New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Stable, Secure Apache Kafka as a Service – A Cloud Provider’s Tale
Running fully managed Apache Kafka® as a service brings many responsibilities that leading cloud providers hide well. There is a reason why cloud services are so popular right now— companies realize how difficult, error prone, and time consuming it is to operate and maintain complex systems.
As a software developer, you don’t need to own this burden. With a managed service, a dedicated provider ensures regular version updates, patches for security vulnerabilities, and stability at all times. These are all table stakes for running a cloud service. Just like any other provider, Confluent stays competitive by constantly innovating and delivering new features to our customers. In the past year, we’ve adapted Apache Kafka for the cloud with elastic scaling, brought most Confluent Platform components to the cloud as fully managed services, shipped core features like usage-based billing, and expanded our cloud service to Microsoft Azure, while maintaining an SLA of 99.99% and frequently deploying the latest trunk version of Kafka.
So how did we do it? In this article, we will explore some of the various ways we ensure reliability. This involves everything from thorough testing to deploying new Kafka versions for our customers.
Community Contributions to Apache Kafka
Apache Kafka, in and of itself, is a very stable product. This stability is rooted in a well-thought-out and thorough process for contributing to the project.
Any change to Kafka must be approved by one or more project committers. A committer is an engineer with a proven track record of meaningful contributions to Kafka and its community: in JIRA, mailing list development discussions, documentation, user support on the mailing list, code reviews, or code contributions. Committers are very experienced in Kafka and are trusted with the responsibility of maintaining the project. Elections are held quarterly, and with the high bar for becoming a committer, the title is certainly prestigious.
Whether coming from a committer or not, any contribution that impacts the public interfaces of the project or introduces new functionality must first be written out as a Kafka Improvement Proposal (KIP). This is a design document that describes the proposed contribution from different angles: compatibility, performance, and user friendliness.
After writing the KIP, the contributor sends it to the mailing list in a [DISCUSS] thread for design discussion and iteration. Then the KIP appears in a new [VOTE] thread, in which community members give explicit approval to the final proposal. Acceptance of a KIP requires a lazy majority (explained in the Kafka bylaws). Typically, voting must be open for a minimum of 72 hours, and at least three project committers must cast binding votes. Committers don’t cast binding votes lightly; a committer who casts a binding vote for a KIP is expected to take ownership of the changes as if they introduced them themselves.
Pull requests can only be merged by project committers. A pull request follows the same pattern of ownership—the committer who merges a change is as responsible for the change as the author. If a committer sometimes seems overly strict when reviewing, keep in mind that this strictness is for the better. It results in a well-maintained and consistently high-quality codebase.

Apache Kafka follows time-based releases. Any given release has cutoff dates after which no major changes can be made or planned for the release—no new KIPs can be approved, and no major features can be merged. If a particular contribution might not make the release date, the project drops the contribution rather than delaying the release.
When all code changes are considered final, the maintainers cut a release candidate and ensure that all of the project’s integration and system tests pass consistently. A release vote requires stricter approval: a lazy majority consisting of at least three binding votes by Project Management Committee (PMC) members.
Community tests
No matter how strict the approval process, how experienced the committers, and how careful the reviews are, we are all humans. Humans make mistakes, and that is why we write automated tests. Apache Kafka boasts 8,179 JUnit tests and 193 system tests.
Contributions to the project are not merged until the JUnit tests pass. The system tests, which take much longer, are run nightly, and a new release of the project requires that the system tests pass in multiple consecutive runs.
The system tests exercise more involved end-to-end scenarios, such as:
- Ensuring protocol version compatibility
- Ensuring successful rolling upgrades of Kafka, Apache ZooKeeper™, and consumer groups
- Restarting a single broker and validating that clients work without interruption
Confluent Platform tests
Kafka’s tests are thorough and ensure that there are no regressions in the project itself. At Confluent, we develop components that integrate with Kafka, and it is not always enough to know only that Kafka itself is stable. We need to ensure that there are no regressions in the Kafka integrations for all Confluent Platform components.
