New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Building Kafka Storage That’s 10x More Scalable and Performant
As part of our series walking through how we built Confluent Cloud into a 10x better Apache Kafka® service, we explored how Confluent Cloud uses Intelligent Storage to achieve 10x better elasticity. Scaling up and down quickly was an important challenge for us to solve for both our customers and internal teams.
However, this wasn’t the only challenge we solved with our intelligent storage management. We originally set out to build a new storage architecture to solve some very real operational customer pain points, to name just a few:
- Constantly throttling tenants to monitor storage limits, and expiring data for clusters that reach capacity
- Operators constantly balancing storage and throughput across tenants, while making sure every dollar put into capacity is actually used
- Negotiating retention times with application teams to maintain cluster uptime and save costs
Over the last few years, the Engineering team at Confluent has worked hard to address these challenges. What really surprised us was the ways our users started evolving their use of Kafka once storage no longer was an operational concern. We saw Confluent Cloud become a source of truth for businesses, with historical and real-time data used to power new apps, experiences, and analytics.
In this blog post, we’ll share a deeper look into what goes into making Confluent Cloud storage 10x more scalable and performant than Apache Kafka. We’ll then show you what you can do when you use Confluent to make Kafka the source of truth for your business.
Infinite Storage: Never worry about Kafka storage again
Retaining the right amount of data in Kafka is operationally complex and expensive. This is primarily because with Apache Kafka, storage and compute are tied together. There is a practical limit to how much you can store on a single Apache Kafka broker. Once that limit is hit, you have to provision additional brokers and pay for more resources than otherwise necessary. You also risk cluster downtime, data loss, and a possible breach in data retention compliance.
Imagine we have a use case that requires us to produce at a sustained rate of 150 MB/s to a topic with the default 7-day retention. This means that by day seven, you would have about 90.7 TB of data or ~272 TB of data if replication is set to 3. In the image below, the area shaded in green represents the amount of throughput required to satisfy our requirements while the area in red represents the extra unused resources we’re getting by provisioning additional brokers to satisfy our storage requirements.
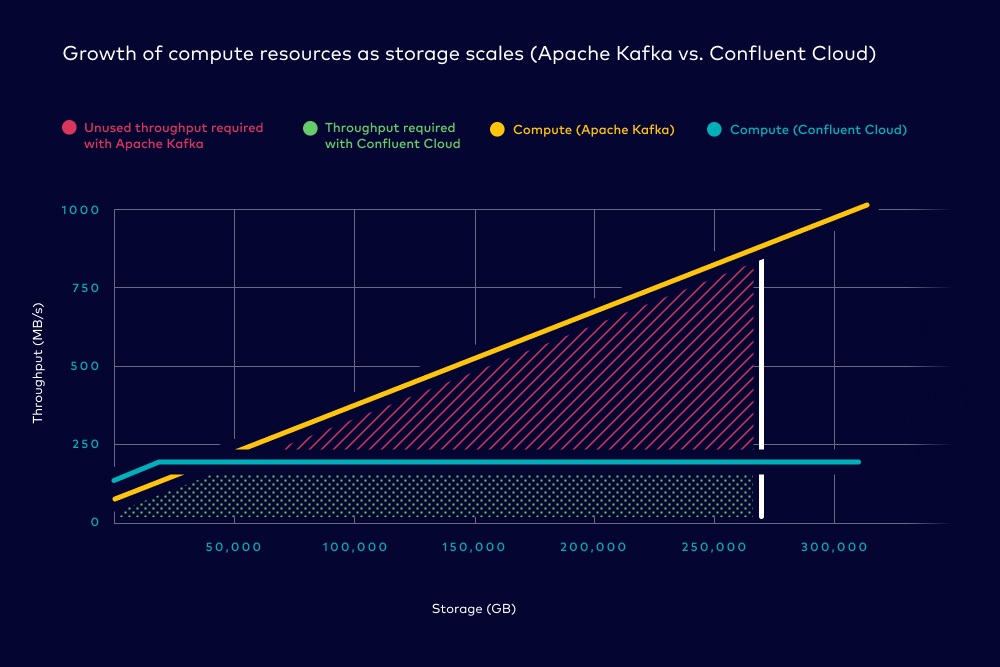
This is all to support requirements for a single use case. What if additional applications or use cases come online? It becomes the operators’ responsibility to distribute, limit, and balance throughput and storage between their internal tenants to avoid running out of storage capacity or throughput. This isn’t an easy task because it requires custom tooling and arbitration between the operators and developers which adds additional risk and complexity to the business.
