New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Enabling the Deployment of Event-Driven Architectures Everywhere Using Microsoft Azure and Confluent Cloud
Hybrid cloud architecture and accelerated cloud migrations are becoming the norm rather than the exception, as our increasingly digital world introduces certain challenges along the way, including modernizing existing application/architecture, scalability, data governance/security, and real-time event streaming across several environments. Data migration is a complex process, and finding a long-term cloud strategy and governing the migration process in real time is now more important than ever.
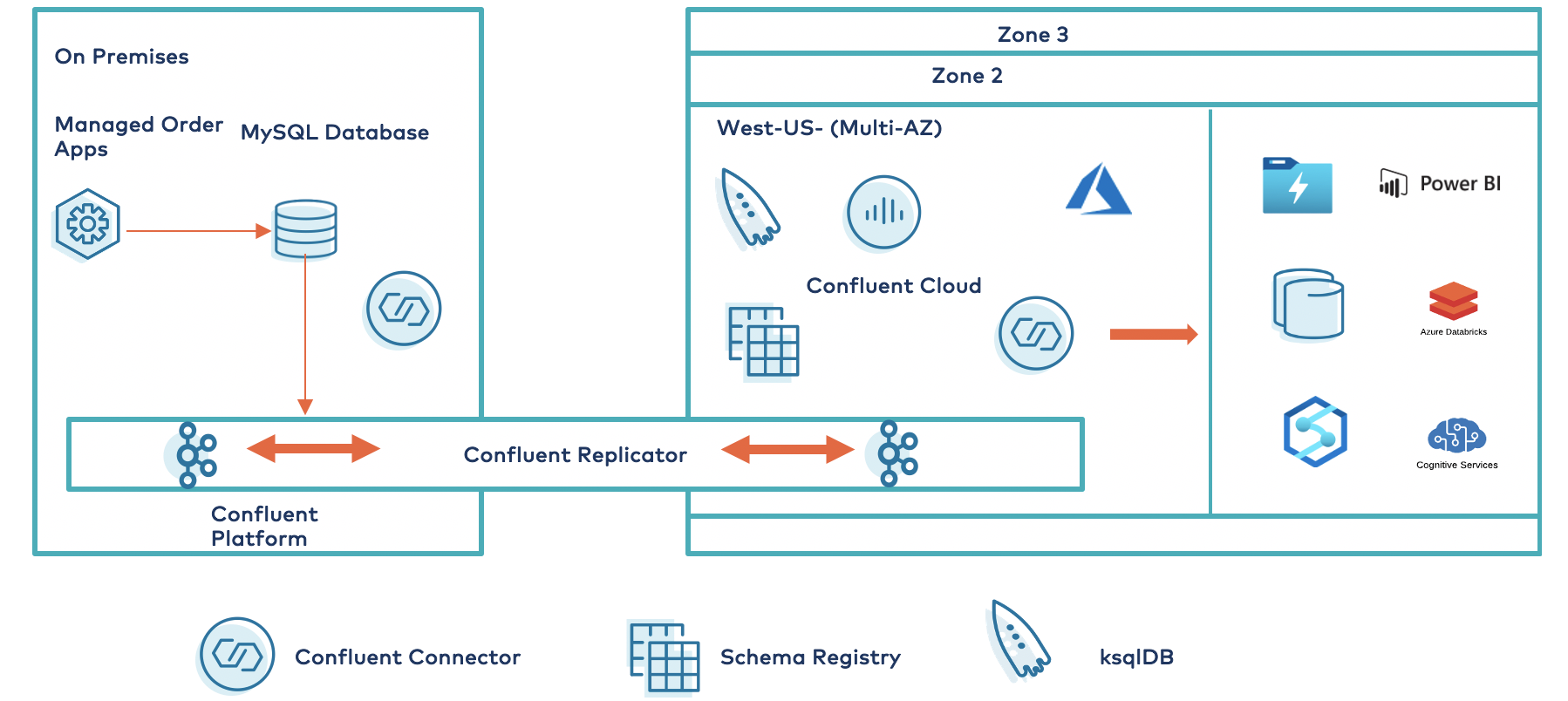
This blog post demonstrates how to build a persistent bridge from on premises or other clouds to Microsoft Azure using Confluent Replicator. It also illustrates how to leverage Confluent’s prebuilt connectors to easily integrate with Azure services, such as Azure Data Lake Storage (ADLS) and Power BI. This allows you to rapidly scale your digital footprint across on-prem data centers and cloud providers so that your organization can be digital first and meet customers where they are.
Building a Bridge to Azure
To deploy and run applications anywhere, you can use Confluent Cloud, a cloud-native, fully managed offering; Confluent Platform, a self-managed option; or a combination of both.
