New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Are We There Yet? The Query Your Database Can’t Answer
What if I told you there is a query your database can’t answer? That would probably surprise you. With decades of effort behind them, databases are one of the most robust pieces of software in existence. Because they have remained enormously popular in their current form, many engineers assume that their database can answer any query they have if they’re willing to wait long enough.
This, however, isn’t a great assumption. Why? Nearly all databases are linked by one common trait: They exclusively query data at rest. When you issue a query, the database executes it by scanning the data and returning the result. The problem is that this architecture inherently puts some queries out of reach. Namely, you can’t write a query whose result updates every time the underlying data changes. You’re blind to everything that happens in between two query invocations. And that is important if what you are doing is driven by software.
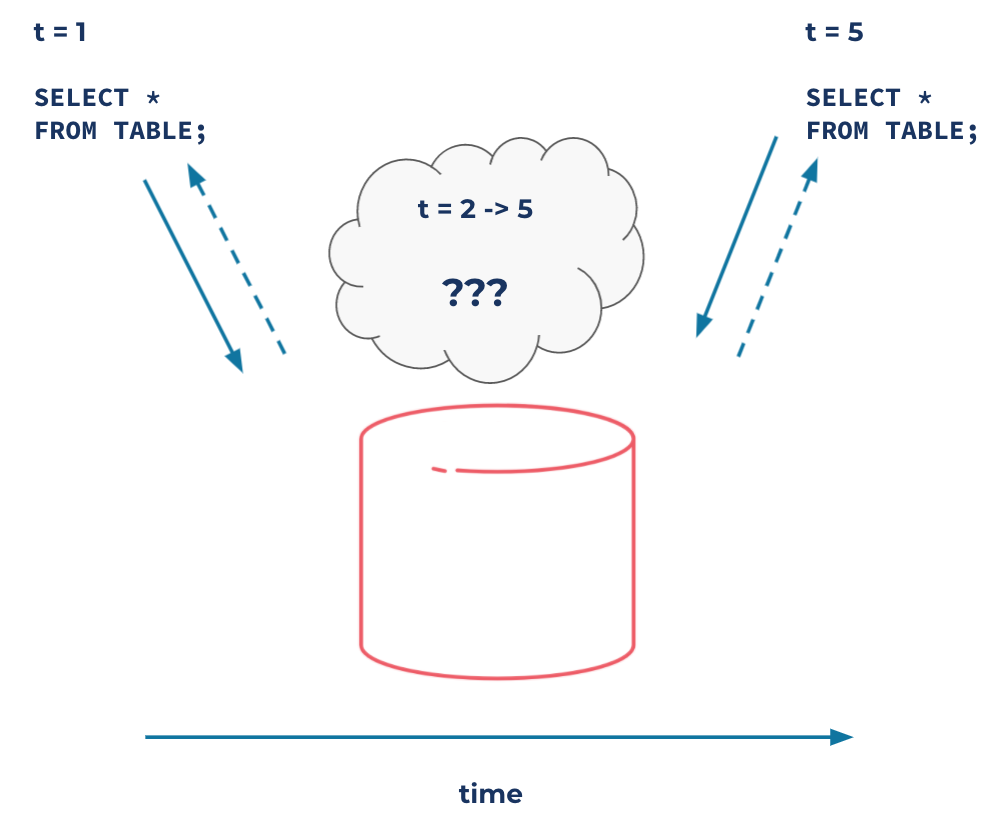
Are we there yet? Are databases complete?
The real end goal
If you had a database that could update query results every time the data changed, you might say it’s reactive. Although reactivity is a missing piece in many databases, it’s the heart of event streams and stream processing—as new events are received, applications immediately react by processing data to take some action.
Stream processing’s reactivity nearly makes it an ideal fit to serve queries for applications. Although this can work, it has a serious weakness—it detonates the tidy abstraction of the database. Databases—in particular, SQL—hide all the underlying complexity of query execution, indexing, concurrency control, crash recovery, replication, and so on. When you make a stream processor responsible for serving queries, you take components that used to be neatly hidden by your database and graft them onto your application. You’re now on the hook to make a lot more things work correctly.
I think the better path is to recognize a hidden relationship: Stream processing is the other half of databases. Databases manage data at rest; stream processing manages data in motion. They just don’t yet fit together.
