New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Confluent Hack Day 2020: Hack from Home
At Confluent, every now and then we like to take a day away from our normal sprint tasks to hack. There are a ton of benefits to hack days, including:
- Collaboration across teams who don’t normally work together, which enables ideas and creations that typically don’t come about without the right mix of engineers, designers, writers, field specialists, and more
- Bottom-up inspiration that allows people on the front lines to build for identified needs
- Risk-taking on ideas that aren’t budgeted into a sprint but could be useful or spark a new initiative
- Team building across geos, which is a priority at Confluent
On our most recent hack day, the projects ranged from practical to eccentric. Let’s take a look at some of the highlights.
Loopio’s Rosetta Stone
With many customers around the world and nearly 20 global offices, our solutions engineers often need to answer inquiries and questions in multiple languages (human languages, not coding languages).
Confluent uses Loopio as a knowledge base for tracking technical questions about our product. It works great as long as you query in English and expect the results to be in English. Since questions and queries are submitted in various languages from around the globe, enabling users to query/read in local languages is a big win. To that end, Confluent solutions engineers Brice Leporini, Sergio Duran, Ramón Marquez, and Remi Forest stood up a system that can continuously pipe Loopio’s corpus through Confluent Cloud, apply accurate translations, and use the Elasticsearch connector to store the translated corpus in Elastic Cloud. Then, they wired up a UI to translate queries and return the results in the desired language.
Cryptographic Stream Integrity Verification
As users move to the cloud, there is an increasing need for clients to validate and verify that their data is handled without intentional or unintentional modification. When a client produces a message into an Apache Kafka® cluster, they may want proof that it is identical to the message they produced onto the cluster. This led Confluent security engineers Nitesh Mor and Mathew Crocker to ask, “Can we build a Kafka client that will let consumers cryptographically prove the integrity of our streamed data as generated by a producer?”
To solve the problem, they built a modified Python producer that creates cryptographic hashes and digital signatures and stores them in message headers. Hash chains are heavily used by a number of cryptographic systems, such as blockchains. When a producer writes a record, it includes cryptographic hashes for each message and one signature per message set. This additional information is stored in the message headers. On the other end, the consumer uses these hashes and signatures to validate that the records it is consuming arrive untampered, exactly as the producer sent them. When the team produces unexpected messages or uses a modified Kafka broker that tampers with the records in the topic, the consumer throws a VerificationError.
Kafka Client Serializer and Deserializer Using Zstandard Compression with Shared Dictionaries
Compression works best when redundancies can be eliminated over and over again. Kafka producers can be configured to linger and accumulate a larger batch of data before compressing and sending it. This gives more opportunity for compression within each batch but at the cost of increased latency. Even linger-batching may not provide gains when you have a large fleet of producers, each producing small batches.
Kafka has built-in support for several compression codecs, including Zstandard, but it does not take advantage of Zstandard’s major feature: shared dictionaries. For data streams composed of mostly similar data, it is wasteful to have Zstandard continuously rediscover and encode redundant information for every single batch.
Confluent software engineer Chris Johnson found a way to automatically generate, save, and reuse Zstandard’s shared dictionaries in a serializer/deserializer library by backing the shared dictionaries to durable storage on a Kafka topic, resulting in better compression ratios while using less CPU. A test run using typical audit log events delivered a 2x improvement over the built-in gzip codec.
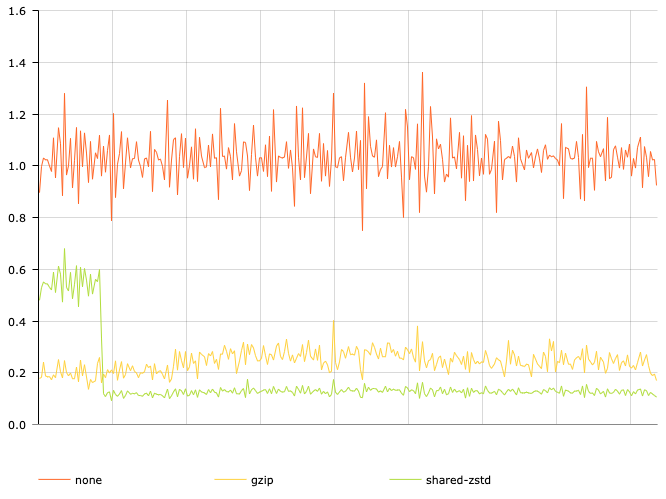 Comparison of no compression, gzip compression, and shared Zstandard compression size as a function of time
Comparison of no compression, gzip compression, and shared Zstandard compression size as a function of time
Project Roomba
At Confluent, some of our teammates were tired of seeing (and paying for) cloud resources that were no longer in use. While there are numerous valid use cases for long-running clusters in pre-prod environments (soak testing, performance testing, etc.), the current method for tracking which clusters could be decommissioned was manual, inefficient to run, and infrequently run.
Project Roomba was a hack to automate the cleanup of our unused clusters. Software engineers Harini Rajendran, Joshua Buss, Krishnan Chandra, and Vivek Sharma built a reaper job in our mothership control plane orchestration to find old, unused resources, and delete them. Their strategy included multiple parts:
- Long-running clusters are now registered and tracked by developers using Git, which enables review and provides a central source of truth. Upon merge, continuous integration (CI) inserts the new clusters into a database.
- The list of unexpired, long-running clusters are exposed via an HTTPS endpoint.
- Reaper service that uses the API to reap expired clusters.
- Output logs of reaped clusters are saved to a wiki for consistency with previous reports, which provides visibility into the reaper’s activities.
- Activity data of the reaper is programmatically integrated into the Cost Engineering Team’s data pipelines.
