New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Building a Materialized Cache with ksqlDB
When a company becomes overreliant on a centralized database, a world of bad things start to happen. Queries become slow, taxing an overburdened execution engine. Engineering decisions come to a crawl, since every schema change has the potential to bog down multiple teams in endless change board review meetings. Good ideas go unexecuted, because no one wants to be the one to disturb something so temperamental. The list of negative consequences goes on.
The problem at the heart of all this is that the database has been cemented into every area of your company—even those that would be better off without it. In some sense, relying on a centralized database can feel deceptively comforting because you only have to worry about one thing.
But it is undoubtedly a natural pinch point. Only so many queries can run concurrently in the same place. And each query can only be optimized so much without requiring pervasive schema changes. As your scale increases, your options become even more limited. You may not even be able to change important database characteristics if your team doesn’t have ownership of it. It’s like trying to untangle the Gordian Knot in software. Can you escape the pain without blowing up the entire operation?
As it turns out, you can, using a construct known as a materialized cache.
A materialized cache is a place where the results of a query are precomputed and stored for fast access. One way to think about the relationship between a database and a materialized cache is to consider how each treats data and queries. With a traditional database, we might say that the data is passive, just waiting to be acted upon. When a query executes, it becomes active over the data and computes the result from scratch every time.
By contrast, a materialized cache inverts this relationship and gives data an active role. When new data arrives, preinstalled queries passively make incremental updates to their results. These results can be accessed with low latency at any time, since the cache is fully precomputed. Some databases support a version of this through materialized views, but the kind of materialized cache we’re describing decouples reads and writes entirely.
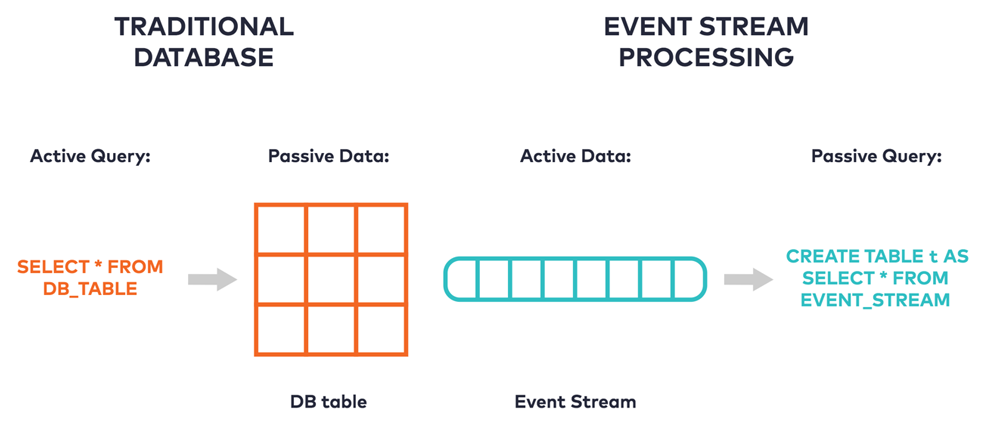
Although these models are opposites, they’re often used in conjunction. When writes are issued to a database, they can be intercepted using some form of change data capture. The changes, or events, can be forwarded into durable, append-only storage like Apache Kafka®.
There are a number of advantages to adopting this model. Because Kafka permits many consumers to concurrently read from a topic in a conflict-free manner, you can construct an arbitrary number of materialized caches over it. These caches can structure the data in any number of different access patterns that are efficient for each application. In this way, you can incrementally decrease pressure on your database as you stand up more materialized caches.
There are a lot of ways that you can introduce a materialized cache into your architecture. One such way is to leverage ksqlDB, an event streaming database purpose-built for stream processing applications. With native Kafka integration, ksqlDB makes it easy to replicate the pattern of scaling out many sets of distributed caches.
Let’s look at how this works in action with an example application. Imagine that you have a database storing geospatial data of pings from drivers at a ridesharing company. You have a particular piece of logic that you want to move out of the database—a frequently run query to aggregate how active a territory is. You can build a materialized cache for it using ksqlDB.
Up and running with ksqlDB
First, you’ll need to get ksqlDB, which is available through Docker. Everything you need, including Kafka, can be found in this Docker Compose file. Copy it into a docker-compose.yml file and bring it up with docker-compose up.
When you use ksqlDB, you build programs interactively through its CLI, just like MySQL. Start a CLI prompt by issuing the following command: docker exec -it ksqldb-cli ksql http://ksqldb-server:8088.
Now that ksqlDB is up and running, you can build your materialized cache.