You may find yourself in a scenario where, due to business or regulatory constraints, there is a need to deploy Confluent Platform on premises and outside of Azure. However, some of the data in the on-premises clusters might need to be used by applications in the cloud and therefore needs to be streamed in real time to Confluent Cloud in Azure. Confluent Replicator enables real-time bidirectional replication from multiple sources, mainframes, relational/non-relational databases, message queues, and several Azure services so that you can run applications anywhere. You can stream the data from outside of Azure to the applications and services in Azure that need it. Confluent Cloud seamlessly connects to many Azure native services, such as ADLS, Azure SQL Database, and serverless compute with Azure Functions.
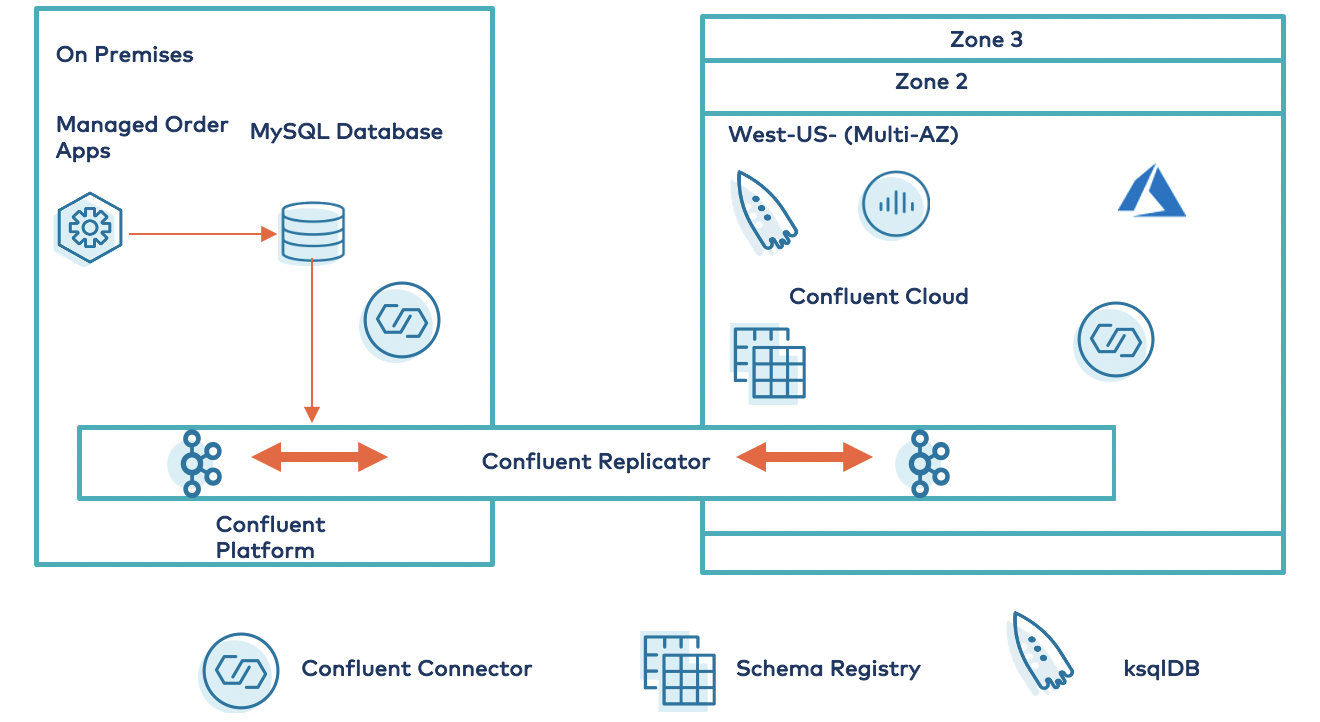
Bridge to Azure use cases
You can use the Bridge to Azure architecture for data replication and migration use cases. Examples include recovery solutions, hybrid cloud architectures, multi-cloud replication, and event aggregation across multiple data sources. For example, customers can use the Azure East U.S. region for running production applications and replicate to the West Europe region for disaster recovery to meet high-availability standards. Similarly, you can choose to replicate the data from other clouds to Azure and develop a global, distributed application architecture.
Connectors to make data access easy
Confluent Cloud on Azure delivers a fault-tolerant, scalable, and secure architecture. Confluent supports 100+ connectors that work with many popular data sources and sinks across the Azure ecosystem and beyond. Confluent Cloud in Azure offers prebuilt, fully managed, Apache Kafka® connectors that can easily integrate available data sources, such as ADLS, Azure SQL Server, Azure Synapse, Azure Cognitive Search, and more.
