Introducing Stream Designer: The Visual Builder for Streaming Data Pipelines
Data pipelines are critical to the modern, data-driven business, connecting a network of data systems and applications to power both operational and analytical use cases. With the need to promptly and immediately act on real-time insights in a digital-first world, companies have turned to Apache Kafka® to build streaming data pipelines that replace legacy, batch-based pipelines.
Today, we’re excited to introduce Stream Designer, the industry’s first visual interface for rapidly building, testing, and deploying streaming data pipelines natively on Kafka. You can start building pipelines in minutes from a unified view in Confluent Cloud and take advantage of built-in integrations with fully managed connectors, ksqlDB, and Kafka topics. Stream Designer provides speed, simplicity, and flexibility, fitting into your existing DevOps practices and allowing you to seamlessly switch between the graphical canvas and full SQL editor. While you and your team might already be familiar with Kafka, we’ve built Stream Designer to not only boost your productivity, but also help developers across your organization get up and running with streaming faster.
Stream Designer is now generally available on Confluent Cloud.
Stream Designer will enable you to:
- Boost developer productivity by reducing the need to write boilerplate code
- Unlock a unified end-to-end view to update and maintain pipelines throughout their lifecycle
- Accelerate real-time initiatives with sharable and reusable pipelines on an open platform
How Stream Designer helps
