[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Operational vs. Analytical Data: The Modern Data Divide
Practically every modern organization and business leader would claim to have data-driven decision-making, operations, customer service, and innovation. After all, data is the lifeblood of modern business.
But while many say that, in reality, actually putting data to use across the organizaiton–effectively, consistently, and efficiently—is often hampered by a fundamental divide between operational and analytical data estates. While both are crucial for business function, their inherent differences in purpose, structure, and access patterns introduce significant challenges to readily ingesting, moving, and acting on data the way that modern business and customer expectations demand.
This guide explores the two data estates, the traditional approaches to bridging them with extract-transform-load (ETL) pipelines, and the emerging strategies designed to use Apache Kafka® every individual and system within an organization to handle and rely on data with confidence.
Comparing How the Operational Estate vs. Analytical Estate Operates
Businesses fundamentally operate on two distinct data planes: the operational and the analytical. Traditionally, these planes have existed in silos, requiring complex and often brittle methods to transfer information between them. This separation, while initially serving specific purposes, has led to a landscape where data access for analytical insights is frequently enabled by cumbersome ETL pipelines, introducing a host of challenges that hinder data reliability and timely access.
Before we dive deeper, let’s go over some fundamental definitions and concepts.
What Is Operational Data (OLTP)?
Operational data is the information generated and used by an organization's day-to-day business activities. It's the real-time, granular data that drives transactions and supports immediate business processes. This includes data captured directly from applications, microservices, and event streams, often coordinated by real-time streaming engines like Kafka. Think of the immediate data generated when a customer places an order, a payment is processed, or inventory levels are updated.
At the core of the operational estate are operational databases, which are typically Online Transaction Processing (OLTP) systems. These databases are highly optimized for fast, frequent, and small transactions, such as inserts, updates, and deletes. They prioritize data integrity, concurrency, and immediate availability for specific, well-defined business use cases.
What Is Analytical Data (OLAP)?
In contrast, analytical data is derived from operational data (often ingested via systems like Kafka) and other sources, specifically structured and optimized for complex queries, reporting, and strategic decision-making. This transformation and aggregation might be performed by powerful stream processing tools like Apache Flink®. It's the aggregated, historical, and often summarized information used to understand business performance, identify trends, and forecast future outcomes.
The central repository for analytical data is often an analytical data warehouse (or data lake or lakehouse). These systems are typically Online Analytical Processing (OLAP) systems, designed for efficient querying and analysis of large volumes of historical data. They prioritize query performance for complex analytical tasks over real-time transaction processing.
The Operational vs. Analytical Estates: A Side by Side Comparison
The distinction between operational and analytical data goes beyond their storage location—it permeates their very nature and purpose. Understanding these differences is crucial for designing effective data strategies that leverage the strengths of both.
Here's a side-by-side comparison summarizing the key differences:
|
Feature |
Operational Data |
Analytical Data |
|---|---|---|
|
Purpose |
Support daily business operations & transactions |
Strategic decision-making, reporting, analysis |
|
Data Type |
Current, real-time, detailed, often volatile |
Historical, aggregated, summarized, stable |
|
Volume |
Moderate to High |
Very High |
|
Latency |
Low (immediate processing) |
High (batch processing, often delayed) |
|
Updates |
Frequent reads, writes, updates, deletes |
Less frequent updates, primarily reads |
|
Data Model |
Normalized, relational (e.g., Third Normal Form) |
Denormalized, dimensional (e.g., Star/Snowflake) |
|
Workload |
OLTP (Online Transaction Processing) |
OLAP (Online Analytical Processing) |
|
Key Metrics |
Transaction speed, data consistency |
Query performance, data accuracy for insights |
|
Typical Systems |
MySQL, PostgreSQL, Oracle DB, SQL Server, NoSQL |
Data Warehouses (Snowflake, Redshift, BigQuery), Data Lakes (S3, ADLS, Databricks), Apache Hive, Spark |
Why Solving the Operational-Analytical Divide Matters
The distinction between operational and analytical data matters immensely because attempting to use one system for both purposes often leads to compromises in performance, scalability, and data integrity.