The table below highlights the current array of Confluent- or partner-built and supported source and sink connectors that you can leverage to integrate your Kafka ecosystem with the Azure platform. For the most current list, please see the documentation.
| Description of Connector | Connector Type |
| ADLS Gen2 | Sink |
| Azure Blob storage | Source, Sink |
| Azure SQL Data Warehouse | Sink |
| Azure Cognitive Search | Sink |
| Azure Functions | Sink |
| Azure Service Bus | Source |
| Azure Event Hubs | Source |
| ADLS Gen1 | Source |
| Azure Data Explorer | Sink |
Deploy a real-time event streaming platform using Bridge to Azure
Using a MySQL relational database as a datastore is one real-world example of an order process application that is common within the retail industry. The Kafka Connect framework is used for capturing events in the database and streaming the data into Confluent Platform. Leveraging Confluent Replicator, these events are easily and reliably streamed from Confluent Platform to Confluent Cloud in real time. A fully managed Azure Data Lake sink connector is used to sink data from Confluent Cloud to Azure Data Lake for longer-term storage and use by other analytics tools.
The flow of this deployment has four phases:
- Set up order processing application and datastores
- Stream database changes to Confluent Platform
- Establish the Bridge to Azure architecture using Confluent Replicator
- Connect Confluent Cloud to Azure services
Overview of the order processing system and datastores
The order processing system is a set of microservices, and the primary data source for the system resides in an on-premises MySQL database. The database schema includes customer, supplier, product, sales order, and purchase order information. The schema is developed based on a simple sales scenario: Customer purchases the product from the company and a sales order is created. The company sends the purchase order details to the supplier so that product demand can be processed, and a balanced inventory can be maintained.
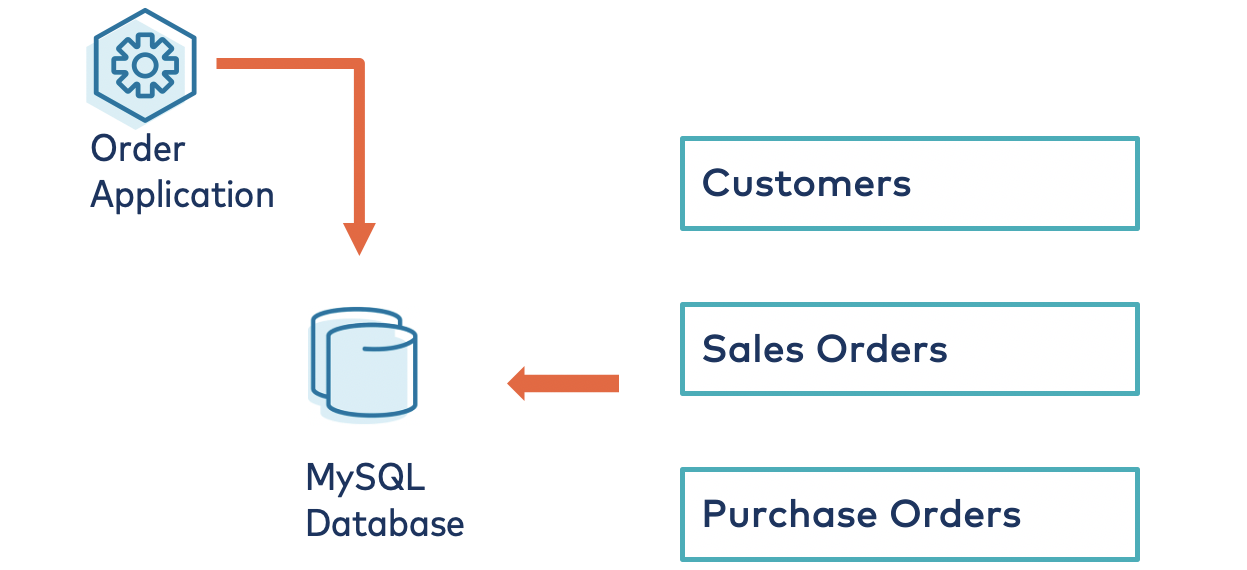
The database consists of multiple tables, including customers, products, purchase orders, and sales orders.
mysql> show tables; +--------------------------+ | Tables_in_orders | +--------------------------+ | customers | | dc01_out_of_stock_events | | products | | purchase_order_details | | purchase_orders | | sales_order_details | | sales_orders | | suppliers | +--------------------------+ 8 rows in set (0.00 sec)
For example, the purchase order table consists of 100 quantities from each product.
