database system: for instance, you may require all your database nodes to agree on which node is the leader for a particular partition (shard) of the database.
It’s pretty important that they all agree on who’s leader: if two different nodes both think they are leader, they may both accept writes from clients. Later, when one of them finds out that it was wrong and it wasn’t leader after all, the writes that it accepted may be lost. This situation is known as split brain, and it can cause nasty data loss.
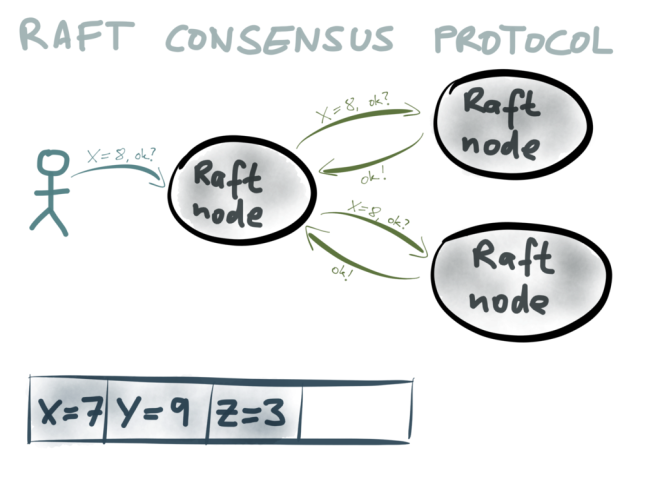 There are a few different algorithms for implementing consensus. Paxos is perhaps the most well-known, but there are also Zab (used by Zookeeper), Raft and others. These algorithms are quite tricky and have some non-obvious subtleties. In this talk, I will just very briefly sketch one part of the Raft algorithm.
There are a few different algorithms for implementing consensus. Paxos is perhaps the most well-known, but there are also Zab (used by Zookeeper), Raft and others. These algorithms are quite tricky and have some non-obvious subtleties. In this talk, I will just very briefly sketch one part of the Raft algorithm.
In a consensus system, there are a number of nodes (three in this diagram) which are in charge of agreeing what the value of a particular variable should be. A client proposes a value, for example X=8 (which may mean that node X is the leader for partition 8), by sending it to one of the Raft nodes. That node collects votes from the other nodes. If a majority of nodes agree that the value should be X=8, the first node is allowed to commit the value.
When that value is committed, what happens? In Raft, that value is appended to the end of a log. Thus, what Raft is doing is not just getting the nodes to agree on one particular value – it’s actually building up a log of values that have been agreed over time. All Raft nodes are guaranteed to have exactly the same sequence of committed values in their log, and clients can consume this log.
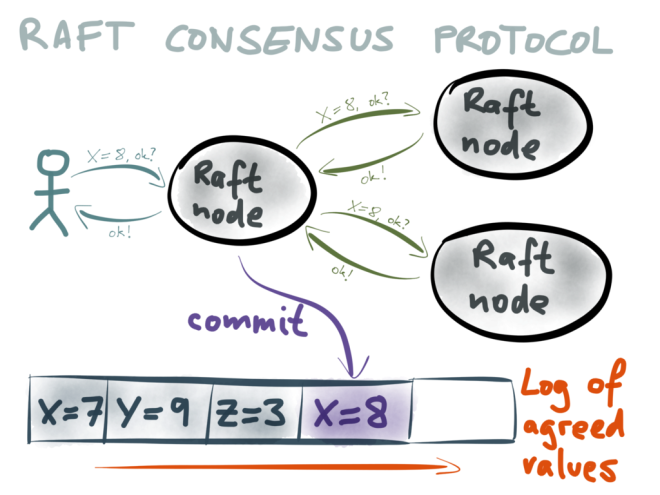
Once the newly agreed value has been committed, appended to the log and replicated to the other nodes, the client that originally proposed the value X=8 is sent a response saying that the system succeeded in reaching consensus, and that the proposed value is now part of the Raft log.
(As a theoretical aside, the problems of consensus and atomic broadcast – that is, creating a log with exactly-once delivery – are reducible to each other. This means Raft’s use of a log is not just a convenient implementation detail, but also
reflects a fundamental property of the consensus problem it is solving.)
 Ok. We’ve seen that logs really are a recurring theme in surprisingly many areas of computing: storage engines, database replication and consensus. As the fourth and final example, I’d like to talk about Apache Kafka, another system that is built around the idea of logs. The interesting thing about Kafka is that it it doesn’t hide the log from you. Rather than treating the log as an implementation detail, Kafka exposes it to you, so that you can build applications around it.