Operational systems cannot efficiently handle the complex, resource-intensive queries of analytics without impacting real-time transactions. Conversely, analytical systems are not designed for the rapid, granular updates required by operational processes. Recognizing and strategically addressing this divide is the first step toward building a truly data-driven organization.
Challenges Integrating Data With ETL/ELT Pipelines
Within an enterprise, data encompasses various forms. While operational and analytical are broad categories, a more granular view includes:
-
Transactional Data: Records of business events (e.g., sales, payments, logins).
-
Master Data: Core business entities (e.g., customers, products, locations).
-
Reference Data: Static data used for classification or lookup (e.g., country codes, units of measure).
-
Metadata: Data about data (e.g., schema definitions, data lineage).
-
Unstructured Data: Free-form text, images, audio, video.
-
Semi-Structured Data: Data with some organizational properties but not strictly tabular (e.g., JSON, XML).
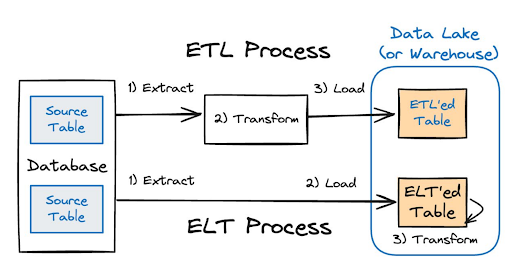
The inherent divide between the operational and analytical planes often necessitates complex data integration strategies for this vast variety of data formats. Traditionally, both ETL and ELT (extract-load-transform) pipelines have served as the primary means to bridge this gap, moving data from source operational systems into analytical environments. However, this approach, while common, introduces a host of challenges, including introducing bad data in event streams that feed a host of downstream systems
ETL pipelines are notoriously brittle, expensive, and demand constant maintenance. Analytics engineers are typically responsible for reaching into the OLTP database to extract the necessary data, transform it for analytical purposes, and then load it into the data lake or warehouse. The significant issue here is a fundamental disconnect: the owners of these pipelines in the analytics domain have minimal control or involvement over the source data model, which remains under the purview of the application developers in the operational domain.
Read the Full eBook | Read Blog
Comparing Solutions to the Operational-Analytical Divide
Addressing the operational-analytical divide and the limitations of traditional ETL/ELT approaches has led to the evolution of several architectural patterns. Each aims to improve data flow, quality, and accessibility, though with varying degrees of success and different trade-offs.
Multi-Hop Data Architecture
A multi-hop data architecture describes systems where data undergoes multiple processing stages and copies before reaching its final, usable form for a specific business use case. Data often flows from raw ingestion to increasingly refined layers. While this provides a structured approach to data transformation, it is inherently inefficient due to the repeated copying, processing overhead, and potential for increased latency at each "hop."
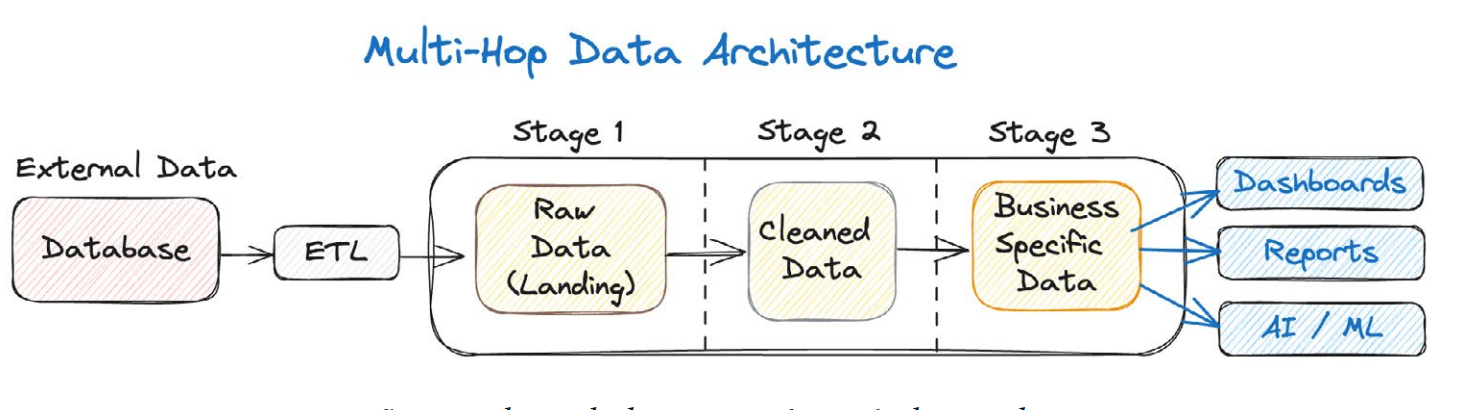
Data flowing through the stages of a multi-hop architecture
Medallion Architecture
The medallion architecture is a specific and popular implementation of a multi-hop data architecture, formalizing the stages into three distinct layers:
-
Bronze Layer: The landing zone for raw, untransformed data, often a direct mirror of the source. It captures data as it arrives, without significant cleaning or structuring.