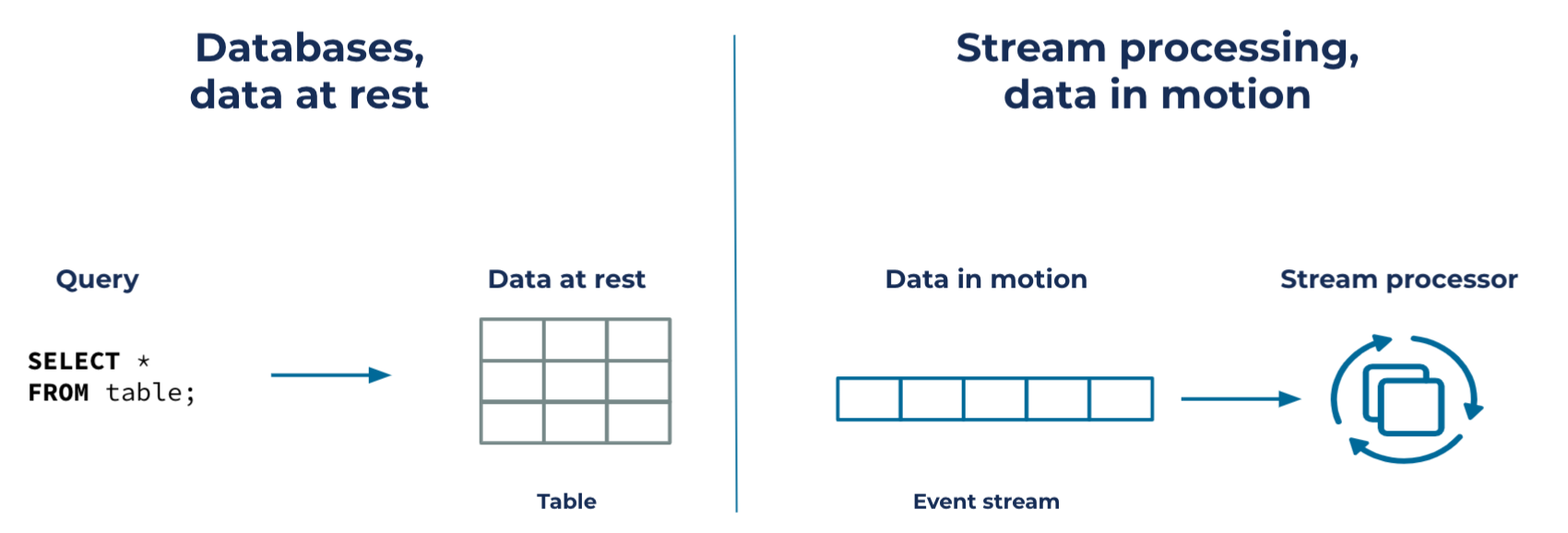
So what would it take to bridge these two worlds?
Confluent has been working on a new kind of database named ksqlDB that tries to do exactly that. It helps you both query your data and react to changes. But instead of managing all of the complexity yourself, you interact with it solely through the abstraction of a relational database—like Postgres. For its transaction log, it relies exclusively on Apache Kafka®.
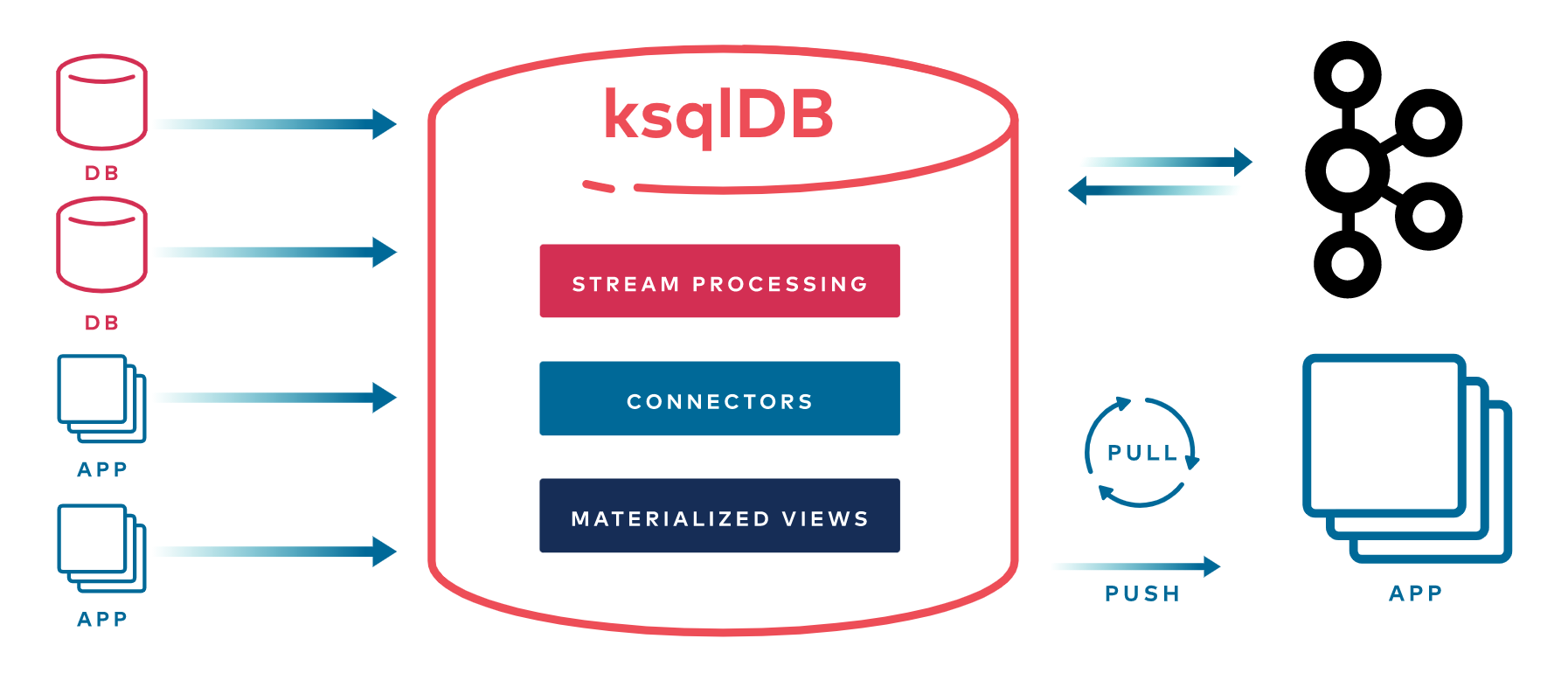
Let me be up front: Although ksqlDB has a strong feature set today, completing its larger vision of marrying databases and stream processing remains an ambitious work in progress. That progress—the subject of this post—relies on a lot of deep work happening in the Kafka ecosystem.