Ok. We’ve seen that logs really are a recurring theme in surprisingly many areas of computing: storage engines, database replication and consensus. As the fourth and final example, I’d like to talk about Apache Kafka, another system that is built around the idea of logs. The interesting thing about Kafka is that it it doesn’t hide the log from you. Rather than treating the log as an implementation detail, Kafka exposes it to you, so that you can build applications around it.
You may have heard of Kafka before. It’s an open source project that was originally developed at LinkedIn, and is now a lively Apache project with many different contributors and users.
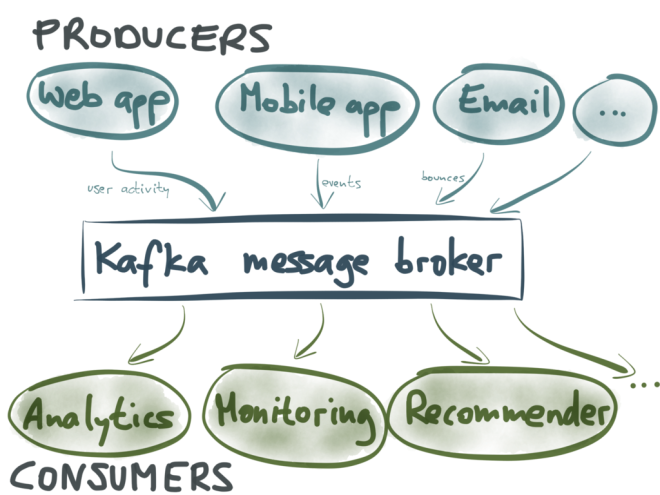
The typical use of Kafka is as a message broker (message queue) – so it is somewhat comparable to AMQP, JMS and other messaging systems. Kafka has two types of clients: producers (which send messages to Kafka) and consumers (which subscribe to streams of messages in Kafka).
For example, producers may be your web servers or mobile apps, and the types of messages they send to Kafka might be logging information – e.g. events that indicate which user clicked which link at which point in time. The consumers are various processes that need to find out about stuff that is happening: for example, to generate analytics, to monitor for unusual activity, to generate personalized recommendations for users, and so on.
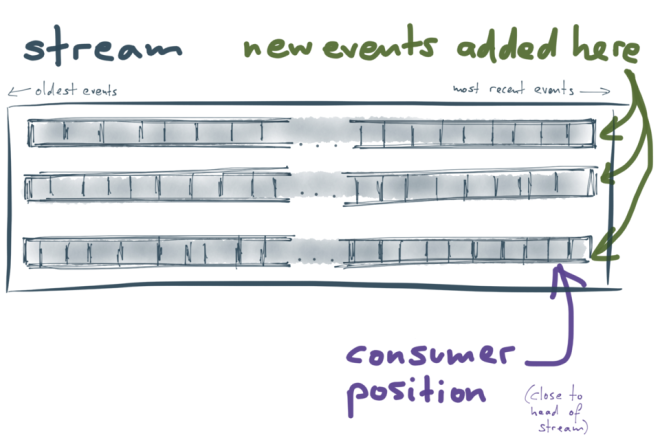
The thing that makes Kafka interestingly different from other message brokers is that it is structured as a log. In fact, it has many logs! Data streams in Kafka are split into partitions, and each partition is a log (a totally ordered sequence of messages). Different partitions are completely independent from each other, so there is no ordering guarantee across different partitions. This allows different partitions to be handled on different servers, which is important for the scalability of Kafka.
Each partition is stored on disk and replicated across several machines, so it is durable and can tolerate machine failure without data loss. Producing and consuming logs is very similar to what we saw previously in the context of database replication:
- Every message that is sent to Kafka is appended to the end of a partition. That is the only write operation supported by Kafka: appending to the end of a log. It’s not possible to modify past messages.
- Within each partition, messages have a monotonically increasing offset (log position). To consume messages from Kafka, a client reads messages sequentially, starting from a particular offset. That offset is managed by the consumer.
Let’s return to the data integration problem from the beginning of this talk.
Say you have this tangle of different datastores, caches and indexes that need to be kept in sync with each other. Now that we have seen a bunch of examples of practical applications of logs, can we use what we’ve learnt to figure out how to build these systems in a better way?
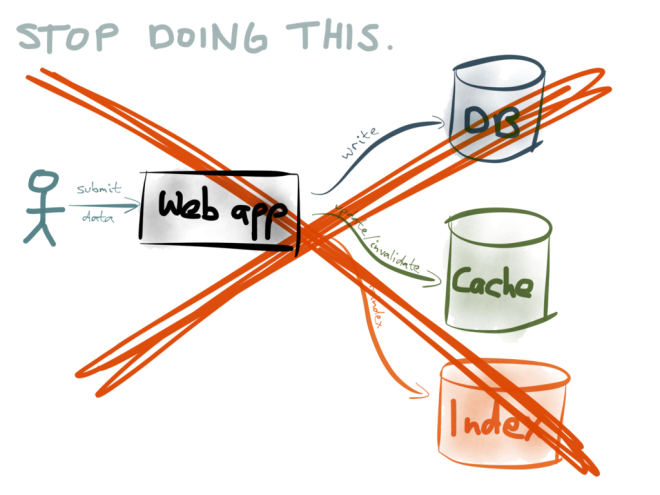
Firstly, we need to stop doing dual writes. As discussed, it’s probably going to make your data inconsistent, unless you have very carefully thought about the potential race conditions and partial failures that can occur in your application.
