New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Using kafka-merge-purge to Deal with Failure in an Event-Driven System at FLYERALARM
Failures are inevitable in any system, and there are various options for mitigating them automatically. This is made possible by event-driven applications leveraging Apache Kafka® and built with fault tolerance in mind. However, automatic measures have their limits, and sometimes we need to manually intervene. Given that this process can and should still be supported by software, at FLYERALARM, we built an open source tool to take the tedium out of it.
Who is FLYERALARM?
FLYERALARM is one of Europe’s leading online printers in the B2B market. All of our processes, from the e-commerce platform, to manufacturing, to logistics, and more are supported by custom software built by over 100 in-house engineers. We constantly work to improve the degree of automation and explore new technologies such as Apache Kafka to help us in this effort.
Why Kafka?
At FLYERALARM, we follow domain-driven design principles and communicate across context boundaries using domain events. For instance, any progress in manufacturing a print product will be relayed back to our CRM system asynchronously as domain events. This approach has been a key part of our effort to move away from a monolithic legacy application towards a more microservice-oriented architecture.
This architecture requires two important components: storage for domain events and facilities for processing them. When we first started down this path, we developed an in-house proprietary solution. Over the years, we discovered a lot of pain points and issues: The old system was built with only PHP in mind and thus is not particularly friendly to other languages when it comes to both emitting and consuming events. Furthermore, the actual storage was not built in a scalable way and was approaching its limit at an increasing pace. Finally, event processing was tedious, as there was no consistent, built-in way for a consumer to retain its position in the event stream, and throughput was limited because parallelizing consumption of a single event type was not feasible without major engineering efforts.
All these issues eventually led to a search for an alternative. We considered several options, but finally settled on Apache Kafka, which, along with its ecosystem, provides everything we needed. The distributed and highly scalable nature of a Kafka deployment helped us as we transitioned to the new architecture. Avro and the Confluent Schema Registry enable us to manage message storage consistently and in a language-agnostic way; the plethora of available libraries ease adoption. Moreover, partitioning of topics, as well as offset tracking for (groups of) consumers provide a way of dealing with throughput issues and simplify processing.
We’re still in the early stages of Kafka adoption at FLYERALARM. First, we had a single team start out with their own small cluster and Kafka Connect for change data capture. This helped us get a feel for the technology and to evaluate it further. We have now started moving the first domain events to the Kafka-based system, while building a set of best practices and techniques before we roll it out further in the organization.
Domain event handling architecture
Handling a domain event usually involves communication with a database, file system, or other downstream systems that only offer synchronous interfaces, which may not always be available or capable of handling a request. Hence, a reliable and fault-tolerant event streaming platform is a necessity. Thankfully, it is quite easy to set up on top of Apache Kafka.
Of course, we’re not the first to deal with these kinds of issues, so we went looking for prior work. The engineers at Uber already put some thought into this and kindly wrote a blog post about it. We’ll give a quick rundown here, but you can find more details in that post if you’re interested.
Producing services write events to one log-compacted, partitioned topic per event type. Each consuming service then claims ownership of several retry topics that are specific to it and the event type. These topics are also log compacted and can have several partitions. Whenever consumption of an event fails, the event is written to the retry topic. This keeps the original topic as a clean stream of events, while separating the concerns of all consumers and enabling them to continue processing more events without waiting for failures to be resolved.
