New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Celebrating Over 100 Supported Apache Kafka Connectors
We just released Confluent Platform 5.4, which is one of our most important releases to date in terms of the features we’ve delivered to help enterprises take Apache Kafka® and event streaming into production. These include Role-Based Access Control (RBAC), Structured Audit Logs, Multi-Region Clusters, and Schema Validation.
In the spirit of innovation around Kafka, we are very excited to announce that we now have reached over 100 supported connectors for getting data in and out of Kafka.
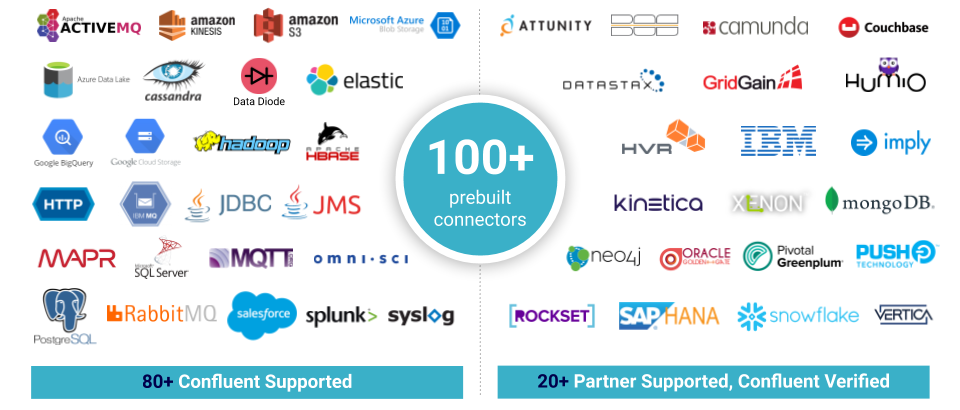
A rich ecosystem of 100+ prebuilt connectors
One of our main goals here at Confluent is to enhance productivity for Kafka developers. This means delivering capabilities that help developers spend more time building the event streaming applications that will actually change their business, and less time figuring out the inner workings of Kafka.
If you are a developer working with open source Apache Kafka, you have two options to connect existing data sources and sinks:
- Develop your own connectors using the Kafka Connect framework: the challenge with developing your own connectors is the time and effort that it takes, which could take up to several weeks, excluding the time required to fix any issues that might arise during actual operations.
- Leverage existing open source connectors already built by the community: the challenge in this case is the inherent risk of using technology that isn’t supported by an expert vendor. If you work for an organization deploying Kafka and event streaming into production, this usually is a gamble you cannot afford to make.
That’s why in 2019, we decided to rocketboost our efforts in this space. We started the year with fewer than 10 and ended the year with more than 100 supported connectors.
Most of these connectors are developed and supported by Confluent, but we have also worked closely with our technology partners. We have developed a program for independent software vendors (ISVs) and partners to verify connectors, assuring customers and users of connector interoperability and functionality with Kafka and Confluent Platform. About a quarter of the 100+ connectors are graduates of this program.
We also gathered extensive customer feedback to prioritize building the connectors you need, so we are confident that you will find the most popular and valuable connectors in our catalog, including Salesforce, InfluxDB, Google BigQuery, Azure Blob Storage, AWS Lambda, Syslog, and more.
Confluent Hub: Your one-stop shop for Kafka connectors
To further simplify how you leverage our connector portfolio, we offer Confluent Hub, an online marketplace to easily browse, search, and filter for connectors and other plugins that best fit your data movement needs for Kafka.
