New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Dawn of Kafka DevOps: Managing and Evolving Schemas with Confluent Control Center
As we announced in Introducing Confluent Platform 5.2, the latest release introduces many new features that enable you to build contextual event-driven applications. In particular, the management and monitoring capabilities that we added to Confluent Control Center have evolved it into an indispensable tool for anyone working with Apache Kafka®. With the Developer License, all of the Confluent Platform features are free of charge for an indefinite duration in a non-production environment with a single broker.
In this three-part blog series, we’ll walk you through some of those new capabilities in Control Center:
- Part 1: Managing and Evolving Schemas with Confluent Control Center
- Part 2: Managing Kafka Configurations at Scale with Confluent Control Center
- Part 3: Managing Multi-Cluster Kafka Connect and KSQL with Confluent Control Center
Let’s dive into the first part: how Control Center integrates with Confluent Schema Registry allows you to manage and evolve schemas. It is useful to think about schemas as APIs, in the sense that applications depend on APIs and expect any changes made to APIs are still compatible and applications can still run.
Similarly, event streaming applications depend on schemas and expect that any changes made to schemas are still compatible and able to run. Schema evolution requires compatibility checks to ensure that producers can write data and consumers can read that data, even as schemas evolve. This is where Confluent Schema Registry helps: It provides centralized schema management and ensures schemas can evolve while maintaining compatibility.
With the enhanced integration with Confluent Schema Registry, you can do any of the following through the UI:
- View schemas for any topic
- Edit schemas as your data evolves
- Check the compatibility of new schemas against previous ones
- Set your schema compatibility policy
