New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Error Handling Patterns for Apache Kafka Applications
Apache Kafka® applications run in a distributed manner across multiple containers or machines. And in the world of distributed systems, what can go wrong often goes wrong. This blog post covers different ways to handle errors and retries in your event streaming applications. The nature of your process determines the patterns, and more importantly, your business requirements.
This blog provides a quick guide on some of those patterns and expands on a common and specific use case where events need to be retried following their original order. This blog post illustrates a scenario of an application that consumes events from one topic, transforms those events, and produces an output to a target topic, covering different approaches as they gradually increase in complexity.
Pattern 1: Stop on error
There are cases when all input events must be processed in order without exceptions. An example is handling the change-data-capture stream from a database.
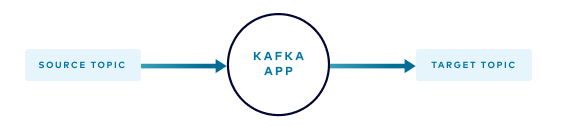
The following diagram illustrates how events in the source topic are processed or transformed and published to the target topic. An error in the process causes the application to stop and manual intervention is required. Notice that the events in the source topic cannot take any other path.
Pattern 2: Dead letter queue
This is a common scenario where events that cannot be processed by the application are routed to an error topic while the main stream continues. It’s important to note that in this approach there are no conditions that require or support a retry process. In other words, an event can be processed successfully, or it is routed to an error topic.
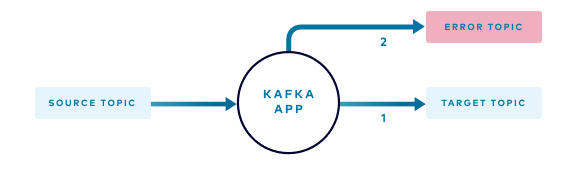
The following diagram illustrates how events in the source topic can take one of two paths:
- Under normal circumstances, the application processes each event in the source topic and publishes to the target topic
- Events that cannot be processed, for example, those that don’t have the expected format or are missing required attributes, are routed to the error topic
Pattern 3: Add a retry topic and retry application
What happens if the conditions required to process an event are not available when the application attempts to process the event? For example, consider an application that handles requests to purchase items. The price of an item may be produced by a different application and could be missing at the time that the request is received.
Adding a retry topic provides the ability to process most events right away while delaying the processing of other events until the required conditions are met. In the example, you would route events to the retry topic if the price of the item is not available at the time. This recoverable condition should not be treated as an error but periodically retried until the conditions are met.
In your containerized environment you may dedicate one or two instances to handle the retry process, as few events are expected to follow this path.
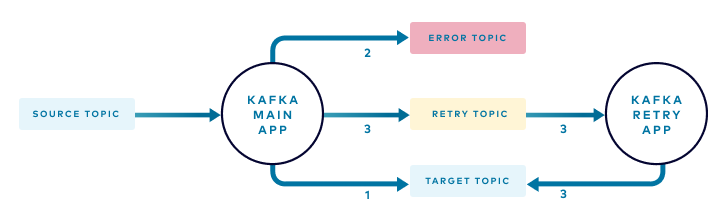
The following diagram illustrates how an event in the source topic can take one of three different paths:
- Under normal circumstances, the application processes each event in the source topic and publishes the result to the target topic
- Events that cannot be processed, for example, those that don’t have the expected format or are missing required attributes, are routed to the error topic
- Events for which dependent data is not available are routed to a retry topic where a retry instance of your application periodically attempts to process the events
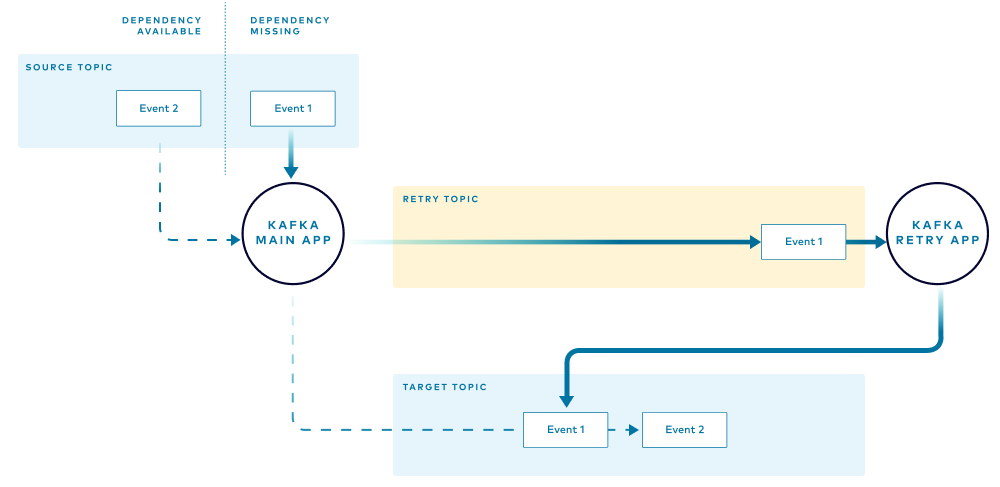
Related events may be processed out of order
There is a very important aspect to highlight with this pattern: Events are not guaranteed to be processed in the same sequence received in the source topic. This is because the retry path is “longer” and usually slower than the normal execution path, as there are fewer retry instances and retries are delayed.
