New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Readings in Streaming Database Systems
What will the next important category of databases look like? For decades, relational databases were the undisputed home of data. They powered everything: from websites to analytics, from customer data to scheduling. No problem was out of reach because the way that we imagined how data could be used was narrow.
But over time, people widened their lens. For today’s companies like Lyft, Netflix, and Airbnb, data isn’t just a tool—it’s the crown jewel. This evolution is why new kinds of databases were born—key/value, columnar, document, and graph databases all offer unique ways to ask questions about your data.
Because databases have primarily evolved in terms of how you query data at rest, it’s easy to think that the next important category of databases will look similar to those that came before it. Reality, however, is giving us a different picture.
We live in an instantaneous, always-on world. When you exit a ride from Lyft, you have a receipt barely after your foot hits the pavement. When you split the cost of dinner with a friend using Venmo, funds are transferred in seconds. Software is what makes this possible; data in motion, not at rest, is what makes this a reality.
What sort of database can do that?
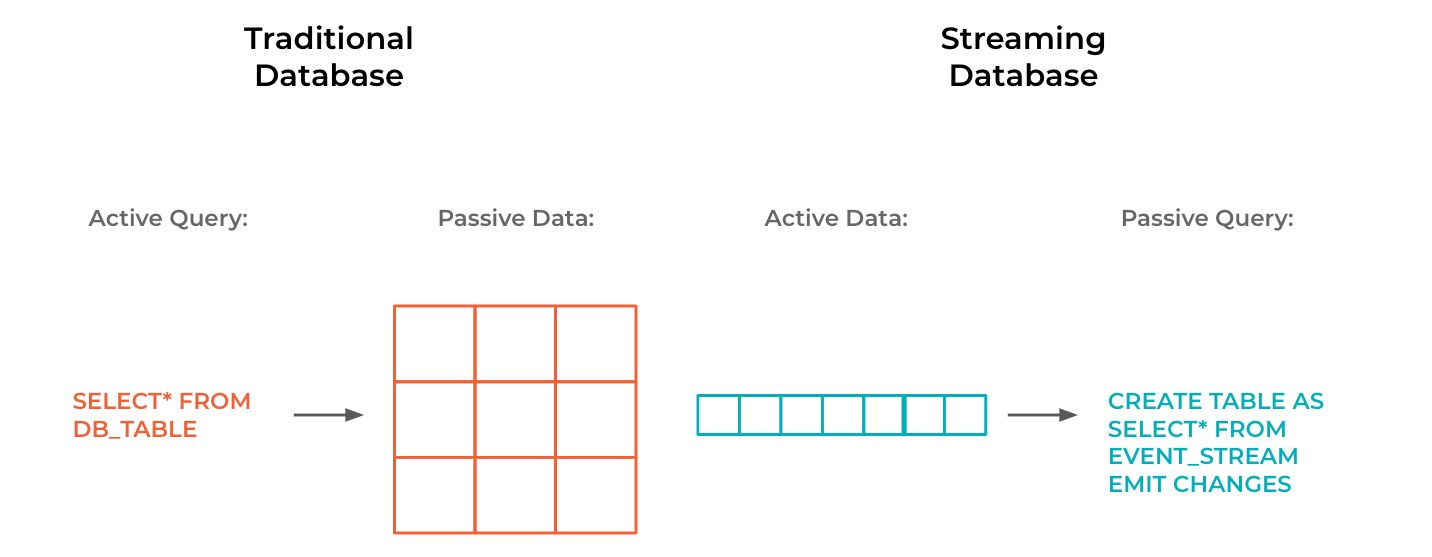
Streaming databases are the answer to that question. A streaming database flips a traditional database on its head. In a traditional database, writes are boring. When you write data into a table, it’s integrated into storage, and nothing else happens. Reads are where the excitement is at. When you issue a query, the database executes it by scanning the data and returning the results. What’s the problem with that? You are blind to everything that happens to your data between two queries invocations. In an always-on world, you can’t be blind to anything.
A streaming database, by contrast, does almost all of its work at write time. When data flows into a streaming database, it’s processed and immediately used to update the results of any registered queries. When applications want to read query results, they can look at all the ways that it has changed over time.
At Confluent, we’ve spent the last four years working on a new kind of database in that vein. The result is ksqlDB. Now, whenever you build something that is genuinely novel, you learn a lot as you go. Four years has been plenty of time to make mistakes, reflect on design trade-offs, and make improvements. In this upcoming three-part blog series, we’d like to share those reflections. They’re interesting in and of themselves, but they also underline why this area is so important for the database community.
Here’s a taste of what you can look forward to.
Posts in this series
- Part 1: The Future of SQL: Databases Meet Stream Processing
- Part 2: 4 Key Design Principles and Guarantees of Streaming Databases
- Part 3: How Do You Change a Never-Ending Query?
Adapting SQL for streaming and data in motion
How do you write a program that runs on a streaming database? In fact, how do you write a program that runs on any database? Most of the time, you find yourself writing SQL. That is no accident—SQL is an abstraction that has stood the test of time. A streaming database should follow suit.
There’s just one problem: SQL was originally framed as a language for querying data at rest. If you want to query data in motion, what would you need to change? Confluent, among others like Oracle, IBM, Microsoft, and Amazon, are jointly working on a streaming SQL standard to figure that out. In our first post, The Future of SQL: Databases Meet Stream Processing, we’ll explore the key elements of what that might look like.
CREATE TABLE weekly_balance AS
SELECT card_number, windowsStart, SUM(amount)
FROM transactions
TUMBLING WINDOW (SIZE 7 DAYS,
GRACE PERIOD 1 DAY,
RETENTION TIME 1 YEAR)
GROUP BY card_number;
One thing is for sure—getting the abstraction of a database right is more important than ever. Because these systems are now born in the cloud, the underlying implementation becomes less interesting. The abstraction is, purposefully, your only way to interact with them.
Foundations in streaming database design
When you trust your data with a particular database, you have high expectations for its durability and correctness. Everyone wants more certainty, not less. This is even truer in streaming databases, which sit at the center of a company’s data channels.
In our second post, 4 Key Design Principles and Guarantees of Streaming Databases, we’ll look at the mechanics of correctness. Although some of these design patterns are borrowed from traditional databases, the majority are uniquely engineered for always-on streaming systems. Log-based architectures, like Apache Kafka®’s, make it possible to design for trade-offs across data completeness, timeliness, and cost. Here again, the challenges are multiplied by databases that are cloud resident: If you, the developer, don’t want to interact with the implementation of your infrastructure, you need to have strong guarantees about how it’ll behave when something goes wrong.
Streaming queries
One of the most striking differences between traditional databases and their streaming counterparts is how many ideas are polar opposites. In a traditional database, you run queries over data at rest, which terminate after they scan your tables. Here, queries have a finite lifetime. But in a streaming database, you run queries over data in motion. These queries never terminate.
Now, what happens when you want to change an indefinitely running query? Unlike a traditional query, you can’t wait for it to complete. It never will. Instead, you need to change it while it continues to process data. Managing change without downtime is the subject of our third post, How Do You Change a Never-Ending Query?
The streaming database series
Maybe data is your company’s crown jewel. Maybe you want to widen your lens of how you use data. Or perhaps you just want to learn about how databases work. Whatever your interest, we look forward to sharing this blog series on streaming databases with you soon.
Until then, check out ksqlDB to learn more.
Other posts in this series
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.