Building the cache
To begin, we’ll model the change data capture that will eventually come from our database as a stream. Here, we declare a new stream with a schema that matches the database table. This stream captures pings and their geographical locations:
CREATE STREAM riderLocations (profileId VARCHAR, latitude DOUBLE, longitude DOUBLE, timestamp BIGINT) WITH (kafka_topic='locations', key='profileId', value_format='json', partitions=1, timestamp='timestamp');
Insert some sample events into the stream so that you can test your program interactively:
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('4ab5cbad', 37.3956, -122.0810, 1578528022704);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('c2309eec', 37.7877, -122.4205, 1578528022805);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('18f4ea86', 37.3903, -122.0643, 1578528023612);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('4ab5cbad', 37.3952, -122.0813, 1578528024200);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('8b6eae59', 37.3944, -122.0813, 1578528024814);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('4a7c7b41', 37.4049, -122.0822, 1578528025097);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('4ab5cbad', 37.3949, -122.0815, 1578528025132);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('4ddad000', 37.7857, -122.4011, 1578528025890);
INSERT INTO riderLocations (profileId, latitude, longitude, timestamp) VALUES ('8b6eae59', 37.3954, -122.0816, 1578528025999);
Before writing any queries, set a property in ksqlDB to force all queries to read from the start of the stream. This is useful for development because you get a repeatable workflow:
SET 'auto.offset.reset' = 'earliest';
You’re all set to model the heart of the program.
We want to move an expensive query off of the database that looks up how active a territory is and, for this example, find out how many pings are coming each hour from drivers within five miles of Mountain View, California. To do that, write a SELECT statement that aggregates events from the stream, retaining only those that are within the defined territory (Mountain View’s latitude and longitude are 37.4133, -122.1162):
SELECT profileid, count(*) AS pings FROM riderLocations WINDOW TUMBLING (SIZE 1 HOUR) WHERE GEO_DISTANCE(latitude, longitude, 37.4133, -122.1162) <= 5 GROUP BY profileid EMIT CHANGES;
This query should output the following data (and continue to wait for more input):
+------------------+-----------+ |PROFILEID |PINGS | +------------------+-----------+ |4a7c7b41 |1 | |4ab5cbad |3 | |8b6eae59 |2 |
In contrast to a traditional database, this query runs forever and incrementally updates its results as new events arrive (press Ctrl+C to stop it). It is the very definition of a materialized cache. But how do you query it?
To do that, you need to make this query persistent. In other words, it needs to run in the background so that ksqlDB can set up a set of named resources to query. This can be achieved by issuing the code below, which simply wraps the previous statement in a named table:
CREATE TABLE mountain_view AS SELECT profileid, count(*) AS pings FROM riderLocations WINDOW TUMBLING (SIZE 1 HOUR) WHERE GEO_DISTANCE(latitude, longitude, 37.4133, -122.1162) <= 5 GROUP BY profileid EMIT CHANGES;
You can now query the table for the number of times each profile ID sent a ping from within Mountain View:
SELECT * from mountain_view WHERE ROWKEY='8b6eae59';
This should output the following:
+------------+----------------+------------+---------+ |ROWKEY |WINDOWSTART |PROFILEID |PINGS | +------------+----------------+------------+---------+ |8b6eae59 |1578528000000 |8b6eae59 |2 | Query terminated
Notice that, in contrast to the persistent query, this query runs immediately and terminates. In fact, this query does no computation. It simply looks up the value of the key from the precomputed materialized cache. ksqlDB calls this a pull query because it allows an application to pull the current state to it. Try inserting more events and query the table again to watch its results change.
Taking ksqlDB to production
And with that, you have a simple materialized cache that you can introduce into your architecture. When you introduce this into your architecture, you’ll want to query the cache remotely instead of using the CLI. ksqlDB has a first-class REST API that supports doing this from remote systems. You can take this for a spin over curl:
curl -X "POST" "http://localhost:8088/query" \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-d $'{
"ksql": "SELECT * from mountain_view WHERE ROWKEY=\'8b6eae59\';",
"streamsProperties": {}
}' | jq
This should yield the following:
[
{
"header": {
"queryId": "PULL-query-MOUNTAIN_VIEW",
"schema": "`ROWKEY` STRING KEY, `WINDOWSTART` BIGINT KEY, `PROFILEID` STRING, `PINGS` BIGINT"
}
},
{
"row": {
"columns": [
"8b6eae59",
1578528000000,
"8b6eae59",
2
]
}
}
]
It’s also important to have a clean way of actually forwarding change capture events from your database into Kafka. Kafka Connect has a vast ecosystem of connectors for doing exactly this, and ksqlDB provides first-class support for running connectors using simple SQL syntax.
With ksqlDB, you can build a complete streaming app with a small set of SQL statements. We think this is a powerful way to introduce core building blocks into your architecture, such as materialized caches. Get started today!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.