New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Apna Unlocks AI Job Matching for 50 Million Users With Confluent & Onehouse
Since its beginnings just five years ago, Apna has become the leading jobs site for tens of millions of workers in India, the largest labor market in the world. Today, Apna has more than 50 million registered users, resulting in more than 5 million interviews and 100,000 jobs activated per month.
To support the platform’s continuous growth and cutting-edge innovation—including the use of artificial intelligence (AI) and machine learning (ML) for job matching—Apna needed to re-architect their site to be faster and more flexible, while maintaining reliability and gaining operational efficiencies. This change took Apna from a monolithic software architecture with batch updates and a data warehouse to microservices, streaming data pipelines, and a universal data lakehouse architecture for data integration.
Migrating from batch updates to real-time data streaming has allowed Apna to outperform competitors, creating an outstanding customer experience, while also reducing costs and delivering a 2x improvement in time to market for new business solutions.
The organization’s new data infrastructure is built on two core technologies:
Confluent’s fully managed data streaming platform—powered by Kora, the cloud-native Apache Kafka® engine—which supports key use cases like change data capture (CDC) for operational databases.
An Apache Hudi® data lakehouse, delivered as part of the Onehouse managed service, that supports end-to-end data table updating from CDC data.
The fact that both Confluent Cloud and Onehouse’s universal data lakehouse are built on open standards made these technologies a perfect fit for Apna’s technical strategy. “We generally prefer open source vendors to avoid lock-in,” said Subham Todi, lead data engineer at Apna. Using managed services from Confluent and Onehouse enables the company to stay “lean and mean,” allowing technical talent to focus on building and improving features that directly bring value to the business.