To save our users from ever needing to think about storage constraints, we built Infinite Storage on Confluent Cloud. This new storage engine provides our users with a proper cloud consumption model that allows users to store as much data as they want, for as long as they need, while only paying for the storage used. Infinite Storage starts with the separation of compute and storage resources. This allows us to store a subset of “hot” data locally on the broker while offloading the majority of data to a respective cloud provider’s object storage tier.
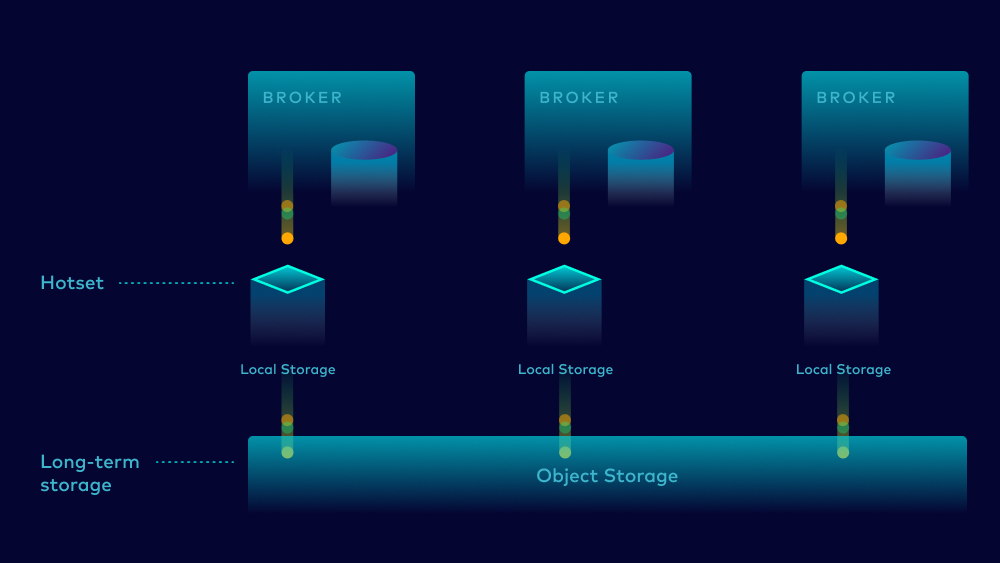
With Confluent’s Infinite Storage, storage grows automatically as you need it without limits on retention time. Operators never have to worry about throttling tenants or limiting use cases based on storage ever again. This is why we say Confluent Cloud scales your storage infinitely better than Apache Kafka (once again, our marketing friends are conservative with the 10x headline).