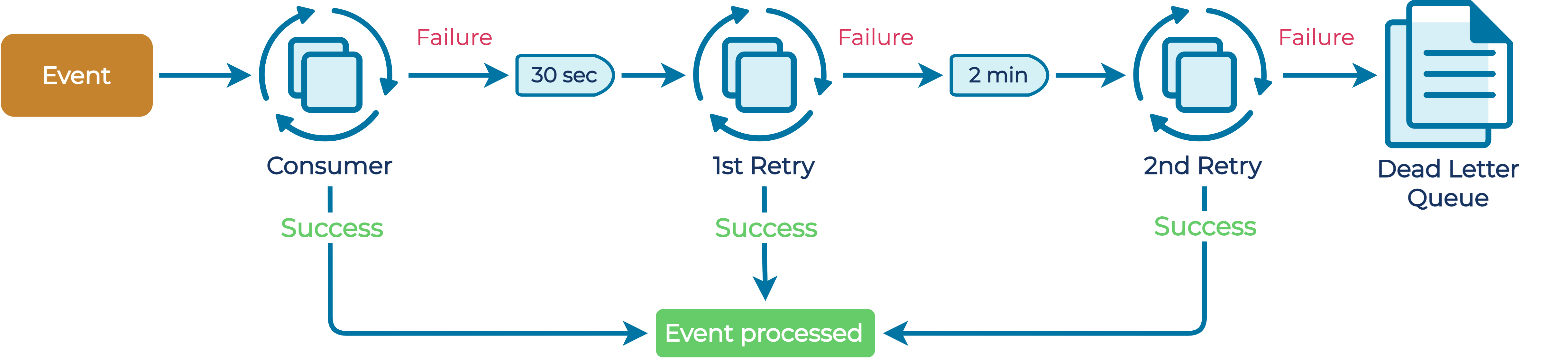
The service also separately consumes its retry topics. Before attempting to reprocess an event, however, it sleeps for some time, to give any downstream systems a chance to recover if that was the cause of the failure. If processing fails again, then the event is written to the next retry topic. As we have multiple retry topics, we can use a different delay for each successive one, and this can be used to implement an exponential backoff mechanism. Right now, rather than blocking the retry consumer thread until any given event has reached its required delay, we write the record back to the topic, retaining its original timestamp in a message header. If a retry attempt succeeds, we write a tombstone message so that the log cleaner can keep the topic at a reasonable size.
No matter how many retries we attempt or how long we wait between stages, there will always be cases where we fail to process an event due to more deep-seated issues. For this reason, when the processing of the final retry topic fails, we bail and write the event to a so-called dead letter queue topic. At this point, manual intervention is probably required, so there is no automated process that tries to handle events from this topic.
This processing architecture only scratches the surface of what’s possible. If downstream systems are temporarily unavailable, we probably don’t want to bombard them with a massive number of requests when they come back up. So, in addition to the exponential backoff in retries, limiting throughput is another avenue worth exploring. Ultimately, a generic approach can only get you so far, and different non-functional constraints can lead to a variety of solutions.
Processing the dead letter queue using kafka-merge-purge
In order to deal with the dead letter queue, engineers or domain experts need a way of exploring the queue and deciding what to do with each event. There are mainly two cases we need to consider here.
On one hand, a domain event might have become obsolete, since the business consequence has already occurred. For example, at FLYERALARM, it is crucial that manufacturing deadlines are met so that the customer receives their order on time. Hence, employees sometimes must circumvent automated processes that are usually triggered by domain events. These actions are not always idempotent, so processing the domain event could actually do more harm than good. Thus, a domain event can simply be purged from the dead letter queue.
On the other hand, an event might still be highly relevant, and not processing it would incur more manual overhead than is acceptable. If an event about order cancellation can’t be processed for some reason and then gets discarded, thousands of physically printed sheets might have to be thrown away. In this case, we instead want to merge the event into the first retry topic so that we can attempt to process it again. We do not write the message to the original event topic, in order not to pollute that topic with the concerns of a particular consumer.