Leaving behind the limitations of Apna’s legacy architecture
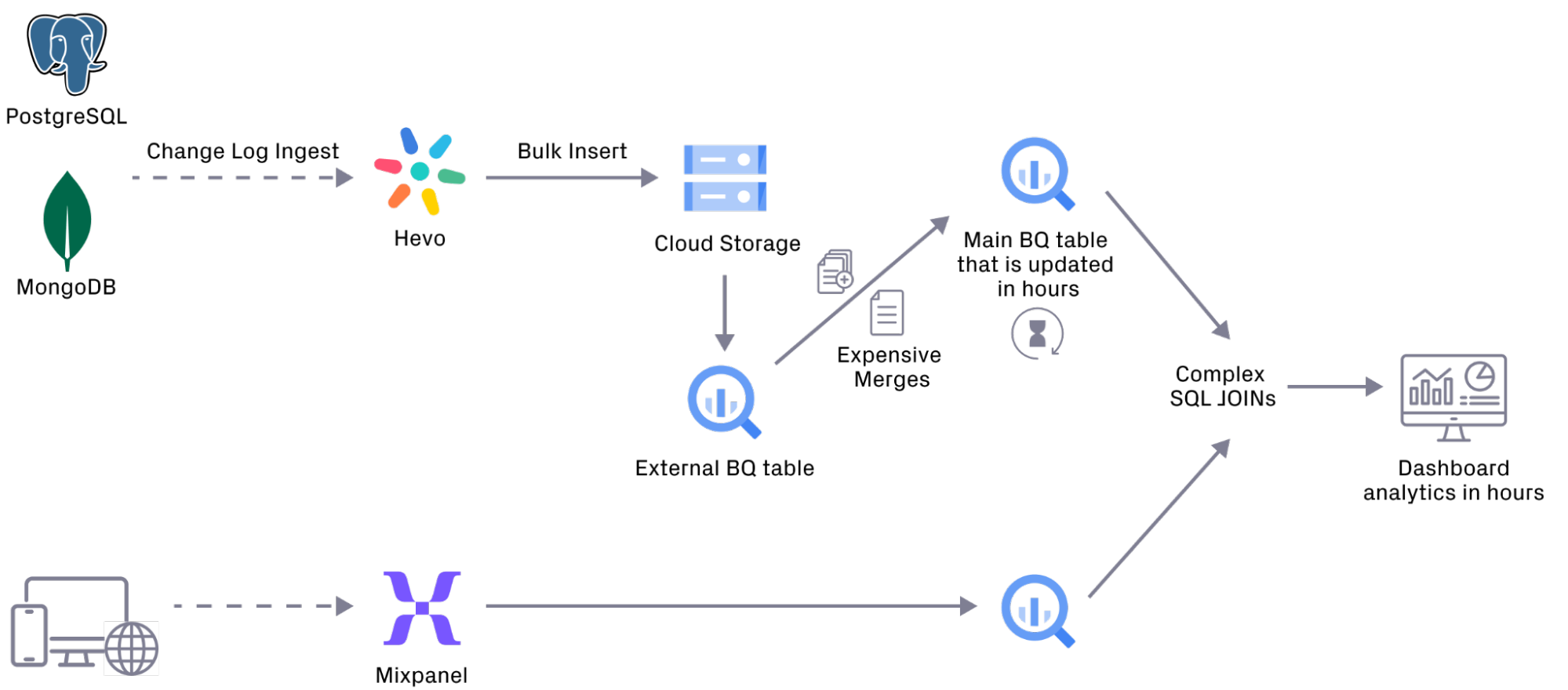
Apna began with a monolithic, back-end software architecture. Structured transactional data came in via CDC from PostgreSQL and MongoDB databases. That data was then ingested using Hevo, being integrated via a Google BigQuery data warehouse. Clickstream sources came in through Mixpanel. Updates were batched at intervals ranging anywhere from every hour to once a day.
This architecture came with numerous issues related to cost, efficiency, and maintenance. Examples include:
The monolithic software backend meant that software updates were infrequent, difficult to develop, and difficult to deliver.
High costs prevented the use of real-time sync for CDC data via Hevo, forcing reliance on much slower batch processing. This limited data freshness and consistency.
Batch processing also generated a large, temporary external BigQuery table, which was costly, time-consuming to maintain, and failure-prone.
The limited alerting capabilities of Hevo meant operators had to constantly monitor the user interface (UI) or risk missing critical issues when they arose.
Time travel was only supported for seven days. Apna needed nearly unlimited time travel for flexible querying and comparisons to support feature development.
The use of multiple third-party systems along with in-house code made development and maintenance difficult.
Interactions across many different systems created multiple potential points of failure, resulting in significant operational challenges for the production system.
These challenges caused latency throughout the system, resulting in delayed data delivery, reduced developer productivity, and the inability to scale to meet user growth for Apna’s existing applications. New functionality, such as the use of AI/ML for job matching, was simply out of reach with this legacy architecture.
Apna rearchitects with Confluent and Onehouse to accelerate growth
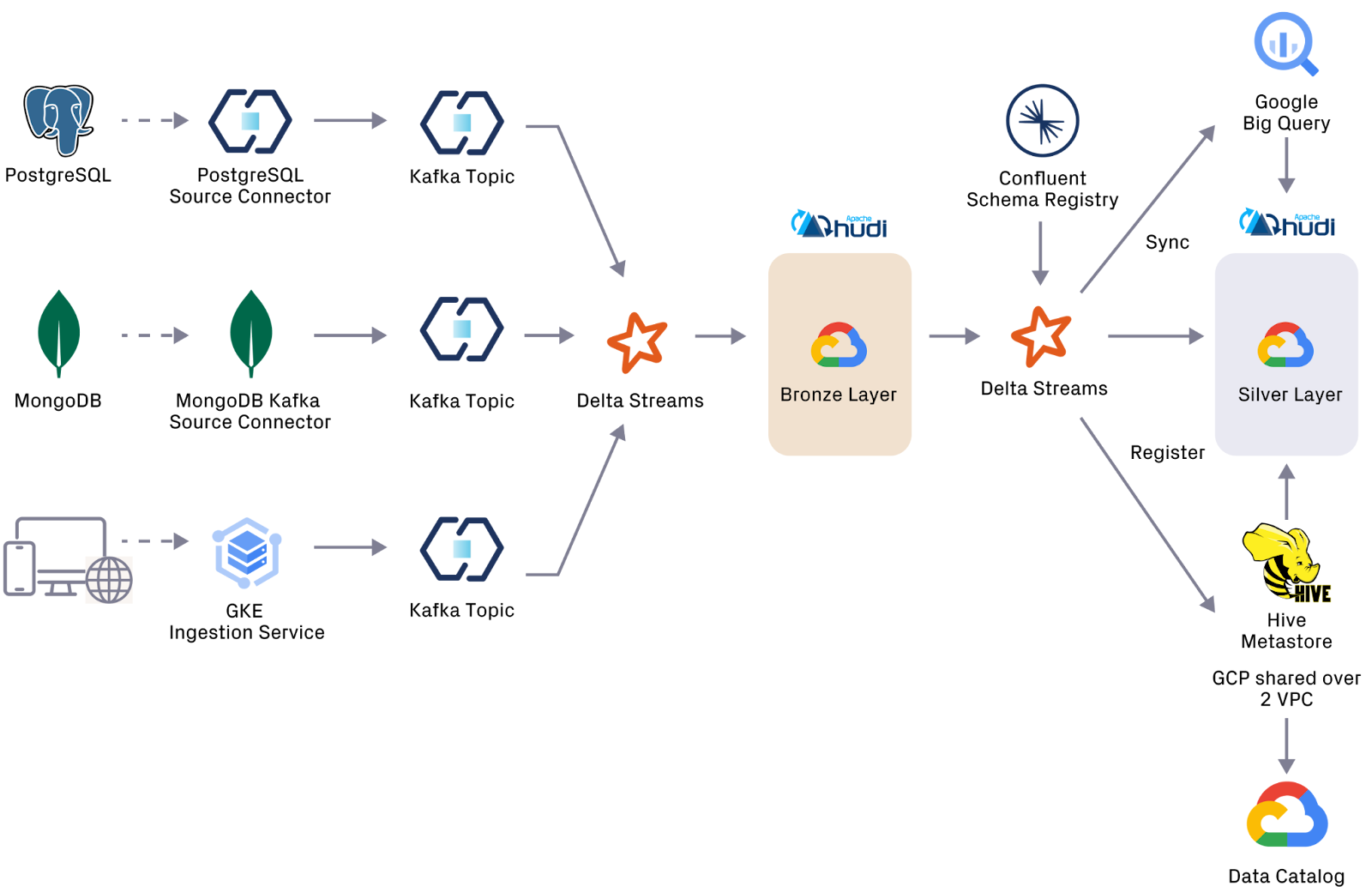