Streaming data pipelines built on Kafka not only enable a real-time paradigm, but also set the foundation for fundamentally better pipelines, which includes decoupling data sources and sinks, continuous data processing, and triggering actions based on real-time events. The goal is an event-driven architecture where users and applications across the organization can access high-quality, real-time data streams.
However, there are still major challenges with trying to efficiently build reusable data pipelines with open-source Kafka on your own. We’ve heard many customers struggle with an over-reliance on specialized Kafka engineering talent to build these pipelines and custom integrations, limiting the number of teams that can leverage the power of data streaming. Moreover, even seasoned Kafka engineers need to spend cumbersome development cycles writing boilerplate code across multiple sub-frameworks – Kafka, Kafka Connect, and Kafka Streams. Without an easy way to reuse production-ready pipelines, teams spend duplicative efforts rebuilding pipelines across environments and similar use cases, increasing their overall total cost of ownership. These bottlenecks and inefficiencies limit the speed at which you can set data in motion across your entire organization.
Over the past several years, we’ve invested heavily at Confluent to address these challenges. We’ve built a robust ecosystem of pre-built connectors to free data silos and transform your entire data architecture into a real-time paradigm. We’ve also introduced ksqlDB, allowing users to easily leverage stream processing with simple SQL queries. Stream Designer takes us one step further to make building streaming data pipelines on Kafka even easier. Here’s a closer look.