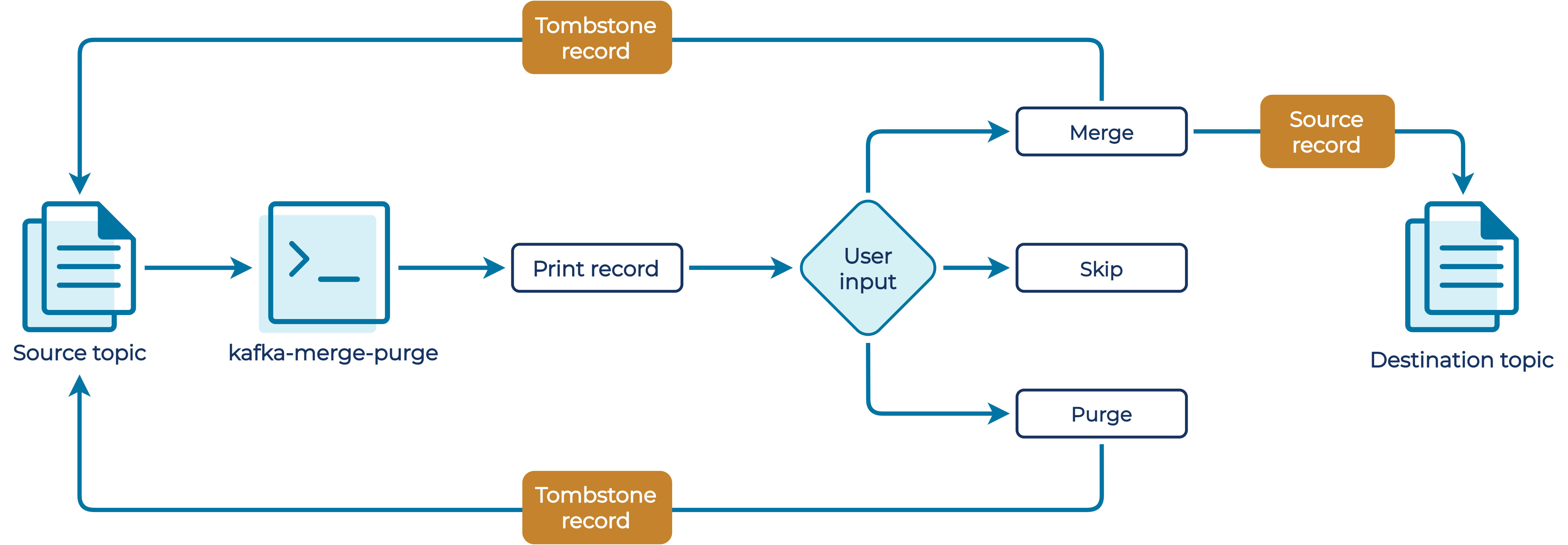
To meet these requirements, we built kafka-merge-purge. On the face of it, kafka-merge-purge is quite simple: Just consume messages from one topic and then optionally write them to another topic. For each record, we allow the user to interactively decide what should be done with it. The application natively supports Avro-serialized messages, which in conjunction with the Confluent Schema Registry allows us to display human-readable JSON for inspection. By default, we use the string deserializer, in order to be as unbiased towards the storage format as possible while not just dumping raw bytes either.
Under the hood, kafka-merge-purge actually uses a custom deserializer and serializer, so that it can retain the original bytes of a record for writing it back to the specified destination topic. This way, we can ensure that messages are not tampered with and that you don’t need to fiddle with any serializer configurations. Furthermore, this makes the application versatile, as it doesn’t need to know the underlying format for writing the messages. Instead, we only deserialize a payload for display purposes.
We have also opted for some opinionated defaults in the configuration of both the consumer and producer instances, which hopefully means that very little customization is required for most use cases. Specifically, we enable the idempotent producer and the read_committed isolation level for the consumer, as we want to keep the behavior of the application as predictable as possible. To this end, kafka-merge-purge also has built-in support for merging messages into the destination topic within a transaction.