One benefit of Confluent Schema Registry is centralized schema management, which enables client applications to register and retrieve globally unique schema IDs. Let’s say you have a Java producer writing Avro data with the following schema file defined in its package:
{
"namespace": "io.confluent.examples.clients.basicavro",
"type": "record",
"name": "Payment",
"fields": [
{"name": "id", "type": "string"},
{"name": "amount", "type": "double"}
]
}
Supposing the client produces data to a topic called transactions, it will first register the above schema with Schema Registry. You can inspect the transactions topic data right from Control Center, which will automatically retrieve the schema and then deserialize the Avro:
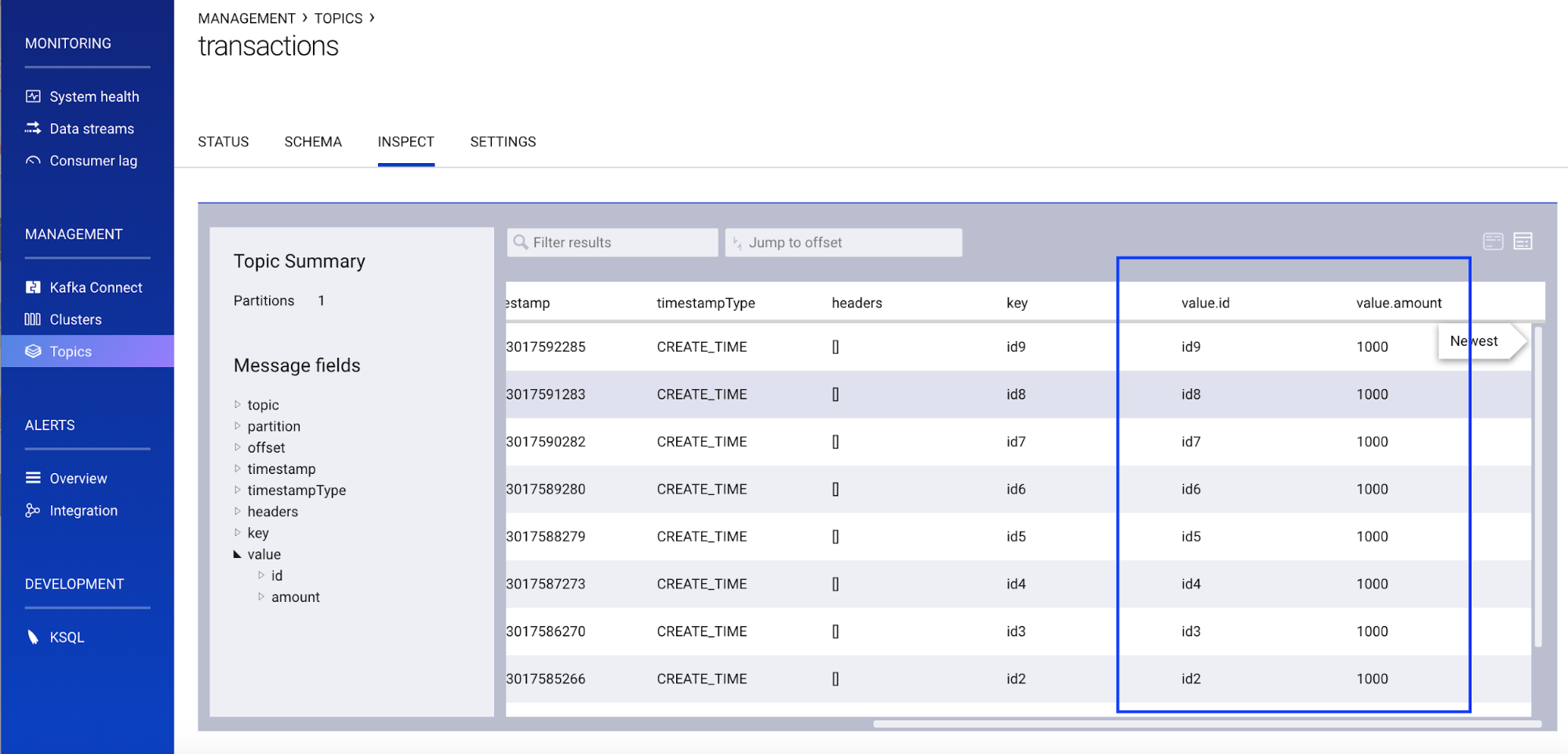