Storing 1 PB of data in Confluent: 10x faster and easier auto-scaling
The effects of Infinite Storage – everybody gets the storage they need, and they only pay for what they use
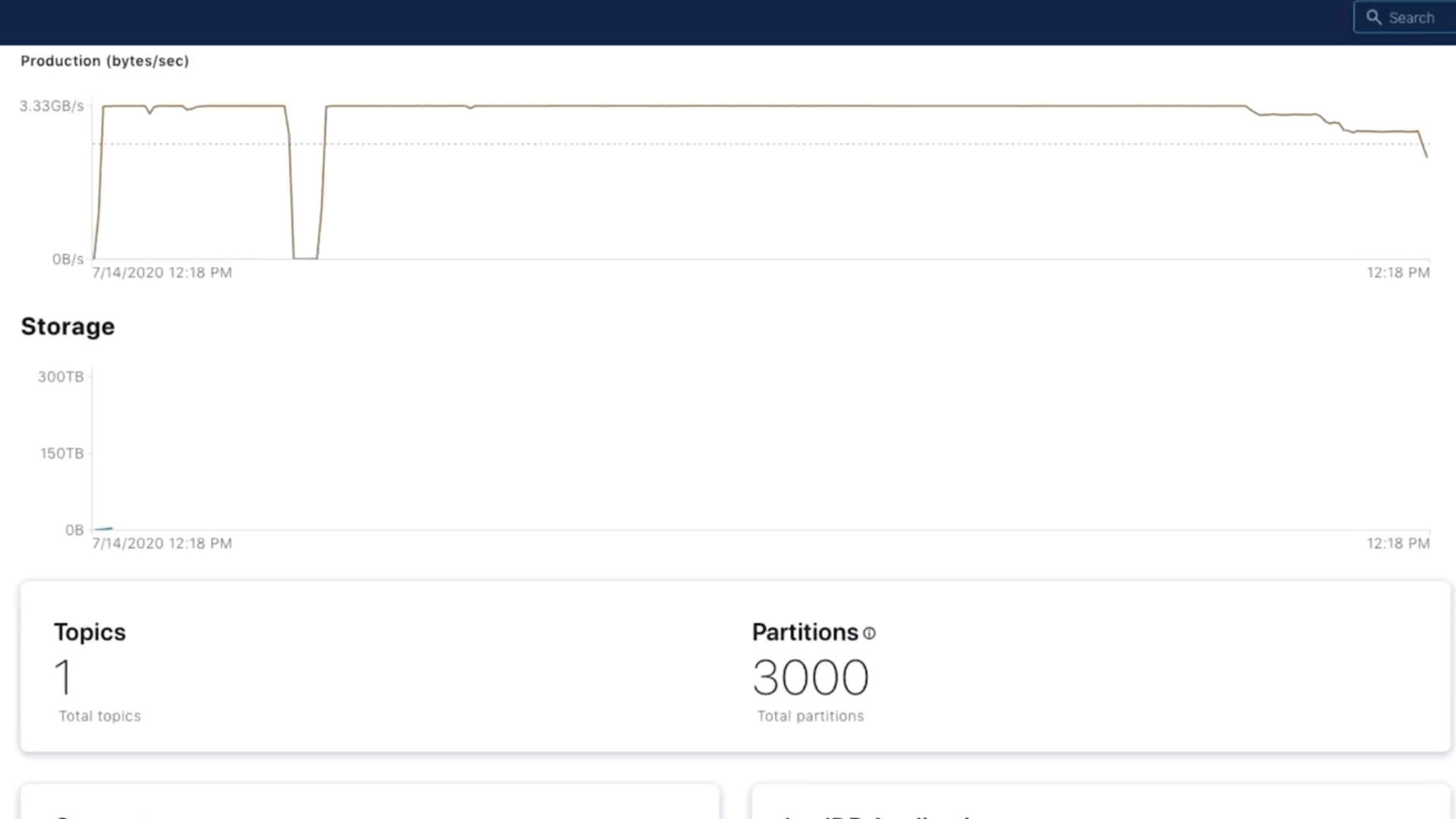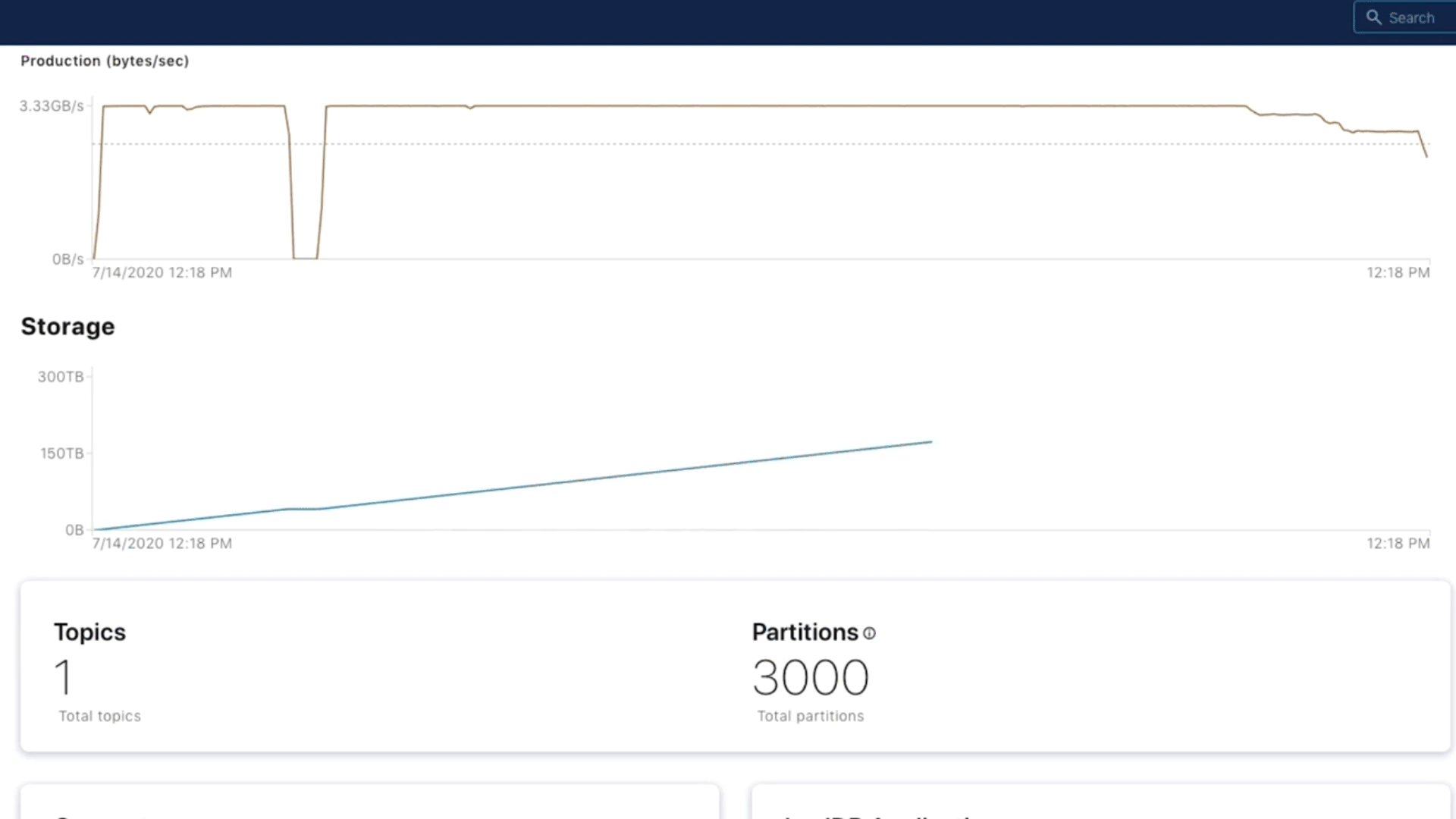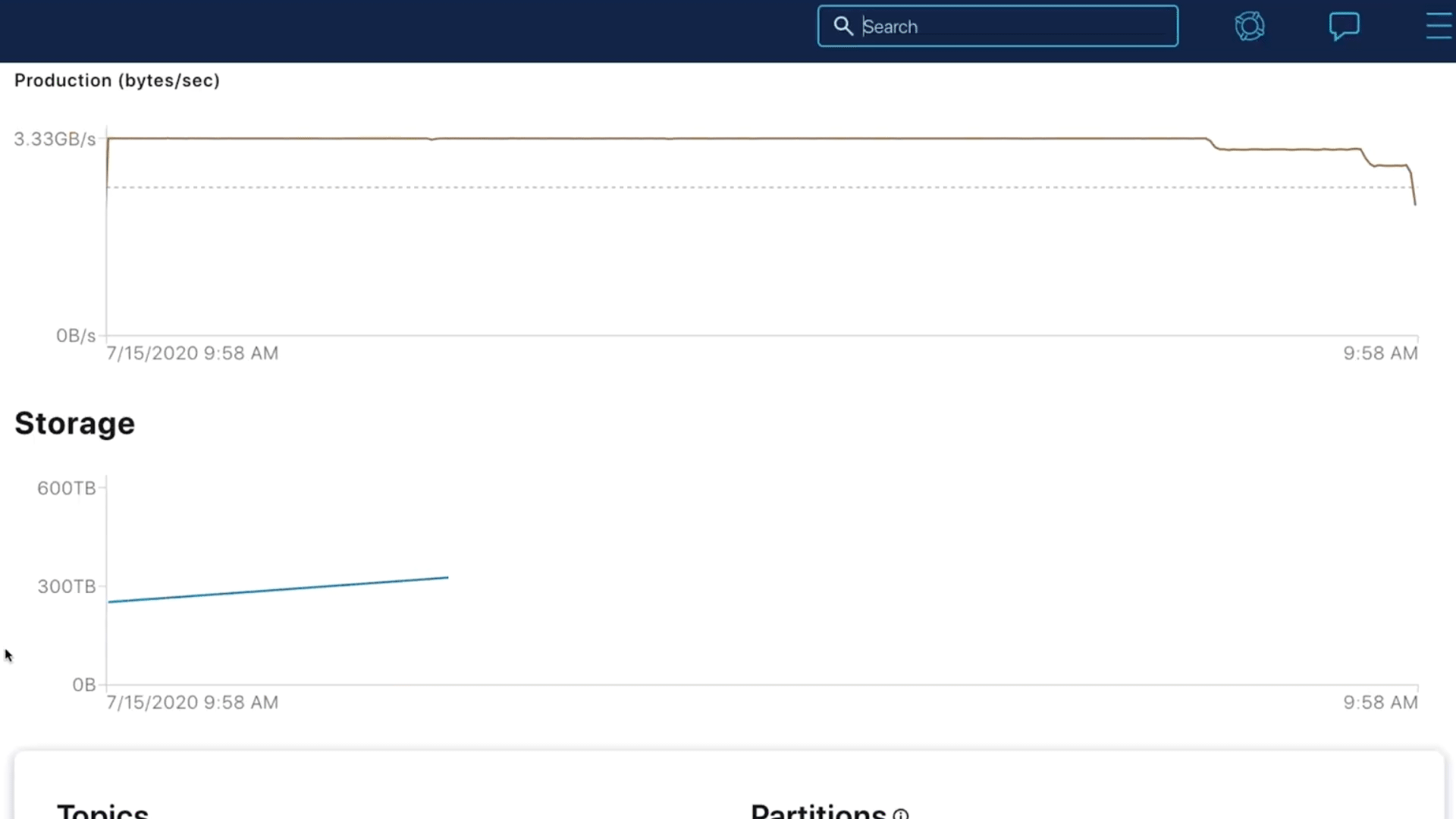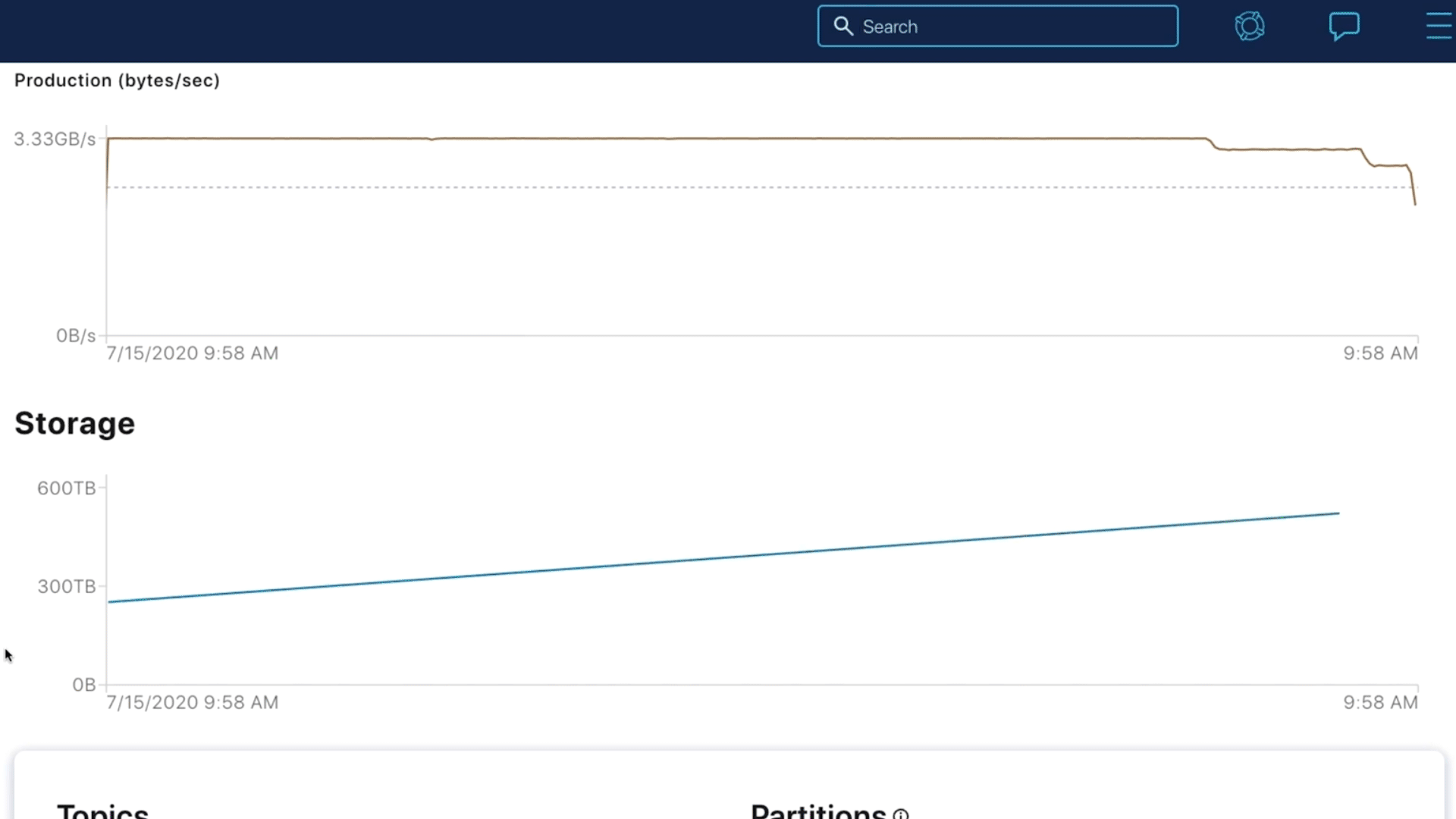
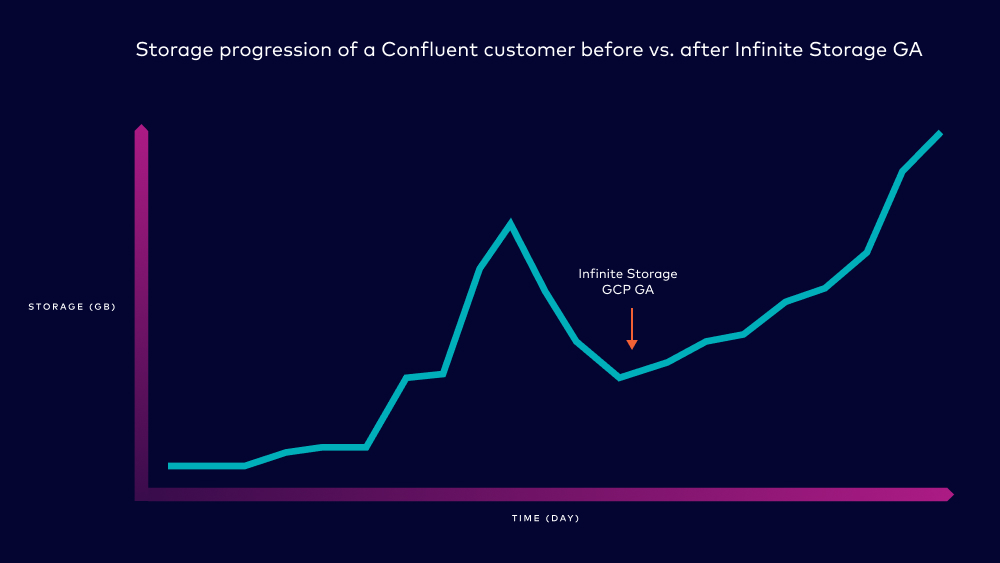
Once we released Infinite Storage, it was amazing to see how quickly our customers adopted it to address some of the operational challenges mentioned above. Let’s take a look at a real example from one of our customers. This customer previously had to work with some storage capacity constraint while launching additional tier 1 use cases. They were bumping up against capacity limits while their storage usage continued to grow (noted by the first spike in storage in the chart below). This forced them to set aggressive retention policies on the data to ensure they wouldn’t hit storage limits and experience downtime.
Once Infinite Storage was released on GCP, these challenges and limitations went away for them. They were able to increase retention across a variety of topics again without having to worry about capacity issues. Because of the cloud consumption model, they only had to pay for data retained, without having to over-provision and pay for any unused capacity. This helped relieve pressure on the operator teams managing storage while giving application teams the ability to consume data over longer periods of time.