Besides unit and integration tests for each component, we also have our own suite of system tests, which tests our entire ecosystem. Many of these tests simulate common use cases to guarantee that new releases don’t break existing workflows. For example, there is a test that validates that ksqlDB can process events ingested into Kafka from MySQL via a JDBC connector.
It’s also not enough to verify that Kafka and these components work together in our own isolated test environment. We’re running a cloud service that provisions, monitors, and maintains all of these components. We need to protect against regressions in any of this functionality and verify that our components perform well in the cloud.
To achieve this, we have a separate suite of system tests, which we call our cloud system tests. These tests exercise:
- Basic functionality of all components:
- ksqlDB/Kafka Connect /Kafka/Confluent Cloud CLI
- Data balancer rebalancing
- Cloud user registration, login, and authentication
- Provisioning/de-provisioning flow:
- Creating a cluster
- Deleting a cluster
- Client stability during rolling upgrades of components
- Failure of a single broker
Performance tests
Kafka is a very performant system, and as with any system that has strict performance guarantees, it’s hard to maintain and easy to regress on performance.
To defend against performance regressions, we have nightly performance tests. These use our automated cluster creation API and Apache Kafka’s Trogdor framework to schedule clients that use the cluster.
Our tests consist of a nine-broker multizone cluster, deployed with the latest version of Kafka. We have nine producer and consumer clients, using a total of 108 partitions. These clients create sustained throughput traffic over the course of one hour. The nightly performance test runs give us detailed information into the health of the cluster via our monitoring systems, enabling us to easily spot performance hiccups. This lets us pinpoint and solve performance problems early in the release process.
We also have various one-off tests that aren’t currently automated. These tests exercise complicated customer situations, such as a large number of partitions, a large and varying number of connections and reconnections, consumers reading from outside the page cache, and others. For a glimpse into the tests and measurements we run, check out 99th Percentile Latency at Scale with Apache Kafka by Anna Povzner and Scott Hendricks.
Tests that never sleep: Soak tests
But even that is not enough!
While all of these tests are exhaustive, some issues are rarely caught by short-run tests. Bugs, such as edge-case deadlocks, memory or socket leaks, and unexpected failure recovery issues, will only be exposed during long-running operations. To detect these issues, we run non-stop soak tests for most of our components—Kafka, the non-Java Kafka clients, ksqlDB, Connect, and Kafka Streams.
These tests run forever, and their only variable is the build of the component being tested. We generally soak a new build for at least seven days before we’re confident of its stability.
To determine that an image has passed a soak test, we ensure that all of its core metrics show positive results. A few key things we look for are increasing CPU or memory usage, under-replicated partitions, unexplained drops in throughput, increases in latency, and exceptions in the logs.
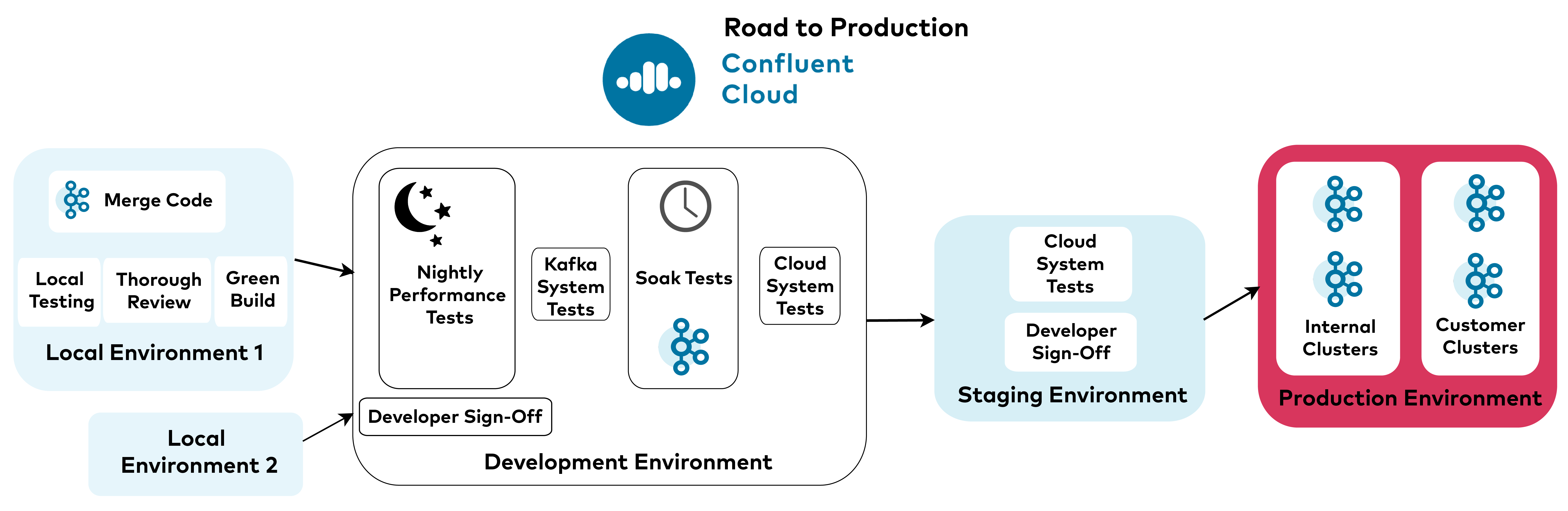
Tying it all up: Road to production
Let’s briefly review the hurdles that any new code must cross to make its way into our customers’ hands.
First, the new functionality must be merged into the respective project. Whether this is Apache Kafka, our Confluent Community licensed components, or a proprietary internal service, it must always pass a thorough review and have a build with green unit tests.