You can also view the schema itself, which is identical to the schema file defined by the client application.
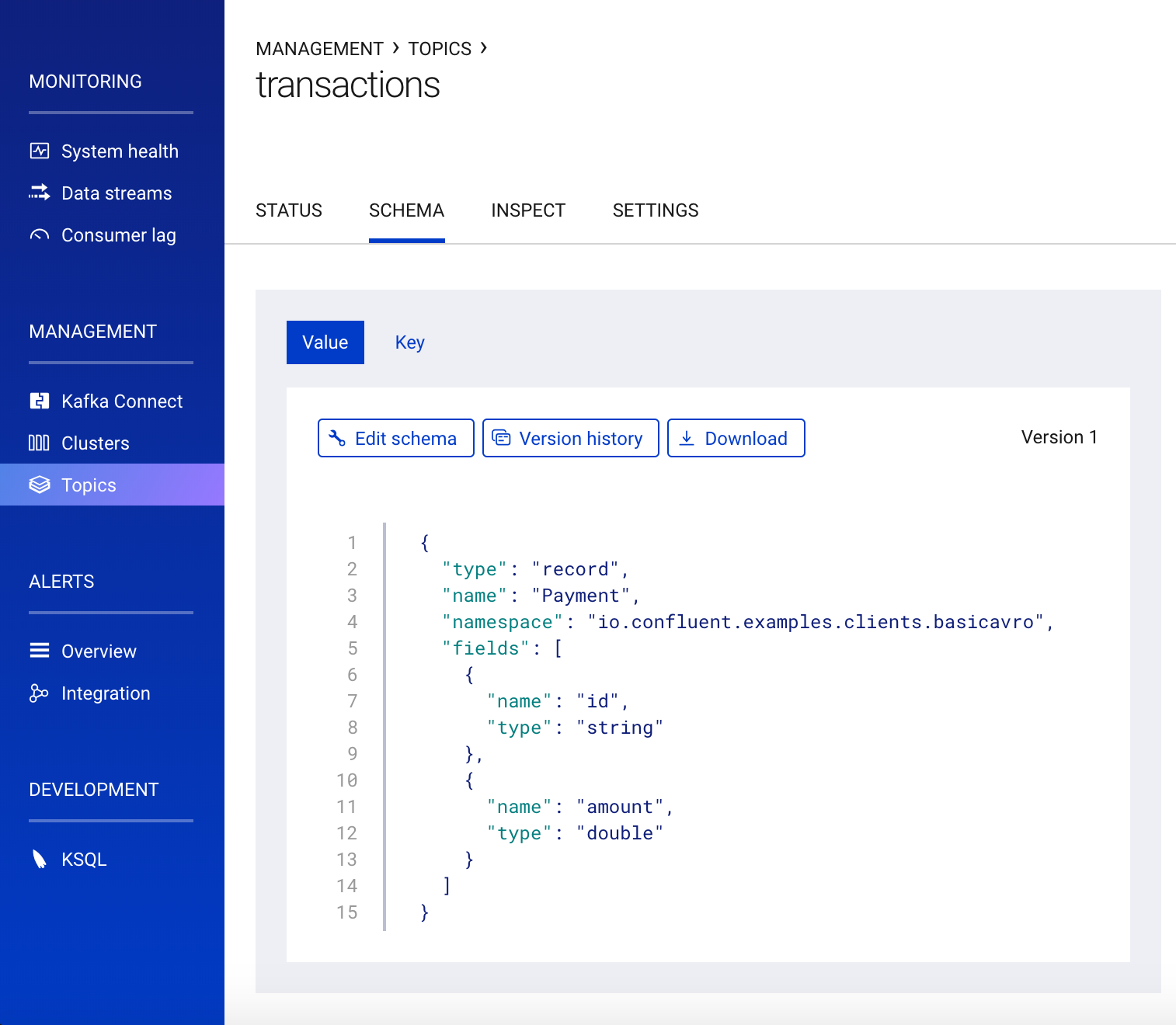
The main value of Schema Registry, however, is enabling schema evolution, a natural consequence of how applications and data develop over time. Similar to how APIs evolve and require compatibility with all applications that rely on both old and new versions of the API, schemas also evolve and likewise require compatibility with all applications that rely on old and new versions of a schema.
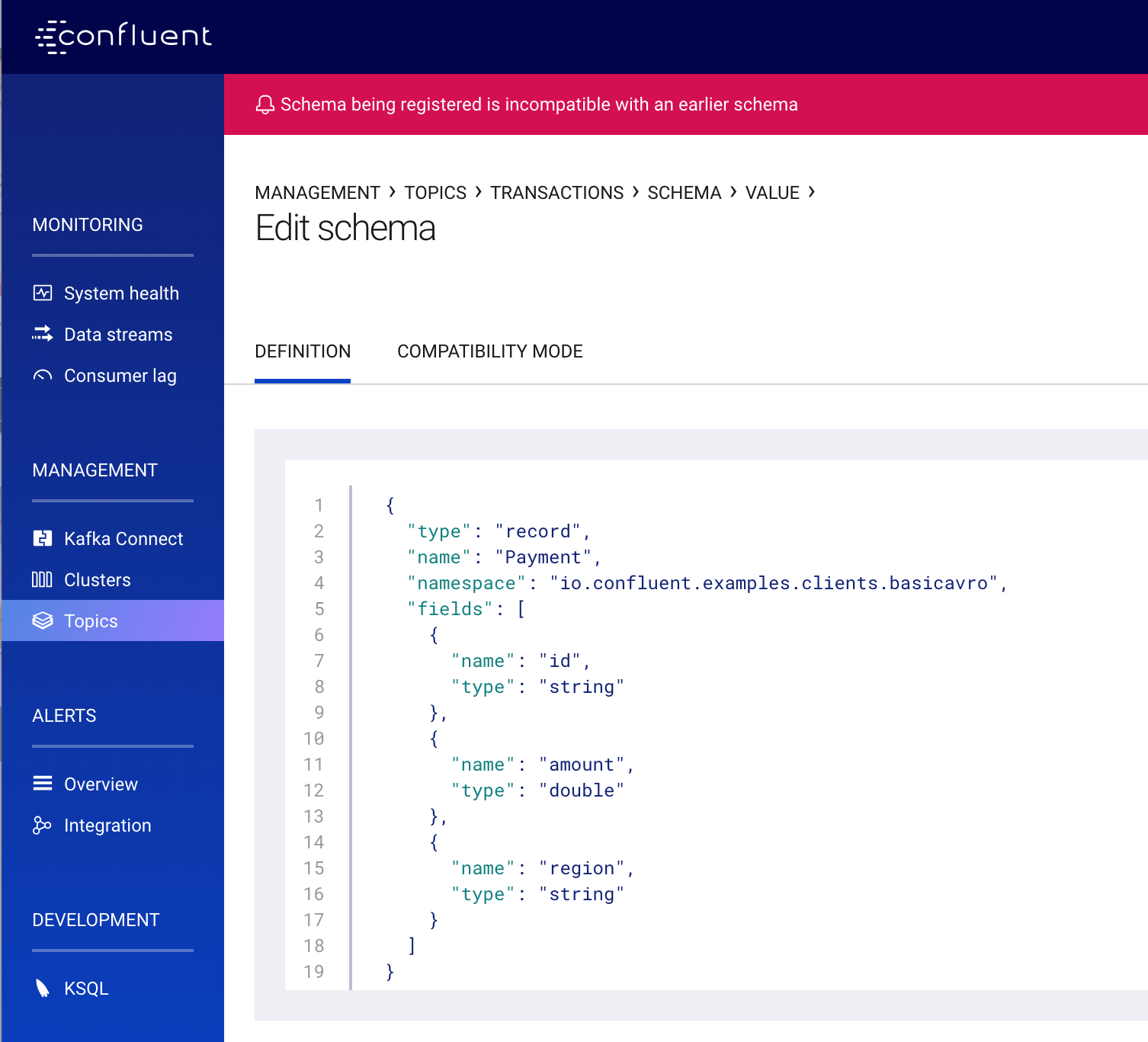
If you are going to edit a schema, you need to know that your changes are compatible with previous versions so applications don’t break. When you