Boost developer productivity
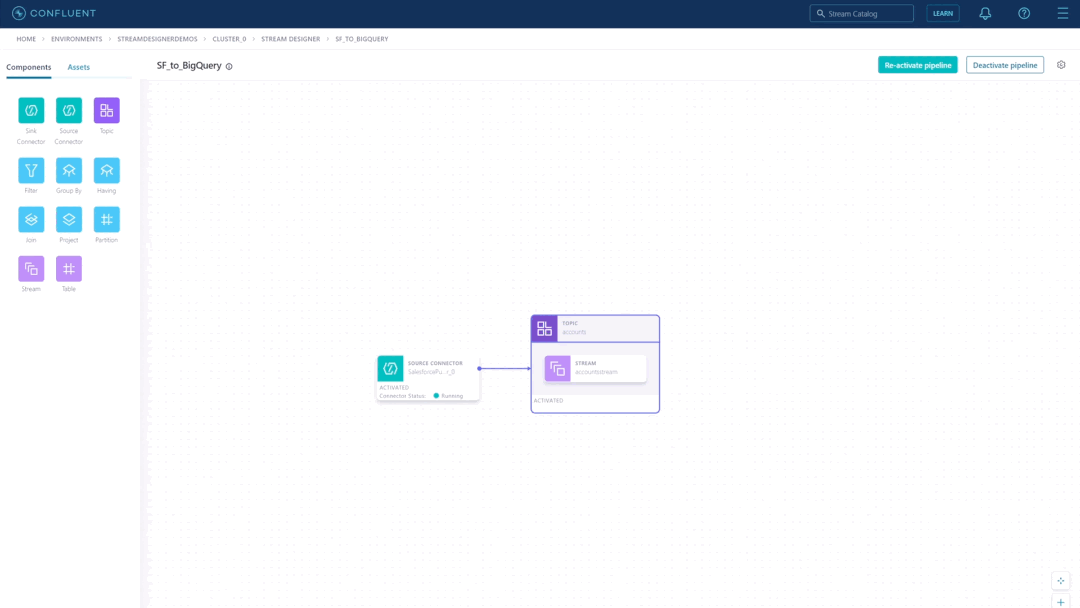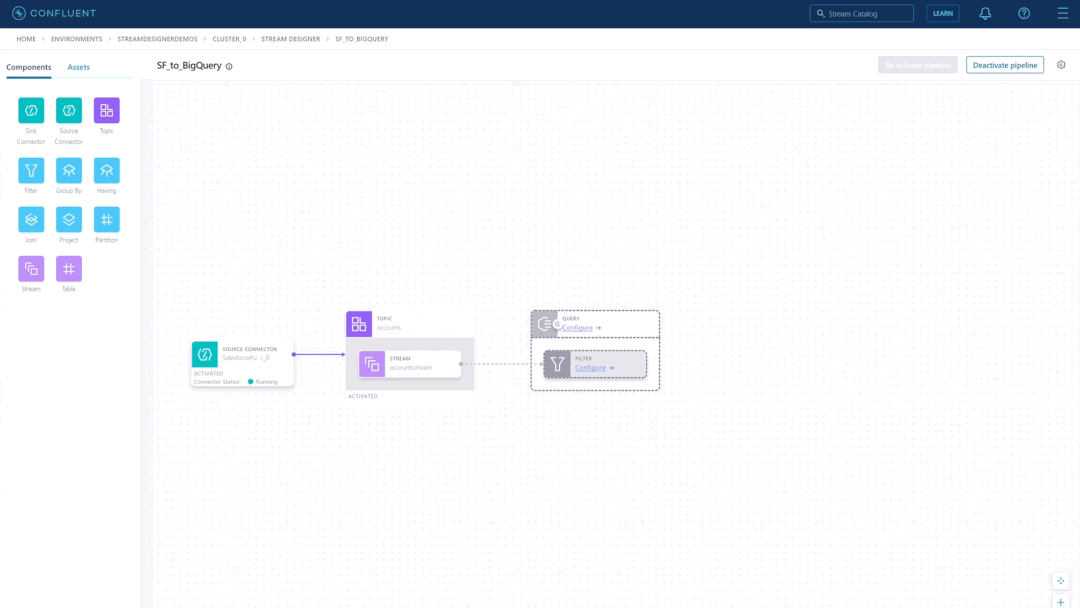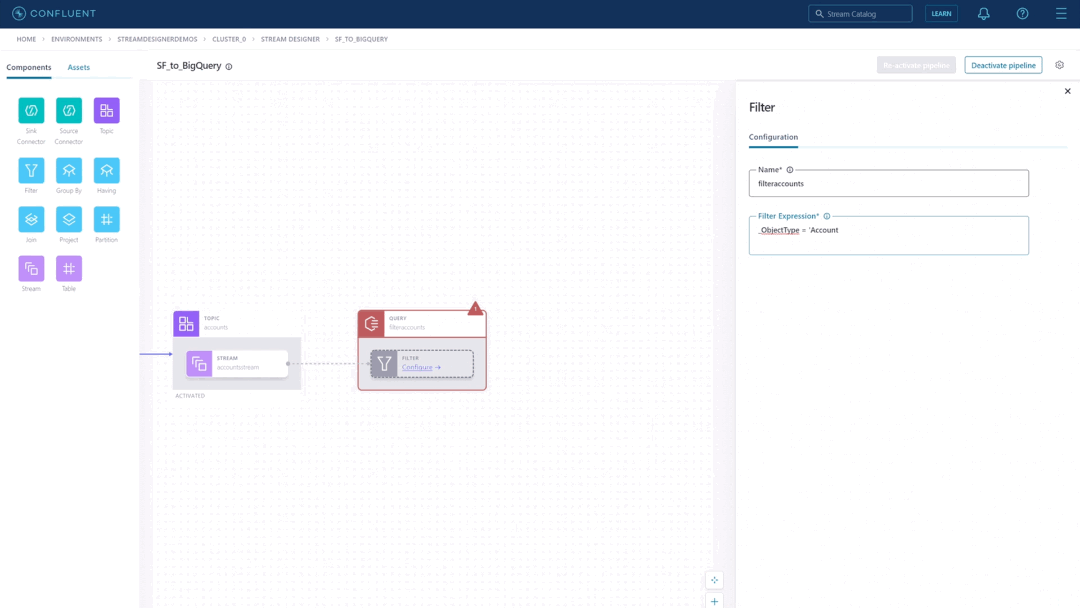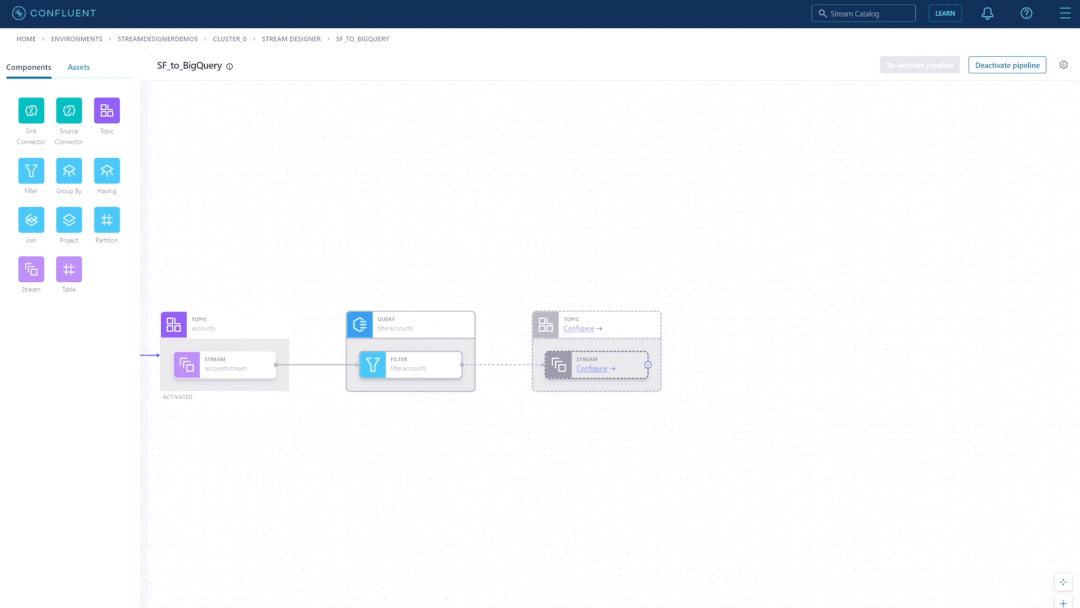
Build streaming data pipelines in minutes using a visual canvas
Stream Designer provides a graphical canvas for building pipelines natively on Kafka, with pipeline definitions translating to ksqlDB code (i.e., SQL queries) under the hood. Unlike other GUI-based interfaces, Stream Designer isn’t built on a proprietary runtime engine that can often become the bottleneck as your data volumes increase. This means you’ll continue to experience fully managed Kafka with no compromises, powered by the same latency and scalability benefits of Confluent Cloud. The visual UI offers you speed and simplicity as you build out pipeline logic, boosting your productivity by reducing the need to write boilerplate code and speeding you through rapid prototyping and iterations.
Leveraging stream processing, a key requirement for efficient and intelligent streaming data pipelines, has never been easier. While writing a few lines of SQL with ksqlDB is already much more accessible than using Java-based Kafka Streams, Stream Designer further simplifies this by translating common stream processing operations like filters, joins, and aggregates into pipeline building blocks you can drag and drop on the canvas. Then configure the fields with simple expressions instead of writing SQL code from scratch.