Using kafka-merge-purge
Let’s get some hands-on experience with kafka-merge-purge. Say we have a simple event for order cancellation, and the event record can contain a textual reason provided by the customer. We can describe this as an Avro message conforming to the following schema:
{
"type": "record",
"name": "OrderCanceled",
"fields": [
{
"name": "orderNumber",
"type": {
"type": "string"
}
},
{
"name": "reason",
"type": {
"type": "string"
}
}
]
}
We can now use this to produce some messages to a dead letter queue topic:
$ kafka-avro-console-producer \
--bootstrap-server localhost:9092 \
--property schema.registry.url=http://localhost:8081 \
--property value.schema='{"type":"record","name":"OrderCanceled","fields":[{"name":"orderNumber","type":{"type":"string"}},{"name":"reason","type":{"type":"string"}}]}' \
--property parse.key=true \
--property key.separator="=" \
--property key.serializer="org.apache.kafka.common.serialization.StringSerializer" \
--topic order-canceled-dead-letter-queue
ORD001={"orderNumber": "ORD001", "reason": "Ordered too large a quantity"}
ORD002={"orderNumber": "ORD002", "reason": "Ordered the wrong product"}
ORD003={"orderNumber": "ORD003", "reason": "Don't want this anymore"}
Now we can use kafka-merge-purge to write these messages back to the first retry topic:
$ kafka-merge-purge ask -b localhost:9092 -c schema.registry.url=http://localhost:8081 -g order-canceled-consumer -t -a order-canceled-dead-letter-queue order-canceled-retry-1
11:31:15.182 WARN Producer transactions were requested without transactional ID, using random UUID '7c6d4b7d-cb4c-4219-a24f-1b8bbc3454c2' 11:31:15.465 INFO Reading topic 'order-canceled-dead-letter-queue'... 11:31:15.774 INFO Record at offset #0 in topic 'order-canceled-dead-letter-queue' (Partition #0): Key: ORD001 Value: {"orderNumber": "ORD001", "reason": "Ordered too large a quantity"} 11:31:15.775 INFO Would you like to (m)erge, (p)urge or (s)kip the record? (default: merge) m 11:31:32.864 INFO Merged record with key ORD001 at offset #0 from source topic 'order-canceled-dead-letter-queue' (Partition #0) into 'order-canceled-retry-1' 11:31:32.870 INFO Record at offset #1 in topic 'order-canceled-dead-letter-queue' (Partition #0): Key: ORD002 Value: {"orderNumber": "ORD002", "reason": "Ordered the wrong product"} 11:31:32.870 INFO Would you like to (m)erge, (p)urge or (s)kip the record? (default: merge) p 11:31:47.715 INFO Purged record with key ORD002 at offset #1 from topic 'order-canceled-dead-letter-queue' (Partition #0) 11:31:47.717 INFO Record at offset #2 in topic 'order-canceled-dead-letter-queue' (Partition #0): Key: ORD003 Value: {"orderNumber": "ORD003", "reason": "Don't want this anymore"} 11:31:47.717 INFO Would you like to (m)erge, (p)urge or (s)kip the record? (default: merge) m 11:32:01.805 INFO Merged record with key ORD003 at offset #2 from source topic 'order-canceled-dead-letter-queue' (Partition #0) into 'order-canceled-retry-1' 11:32:03.140 INFO Finished processing topic 'order-canceled-dead-letter-queue' 11:32:03.140 INFO Successfully processed records: 2 merged, 1 purged, 0 skipped
As you can see, we get detailed information about where a specific record comes from, and we can inspect its key and value and then decide what to do with it. Since we purged the second record but kept the other two, we can expect to find that the retry topic contains exactly two messages:
$ kafkacat -b localhost:9092 -r http://localhost:8081 -K= -s value=avro -C -o earliest -t order-canceled-retry-1
ORD001={"orderNumber": "ORD001", "reason": "Ordered too large a quantity"} ORD003={"orderNumber": "ORD003", "reason": "Don't want this anymore"} % Reached end of topic order-canceled-retry-1 [0] at offset 3
If we check the dead letter queue now, we should find three tombstone records for the processed keys as well. Indeed, we do:
$ kafkacat -b localhost:9092 -r http://localhost:8081 -K= -s value=avro -C -o earliest -t order-canceled-dead-letter-queue
ORD001={"orderNumber": "ORD001", "reason": "Ordered too large a quantity"} ORD002={"orderNumber": "ORD002", "reason": "Ordered the wrong product"} ORD003={"orderNumber": "ORD003", "reason": "Don't want this anymore"} ORD001= ORD002= ORD003= % Reached end of topic order-canceled-dead-letter-queue [0] at offset 7
Thus, kafka-merge-purge did exactly what we expected, and we can hope that our events are now successfully processed by the retry consumer(s)!
Conclusion
In this post, we outlined our reasons for choosing Apache Kafka as the basis for our new domain event platform at FLYERALARM and elaborated on how we use it to achieve reliable, fault-tolerant event processing. kafka-merge-purge is the ideal tool in this process, should manual intervention be required. We now have everything we need in our toolkit to continue with our move to Apache Kafka, and we’ll hopefully be rolling it out further very soon.
Start building with Apache Kafka
If you want to start building with Apache Kafka too, check out Confluent Developer to find the largest collection of resources for getting started, including end-to-end Kafka tutorials, videos, demos, meetups, podcasts, and more.





