New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Building a Cloud ETL Pipeline on Confluent Cloud
As enterprises move more and more of their applications to the cloud, they are also moving their on-prem ETL pipelines to the cloud, as well as building new ones. There are many powerful use cases for these real-time cloud ETL pipelines, and this blog post demonstrates one such use case—a log ingestion pipeline that spans multiple cloud providers. The demo leverages easy CLI commands so you can automate it end-to-end on Confluent Cloud with fully managed Apache Kafka® brokers, Kafka connectors, Confluent Schema Registry, and ksqlDB.
Accompanying this blog post, there is an automated demo in GitHub which you can run in parallel or refer to for configuration examples.
Multiple cloud providers
Enterprises are faced with the realities of multi-cloud requirements for reasons such as business regulations, shifting cloud costs, or variable requirements across lines of business. For example, one line of business uses BigQuery, another, Amazon Athena, and yet another, Azure Data Lake. Developers in these enterprises are inclined to choose the application based on their needs, not based on their organization’s cloud preference. An expanding multi-cloud footprint may also occur unintentionally: after an acquisition, companies inherit the acquired company’s cloud choices, which may not be the same as the acquiring company.
Ultimately, developers want to choose the apps they want, unshackled from single-vendor offerings. The outcome is that enterprises need to manage fluid workloads seamlessly between any public cloud provider, private cloud, or even on-prem deployment. Confluent Cloud can be that single source of truth for your business’s mission-critical services.
Fully managed service
Confluent Cloud is a fully managed service that includes:
- Apache Kafka
- Connectors
- Confluent Schema Registry
- KSQL
- ACLs
As a fully managed service, Confluent Cloud offloads operational burden from developers so that you can focus on applications. You may develop your own client applications in any of the programming languages that support the Kafka client API and connect them to your Kafka cluster in Confluent Cloud. Or, if you want to use one of the 100+ supported connectors, some of which have yet to be available as fully managed connectors in Confluent Cloud, you can run your own Kafka Connect cluster and deploy connectors that write to or read from Confluent Cloud.
Cloud providers like Google Cloud Platform (GCP), Microsoft Azure, and Amazon Web Services (AWS) have robust CLIs that enable users to interact with the services in their portfolio. Likewise, the Confluent Cloud CLI allows users to build Kafka-based pipelines in Confluent Cloud. The CLI now supports the ability for you to manage, create, and describe Confluent Cloud features:
- Kafka clusters and environments
- Connectors
- Schema Registry
- ksqlDB applications
- Service accounts, API keys, and secrets
- ACLs
For a primer on the Confluent Cloud CLI, see this Confluent Cloud CLI demo in GitHub and refer to the documentation.
Cloud ETL demo use case
As a simple use case, let’s consider the scenario of log event ingestion. Apps can generate log events at massive scale, and some organizations keep log files around for a limited number of days. To build a log ingestion pipeline, you can extract those events and cleanse, transform, or enrich the log events in some way. Then, they can be loaded into a cloud storage system for later analysis. This log event ingestion scenario forms the basis for the use case in this blog post.
Confluent Cloud enables a multi-cloud pipeline, so the source cloud provider of the log events can differ from the destination cloud provider. For the purpose of this demo, let’s say the log events are written to an Amazon Kinesis stream. Perhaps you want to centralize that data in Kafka, move that data to another cloud provider, or run a performant ksqlDB application on that dataset. Either way, you want to extract the raw Kinesis stream into a Kafka topic in Confluent Cloud. Once written into Confluent Cloud, the log events are transformed by ksqlDB and then loaded into any cloud storage: Google Cloud Storage (GCS), Azure Blob Storage, or Amazon S3. This brings the log events, which originated in one cloud provider, to any cloud provider of your choice.