So let’s look at that deep work in each layer of the stack—from data capture, to storage, to processing, to query execution—to get an idea of what it will take to answer the unanswerable query.
Where better to start than the beginning?
Connecting the software world
Whenever you imagine building an event-driven system, it’s easy to make one crucial, yet incorrect, assumption about how it will work: that the events you want will already be captured in a stream.
But that’s not how it works in practice. Events are born outside of streams: in other databases, other web apps, other servers. Some piece of code, somewhere, needs to be smart enough to send data to (or receive data from) a stream. This is almost always overlooked because it intuitively feels like a solved problem; all the cool computer science work you hear about related to event streaming tends to be about processing or storage. You tend to hear less about byte shoveling.
But like anything in life, nothing is free. In the beginning, there was no built-in software that did this with Kafka. You had to write your own specialized programs to transport data in a scalable, fault-tolerant, correct way. You had to do this for every data system that you wanted to integrate with, source and sink. This isn’t just annoying grunt work; it is quite hard to build for systems that don’t natively expose a change data capture mechanism.
If this part didn’t work well, nothing else mattered. Without events, what is the point of any of this? The first order of business was to make a framework so that we could isolate all of the common complexity for communicating with external systems. Kafka Connect was added to Apache Kafka in 2015 to do just that.
Ever since then, Connect’s mission has been delightfully single minded: Build a connector to and from everything. There are now more than 200 connector integrations, many of which are pearls of engineering. Consider the suite of Debezium connectors that do change data capture against MySQL, Postgres, MongoDB, and friends. Or take the connectors that integrate with SaaS apps like Salesforce. There’s even a connector to source data from Oracle.
Out of focus comes power. ksqlDB builds on this to make it easy to source and sink events with connector management. Using SQL, you can interactively create connector objects:
CREATE SOURCE CONNECTOR riders WITH ( 'connector.class' = 'JdbcSourceConnector', 'connection.url' = 'jdbc:postgresql://...', 'topic.prefix' = 'rider', 'table.whitelist' = 'geoEvents, profiles', 'key' = 'profile_id', ...);
Break out your shovels—bytes are now in motion. The connectors run in a fault-tolerant, scalable manner across ksqlDB’s servers, all thanks to Kafka Connect.
A log you can depend on
Once you’ve managed to capture events, you need a home for them. In databases, we call that the log. If the log, stored as a Kafka stream, is going to be the backbone of your architecture, there can be no doubt in your mind about its stability.
But a decade ago, that wasn’t exactly the case. There were lots of unanswered questions about what it would be like to use Kafka for mission-critical use cases.
Yes, it’s cool, we said, But can it store all my data? Kafka used to store data only on the brokers’ disks, which meant that it was storage bound against the broker with the least amount of capacity. You had to choose between provisioning expensive, high-capacity disks and storing less data. But it was worse than that. Many use cases, like auditing and online machine learning, can’t work with streams that have short retention.
What might be better? Object stores, like Amazon S3 and Google Cloud Storage, offer effectively infinite storage capacity. If Kafka were to use those services as storage backends, it could be made to store huge volumes of data. In 2020, Confluent introduced Tiered Storage to make that a reality. And for Apache Kafka, KIP-405 aims to introduce similar functionality. This technique has made it possible to store limitless amounts of data in streams for absurdly cheap costs.
Sure, but can it survive a regional outage? We live in a world that is always on, 24×7. A datacenter outage isn’t just inconvenient anymore—it can be damaging. If Kafka is going to be used for anything critical, you need to be able to count on your data being available, even when an entire availability zone is lost. Until recently, the conventional technique for making Kafka immune from outages was to simply “stretch” the cluster’s nodes across data centers. This idea worked somewhat, but it was far from perfect. The further the nodes move away from each other geographically, the harder it becomes to operate the cluster.
There is not a soul who has worked with Kafka and didn’t want an easier way to do cross-datacenter replication. And in 2020, it got one—two, actually. Apache Kafka added geo-replication (under the project name MirrorMaker2), which is a piece of software that sits in the middle of two Kafka clusters, replicating between them (it’s cleverly built on Kafka Connect). The second was an addition to Confluent, named Cluster Linking—instead of using a middleman for replication, it uses Kafka’s native replication protocol to copy data directly.
Okay, but can I keep it up? When it comes to infrastructure, everything is riding on your confidence in keeping it online. If it’s hard to operate, it won’t stay up, and it will give you no value. Running Kafka yourself used to be hard. It wasn’t as battle-tested as it is today, and no one had time to specialize in operating it. You had to carefully choose your cluster size, then police everyone who used it to play by your administrative rules.