Apna’s new data platform, shown in Figure 2, is called Apna Analytics Ground (AAG)—the acronym AAG means “fire” in Hindi. AAG uses Confluent’s data streaming platform for software deployment and software operations, the Onehouse-powered universal data lakehouse for data storage and data access, and Apache Spark® to drive delta streams between data tables.
The use of managed services saves time and developer resources, which allows Apna to stay focused on “the core mission of connecting people to opportunities.” Additionally, Confluent Cloud provides 120+ pre-built connectors that save development time and deliver high availability on an elastically scaling platform with a 99.99% uptime SLA.
The data lakehouse at the core of the Onehouse managed service, kept up to date by data streaming from Confluent Cloud, serves as a “single source of truth” for all analytics needs, including AI/ML use cases. Confluent Schema Registry validates messages from Postgres, clickstream and CDC sources.
Transactional data is ingested from Postgres using CDC via an open source connector and a MongoDB Kafka Source Connector. After migrating to this new architecture, Apna wrote a logging service to bring clickstream data from web and mobile applications into a Kafka topic, one per data table. Ingested data is now stored in bronze tables—an immutable, append-only data log that can be used to re-create downstream tables to meet new needs or deal with errors.
The company implements advanced Onehouse functionality such as a schema validation check for updates. Records that fail the check are streamed and saved to a quarantine table for review. With the robust medallion architecture in place, as supported by the universal data lakehouse, Apna can always re-run a problematic job after it’s repaired.
Apna has cultivated a high level of engagement with both Confluent and Onehouse, giving them a seat at the table to mutually share insights on the evolution of these key technologies, while maintaining the focus of its technical staff on innovation relevant to their industry and business needs rather than building, scaling, or maintaining infrastructure.