mysql> SELECT * FROM purchase_order_details; +----+-------------------+------------+----------+------+ | id | purchase_order_id | product_id | quantity | cost | +----+-------------------+------------+----------+------+ | 1 | 1 | 1 | 100 | 6.82 | | 2 | 1 | 2 | 100 | 7.52 | | 3 | 1 | 3 | 100 | 6.16 | | 4 | 1 | 4 | 100 | 8.07 | | 5 | 1 | 5 | 100 | 2.10 | | 6 | 1 | 6 | 100 | 7.45 | | 7 | 1 | 7 | 100 | 4.02 | | 8 | 1 | 8 | 100 | 0.64 | | 9 | 1 | 9 | 100 | 8.51 | | 10 | 1 | 10 | 100 | 3.61 | | 11 | 1 | 11 | 100 | 2.62 | | 12 | 1 | 12 | 100 | 2.60 | | 13 | 1 | 13 | 100 | 1.26 | | 14 | 1 | 14 | 100 | 4.08 | | 15 | 1 | 15 | 100 | 3.56 | | 16 | 1 | 16 | 100 | 7.13 | | 17 | 1 | 17 | 100 | 7.64 | | 18 | 1 | 18 | 100 | 5.94 | | 19 | 1 | 19 | 100 | 2.94 | | 20 | 1 | 20 | 100 | 1.91 | | 21 | 1 | 21 | 100 | 8.89 | | 22 | 1 | 22 | 100 | 7.62 | | 23 | 1 | 23 | 100 | 6.19 | | 24 | 1 | 24 | 100 | 2.83 | | 25 | 1 | 25 | 100 | 5.51 | | 26 | 1 | 26 | 100 | 4.23 | | 27 | 1 | 27 | 100 | 8.33 | | 28 | 1 | 28 | 100 | 7.09 | | 29 | 1 | 29 | 100 | 1.75 | | 30 | 1 | 30 | 100 | 1.72 | +----+-------------------+------------+----------+------+ 30 rows in set (0.00 sec)
Now, you can generate sales orders to simulate the product demand and confirm that the sales orders get created in the database. If you need the details of the implementation, please refer to this resource.
root@ganaworkshop-0:~# docker logs -f db-trans-simulator Sales Order 1 Created Sales Order 2 Created Sales Order 3 Created Sales Order 4 Created Sales Order 5 Created
Stream database changes to Confluent Platform
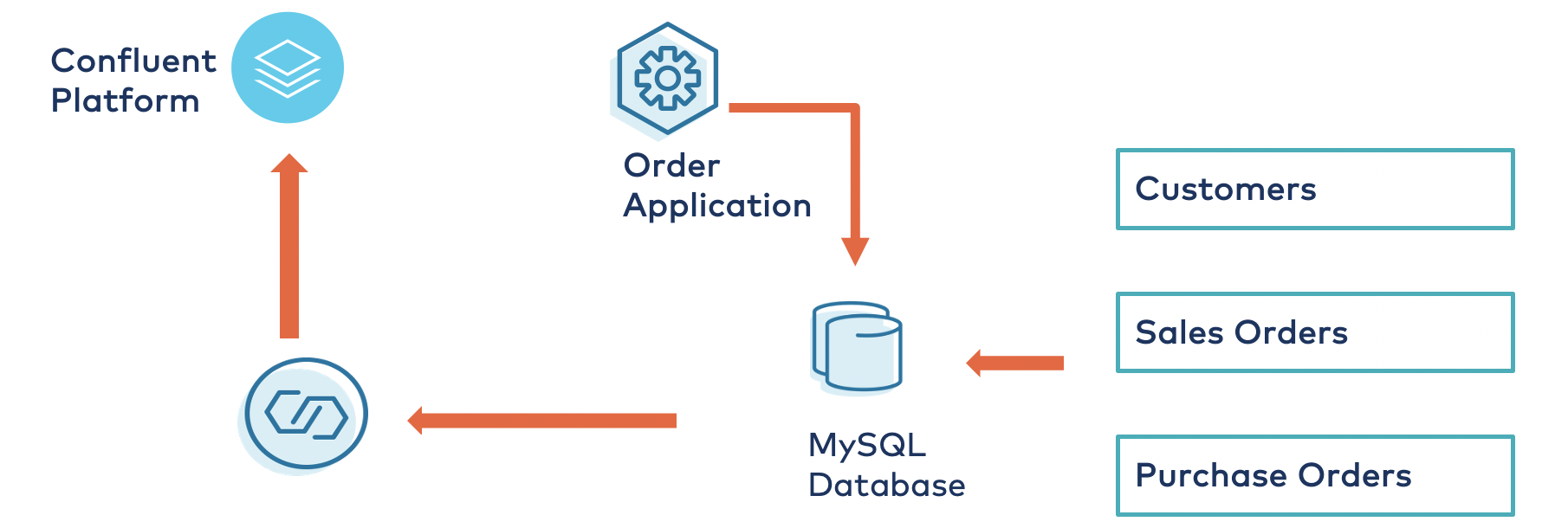
This part of the topology focuses on pushing change data capture (CDC) events out of the relational database into the on-premises Kafka cluster running on Confluent Platform. You can leverage the Kafka Connect framework to accomplish this objective. Connectors are high-level abstraction layers that handle the data flow in and out of the cluster by managing tasks.
For this scenario, leverage the Confluent-supported Debezium MySQL CDC Connector, which initially takes a snapshot of an existing database and then subsequently captures row-level changes from the tables each time there is a change event, such as an INSERT, UPDATE, or DELETE in the database tables. Use the table sales_orders_details and write the upcoming events or messages to topics in Confluent Platform. You can create a MySQL source connector using the cURL:
root@ganaworkshop-0:~# curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:18083/connectors/ \
-d ‘{
"name": "mysql-source-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
Continues..