Software as a service in the cloud has completely changed this. It’s no longer the case that Kafka is only suitable for big projects or high-volume workloads. You can get an inexpensive Kafka cluster from many cloud vendors, like Confluent Cloud—with an SLA. You are shielded from all of the hard work of keeping brokers healthy. Running Kafka is someone else’s problem now.
Simply put, a database is nothing without its storage engine. Likewise, ksqlDB is nothing without Kafka. It’s only useful because its transaction log is capacious, shareable, durable, and inexpensive. But what do we do with that data after we’ve stored it?
Processing the stream of puzzle pieces
A stream full of events is only useful if it can be processed. This is the heart of where stream processing meets databases—you write queries whose results are revised as soon as new information is received.
For newcomers, this idea sounds exotic, but it’s easy to understand with an analogy: Processing data is like solving a jigsaw puzzle. With traditional database query processing, every query is like a brand new puzzle. You are given all the pieces up front, but you can’t see the picture the puzzle will reveal until all of its pieces have been fit together.
With stream processing, queries run indefinitely—it is like solving one puzzle continuously, where you are given only a few pieces at a time. You immediately fit the piece you are given into the puzzle as best as you can. By contrast to traditional query processing, stream processing lets you see the puzzle’s picture as it evolves. This is just like solving a real puzzle—you don’t need to wait until the end to learn what it will reveal.
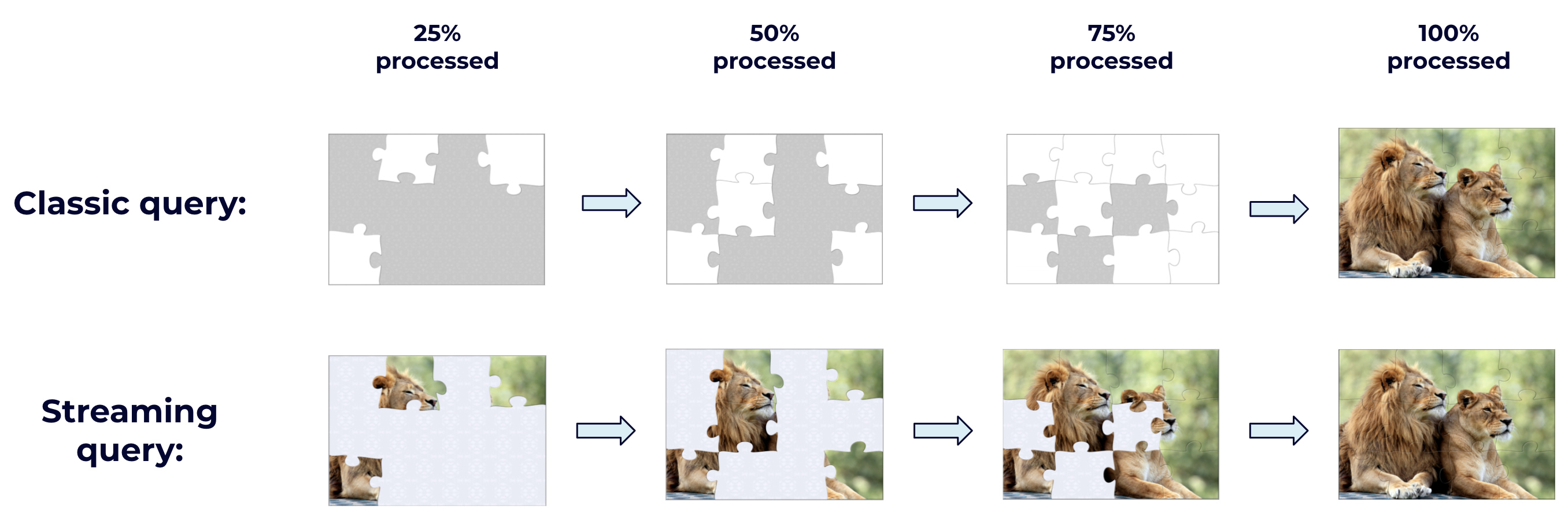
The analogy works because seeing the face of the puzzle is just like seeing the results of a query. But this isn’t just attractive because you can receive query results early. It’s attractive because the intermediary states of a query often have value in themselves.
The utility of stream processing is clear—but how do you build a system to do that? Before Kafka, the answer wasn’t obvious. Stream processing was and still is a new paradigm of programming. Back then, it had limited APIs, and the theory behind it was still being figured out. Let’s look at three of the most important concepts that have evolved since then: time, scale, and synchronization.
Time
First, time. To depart from the metaphor, a stream processing puzzle is never finished because you don’t know if you have all the pieces yet. This is reflective of real life—it is hard to know if you ever have all the data that you will get. In 2015, the Google Dataflow paper explored this tension, framed as a trade-off between correctness, latency, and cost.
One consequence of not knowing if you have all the data yet is dealing with receiving data out of order. Event data, by definition, carries a timestamp—the time at which the event happened. What happens if you receive “older” events after “newer” events? There are plenty of situations where this can happen.
