New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Cloud-Like Flexibility and Infinite Storage with Confluent Tiered Storage and FlashBlade from Pure Storage
With the release of Confluent Platform 6.0, we officially made Tiered Storage generally available. At launch, we supported two major cloud-specific object stores: Amazon S3 and Google Cloud Storage. Today, we are very excited to add support for our first on-premises object storage: FlashBlade from Pure Storage.
Storage is absolutely critical to get right, which is why we worked very closely with Pure Storage for this certification. It was an absolute treat to work with the team—they certainly know their stuff and we think you’ll be impressed with the performance, scale, reliability, and ease of use that comes with it.
What is Tiered Storage?
Tiered Storage gives users the ability to separate compute from storage in Confluent Platform. We do this by tiering data as it’s written to the broker to remote object storage. A new topic-level setting, hotset retention, defines how long data will stay local to the broker before being reclaimed. This provides a number of advantages.
Elasticity
Combined with Self-Balancing Clusters in Confluent Platform 6.0, scaling Apache Kafka® brokers up and down becomes extremely fast. Because the majority of the data is offloaded to the remote store, only a small subset of the data on the broker’s local disk must be replicated between replicas. This process is automated for adding and removing brokers when Self-Balancing Clusters are enabled. This results in significant operational improvements by reducing the time and cost to rebalance, expand or shrink clusters, or replace a failed broker.
Infinite retention
More and more, Kafka is being used as a system of record. By retaining data in Kafka, the data can be easily reprocessed or streamed into new or existing systems. It is common to limit the amount of data stored in Kafka either due to local storage limitations, technical requirements (such as managing rebalancing), or business-related reasons. Tiered Storage alleviates those concerns and makes it possible to infinitely retain data in Kafka while reducing the operational burden and cost.
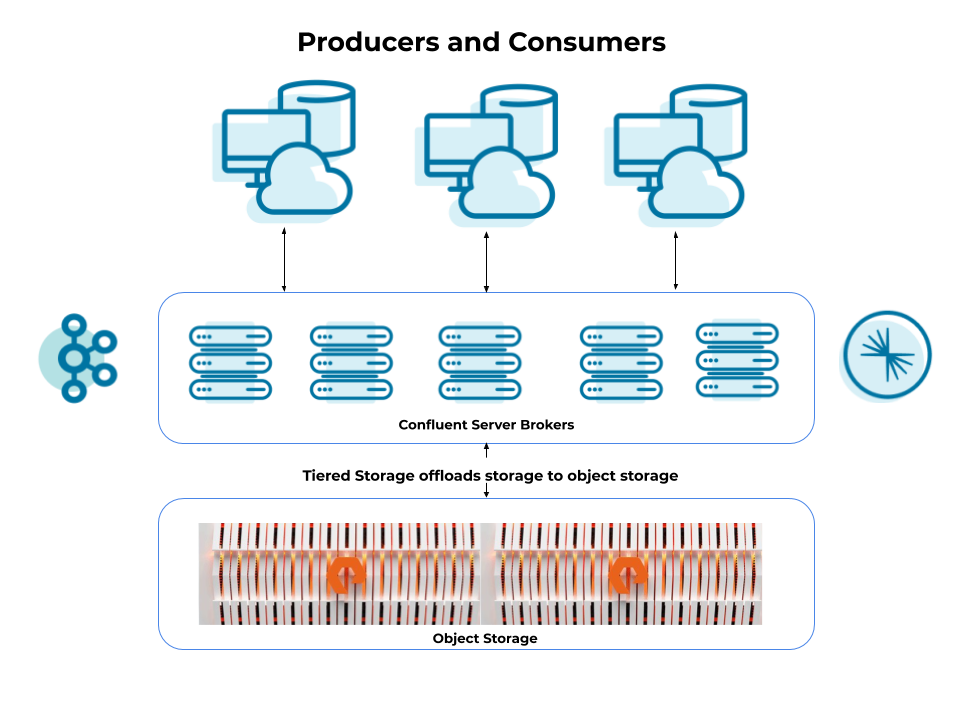
Why Pure FlashBlade?
Pure FlashBlade is an extremely advanced (and fast) object storage platform that’s designed to deliver amazing throughput and parallelism with reduced latency. Tiered Storage connects to FlashBlade via the S3 API, so setup is convenient and easy.
In order to certify FlashBlade, we focused on two very critical areas:
- Performance: Can FlashBlade handle the throughput demands of Apache Kafka without introducing major regressions or lag?
- Reliability: Under significant load, does FlashBlade maintain SLAs and data correctness?
Fortunately, FlashBlade not only passed but exceeded our expectations. In performance tests, Pure FlashBlade was able to hit up to 7.5 GB/sec of sustained throughput. This number is extremely impressive and scales linearly as the FlashBlade grows in size.