….
HTTP/1.1 100 Continue
HTTP/1.1 201 Created
Date: Mon, 10 Aug 2020 06:40:08 GMT
Location: http://localhost:18083/connectors/mysql-source-connector
Content-Type: application/json
If you need further details on the implementation, please refer to this resource.
After successfully configuring the connector, the database changes are pushed to Confluent Platform through the MySQL database connector.
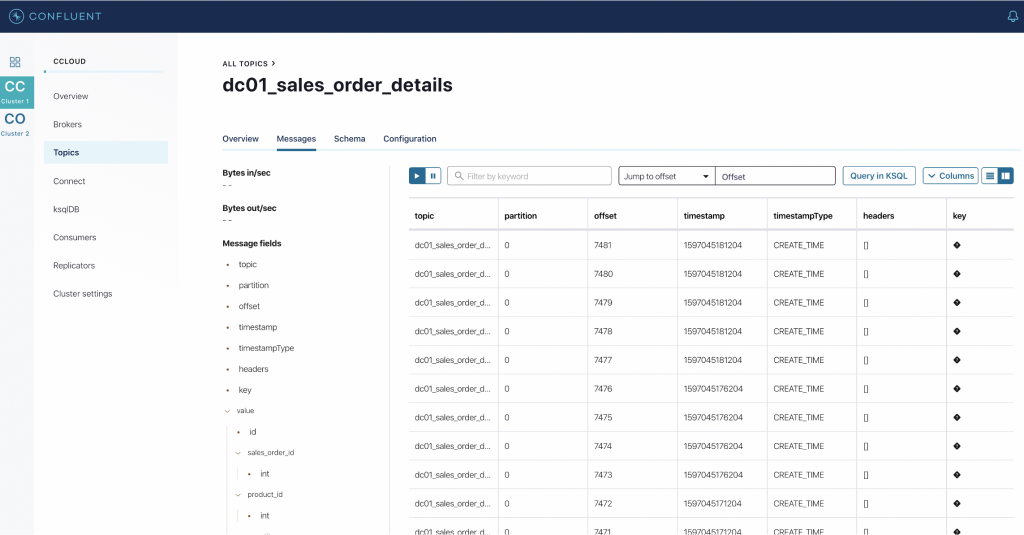
To confirm that the events are being ingested to Confluent Platform, use Confluent Control Center. Control Center is a web-based UI tool for centrally managing and monitoring Kafka clusters. On the landing page of Control Center, you can observe that there are two clusters that are operational. For simplicity, refer to the on-premises cluster as “CO” and the cluster hosted in Confluent Cloud as “CC,” and validate the streams of events from topic sales_order_details.
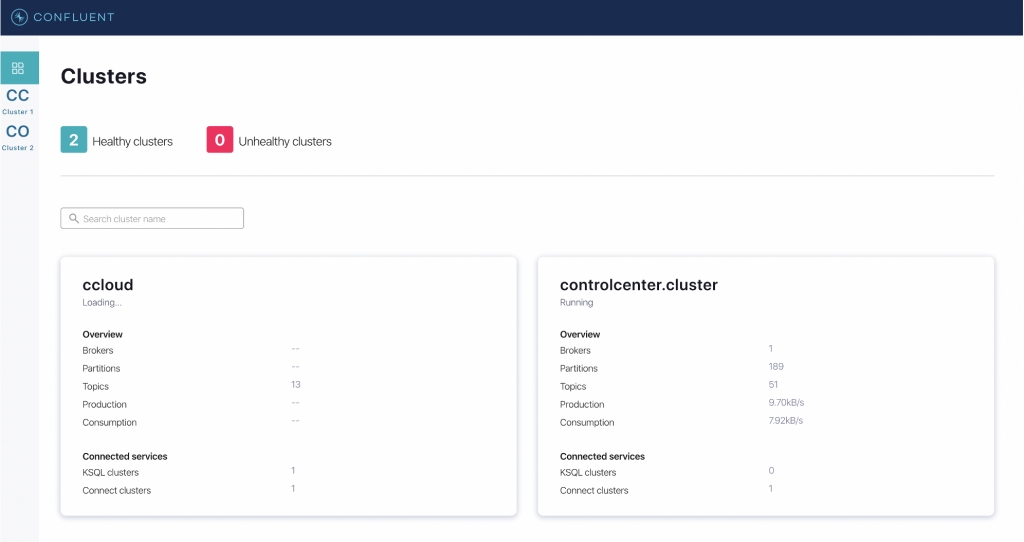
Now look at the sales_order_details topic from CO and confirm the flow of data or events from the ”Messages” tab.