Here’s a quick example. Consider a simple stream processing program that tallies how much money a business is making each day. As orders flow in, the revenue is summed up for whatever day today is. But now imagine that a batch of orders was submitted late. The orders were placed yesterday, but you only received them today. The appropriate action is to adjust the daily revenue totals for yesterday. But if all your program knows how to do is add to today’s total, you’re toast.
In the past, you’d have to pick your poison: either throw away the data, or use a batch processor to mop up the problems later. The latter, known as the lambda architecture, was particularly pernicious because it meant that you had to write your program twice—in both your stream processing and your batch processing framework.
There is no single thing that changed to make out-of-order stream processing easier. Rather, a collection of solutions evolved over the course of 2014 to present day.
Kafka Streams, Flink, and Dataflow all built APIs that mostly handle out-of-order data by default. This means that other than hinting to the stream processing framework where to find the timestamp, you don’t have to do anything to get correct answers. Most APIs accomplish this with windowing—tumbling, hopping, sliding, and session windows help you slice time in different ways, but all handle disorder transparently.
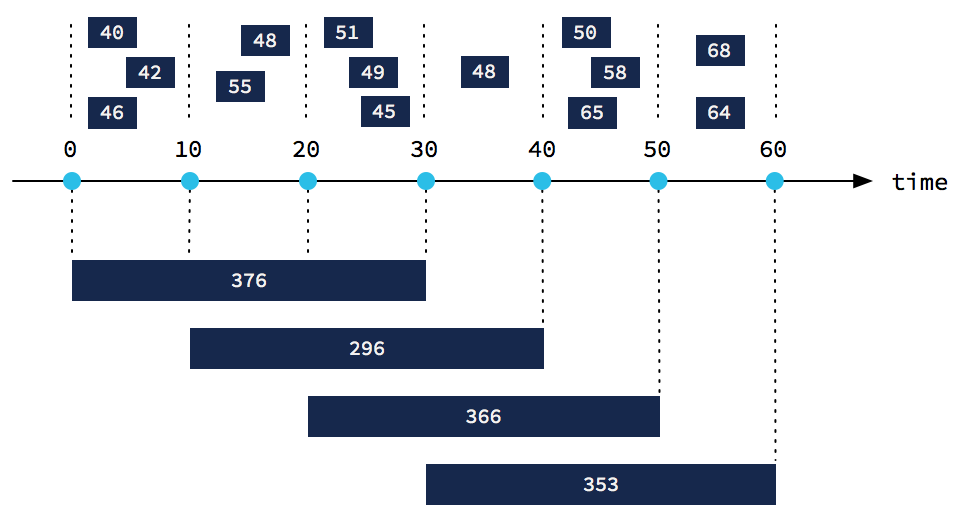
At the same time, we had to deal with data being “too late” to be useful. Kafka Streams pioneered the concepts of stream time, grace periods, and retention. Flink spearheaded watermarks and a unified API for batch and stream processing.
Programming with time will probably always be tricky, but the progress is undeniable.
Scale
Now, scale. What is it that motivates someone to architect with event streams? One of the reasons is often scalability. When you maintain state with a stream processor, you decentralize where your queries run; instead of having them all run together in your database servers, you place them onto different application services. This allows you to adjust how many resources are dedicated to each query. If you have a query that needs to process a lot of data, you can add more machines to parallelize the work.
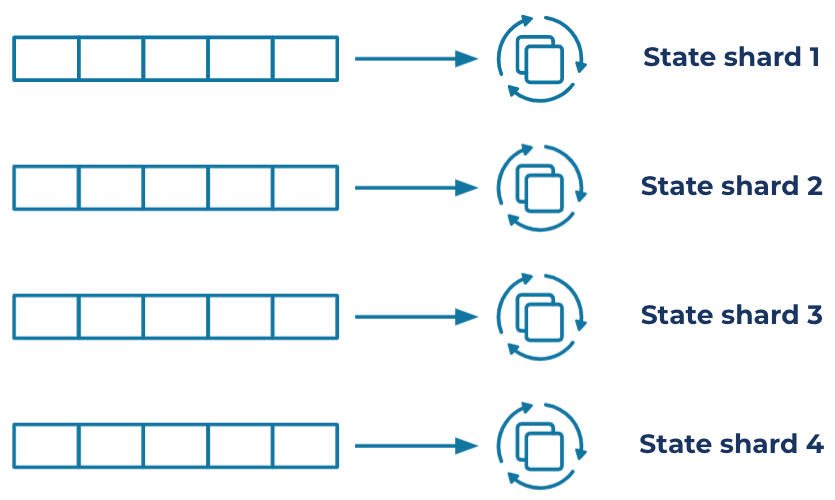
This is hugely useful, but how does it work in practice?
Imagine that you have a cluster of two nodes processing a stateful query. The two nodes divide the keyspace and create localized, aggregated state. Now, what will happen if you add a third node to your cluster? Early on, this was a recipe for pain. What you need to do is redivide the keyspace and shuffle the data evenly across the three nodes. Data shuffling has always been a hard problem, but it’s even more challenging in an always-on stream system. Until recently, Kafka Streams’ solution to this problem was to stop the world. A global rebalance would take place, and availability was only restored when the rebalance completed. The more state you had, the longer this took.