And note this inconsistency isn’t just a kind of “eventual consistency” that is often quoted in asynchronous systems. What I’m talking about here is permanent inconsistency – if you’ve written two different values to two different datastores, due to a race condition or partial failure, that difference won’t simply resolve itself. You’d have to take explicit actions to search for data mismatches and resolve them (which is difficult, since the data is constantly changing).
We need a better approach than dual writes for keeping different datastores in sync.
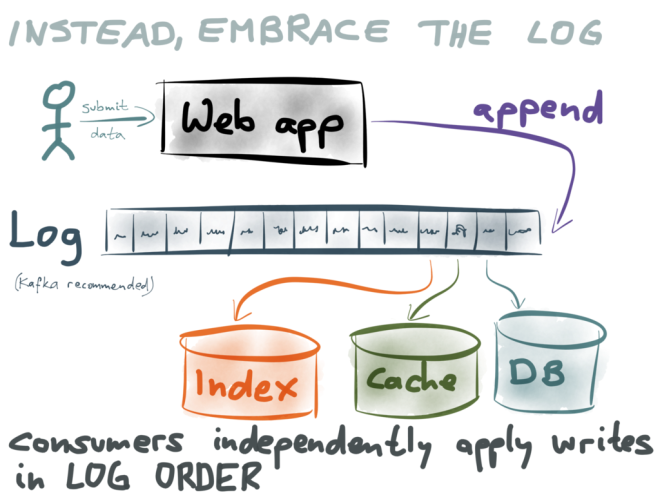
What I propose is this: rather than having the application write directly to the various datastores, the application only appends the data to a log (such as Kafka). All the different representations of this data – your databases, your caches, your indexes – are constructed by consuming the log in sequential order.
Each datastore that needs to be kept in sync is an independent consumer of the log. Every consumer takes the data in the log, one record at a time, and writes it to its own datastore. The log guarantees that the consumers all see the records in the same order; by applying the writes in the same order, the problem of race conditions is gone. This looks very much like the database replication we saw earlier!
And what about the problem of partial failure? What if one of your stores has a problem and can’t accept writes for a while?
That problem is also solved by the log: each consumer keeps track of the log position up to which it has processed the log. When the error in the datastore-writing consumer is resolved, it can resume processing records in the log from the last position it previously reached. That way, a datastore won’t lose any updates, even if it’s offline for a while. This is great for decoupling parts of your system: even if there is a problem in one datastore, the rest of the system remains unaffected.
The log, the stupidly simple idea of putting your writes in a total order, strikes again.
Just one problem remains: the consumers of the log all update their datastores asynchronously, so they are eventually consistent. Reading from them is like reading from a database follower: they may be a little behind the latest writes, so you don’t have a guarantee of read-your-writes (and certainly not linearizability).
I think that can be overcome by layering a transaction protocol on top of the log, but that’s a researchy area which so far hasn’t been widely implemented in production systems. For now, a better option is to extract the log from a database:
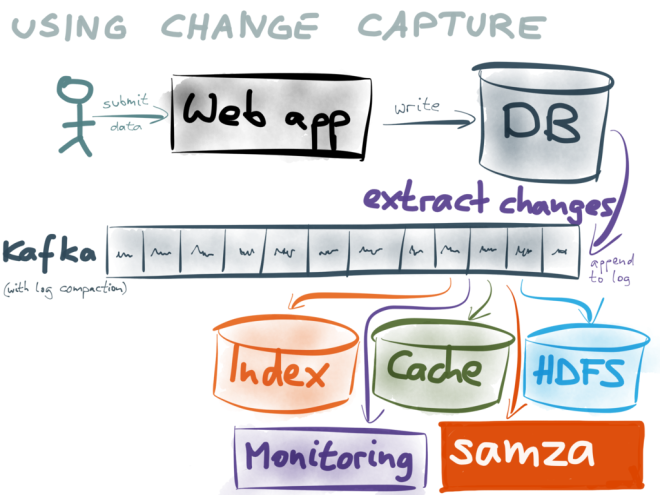
This approach is called change data capture, which I wrote about recently (and implemented on PostgreSQL). As long as you’re only writing to a single database (not doing dual writes), and getting the log of writes from the database (in the order in which they were committed to the DB), then this approach works just as well as making your writes to the log directly.