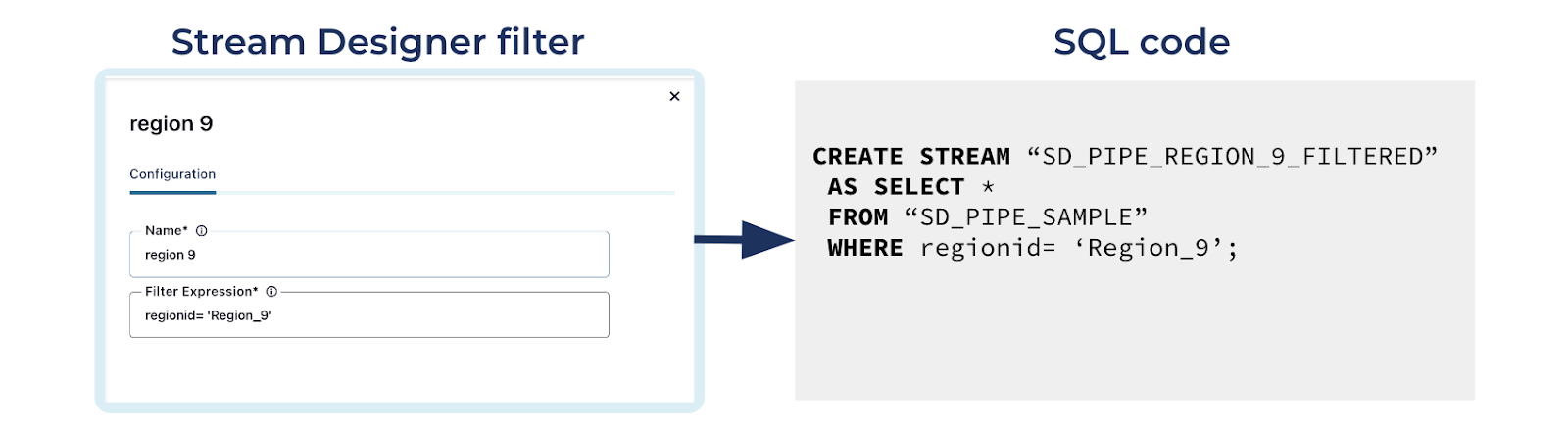
Example of a filter component on Stream Designer and its SQL equivalent
You’ll also be able to tap into Confluent’s ecosystem of 70+ fully managed connectors for data integration, as pipelines are only as useful as the data systems to which they connect. Instead of spending months building, testing, and maintaining custom connectors on Kafka Connect, you can quickly deploy our battle-tested connectors for popular databases, data warehouses, data lakes, SaaS apps, and more with just a few clicks. Single message transform capabilities are also supported on Stream Designer, so you can efficiently perform simple data transformations like masking a sensitive field on the fly within the connector using our built-in operations.
Unlock a unified view
After pipelines are built, the next challenge comes with updating them over their lifecycle as requirements and tech stacks evolve. To make this easy and avoid re-work, you can import existing ksqlDB pipelines into Stream Designer, which will yield an end-to-end view of even the most complex pipeline. You can then make any edits directly on the canvas, which will be kept in sync with the underlying code. Developers have the full flexibility to switch between the graphical canvas and built-in SQL editor when modifying pipelines, with changes seamlessly translated from UI to code and vice versa. You can also choose to manage pipelines programmatically using CLI commands.