Global rebalancing—goodbye. Say hello to cooperative, incremental rebalancing. Added in 2020, incremental rebalancing helps Kafka Streams shuffle the minimum amount of data across nodes when a cluster changes size. There is no avoiding shuffling in distributed processing systems, but you can minimize the amount of pausing and data movement. Kafka Streams does this by default now.
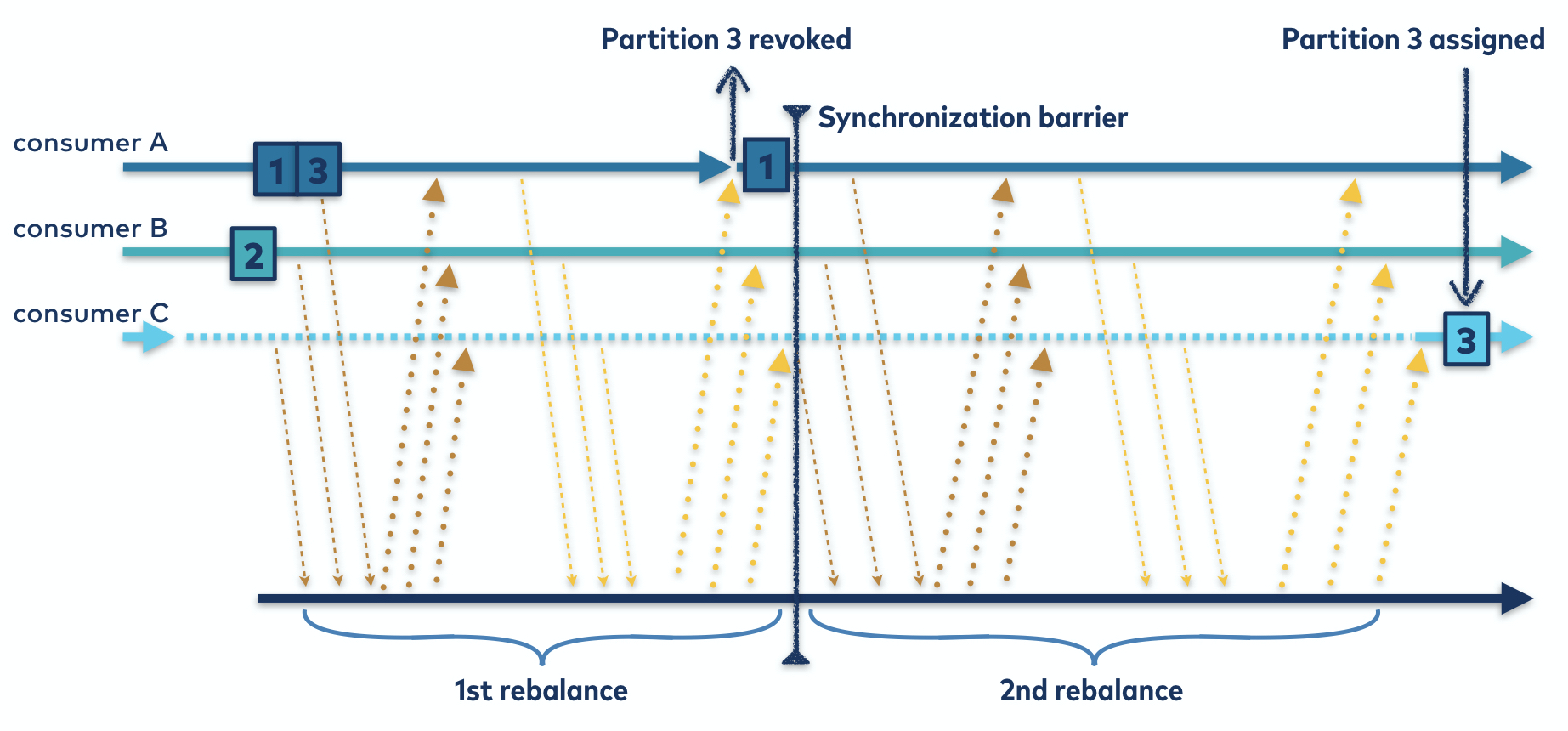
Synchronization
Finally, synchronization. If events are the currency of your system, it’s important that the teller be precise when following your instructions. But whenever distributed systems are involved, there’s sure to be easy ways to make mistakes. In particular, when distributed nodes exchange messages, failures can create retries, which in turn can create duplicate messages, loss of messages, or partial execution of instructions. Kyle Kingsbury has made a living showing what a mess this can be.
When Kafka took off, it couldn’t make strong guarantees about how messages would be exchanged under failure scenarios. There wasn’t a way to work around this—these are low-level guarantees that need to be made for you by the infrastructure.
If Kafka was going to be used for mission-critical workloads, this needed to change. So in 2017, Apache Kafka added exactly-once semantics (EOS). EOS means three things: idempotent message sending, transactions, and idempotent stateful processing. You need all three of these to completely solve the problem of reliable message processing. With this in place, Kafka became trusted for situations where there just isn’t room for error.
Where is ksqlDB in all this? Happily solving jigsaw puzzles. Out-of-order data is handled transparently thanks to Kafka Streams’ API. Cluster scaling works without much of a thought. And exactly-once semantics can be activated with a single server flag.