submit a new schema, Control Center will immediately check whether it obeys the compatibility policy. In the example output below, Control Center rejects the new schema because a new field was added with no default value, making it backwards incompatible.
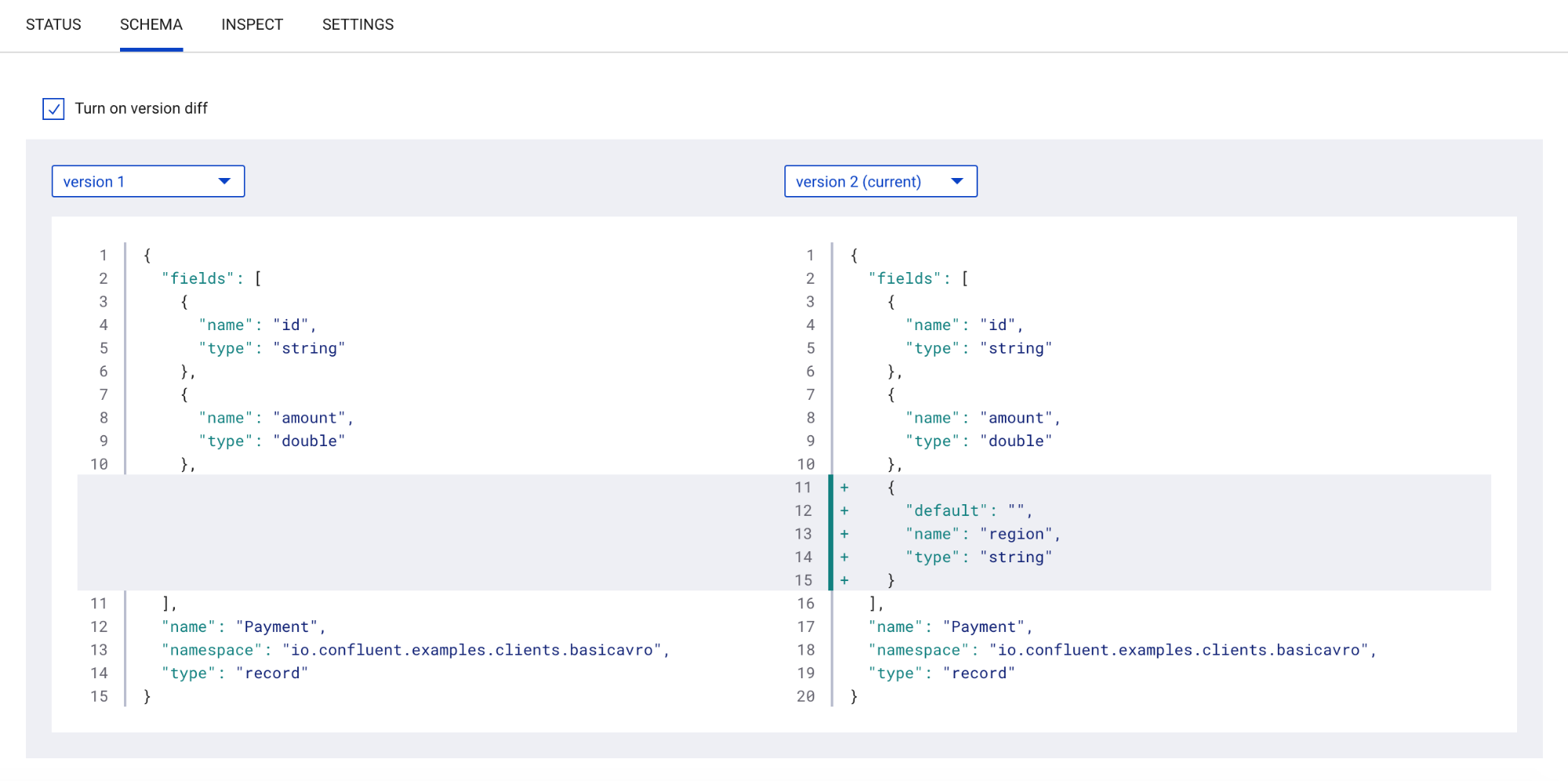
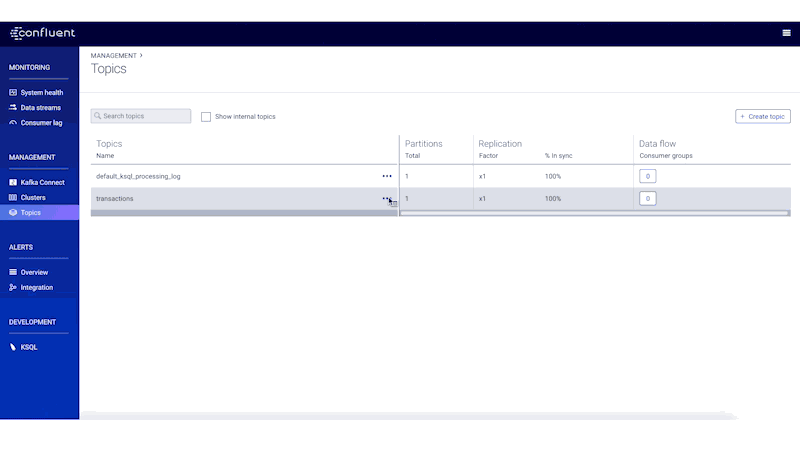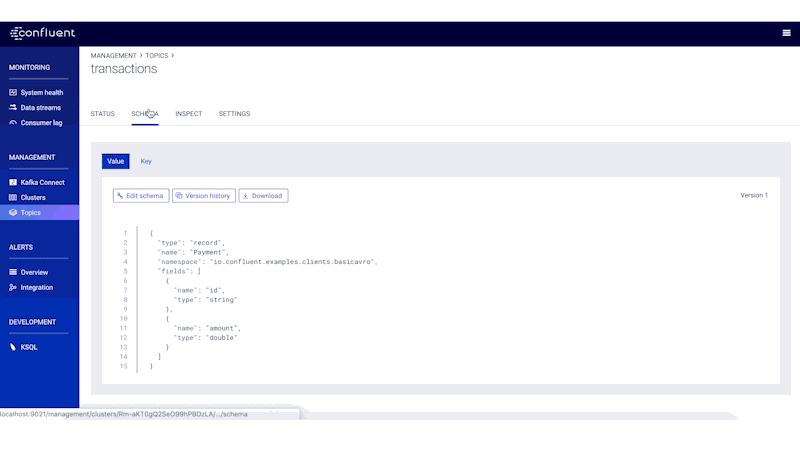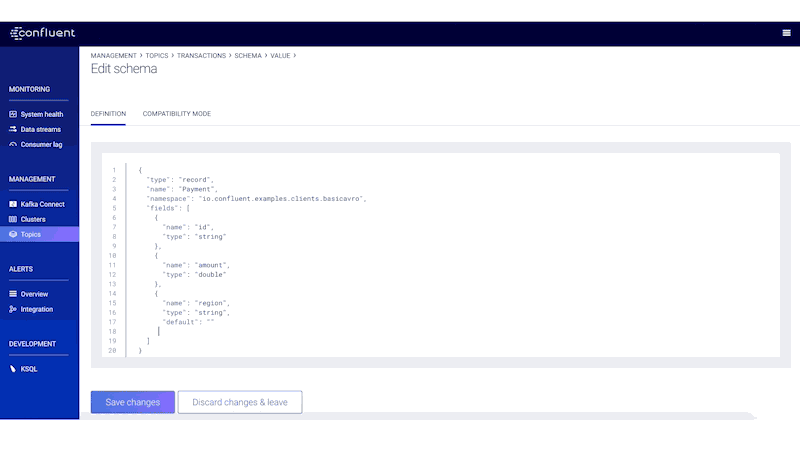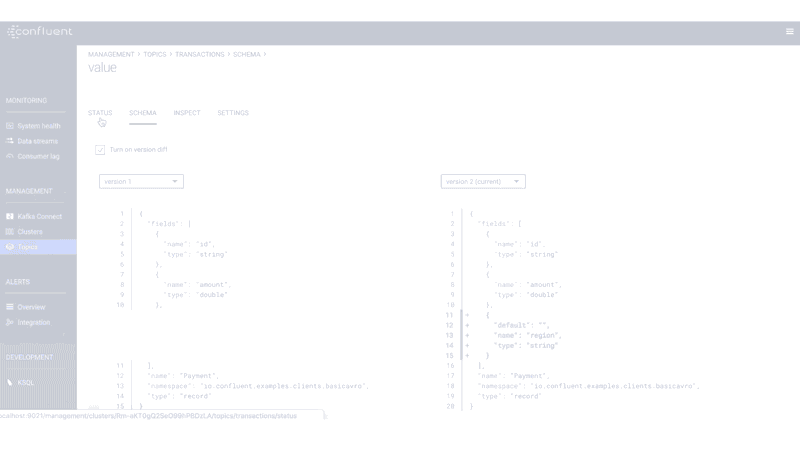
If you have evolved your schema through different versions, you can do a comparison to see the difference between those versions. This is useful for quickly discerning how schemas have changed and seeing which fields have been added or deleted.