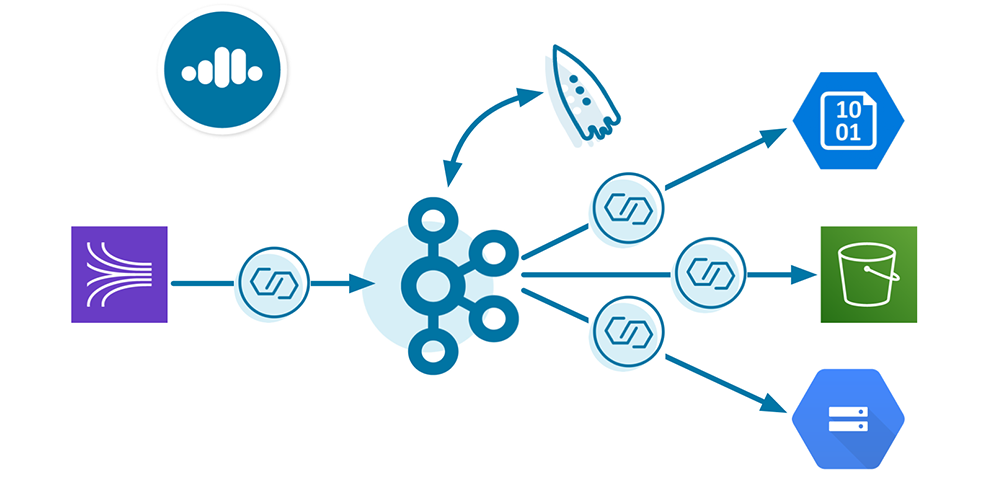
Cloud ETL use cases vary from user to user and org to org, so I’ll just paint the broad requirements for the services in this demo. Make sure you have done the basic steps to spin up services. For example, you’ve got a Confluent Cloud environment and Kafka cluster (you can create these via the CLI or UI!), enabled Confluent Cloud Schema Registry, enabled Confluent Cloud KSQL, etc. From there, use your user account credentials or create appropriate service accounts, create key/secret pairs for those service accounts, set appropriate permissions via ACLs, etc.
For repeatability and scriptability, use the Confluent Cloud CLI with some flavor of the following commands:
# Login ccloud login
# Confluent Cloud Kafka cluster ccloud kafka cluster <...>
# Confluent Cloud Schema Registry ccloud schema-registry cluster <...>
# Confluent Cloud KSQL ccloud ksql app <...>
# Credentials: API key and secret ccloud api-key <...>
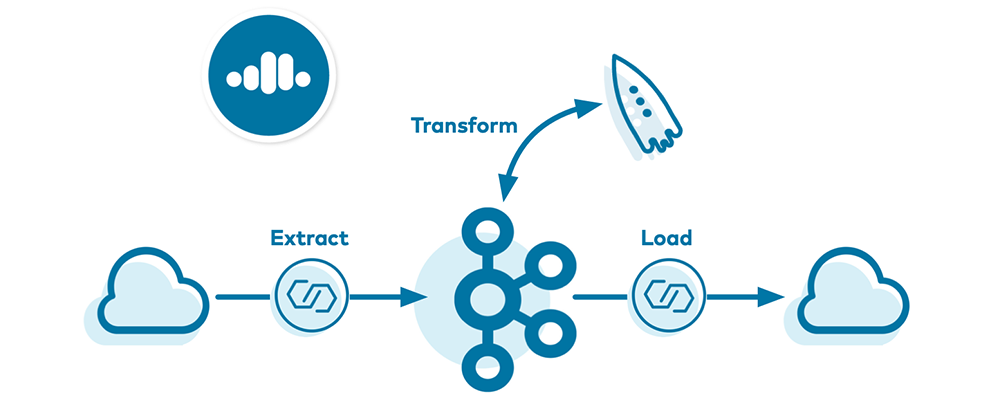
At this point, you have basic services set up but no data flowing through them yet. Let’s get some data into that Kafka cluster in three steps:
- Extract: Create the source connector
- Transform: Run ksqlDB commands
- Load: Create the cloud storage sink connector
Extract: Create the source connector
Confluent Cloud provides fully managed connectors so you don’t have to self-manage the connector or the Connect framework that it runs in. Create a JSON-formatted configuration file for the Kinesis connector that looks like the following, substituting in your Kafka cluster credentials and cloud provider values, and call it kinesis.json. As a source connector, the configuration parameters that start with aws.* and kinesis.* tell the connector where to read from, and those that start with kafka.* tell the connector where to write to:
{
"name": "demo-KinesisSource",
"connector.class": "KinesisSource",
"aws.access.key.id": "$AWS_ACCESS_KEY_ID",
"aws.secret.key.id": "$AWS_SECRET_ACCESS_KEY",
"kinesis.region": "$KINESIS_REGION",
"kinesis.stream": "$KINESIS_STREAM_NAME",
"kinesis.position": "TRIM_HORIZON",
"tasks.max": "1",
"kafka.api.key": "$CLOUD_KEY",
"kafka.api.secret": "$CLOUD_SECRET",
"kafka.topic": "eventLogs"
}
Pass in that configuration file as an argument when you use the CLI to create the Amazon Kinesis Source Connector for Confluent Cloud:
ccloud connector create --config kinesis.json
When this connector is provisioned, you can monitor its state:
ccloud connector describe lcc-knjgv
Connector Details +--------+--------------------+ | ID | lcc-knjgv | | Name | demo-KinesisSource | | Status | RUNNING | | Type | source | +--------+--------------------+
...