We’ve worked our way across the stack: from data acquisition, to storage, to processing. What’s left? The most striking feature of databases is what’s left.
Queries under one roof
Close your (figurative) eyes. Think about sitting down at your laptop to use a database. What do you see?
You probably see yourself typing some text into a console. That text is probably SQL.
SQL-based databases have dominated for decades, and rightly so. Their query models are easy to use and easy to understand. If stream processing is to become the other half of databases, we need to pursue a similar abstraction that encompasses everything we’ve talked about so far.
ksqlDB is one attempt at that abstraction.
Its query layer, built around SQL, uses a simple client/server architecture—just like how Postgres works. Instead of communicating directly with the underlying components, you use SQL to create streams, inspect tables, derive materializations, and issue queries. You see only two layers: storage (through Kafka) and compute (through ksqlDB). Both elastically scale independently from one another.
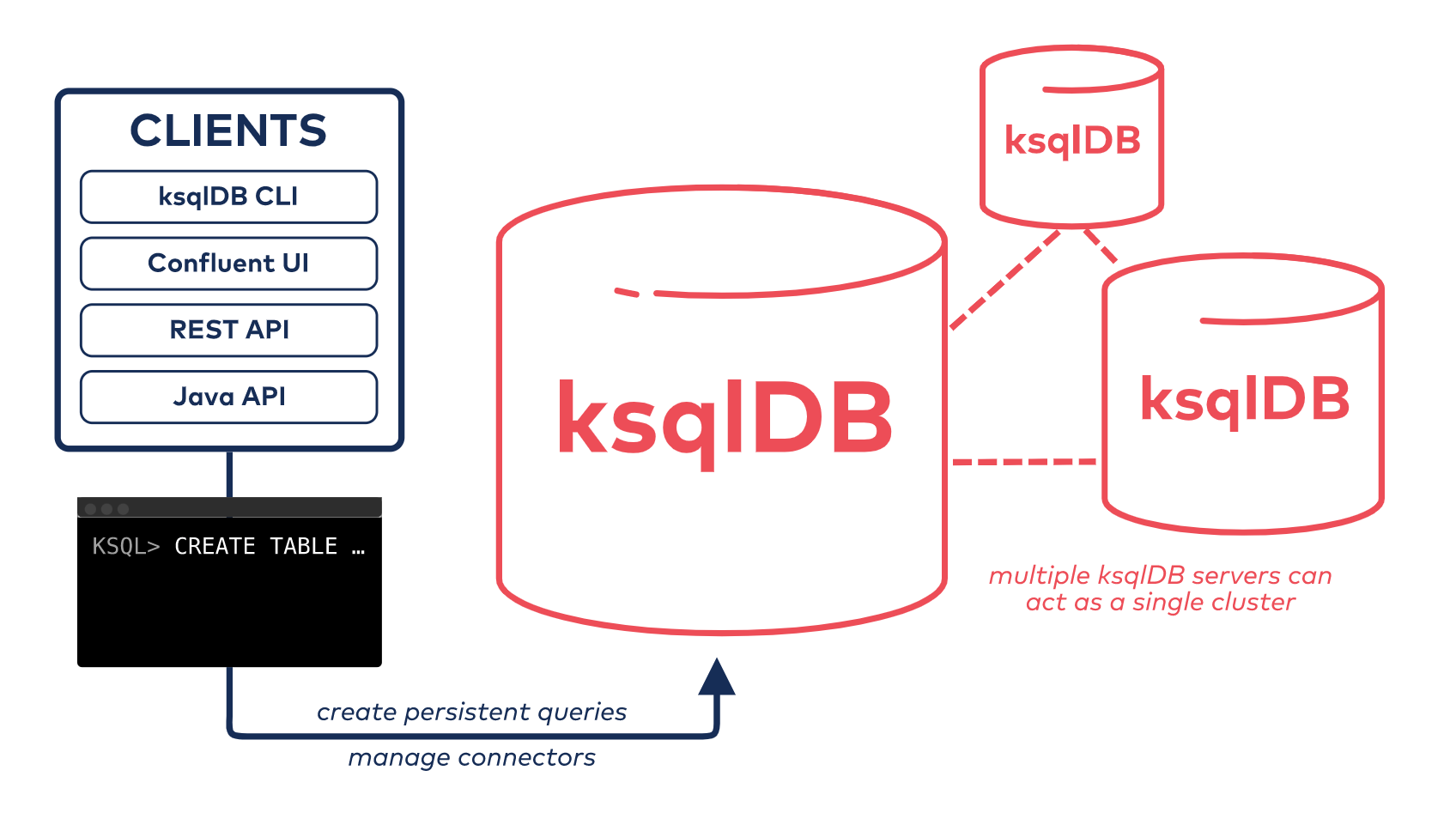
When you want to query your data, accessing your tables of state is simple. Because all of the work to update your query’s state (fitting each puzzle piece) happens at processing time, reading the results of a query (seeing the face of the puzzle) is predictably fast. There is no work to be done. Although this idea is straightforward in theory, building your architecture around it is more challenging.