-
Silver Layer: This layer stores filtered, cleaned, standardized, and modeled data. It represents a "minimally acceptable" level of quality, suitable for core analytics and as building blocks for more advanced models.
-
Gold Layer: Contains highly curated, aggregated, and purpose-built datasets optimized for specific business applications, reports, dashboards, and AI/ML models.
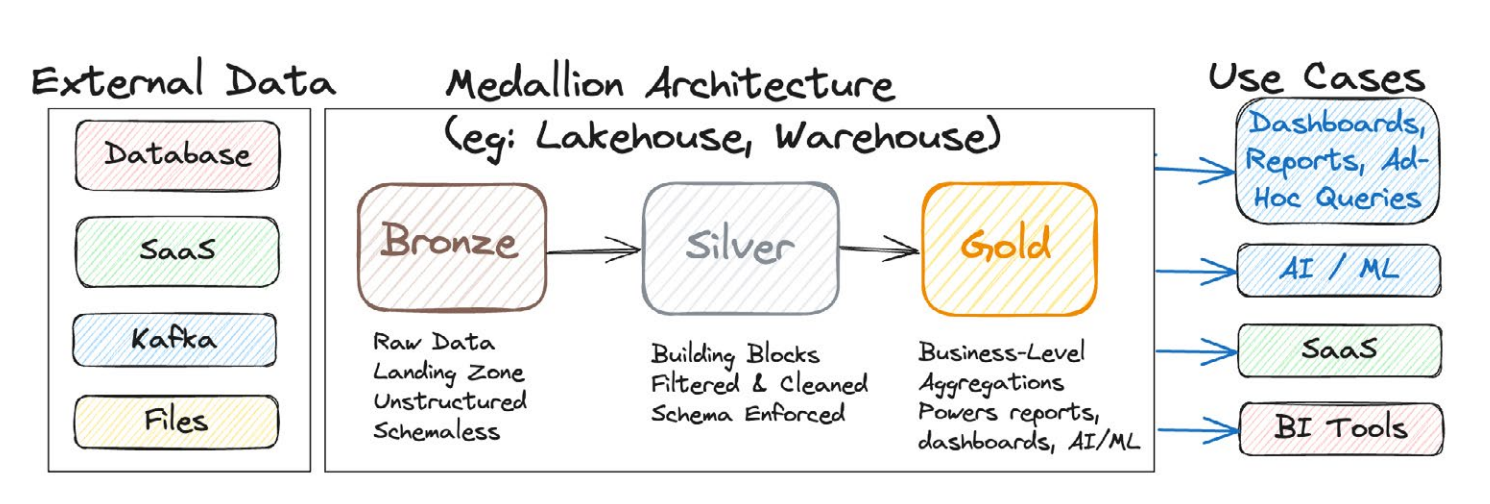
The medallion architecture, a popular version of the multi-hop architecture
While the medallion architecture brings order to data processing within a data lake or warehouse, it still typically relies on copying data between layers and often leaves the high-quality data in the silver layer "locked away" from operational systems that could benefit from it.