After a certain period, typically one to two weeks, we start to prepare a release. At Confluent, we maintain four environments for our cloud product : a managed local environment for each developer to use in testing new features, a development environment running locally tested features, a staging environment including features that are about to be rolled out, and last but not least , production. A release follows this same order and is deployed first on local environments, then to development, staging, and finally production.
When preparing a release, we first check for stellar results from Kafka’s latest nightly performance runs. Next, we ensure that all system tests are passing for Kafka and our Confluent Platform components. We then deploy the new version for soak tests and wait for the new build to pass a sufficient soak testing period (typically one week).
Finally, we start to bump versions in our respective environments and check for passing cloud system tests for each component. For internal services, cloud system tests run for each merged pull request. When these tests pass, the code is automatically promoted to our development environment.
When we’re ready to start a release train, each developer signs off on the feature in one environment (development and staging) before we promote it to the next environment. In the meantime, we monitor the first environment’s cloud system tests. We only move to the next environment after consecutive passing test runs.
When it comes time to move to production, we are especially careful. Whenever possible, we follow a canary release pattern, deploying new changes incrementally to a small subset of users. Since we use our own cloud product, we’re often our own canaries.
We always deploy a new release to Confluent’s internal clusters first. Only after we’ve seen that the new release is stable do we begin incremental rollouts across customer clusters, which we carefully monitor.
Next steps
Of course, you can never have enough testing, and even the most exhaustive test suites can have bugs slip through. There are two ways to battle this : constantly improve your test framework and have a very efficient process for responding to failures. The latter is a topic of its own, but let’s quickly examine how we at Confluent plan to improve our testing efforts.
Our next step is to introduce automated performance regression tests to every component, not just Kafka. This will allow us to catch any possible performance degradations in new releases.
We plan to encompass our tests within an easy-to-use platform that provides meaningful benchmarks and human-friendly reports for engineers. This offers an easier way to identify bottlenecks, plan optimal capacities, and tune parameters—all of which translate into a better, cheaper, and more efficient product for our customers.
We’re also aiming to split our current monolithic releases into independent releases for each component. This will provide better isolation for changes, reduce friction, and improve productivity across the board.
I hope that this post gave you an interesting peek into the world of running a managed cloud service. If you’re excited about running Kafka in the cloud, we’re hiring for all kinds of positions around the world. Whether or not you see your exact profile listed on the careers page, don’t hesitate to reach out to me or to any other Confluent employee for more details!
If you haven’t already, you can also sign up for Confluent Cloud to get $50 of free usage per month for the first three months.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.