The project was successful and is now running in pre-prod environments!
Conflack: Persisting Slack Data to Confluence
Slack does not retain messages forever, and it’s hard to search. But a lot of us at Confluent would like to save useful threads for future reference. That’s why quality engineers Scott Hendricks and Srini Dandu and software engineer Atharva Pendse built Conflack, a tool that’s part Slack bot and part Confluence wiki.
Do you want to save a thread? Simply react to the thread with the Conflack emoji, and the whole thread is instantly saved to the team’s Confluence page. The thread can then be edited and reformatted at the user’s convenience.
One of the main constraints around this problem is delivering a service with low operational overhead, and cheap to run. The usage pattern would be lower volume of hits, and perhaps a lot of idle time throughout the night. Given these constraints, the team chose to implement their backends using a serverless architecture powered by Google Functions. They integrated the Slack API to trigger a Google Function call, which could then write to Confluence using the Atlassian API.
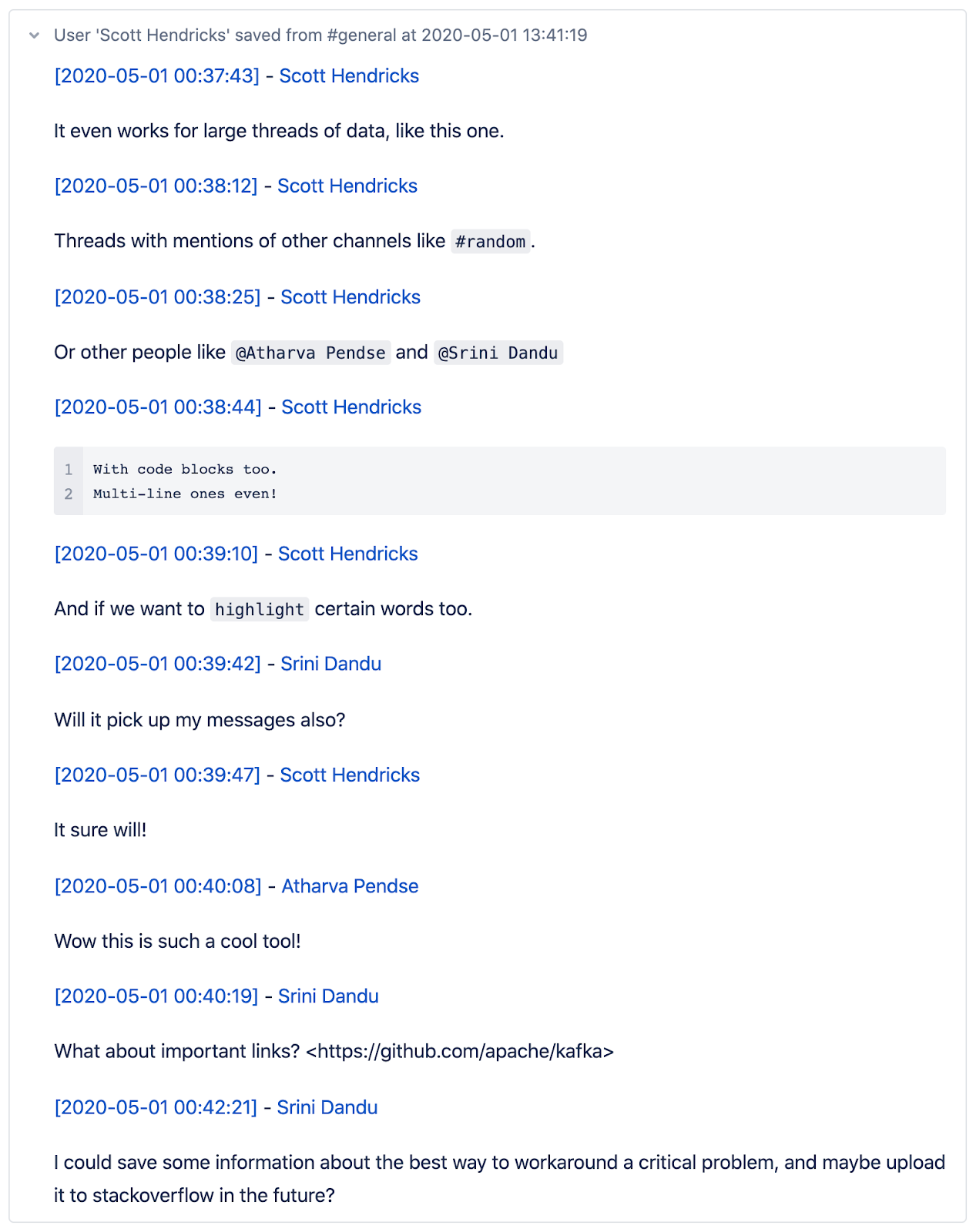 Sample output of our Slack
Sample output of our Slack
Conclusion
At Confluent, we’re building the world’s leading event streaming platform. Sometimes, that means taking some time to explore our technology and collaborate across team functions. Our hack days come to life when the enthusiasm for our products comes pouring out of our normal sprint work—they’re a purely bottom-up initiative around what we can discover and build when we collaborate across our normal team boundaries. If this sounds like the kind of place where you’d want to work and solve problems, check out our Careers page!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Confluent Champion: Building a Secure Foundation for Accelerating Product Launches
Meet Akshay Ben, Senior Software Engineer II at Confluent, and learn how IAM, RBAC, and platform security enable faster, scalable product launches.



Starting With Purpose: In-Person Onboarding in a Remote-First World
How Confluent blends remote-first flexibility with in-person onboarding to build connection, purpose, and long-term employee success from day one.