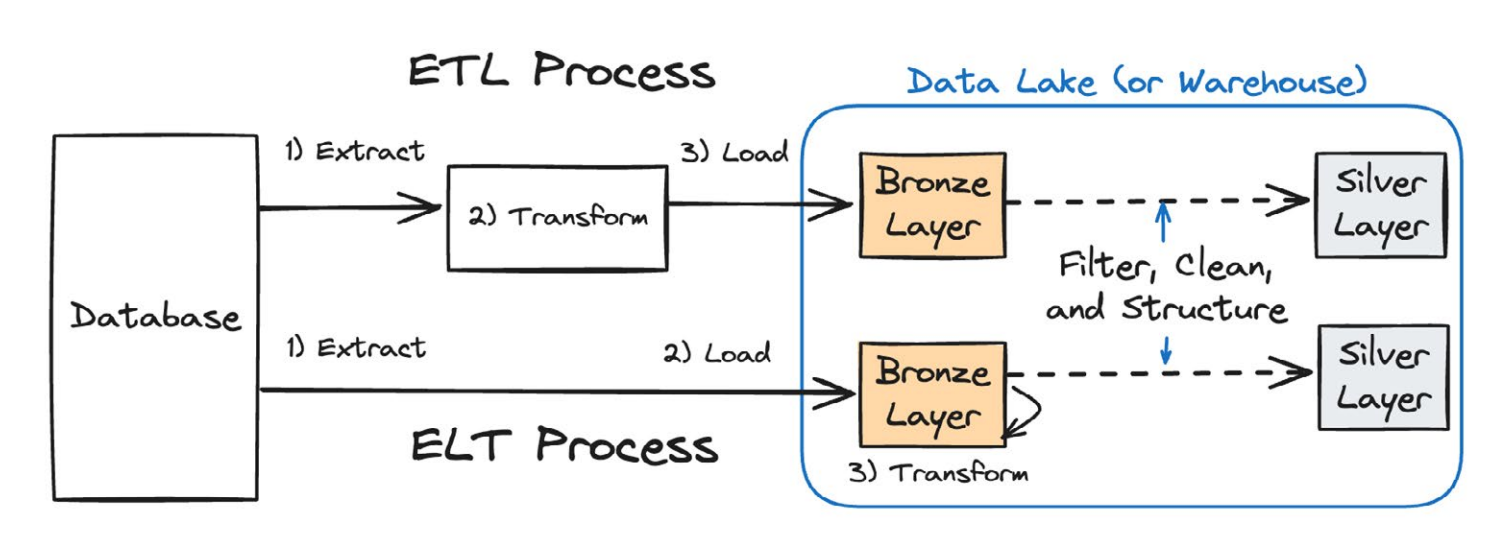
How data retrieved via ETL or ELT processes reach the silver layer in the medallion architecture
Headless Data Architecture
The headless data architecture (HDA) represents a significant shift, emphasizing the decoupling of data storage and management from the applications and services that consume and process it. The core idea is to process and govern data as close to the source as possible (referred to as "shifting left"), making it available as a well-defined data product that can be accessed by any system, whether operational or analytical, as a stream or a table, without additional copying or redundant transformations.
Key technologies that enable HDA include:
- Data Streaming Platforms (DSPs): Combining data streaming, integration, governance, and stream processing, which allows organizations to decouple data producers from consumers while enabling real-time data flow and self-service discovery.
- Open Table Formats: Like Apache Iceberg™ and Delta Lake tables, which provide robust table management over object storage, offering transactional guarantees, schema evolution, and time-travel capabilities for data accessed as tables.
- HDA allows for a "write once, plug in anywhere" model, providing consistent, reliable, and timely access to a single source of truth.
5 Issues Driving Demand for Headless Data Architecture
Batch-oriented ETLs inherently introduce latency, making them unsuitable for real-time analytical or operational use cases that demand immediate access to fresh data. But there are other, fundamental issues with mutli-hop data architectures that lead to higher maintenance burden for data platform teams, delayed results, data duplication and inconsistency, and ultimately unhappy customers.