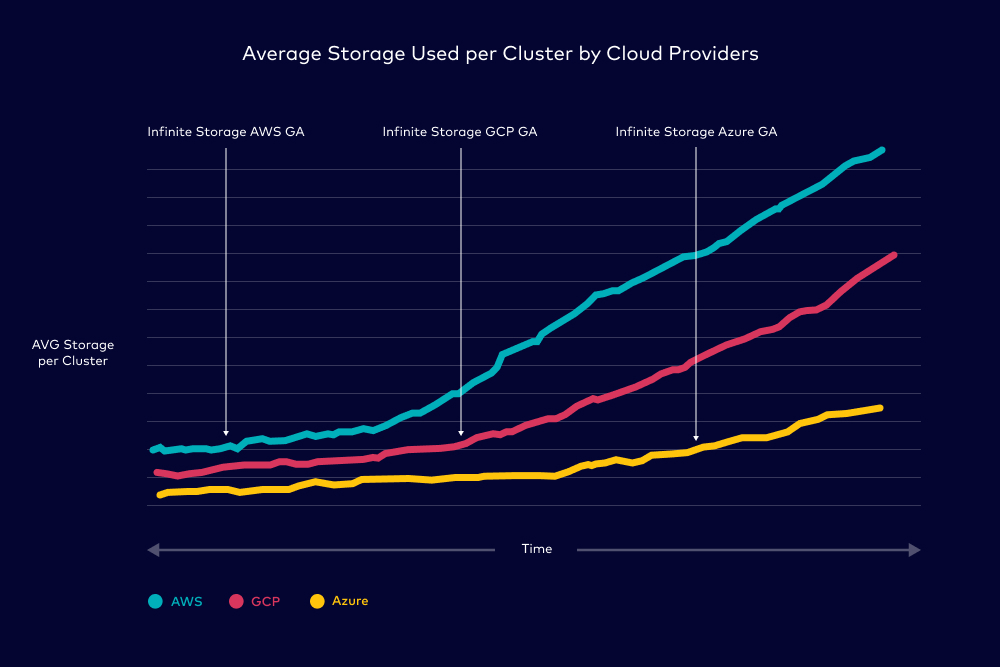
This is not an isolated incident either. We noticed that on average, users that have access to Infinite Storage end up storing 5x more data than users without it. The chart below shows the average storage per cluster over time. Once Infinite Storage was released for a respective cloud provider, we saw dramatic increases in the amount of storage users use per cluster. Infinite Storage is now generally available on all three major cloud providers, so store away!
Enabling interesting use cases when everybody gets the storage they need
Having the ability to store data infinitely is great but users aren’t doing it just for fun (Ok, maybe some are). With the operational concerns out of the way, Confluent Cloud users can divert their engineering time and resources to focusing on some really interesting and important use cases.
Confluent Cloud as a source of truth
Companies have started adopting Apache Kafka as a system of record as they make their transition into an event streaming world. This is because Kafka is often the first place data lands while being an immutable log of ordered events. This is what enables it to be that original source of truth.
One of the main challenges with using Apache Kafka as a source of truth has always been the operational burdens of managing storage. Data loss from consumer lag before consumers have a chance to consume the data can be a very real problem when aggressive retentions are set — the value comes from providing a persistent and authoritative view of the data that any user or system can immediately access. This is why with no retention limits, and immutable, ordered data, Infinite Storage has become a critical part in accelerating Confluent Cloud as a source of truth.
Powering apps and analytics with real-time and historical data
With Confluent Cloud as a source of truth, businesses have access to real-time and historical events from any time period. This powers all sorts of use cases—from day-to-day operations, to customer-facing apps, all the way to powerful transformational experiences:
- Event sourcing: The New York Times does this for all their article data as the heart of their CMS to power search engines, feed generators, websites, and more that need access to published content. Event sourcing becomes operationally complex when having to constantly monitor storage and expand capacity to accommodate a constantly growing business and dataset.
- Machine learning/personalization/advanced analytics: Being able to efficiently store data for long periods of time means it’s easier to combine both real-time and historical data for various analytical purposes. For example, a ridesharing application powered by ML needs both real-time traffic as well as historical arrival estimates.
- Stream processing with historical data: Infinite Storage allows developers to spend less time and effort rebuilding history from various systems. This is traditionally done via “reverse ETL”—the requirement to extract reload data from various downstream sources and stitch it back together. It is very complicated and time consuming to get batch dumps of data from various sources to recreate your stream processing state every time your logic changes. By having complete data sets in stream form you can just rewind your consumers and reprocess.