Benefits of adopting Confluent + Onehouse that paved the way for AAG
Adopting Confluent Cloud and Onehouse has helped Apna not only solve problems with the previous infrastructure but also enabled new gains. For example, Apna worked with Confluent to completely revamp their software development, delivery, and operations processes.
Additionally, combining data streaming on Confluent Cloud with Onehouse’s universal data lakehouse delivers shared benefits across the entire infrastructure, including:
Seamless integration across open source standards, including Kafka-based data streaming, the Hudi-based lakehouse, and Apache XTable (incubating) for data interoperability
Involving Apna in the evolution of multiple open source technologies, without the burden of “owning” vast tranches of infrastructure code
Apna now describes Confluent Cloud as the central nervous system of its DevOps and data infrastructure. The Kafka-based data streaming platform is used as an event manager, for communication between microservices, for ephemeral storage, for distributed task scheduling, and (of course) as the workhorse for any other application that requires data in motion.
Confluent provides Apna with many benefits:
More than “four nines” of availability (equating to a maximum of less than an hour of downtime a year)
Elastic scalability, with response time in milliseconds
Advanced security and end-to-end encryption
A 2x improvement in time to market for new business solutions, using pre-built, fully managed connectors and cloud-native infrastructure
Zero bandwidth invested in cluster maintenance and other routine tasks
Adoption of Confluent Cloud has also paved the way for building AAG on the Onehouse lakehouse by:
Reducing costs for storage, with storage costs savings greater than 2x
Data update sync frequency is now configurable, where previously updates could only be done in batch mode due to cost constraints
Bringing data freshness to the minute level, instead of hours—an improvement of 5-10x in most cases, in comparison to Apna’s legacy architecture
Allowing data to be kept in Apna’s virtual private cloud (VPC) on Google Cloud Storage, significantly improving security
Delivering on flexible SLAs for balance costs and business requirements across the system
Providing robust alerting greatly reduces operations burdens and enables progressive improvement
Allowing for much more extensive time travel for analytics purposes
Ensuring any query engine can be used against data in the silver layer, with the lakehouse serving as a “single source of truth”—with Apna’s use of the medallion architecture
This fast and flexible infrastructure allows Apna to simultaneously manage costs, maintain uptime, and work at the cutting edge of innovation. Today, Apna easily uses an AI-powered matching service to optimize results for both job seekers and recruiters—all built on top of the data platform enabled by Confluent and Onehosue.
How migrating its data infrastructure unlocks further innovation for Apna
Through a great deal of hard work, including not only technical effort but strategic planning, partnering, and relationship-building, Apna has established a leadership position both in business and in the creative use of advanced technology. Through the use of managed services they’re able to improve scalability and time to market while containing costs.
Apna’s deployment of data streaming and the universal data lakehouse has enabled the company to establish a “new normal” in data integration, data management, and data analytics. Apna has created a fast, easy to use, easy to manage, efficient, and affordable architecture, on which they can now innovate further.
The company now has their eye on new goals such as an enhanced job recommendation engine that supports multiple overlapping objectives, a community feed powered by deep learning algorithms, and data democratization with enhanced transparency and greater end-user control of data. Though still young, Apna has established a benchmark for the deft use of technology to achieve its business goals and raise its standards for data management.
Get started with Confluent and Onehouse
Interested in bringing the benefits of Confluent Cloud and Onehouse to your business? Start your free trial of Confluent Cloud today. New signups receive $400 to spend during their first 30 days.
You can also schedule a test-drive of Onehouse. You will receive $1,000 in free credit for use in your first 30 days.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



How Apna, Glance, & Meesho Are Innovating with Data Streaming For Consumers in India
What do Apna, India’s largest hiring platform currently connecting 40 million job seekers to 445,000 employers across 174 cities, Meesho, India’s fastest ecommerce platform to cross one million registered sellers, and Glance, InMobi-owned live lock screen infotainment...


{kind=link}
{kind=link}
{kind=link}

From 1 to 1 Million: How Agent Taskflow Built a Scalable AI Future with AWS and Confluent
Agent Taskflow built a multi‑agent AI platform on Confluent Cloud and AWS that can scale from one to one million agents with sub‑30ms latency. This post breaks down their architecture, benchmark results, and why an event‑driven backbone is critical for production agentic AI.