As a result, the limitations of traditional approaches and the increasing demands of modern data ecosystems are accelerating the shift towards architectures like HDA. Here are five key issues driving this demand:
-
Consumers take responsibility for data access: Traditional models burden downstream consumers (e.g., data analysts) with the responsibility of extracting, integrating, and cleaning data from disparate sources. This is inefficient and reactive, as consumers lack ownership or influence over source data models, leading to brittle pipelines and constant breakages.
-
Medallion architectures are expensive: The multi-copy nature of medallion and similar architectures leads to excessive storage, network, and compute costs. The "build your own pipe" mentality further exacerbates this, resulting in duplicate efforts and fragmented data discovery. Outages and reprocessing are also costly due to the cascading dependencies.
-
Once lost, restoring data quality is difficult: When data is transformed multiple times downstream by teams unfamiliar with the source domain, restoring its original fidelity and ensuring accuracy becomes extremely challenging. This can lead to "similar-yet-different" datasets, eroding trust and causing misinformed decisions.
-
The Bronze layer is fragile: As the foundation of multi-hop architectures, the bronze layer, reliant on brittle ETLs and poorly aligned responsibilities, makes the entire analytical edifice fragile. Breakages at this initial stage ripple throughout the system, leading to delays and unreliable downstream data, which quickly erodes customer trust.
-
Operational workloads have poor data reusability: Data processed for analytical purposes in data lakes/warehouses often remains trapped in that realm, primarily available via slow batch jobs. Operational systems, which increasingly need access to the same high-quality, processed data for real-time use cases, are forced to build their own separate integration and transformation logic, creating further fragmentation and duplication.
With a batch-based approach, any evolution or change in the operational application space can, and frequently does, cause data pipelines to break. This results in extensive "break-fix" work for data engineers, diverting their time from more valuable tasks. The lack of tight integration and control can lead to "bad data" seeping into analytical systems, eroding trust in insights. And pipeline failures lead to delays in data availability for analytics, impacting decision-making.
Having independent, duplicative pipelines often results in multiple copies of similar-yet-slightly-different datasets, leading to data sprawl, increased storage costs, and conflicting versions of "truth." This leads to a number of poor and avoidable outcomes, like:
-
ETL jobs querying source databases can consume significant compute resources, potentially degrading the performance of live production operational systems.