Data retention to meet compliance requirements
Infinite Storage with Confluent Cloud also ensures companies meet regulatory requirements for data retention. For example, financial institutions are required to retain data for seven years. During audits, it’s common that companies create a new application just to surface data from this time period. It’s infinitely more simple to read this data from an existing Apache Kafka log than having to reload data from various data sources.
Using Infinite Storage while getting even better performance
Just enabling storage retention time to infinite is not enough. In Apache Kafka, mixing consumers that read both real-time (latest) and historical (earliest) data can cause a lot of strain on the IO system, slowing down throughput and increasing latency. One of the great performance wins with Infinite Storage is the resource isolation that happens between these reads. “Real-time” consumers consume data from local storage, meaning this will continue to use the local IO system. “Historical” consumers read from object storage, meaning they rely on network which consumes a separate resource pool than real-time consumers. This means that large batch reads that you typically see with historical workloads do not compete with the streaming nature of real-time workloads, preventing latency spikes and improving throughput.
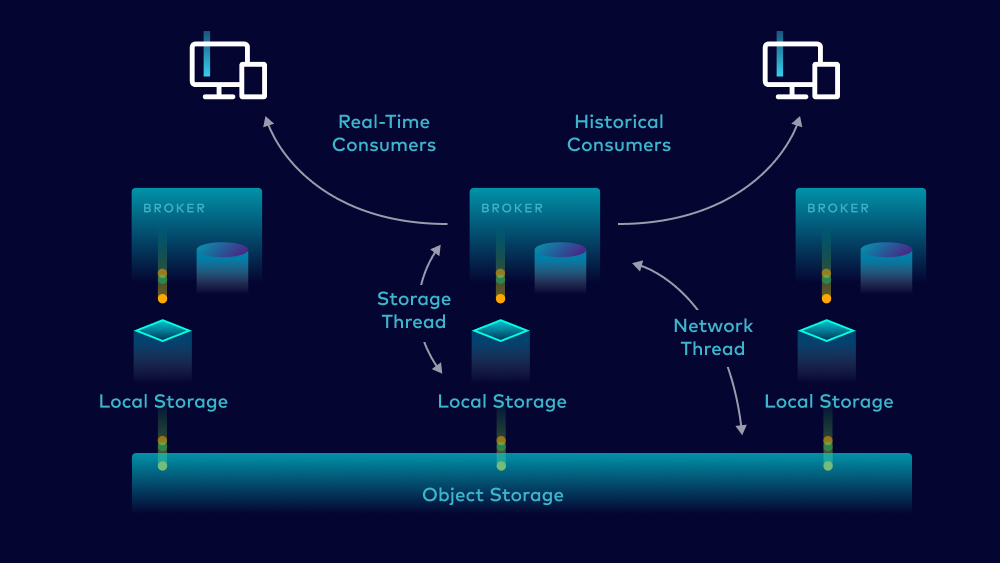
Big architectural changes aren’t the only areas we’re able to continue to improve on performance. For example, we optimized performance for each cloud provider’s unique characteristics. We’ve also improved Confluent Cloud’s write path to better handle intermittent latency spikes from storage failover, and improved the replication fetch path. We’ve also tuned many lower-level parameters such as page cache, readahead, and much more.
Conclusion
We’ve made Confluent Cloud’s storage engine 10x (in many cases infinitely) more scalable and performant than Apache Kafka. What does that mean for you? Well, to recap, you can now:
- Never worry about Kafka storage limits again by setting infinite retention time at the topic level
- Pay only for the retained data, not for any pre-provisioned or unused storage capacity
- Save on unnecessary compute infra or any ops burdens as storage auto-scales 10x faster and easier
- Avoid downtime, data loss, and business risks by maintaining a persistent log of all events
Learn more from our customers about how storage with Confluent Cloud empowers their day-to-day jobs, or check out other areas where we’ve made Confluent a 10x better data streaming platform.
To give Confluent Cloud a go and try out our 10x better storage offering, sign up for a free trial. Use the code CL60BLOG for an additional $60 of free usage.*
More posts in this series
- Introduction from our CEO: Making an Apache Kafka Service 10x Better
- Elasticity: Making Confluent Cloud 10x More Elastic Than Apache Kafka
- Reliability: Leave Apache Kafka Reliability Worries Behind with Confluent Cloud’s 10x Resiliency
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.