Establish the Bridge to Azure architecture using Confluent Replicator
In the previous section, the data stream successfully arrived at the on-premises cluster (CO). The next stage in the topology is to stream the data from CO to Confluent Cloud. You need to set up Confluent Replicator to replicate the topic sales_order_details from Confluent Platform to Confluent Cloud. Confluent Replicator uses Kafka Connect, which is already configured for database changes (as described above), and you can use the same Connect framework for data replication. Confluent Replicator uses the source as Confluent Platform (CO) and Confluent Cloud (CC) as the destination. Now, you need to choose the topic sales_order_details for the data replication and set up Replicator using the cURL command:
root@ganaworkshop-0:~# curl -i -X POST -H "Accept:application/json" \
-H "Content-Type:application/json" http://localhost:18084/connectors/ \
-d ‘{
"name": "replicator-dc01-to-ccloud",
"config": {
……
Continues
HTTP/1.1 100 Continue
Date: Mon, 10 Aug 2020 07:37:01 GMT
Content-Type: application/json
Content-Length: 81
Server: Jetty(9.4.24.v20191120)
For the implementation details, please refer to this resource.
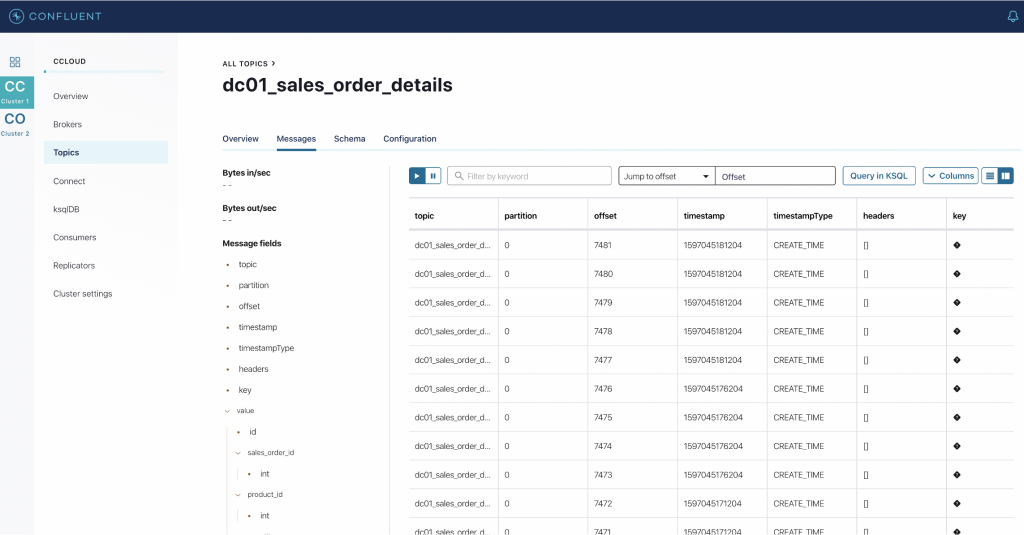
Using Confluent Control Center, we can verify that Confluent Cloud receives the data from the topics using Replicator, as depicted in the above image. Select cluster CC from the left navigation pane, click Topics, and choose the topic sales_order_details.
In the details of the sales_order_details topic, you can check the messages tab to confirm that the data is replicated from Confluent Platform.
You have now successfully set up the bridge to Azure and are replicating the data on premises to Confluent Cloud.
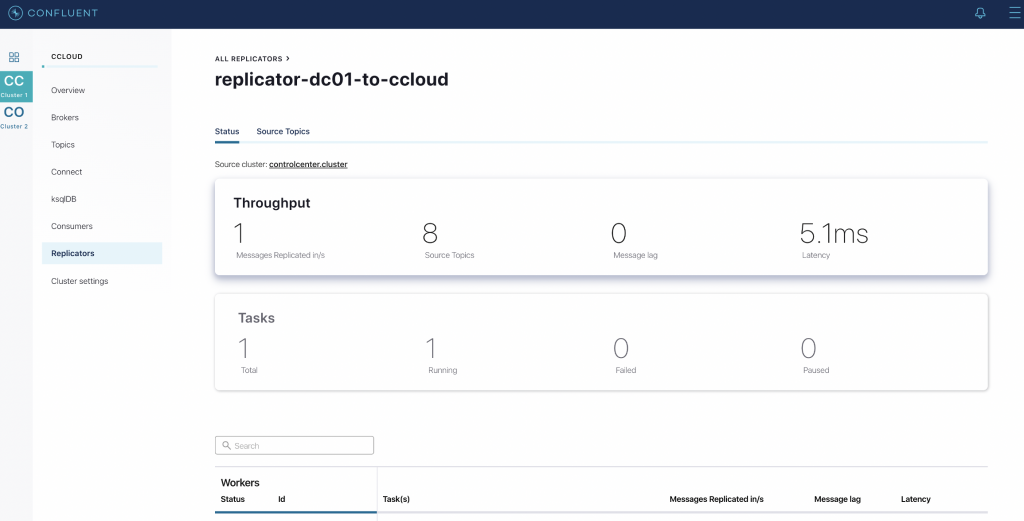
You can view the status of the Replicator connector in Confluent Control Center by selecting Replicators on the left-hand navigation pane, where throughput and latency statistics are also shown.