-
Business users reliant on data for reporting and operations experience frustration due to delays and data inconsistencies.
That’s where shift-left integration comes in.
Shifting Left to Solve the Operational-Analytical Divide
The shift-left strategy is the core principle behind the headless data architecture. It means taking the work of data extraction, transformation, cleaning, and modeling—traditionally done downstream in the analytics plane—and moving it upstream, as close to the data source as possible.
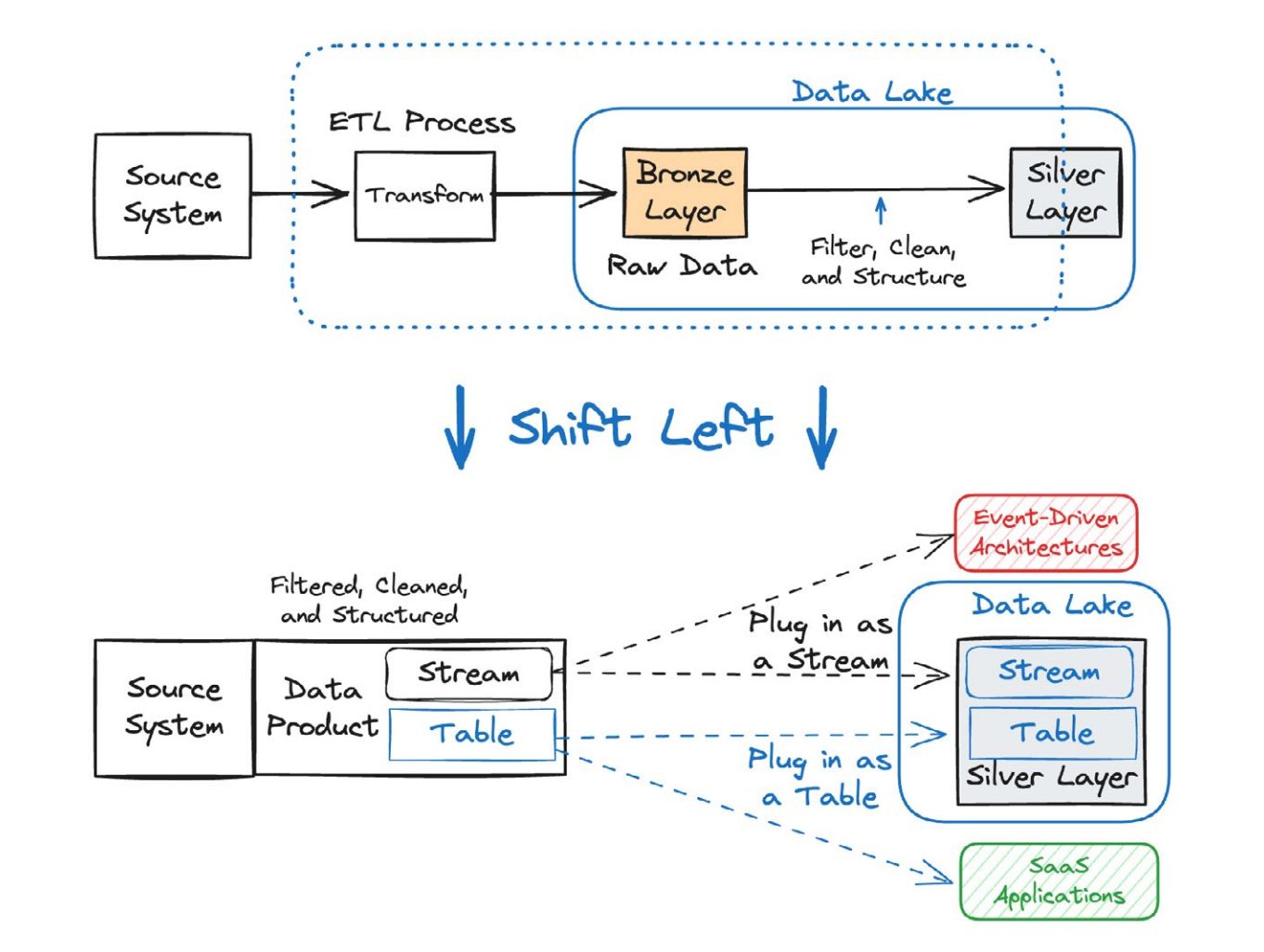
By embedding data governance and quality processes earlier in the data life cycle, organizations can use a data streaming platform to publish a single, well-defined, and well-formatted data product. This ensures consistency, reliability, and timeliness for all downstream consumers, whether they are operational services, analytical tools, or AI models, effectively unifying the traditionally separate data planes.
Next Steps for Bridging Your Organization’s Operational-Analytical Divide
The divide between operational and analytical data has long presented a significant hurdle for enterprises seeking to become truly data-driven. While traditional ETL/ELT and multi-hop architectures like the medallion pattern offered solutions, they introduced new complexities, costs, and fragilities. The emergent headless data architecture, powered by principles like shift-left data integration and technologies such as data streaming platforms and open table formats, offers a compelling path forward.
By embracing these principles and technologies, organizations can move beyond the persistent data divide, enabling a future where data is truly a unified, accessible, and trusted asset for everyone. Take these next steps to get started:
-
Understanding Your Data Landscape: Identify your most critical operational data sources and their primary consumers (both operational and analytical).
-
Pilot a Shift-Left Approach: Start with a few key datasets. Instead of building another ETL to a data lake, explore how to process and publish that data as a shareable data product at the source.
-
Explore Data Streaming and Open Table Formats: Investigate how Kafka and Flink can serve as foundational components for building versatile data products that can be used to generate analytics tables with clean, trustworthy, unified data. Confluent’s complete data streaming platform allows you to not only stream data and process Kafka topics with Flink SQL, but it also offers Tableflow—allowing you to materialize integrated, governed & processed data streams as Iceberg tables and Delta Lake tables (Open Preview).
-
Foster Collaboration With Data Contracts: Encourage collaboration between operational application teams and data analytics teams to align on data models and ownership, a crucial social component of shifting left.