Once the Kinesis stream has data in it, use the Confluent Cloud CLI to view the messages in the topic, which is eventLogs in this case. The -b argument instructs the CLI to read from the beginning of the topic.
ccloud kafka topic consume eventLogs -b
Now your Kafka cluster in Confluent Cloud has data that is being populated with events from the Kinesis stream:
...
{"eventSourceIP":"192.168.1.1","eventAction":"Create","result":"Pass","eventDuration":2}
{"eventSourceIP":"192.168.1.1","eventAction":"Delete","result":"Fail","eventDuration":5}
{"eventSourceIP":"192.168.1.1","eventAction":"Upload","result":"Pass","eventDuration":3}
...
Transform: Run ksqlDB commands
Let’s apply some stream processing on the ingested log events. This stream processing is the transform part of the Cloud ETL. We have a fully managed ksqlDB application in Confluent Cloud, but what do we want the ksqlDB application to do? For the demo, the streaming application counts the number of log events and sums the time duration of successful log events. In KSQL, this translates to the following commands:
- Create a stream of log events. The ksqlDB STREAM eventLogs associates a schema with the underlying Kafka topic eventLogs.
CREATE STREAM eventLogs ( eventSourceIP varchar, eventAction varchar, Result varchar, eventDuration bigint) WITH (kafka_topic='eventLogs', value_format='JSON'); - Count the number of log events, grouped by device IP address:
CREATE TABLE count_per_source WITH (KAFKA_TOPIC='COUNT_PER_SOURCE', PARTITIONS=6) AS SELECT eventSourceIP, count(*) as COUNT FROM eventLogs GROUP BY eventSourceIP EMIT CHANGES; - Sum the duration of successful log events, grouped by device IP address. Notice the underlying Kafka topic SUM_PER_SOURCE is Apache Avro™ formatted.
CREATE TABLE sum_per_source WITH (KAFKA_TOPIC='SUM_PER_SOURCE', PARTITIONS=6, VALUE_FORMAT='AVRO') AS SELECT eventSourceIP, sum(eventDuration) as SUM FROM eventLogs WHERE Result='Pass' GROUP BY eventSourceIP EMIT CHANGES;
Confluent Cloud provides fully managed ksqlDB clusters for you to build your app in. Once the cluster is provisioned and appropriate ACLs are configured for the ksqlDB app to access the topics, simply submit queries to it. You can use the ksqlDB REST API to send commands. Substitute your values for the ksqlDB endpoint and your API key/secret, and then send the ksqlDB command(s) set in the ksqlCmd variable shown in the sample below:
curl -X POST $KSQL_ENDPOINT/ksql \
-H "Content-Type: application/vnd.ksql.v1+json; charset=utf-8" \
-u $KSQL_BASIC_AUTH_USER_INFO \
-d @<(cat << EOF
{
"ksql": "$ksqlCmd",
"streamsProperties": {}
}
EOF
)
You can view the flow through your ksqlDB application from the Confluent Cloud UI:

Since the VALUE_FORMAT for SUM_PER_SOURCE is Avro, the Confluent Cloud ksqlDB application automatically uses Confluent Cloud Schema Registry associated with the Kafka cluster, which should have been enabled as a prerequisite. There is a schema associated with this topic, which you can view from the command line by querying the Schema Registry for the topic’s value (versus key).
ccloud schema-registry schema describe \ --subject SUM_PER_SOURCE-value \ --version latest | jq .