The following diagram illustrates how the first event received (Event 1) reaches the target topic after an event that was received later (Event 2). You should use this pattern only if you are okay with this behavior.
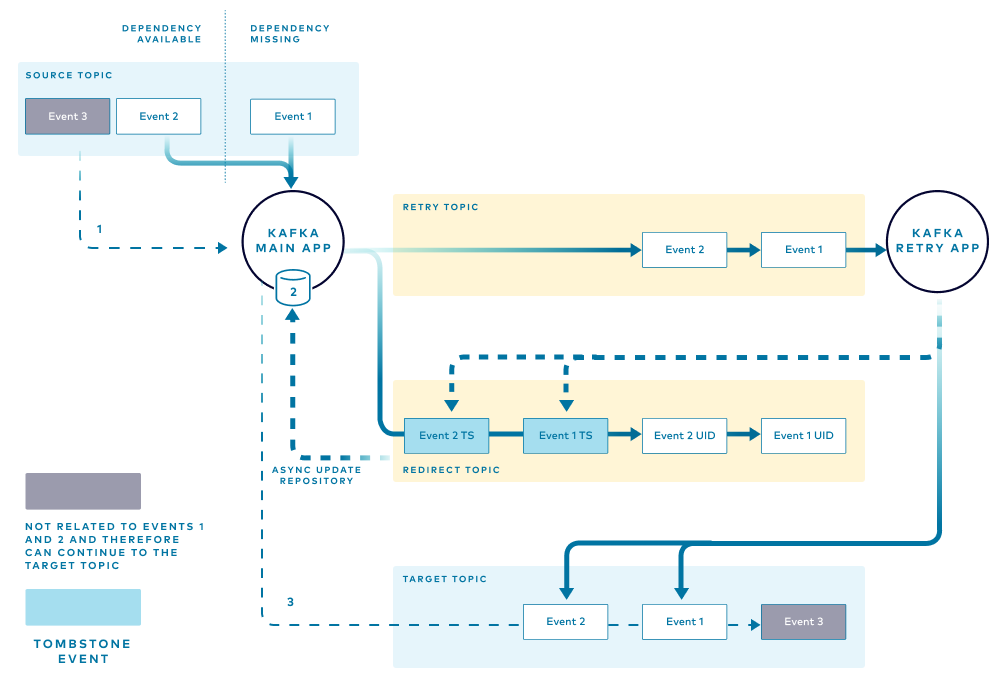
Pattern 4: Maintain order of redirected events
As shown in the previous pattern, adding a retry topic and associated flow provides a few benefits by delaying the execution of some events until the required conditions are met. However, the previous pattern also illustrated that the order at the target topic may change.
There are some conditions where changing the order of the events is not acceptable. For instance, an application that updates the inventory of an item would produce different results if an increase in the inventory is processed before a decrease or vice versa. If there is a trigger that initiates a “purchase request” when an item’s inventory falls below 10 and you currently have 10 units, processing a decrease of inventory before a previously received increase may trigger an unwanted “purchase request”, as the inventory may fall below a desired limit. This could also cause an error if the inventory goes below zero. This final pattern addresses that problem.
In this pattern, the main application needs to keep track of every event routed to the retry topic. When a dependent condition is not met (for instance, the price of an item) the main application stores a unique identifier for the event in a local in-memory structure. The unique event identifiers are grouped by the item that they belong to. This helps the application determine if events related to a particular item, for example, Item A, are currently being retried and therefore subsequent events related to Item A should be sent to the retry path to preserve order.
When the first event that has missing dependencies is received, the main application performs the following tasks:
- Notes the unique ID for the message (grouped by the item that they belong to), adding it to a local in-memory store.
- Routes the event to the retry topic, adding a header with the unique ID of the message. Adding the message ID as a header prevents alteration of the original message, and as explained below, enables the retry application to publish the appropriate tombstone event when the retry is complete.