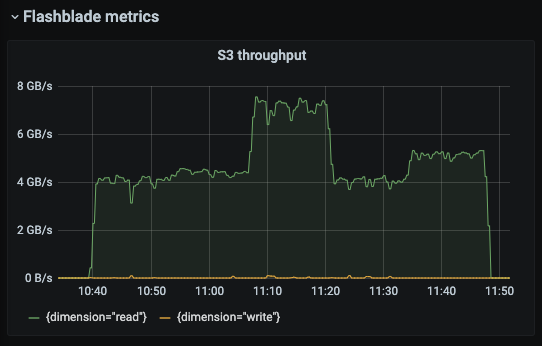
Just as it is important for FlashBlade to handle high, sustained throughput, it’s also important to ensure correctness and reliability. We conducted a series of high-throughput tests where we measured correctness by waiting for data to expire locally from the broker and reading it directly from FlashBlade. We ran this test multiple times on multiple days to generate an accurate sample. As expected, FlashBlade passed these tests with no failures whatsoever.
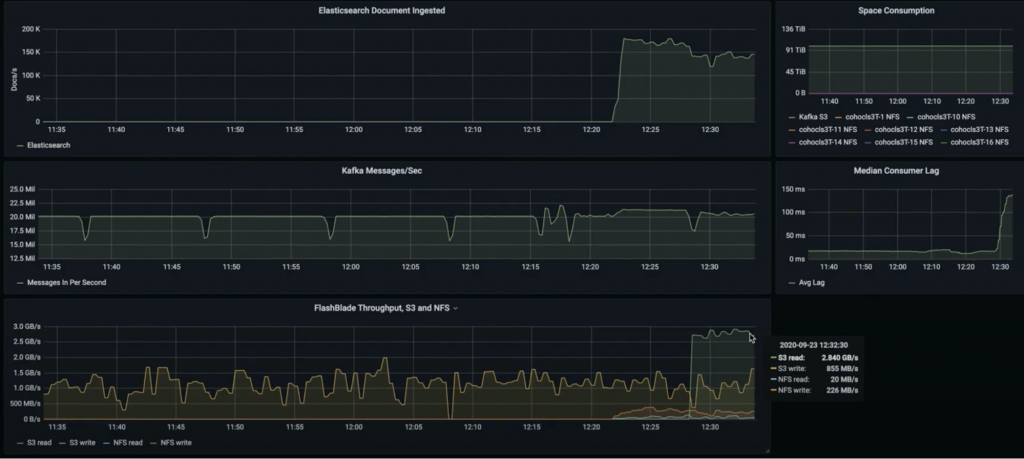
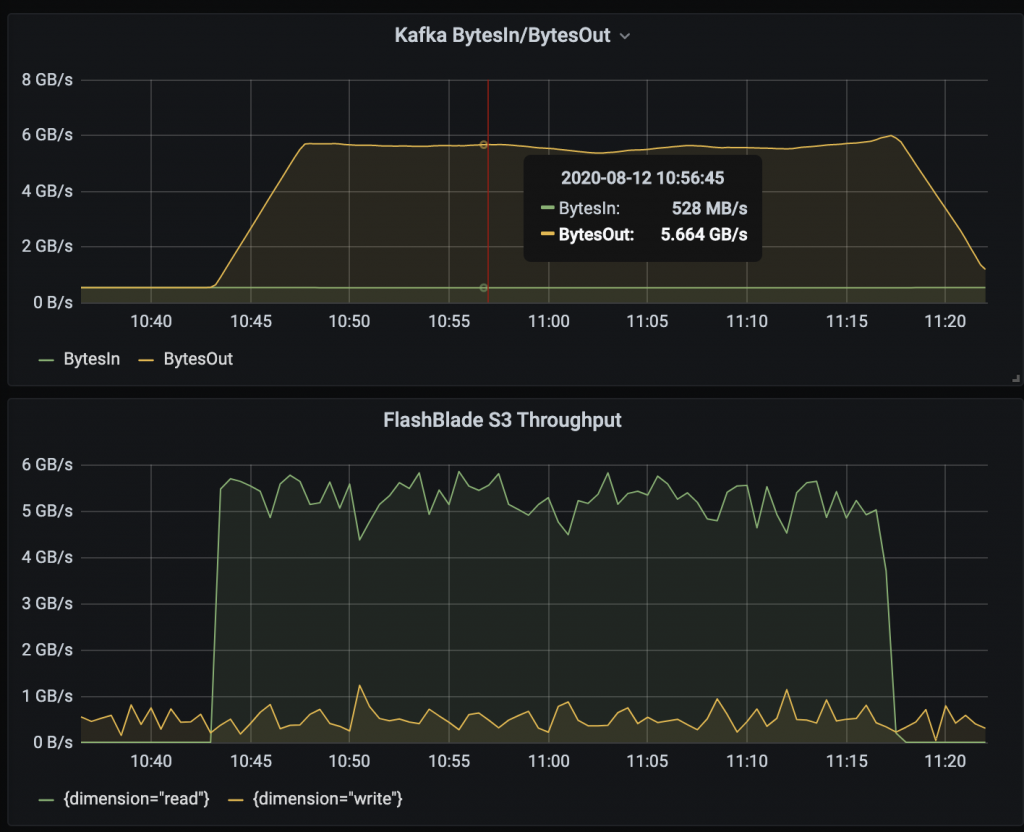 Apache Kafka and FlashBlade throughput metrics taken directly from our testing environment
Apache Kafka and FlashBlade throughput metrics taken directly from our testing environment
It’s not all about speeds and feeds though—FlashBlade helps Confluent Tiered Storage bring cloud-like elasticity on premises. Need to expand storage? Simply add blades to scale capacity instantly with no downtime.