You may already know about Confluent Hub given that we first introduced it back in June 2018. What’s newsworthy is that we’ve given it a complete makeover. The new Confluent Hub boasts updated graphics, cleaner layouts and content, but most importantly, a dramatically enhanced user experience with a left-hand filtering banner that allows you to granularly search for plugins based on critical attributes, such as:
- Type: a sink connector, source connector, converter, or transform
- Enterprise support: Confluent or partner supported
- Licensing: commercially licensed or free (open source or community licensed)
- Confluent Cloud availability: whether it’s available fully managed in our hosted SaaS offering
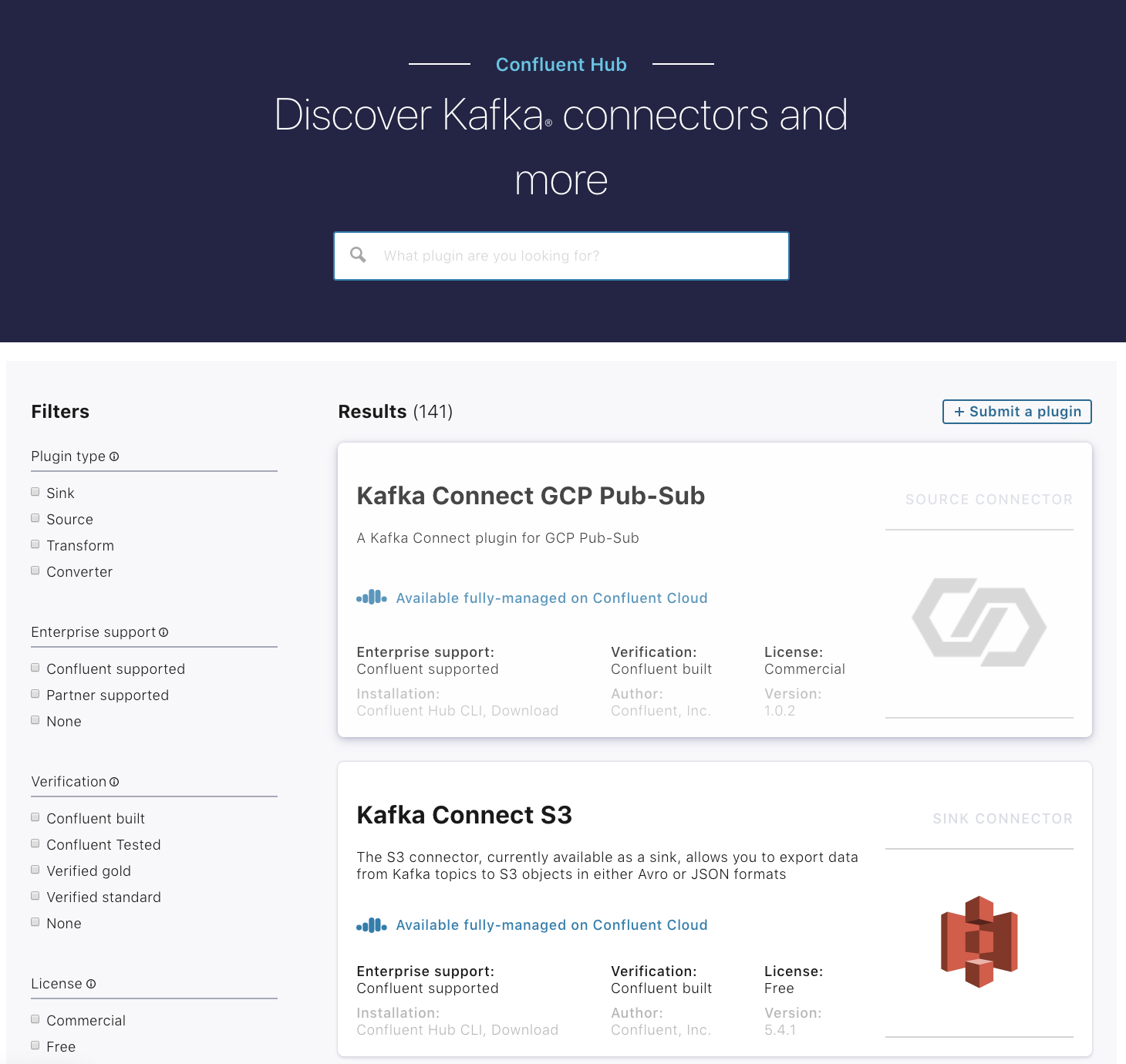
You can read about how the new Confluent Hub makes finding connectors easier than ever in this blog post by Ethan Ruhe.
Ready to get started?
Thanks to this important milestone of 100+ supported connectors and a revamped Confluent Hub, it has never been easier for you and your organization to instantly connect your most popular data sources and sinks to Kafka. We encourage you to explore Confluent Hub to find the Kafka connectors that are right for your use cases.
If you’d like to try the rest of our enterprise features from the 5.4 release, you can download Confluent Platform to take Kafka into production for your mission-critical use cases.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Real-Time Hyper-Personalization in 2026: Architecture Guide
Batch CDPs can't capture user intent as it forms. By the time a nightly sync runs, the moment is gone. This guide covers the streaming architecture behind real-time personalization, from sub-100ms ad bidding to cross-channel orchestration, with recommendation patterns built on Kafka and Flink.
How to Eliminate Training-Serving Skew With a Unified Real-Time Streaming ML Pipeline (2026 Guide)
Separate batch and streaming pipelines for ML features cause training-serving skew. DoorDash measured a 35.7% feature mismatch in their dual setup. This guide covers a unified kappa architecture using Flink to compute features once for both training and serving, plus a 2026 tooling comparison.