- Publishes the unique ID of the received message to the redirect topic.
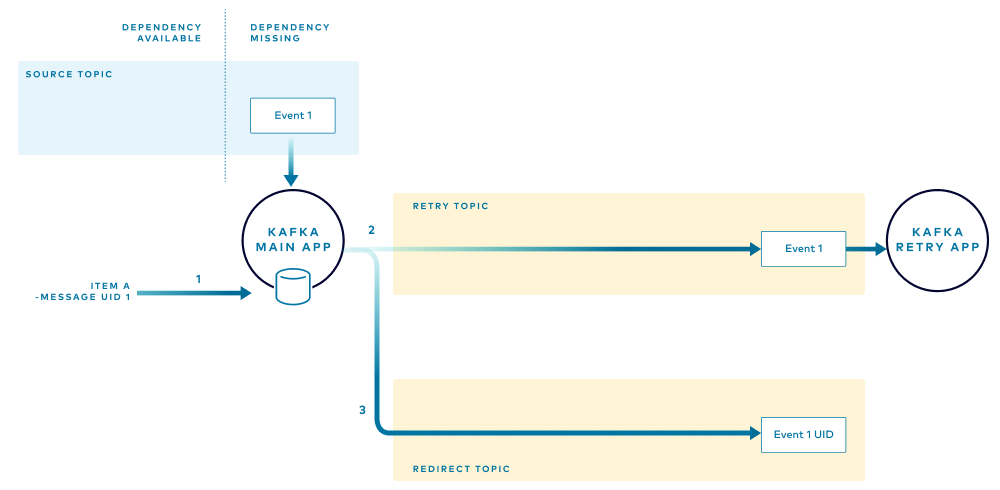
When the next event is received, the application checks the local store to determine if there are events for that item. If one or more events for the item are found, the application knows that some events are being retried and will route the new event to the retry flow.
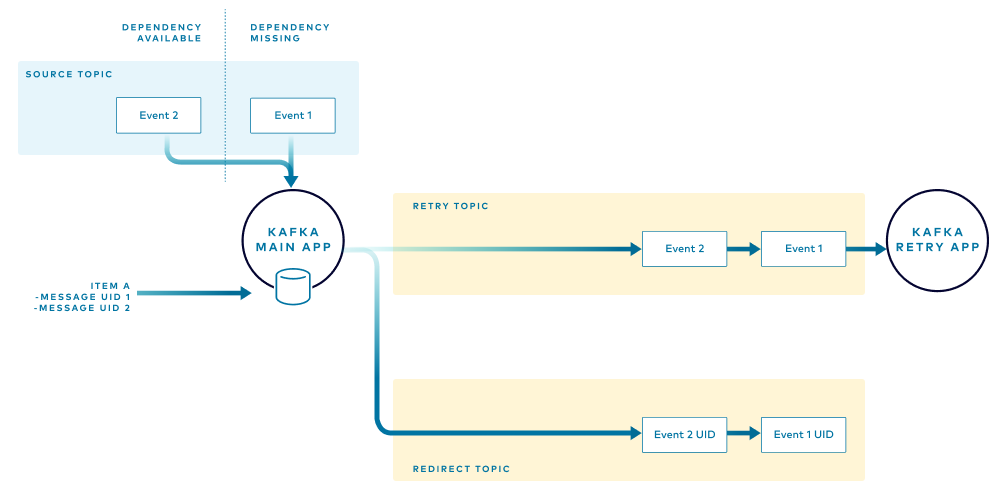
In the example, if the application receives an event for Item A, which currently has events that are being retried, the application will not attempt to process the event but will instead route it through the retry flow. This ensures that all the events for Item A are processed in the same order that they were received. The application adds the unique identifier for that new event to the local store and routes to the retry and redirect topics as before.