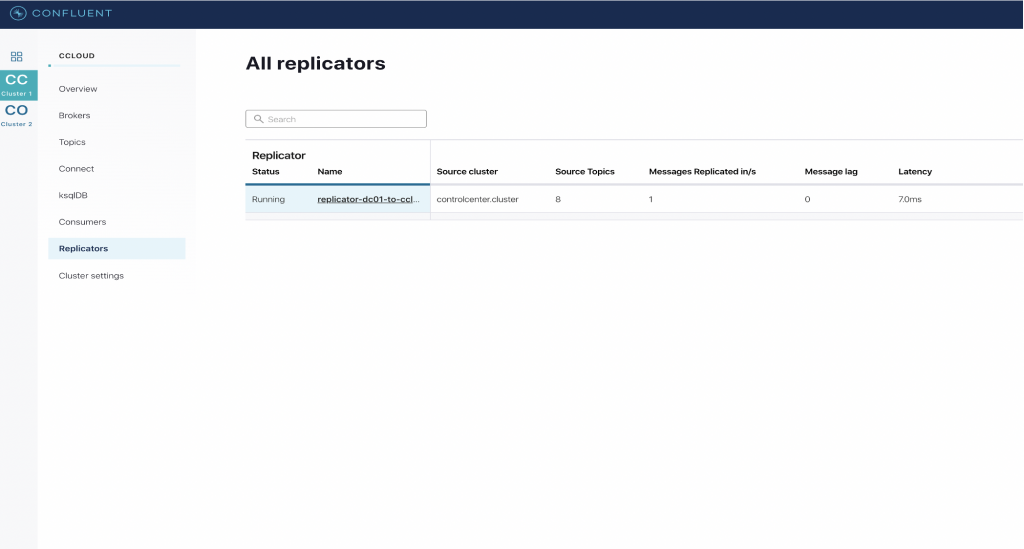
Replicator is in a running state and displays the number of topics replicated as well as latency details for further discovery and analysis.
Connect Confluent Cloud to Azure services
Confluent and Confluent partners have built 100+ connectors to import and export data from popular data sources and sinks. This includes numerous integrations Azure Cloud services such as ADLS, Azure SQL, Azure Functions, Azure Synapse, Azure Cognitive Search, and more. Once the event stream arrives at one of these destinations, there are additional opportunities for integrating with subsequent Azure platform products, such as Event Grid, Logic Apps, Power BI, and Azure Synapse Analytics.
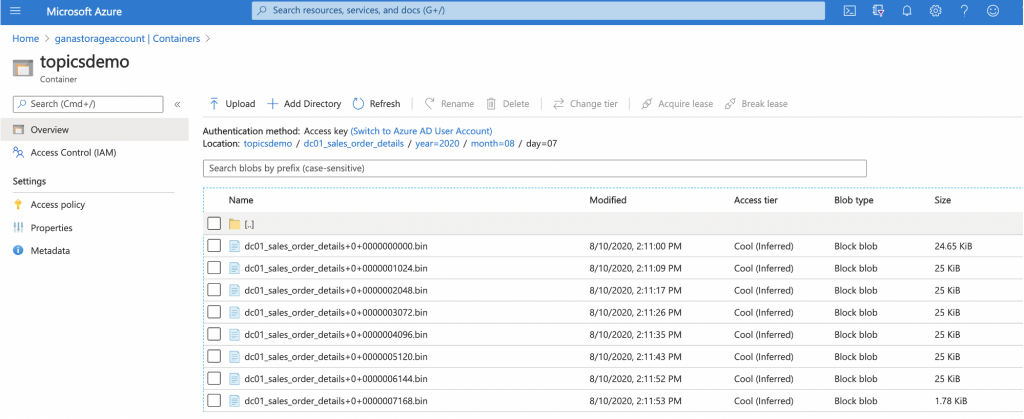
The use case in this blog post also demonstrates the integration with ADLS and Power BI for creating visualization views. The ADLS sink connector streams data from Confluent Cloud to ADLS Gen2 files in Avro, JSON, and byte array data formats. The ADLS connector guarantees exactly-once semantics, periodically polls data, and copies it to ADLS Gen2.
In the example below, the ADLS Gen2 connector is configured to push data to ADLS Gen2 in real time.
Further, you can discover the sales_order_details datasets through Power BI. Power BI is a data visualization tool that allows you to connect, transform, and visualize data. Power BI can connect to the data from multiple sources, and you can analyze the entire estate by combining both Azure Data Lake Analytics and Azure Synapse Analytics. With Microsoft Power BI Desktop, you can easily analyze the data using functions that provide access to data from multiple sources, enabling data enrichment and the creation of related reports.