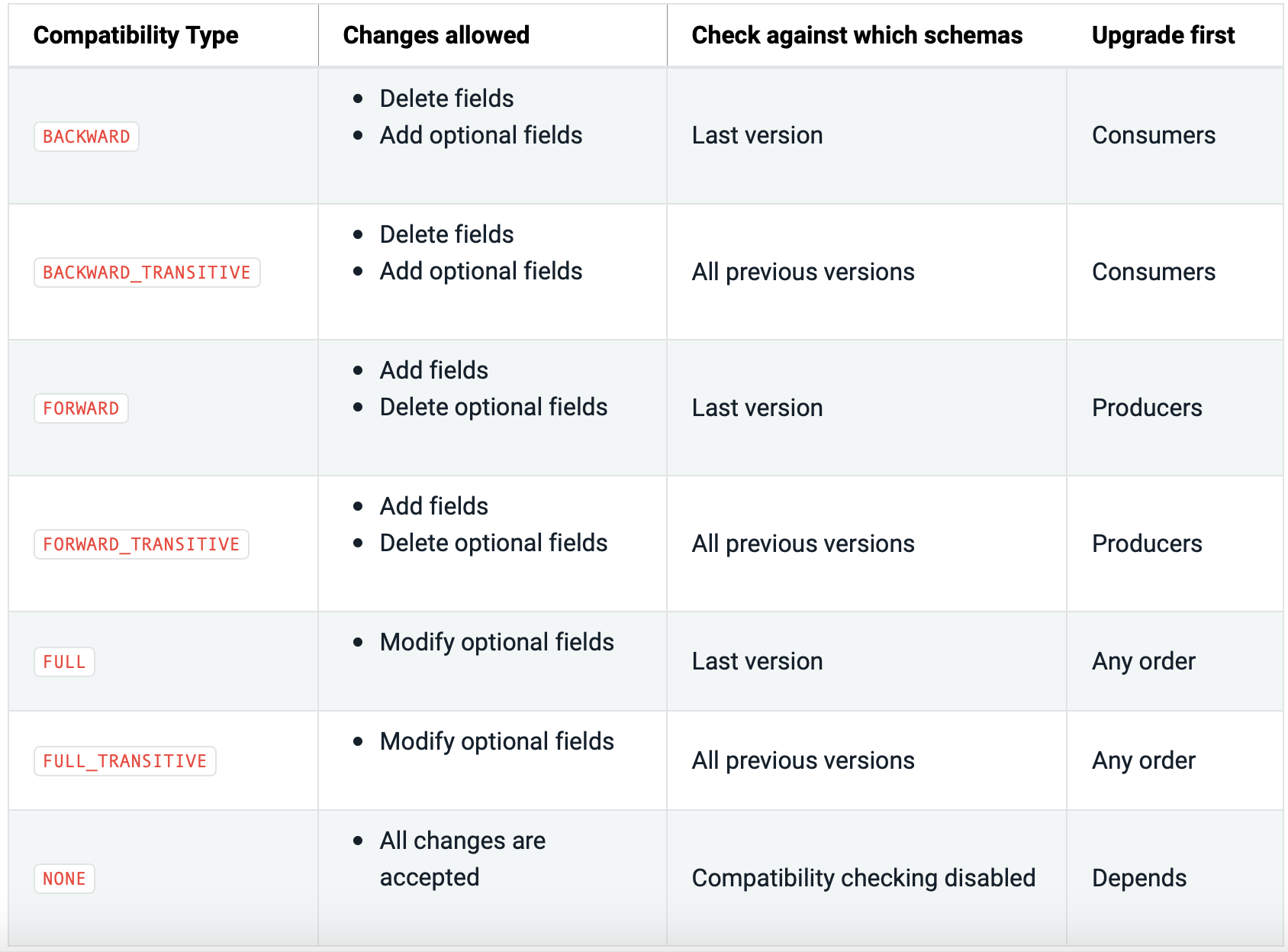
Finally, you may want to change the compatibility policy to alter the rules by which schemas are allowed to evolve. The default compatibility policy is backwards, which means that consumers using the new schema can read data produced with the previous schema. The table below shows several other compatibility options, which the Schema Evolution and Compatibility documentation describes in more detail.
Next steps
For a step-by-step guide on using Control Center’s integration with Confluent Schema Registry, follow the full Confluent Schema Registry Tutorial that has been updated to include the new 5.2 features.
Download Confluent Platform version 5.2 and follow the Confluent Schema Registry Tutorial to see how to use Schema Registry features from Confluent Control Center!
Other articles in this series
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.