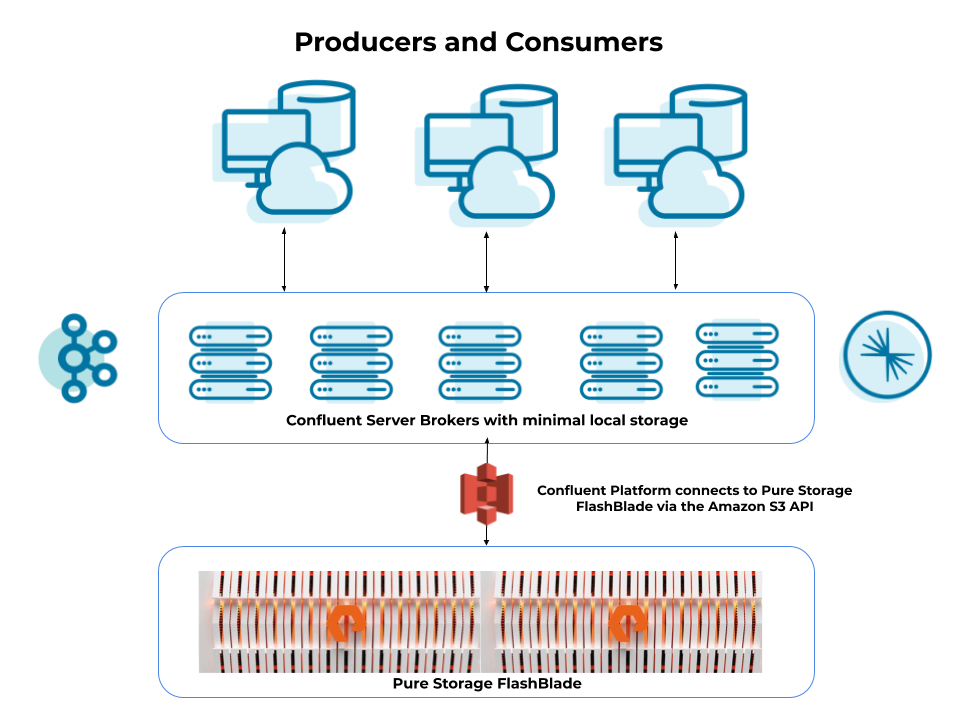
What’s really great about pairing Tiered Storage with FlashBlade are the use cases that it enables. Having all of your data efficiently stored on flash storage means that running analytics, historical queries, or hydrating downstream systems is extremely fast and efficient.
Our friends at Pure Storage made an awesome demo showcasing Tiered Storage and FlashBlade pair together when using tools like Elasticsearch and ksqlDB.
Together, Tiered Storage and Pure FlashBlade bring an easy-to-use, cloud-like experience on premises combined with excellent performance and reliability.
Learn more
If you’d like to learn more, join the webinar to see Confluent Tiered Storage and Pure FlashBlade in action.
To learn more about the Pure FlashBlade and Confluent Platform announcement from Pure’s perspective, take a look at the blog post by Navin Albert, solutions manager at Pure Storage.
To get started with Tiered Storage, you can download the Confluent Platform, the complete event streaming platform built by the original creators of Apache Kafka.
A lot of time and care was put into ensuring the quality and performance of this integration. A special thank you to the Pure Storage (Craig Halliwell, Navin Albert, Joshua Robinson, Kelly Jo Smith, and Stashka Lepera) and Confluent (Kowshik Prakasam, Dhruvil Shah, Rittika Adhikari, Lisa Sensmeier, and Sid Rabindran) teams who helped with this effort.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.