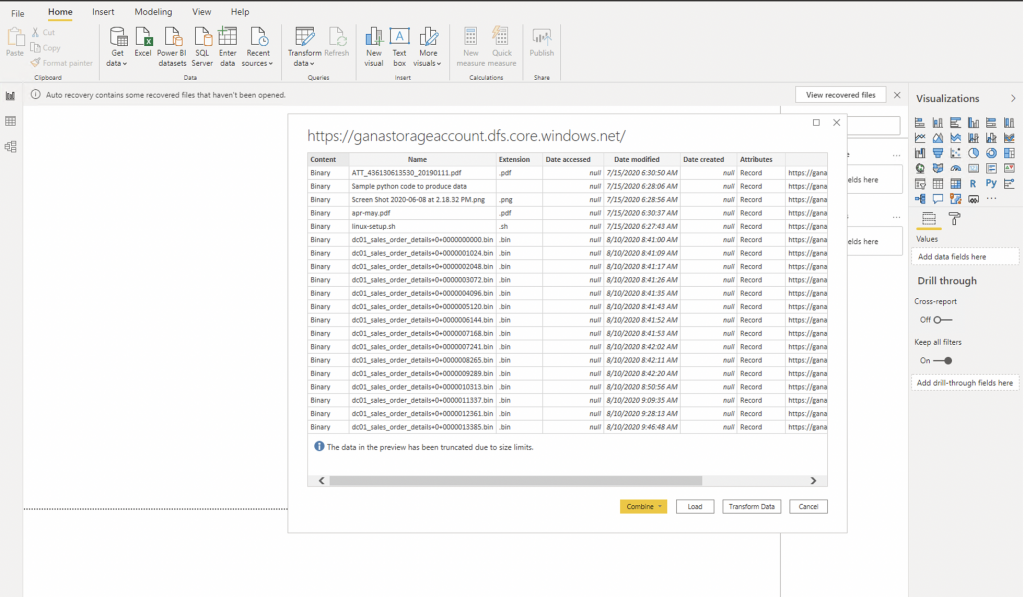
You can use the Power BI “Get Data” function to connect to multiple sources and provide ADLS with the details to create the connection.
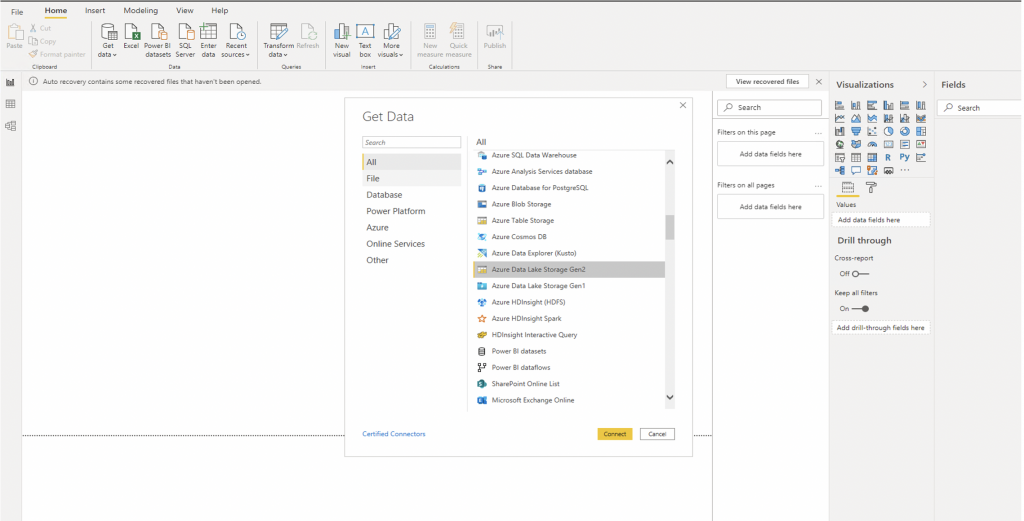
When the connection is established to ADLS, Power BI can load the sales_orders_details dataset or transform and visualize the datasets for special requirements.
This blog post demonstrated how the Bridge to Azure architecture enables event streaming applications to run anywhere and everywhere using Microsoft Azure, Confluent Replicator, and Confluent Cloud. This paves the way to migrate or extend any application running on prem or other clouds to Azure.
Learn more
- Check out fully managed Apache Kafka on Azure for the latest blog post, online talks, integrations, and more
- Get started with Confluent Cloud use the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage (details)
- Join us for a live demo of Confluent Cloud that shows you how to easily create your own Kafka cluster and use out-of-the-box components like ksqlDB to develop event streaming applications
- Watch Israel’s Kafka Summit talk: Getting Started with Apache Kafka: a Contributor’s Journey
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.