The retry application handles the events in the retry topic in the order that they are received. When an event is successfully retried and published to the target topic, the retry application instance sends confirmation in the form of a tombstone event to the redirect topic. One tombstone event is published for each successfully retried event.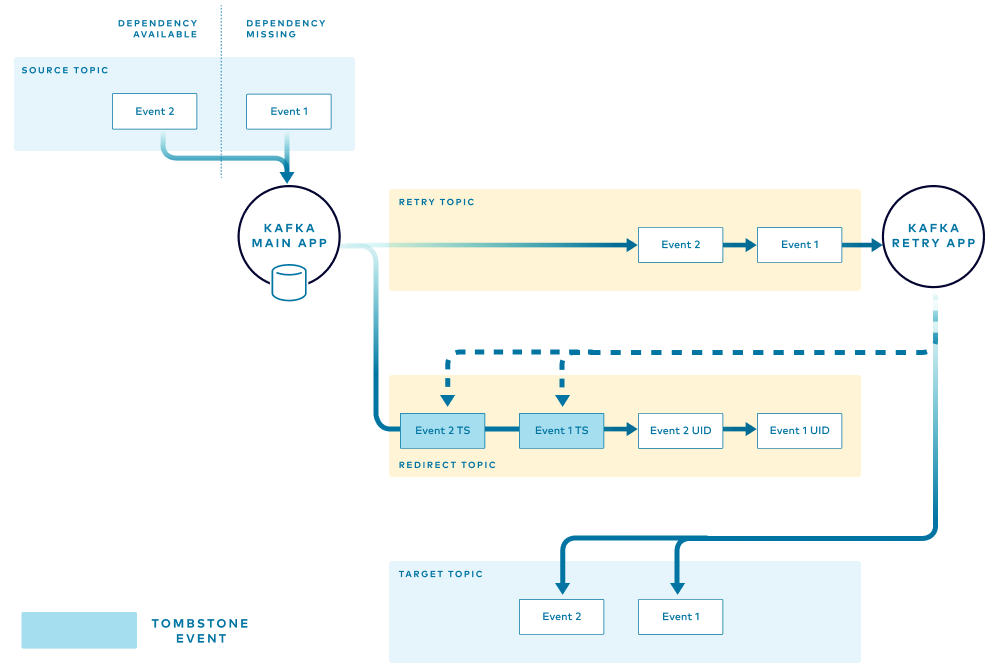
The main application listens to the redirect topic for tombstone events that signal successful retry. The application removes the messages from the in-memory store. This also allows for subsequent events for the same item to be processed through the main flow.
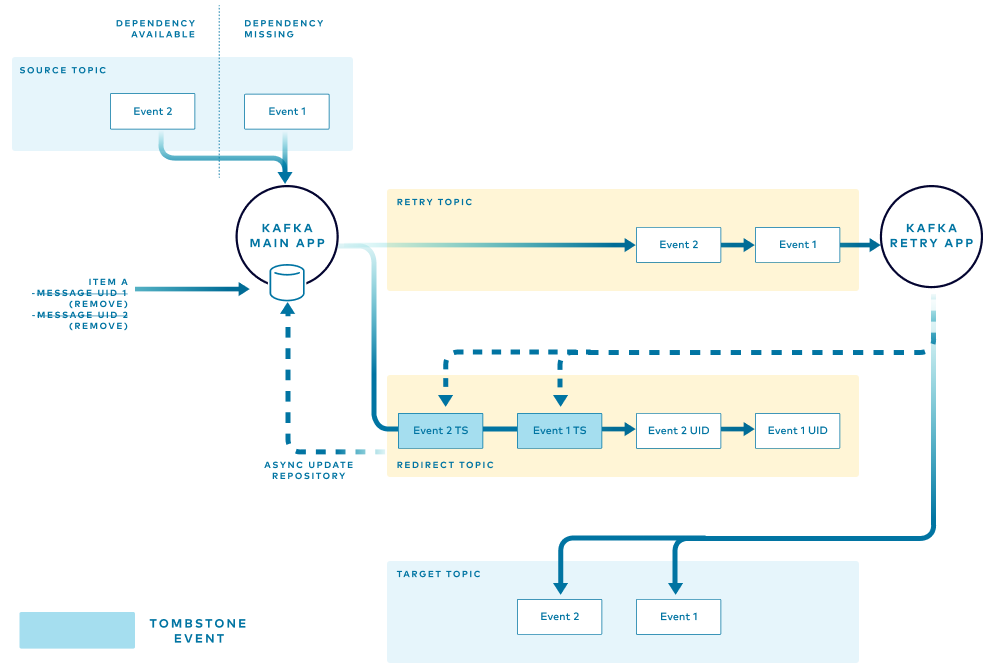
The final diagram illustrates the path taken by an event for an item that has all the required dependencies and can follow the normal flow. The main application performs the following tasks:
- Reads the event from the source topic
- Checks the local store to verify that no entries exist in the retry path
- Processes the event and publishes to the target topic
Recovery
In the case of failure, the in-memory store that the main application was managing will be gone. However, this can easily be restored by reading the events in the redirect topic and initializing that in-memory store.
Conclusion
Error handling and retries are important aspects of the development of all types of applications, and Kafka applications are no exception. The approaches mentioned are not intended to cover all possible aspects but provide guidance that can be adapted to meet your needs.
If you’d like to learn more, check out Confluent Developer to find the largest collection of resources for getting started, including end-to-end Kafka tutorials, videos, demos, meetups, podcasts, and more.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