For example, in a distributed cluster, how will you find the right server to issue your query against? And what should happen if the data you’re looking for has recently moved to another server? How do you make the networking between the client and servers not a problem for everyone who has a query?
ksqlDB makes this easy with its dual query support. When you issue queries to ksqlDB’s servers, it’s able to automatically route your query to the right node—even in the face of failures. This is all thanks to KIP-535 in Kafka Streams, which augmented its state store APIs to support replica information. Using this, ksqlDB can serve pull queries (request/response style) and push queries (streaming style).
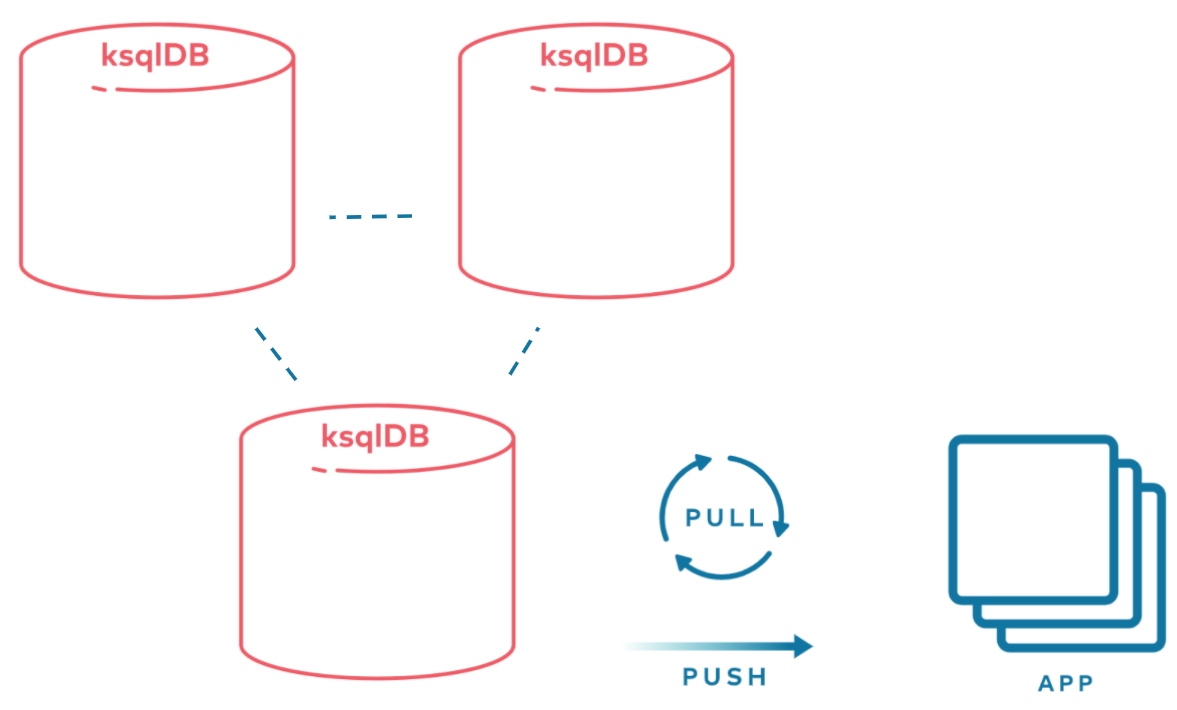
So, is this it? Are we there yet?
The road ahead
For all the progress we’ve made, we’re not there yet. A book could be filled with the remaining gaps, but for now I’ll briefly touch on three of the larger ones. In a follow-up post, I’ll discuss more of them in detail.
The first area that has a range of open problems is at the top of the stack, the query layer. To support request-response style queries, ksqlDB ought to handle ad hoc SQL. Today, it has more limited expressivity that’s bounded by its ability to generate additional indexes. And to support streaming style queries, the SQL language needs to be rethought and extended. There’s an ongoing standards committee (DM32 Technical Committee of INCITS), made up of companies like Microsoft, Google, Oracle, IBM, and Confluent, taking a shot at that problem.
Another part of the picture that needs more thought is consistency with fault tolerance, both across replicas and between the source/sinks. All things being equal, it’s easier to build applications against data systems with stronger consistency guarantees than weaker ones. Today, ksqlDB is a fault-tolerant, eventually consistent system. Other projects are approaching this in the reverse direction by starting with strong consistency and no fault tolerance. The end goal is clearly to get both.
Lastly, there’s a hidden gem in the world of stream processing that’s worth remembering. One of the perks of using stream processing to materialize state is that you can choose your storage backend. If you need to do fast lookups, you can use a key/value store. If you need to do analytical queries, you can plug in a columnar store. Relational databases support swappable storage engines to some degree, but stream processors traditionally give you far more latitude. Today, ksqlDB bakes in the choice of RocksDB. But in a more mature version, this choice should be given back to you to recover the flexibility.
What’s next?
Databases and stream processing will increasingly become two sides of the same coin. At this point in engineering history, the metal of those technologies are still melding together. But if it happens, 10 years from now the definition of a database will have expanded, and stream processing will be a natural part of it.
It’s at this point in a blog post that you’d usually find a call to action—try a tutorial or submit your resume to a job opening. But if you’ve read this far, I want to motivate you to try something different: tinker with abstractions; read academic papers; meet new people in computing. Uncovering hidden relationships—like the one between databases and stream processing—is key to making software better. And it’s really fun.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.