As this database in front of the log applies writes synchronously, you can use it to make reads that require “immediate consistency” (linearizability), and enforce constraints (e.g. requiring that account balances never go negative). Going via a database also means that you don’t need to trust the log as your system of record (which may be a scary prospect if it’s implemented with a new technology) – if you have an existing database that you know and like, and you can extract a change log from that database, you can still get all the advantages of a log-oriented architecture. I’ll be talking more about this topic in an upcoming conference talk.
To close, I’d like to leave you with a thought experiment:

Most APIs we work with have endpoints for both reading and writing. In RESTful terms, GET is for reading (i.e. side-effect-free operations) and POST, PUT and DELETE are for writing. These endpoints for writing are ok if you only have one system you’re writing to, but if you have more than one such system, you quickly end up with dual writes and all their aforementioned problems.
Imagine a system with an API in which you eliminate all the endpoints for writing. Imagine that you keep all the GET requests, but prohibit any POST, PUT or DELETE. Instead, the only way you can send writes into the system is by appending them to a log, and having the system consume that log. (The log must be outside of the system, so that you can have several consumers for the same log.)
For example, imagine a variant of Elasticsearch in which you cannot write documents through the REST API, but only write documents by sending them to Kafka. Elasticsearch would internally include a Kafka consumer that takes documents and adds them to the index. This would actually simplify some of the internals of Elasticsearch, since it would no longer have to worry about concurrency control, and replication would be simpler to implement. And it would sit neatly alongside other tools that may be consuming the same log.
My favorite feature of this log-oriented architecture is this: if you want to build a new derived datastore, you can just start a new consumer at the beginning of the log, and churn through the history of the log, applying all the writes to your datastore. When you reach the end, you’ve got a new view onto your dataset, and you can keep it up-to-date by simply continuing to consume the log!
This makes it really easy to try out new ways of presenting your existing data, for example to index it another way. You can build experimental new indexes or views onto your data without interfering with any of the existing data. If the result is good, you can shift users to read from the new view; if it isn’t, you can just discard it again. This gives you tremendous freedom to experiment and adapt your application.
Further reading
- Many of the ideas in this talk were previously laid out by Jay Kreps: “The Log: What every software engineer should know about real-time data’s unifying abstraction,” 16 December 2013. (An edited version was published as an ebook by O’Reilly Media, September 2014.)
- This talk arose from research I did for my own book, “Designing Data-Intensive Applications,” to appear with O’Reilly Media in 2015.
- For a more detailed vision of deriving materialised views from a log, see my previous talk “Turning the database inside-out with Apache Samza,” at Strange Loop, 18 Sep 2014.
- Pat Helland has also observed that immutability and append-only datasets are a recurring pattern at many levels of the stack: see “Immutability Changes Everything,” at 7th Biennial Conference on Innovative Data Systems Research (CIDR), January 2015.
- LinkedIn’s approach to building derived data systems based on totally ordered logs is described in Shirshanka Das, Chavdar Botev, Kapil Surlaker, et al.: “All Aboard the Databus!,” at ACM Symposium on Cloud Computing (SoCC), October 2012.
- Facebook’s Wormhole has a lot of similarities to Databus. See Yogeshwer Sharma, Philippe Ajoux, Petchean Ang, et al.: “Wormhole: Reliable Pub-Sub to Support Geo-replicated Internet Services,” at 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI), May 2015.
- If you need transactional semantics (e.g. linearizability), you can add a transaction protocol on top of the asynchronous log. I like the one described in Mahesh Balakrishnan, Dahlia Malkhi, Ted Wobber, et al.: “Tango: Distributed Data Structures over a Shared Log,” at 24th ACM Symposium on Operating Systems Principles (SOSP), pages 325–340, November 2013.
- Write-ahead logs are described in many places. For a detailed discussion, see C Mohan, Don Haderle, Bruce G Lindsay, Hamid Pirahesh, and Peter Schwarz: “ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging,” ACM Transactions on Database Systems (TODS), volume 17, number 1, pages 94–162, March 1992.
- The log-structured storage approach used in Cassandra and HBase appears in Patrick O’Neil, Edward Cheng, Dieter Gawlick, and Elizabeth O’Neil: “The Log-Structured Merge-Tree (LSM-Tree),” Acta Informatica, volume 33, number 4, pages 351–385, June 1996.
- For an analysis of the Raft consensus algorithm, and some subtle correctness requirements, see Heidi Howard, Malte Schwarzkopf, Anil Madhavapeddy, and Jon Crowcroft: “Raft Refloated: Do We Have Consensus?,” ACM SIGOPS Operating Systems Review, volume 49, number 1, pages 12–21, January 2015.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