Sample output:
{
"type": "record",
"name": "KsqlDataSourceSchema",
"namespace": "io.confluent.ksql.avro_schemas",
"fields": [
{
"name": "EVENTSOURCEIP",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "SUM",
"type": [
"null",
"long"
],
"default": null
}
]
}
Load: Create the cloud storage sink connector
So now you want to send these transformed log events off Confluent Cloud, perhaps to a cloud storage service for downstream consumption, future analytics, or potential auditing purposes. Let’s say those applications are in another cloud (e.g., GCP or Azure), which differs from where the log events were created (e.g., AWS in the case of this demo). Confluent Cloud enables you to easily build this cloud ETL across providers by nature of running an appropriate connector to move the data to a different cloud provider. Note that for the fully managed sink connectors like AWS S3, GCP GCS, and Azure Blob Storage, your Kafka cluster in Confluent Cloud must be in the same cloud provider and region as the destination cloud provider.
For this blog post, let’s choose GCS for cloud storage. Create a JSON-formatted configuration file for the GCS connector similar to below, substituting in your Kafka cluster credentials and cloud provider values, and call it gcp.json. As a sink connector, the configuration parameters that start with kafka.* tell the connector where to read from, and those that start with gcs.* tell the connector where to write to. Set the configuration parameter data.format to AVRO or BYTES depending on whether it is an Avro-formatted topic or not. Notice that the topics configuration parameter is set to COUNT_PER_SOURCE, which indicates that this connector is “loading” the values from the post-transformed data that was created by the ksqlDB application into cloud storage for later use.
{
"name": "demo-GcsSink-no-avro",
"connector.class": "GcsSink",
"tasks.max": "1",
"kafka.api.key": "$CLOUD_KEY",
"kafka.api.secret": "$CLOUD_SECRET",
"gcs.bucket.name": "$GCS_BUCKET",
"gcs.credentials.config": "$GCS_CREDENTIALS",
"data.format": "BYTES",
"topics": "COUNT_PER_SOURCE",
"time.interval" : "HOURLY"
}
Then pass in that configuration file as an argument when you use the CLI to create the Google Cloud Storage Sink Connector for Confluent Cloud:
ccloud connector create --config gcp.json
Once there are enough records in the Kafka topic to meet flush size requirements, the data gets sent to GCS. Using GCP’s CLI gsutil tool, we see GCS now has that data in it:
... gs://confluent-cloud-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=25/hour=13/COUNT_PER_SOURCE+1+0000000000.bin gs://confluent-cloud-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=25/hour=13/COUNT_PER_SOURCE+1+0000001000.bin gs://confluent-cloud-demo/topics/COUNT_PER_SOURCE/year=2020/month=02/day=25/hour=13/COUNT_PER_SOURCE+1+0000002000.bin ...
The demo’s cloud ETL from Kinesis to Kafka, ksqlDB for stream processing, and Kafka to GCS is complete!
Summary and next steps
You now have read how to build a real-time cloud ETL on Confluent Cloud across multiple cloud providers (GCP, Azure, and AWS), with fully managed services, such as Cloud connectors, Schema Registry, and ksqlDB applications. While you can perform most of the same actions from the Confluent Cloud UI, we’ve used the Confluent Cloud CLI for automation purposes—scriptability and repeatability.
As a next step, if you haven’t already, take advantage of the promo code CL60BLOG to get an additional $60 of free Confluent Cloud usage, so that you can run the automated version of this tutorial in the Cloud ETL demo in GitHub.* Also be sure to check out the blog post Streaming Heterogeneous Databases with Kafka Connect for further reading.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Real-Time Hyper-Personalization in 2026: Architecture Guide
Batch CDPs can't capture user intent as it forms. By the time a nightly sync runs, the moment is gone. This guide covers the streaming architecture behind real-time personalization, from sub-100ms ad bidding to cross-channel orchestration, with recommendation patterns built on Kafka and Flink.
How to Eliminate Training-Serving Skew With a Unified Real-Time Streaming ML Pipeline (2026 Guide)
Separate batch and streaming pipelines for ML features cause training-serving skew. DoorDash measured a 35.7% feature mismatch in their dual setup. This guide covers a unified kappa architecture using Flink to compute features once for both training and serving, plus a 2026 tooling comparison.