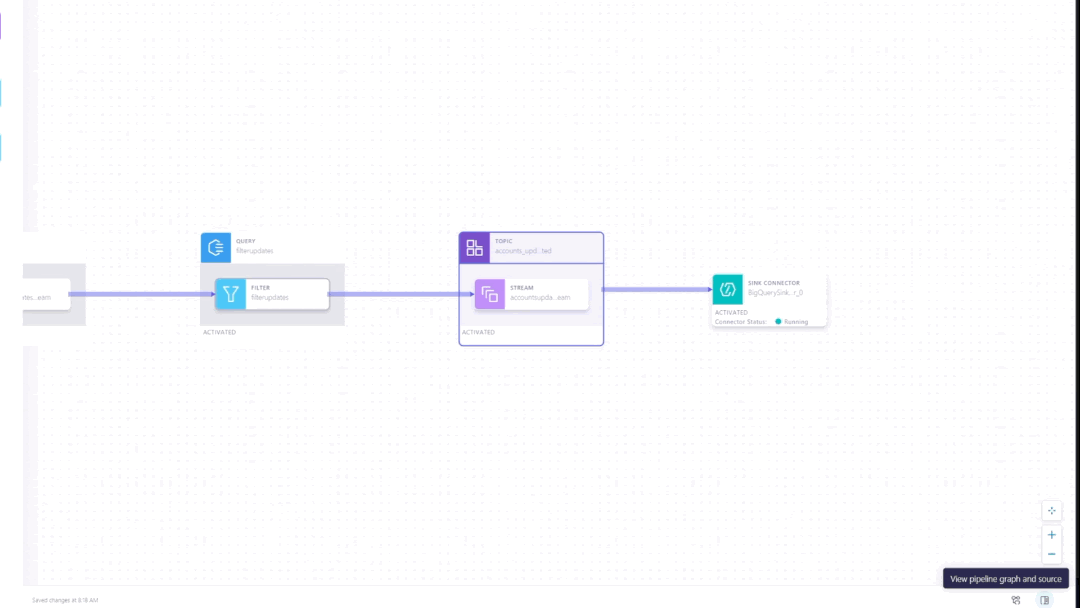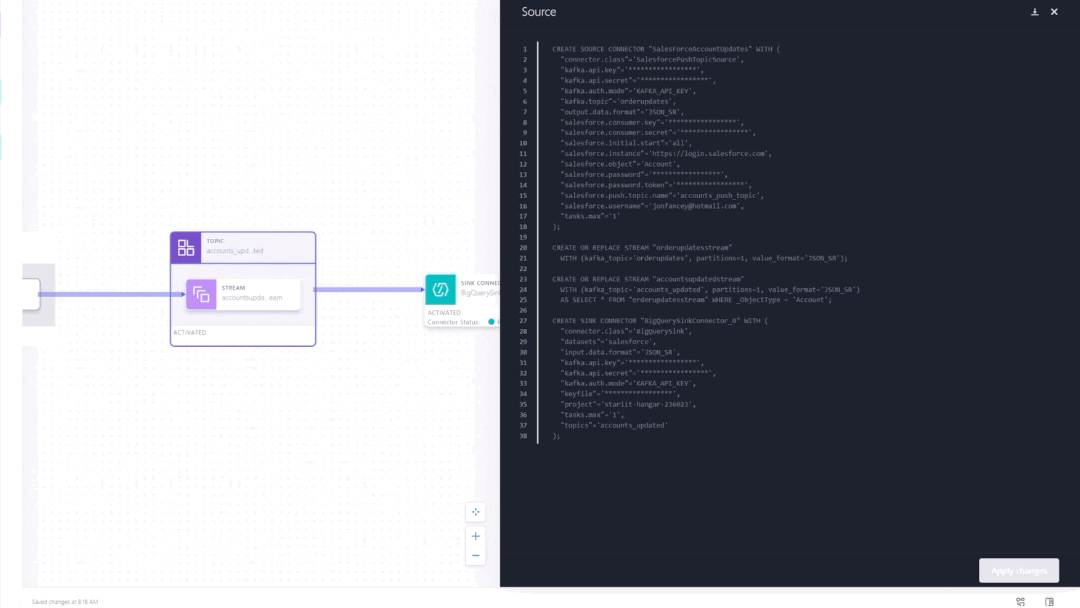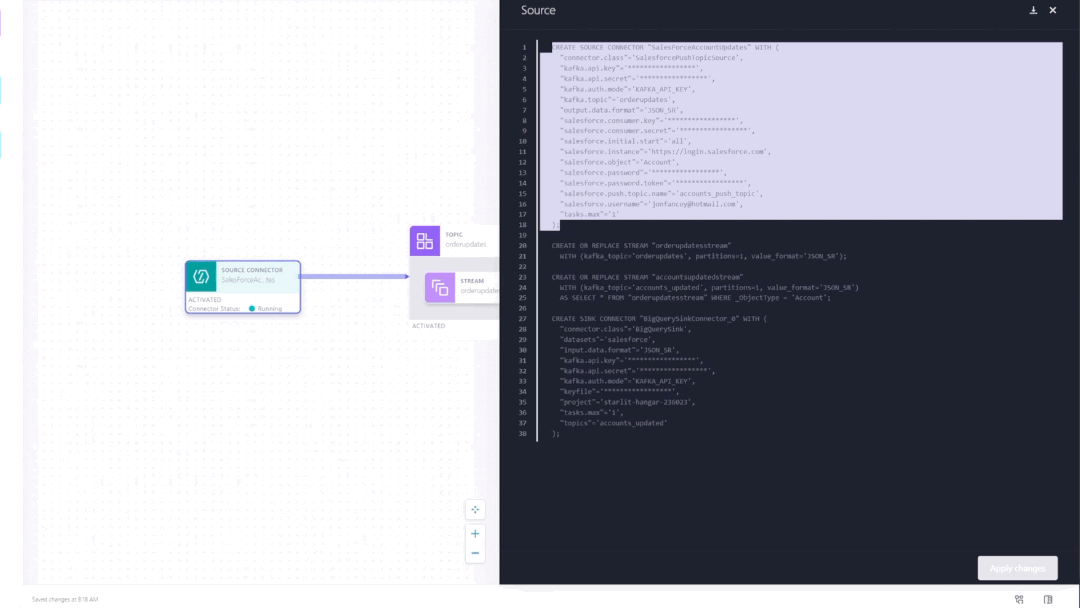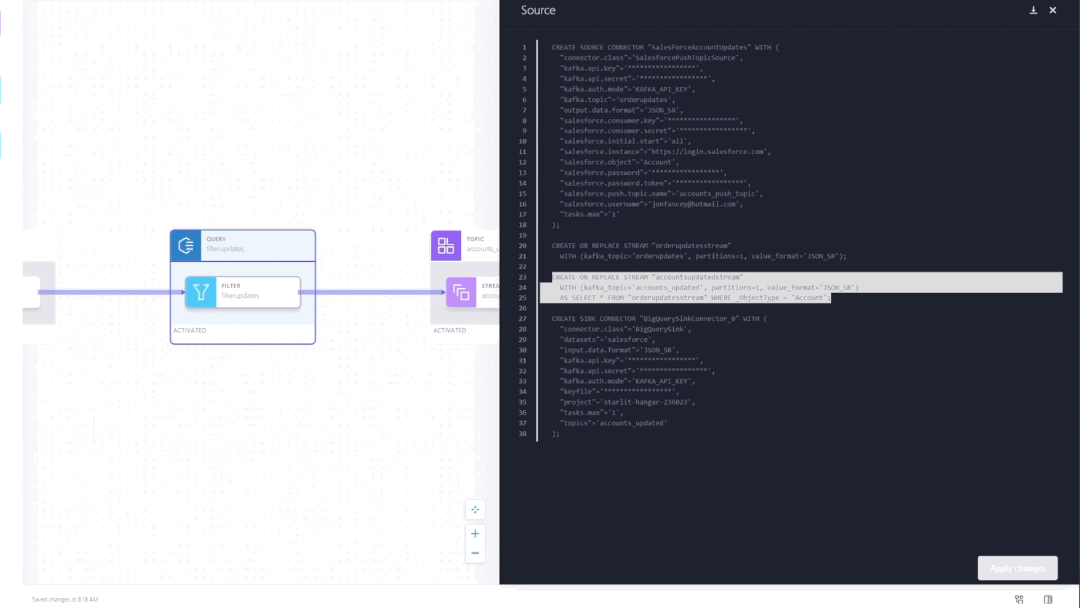
Pipeline definitions are automatically translated to ksqlDB code
For end-to-end testing and troubleshooting, you’ll see pipeline alerts and validations as you build and edit pipelines, getting instant feedback and catching errors before they become bigger problems in production. Finally, security is always top of mind as Kafka usage scales – you’re able to take control of who can access and edit pipelines with role-based access control for improved security and compliance.
Accelerate real-time initiatives
In order to democratize access to data streams across an organization and reduce reliance on specialized Kafka expertise, teams need to be able to get started with streaming quickly and reuse production-ready pipelines instead of building from scratch.
You can export pipelines built on Stream Designer as SQL source code for sharing as a template with other teams, deploying to another environment, or fitting into existing CI/CD workflows. Instead of starting from a blank canvas, teams can import Stream Designer pipelines as SQL code from the UI. From there, you can simply tailor and reuse the pre-built pipeline structure for rapid deployment. You’ll also have the option to launch one of Confluent’s stream processing use case recipes within Stream Designer.
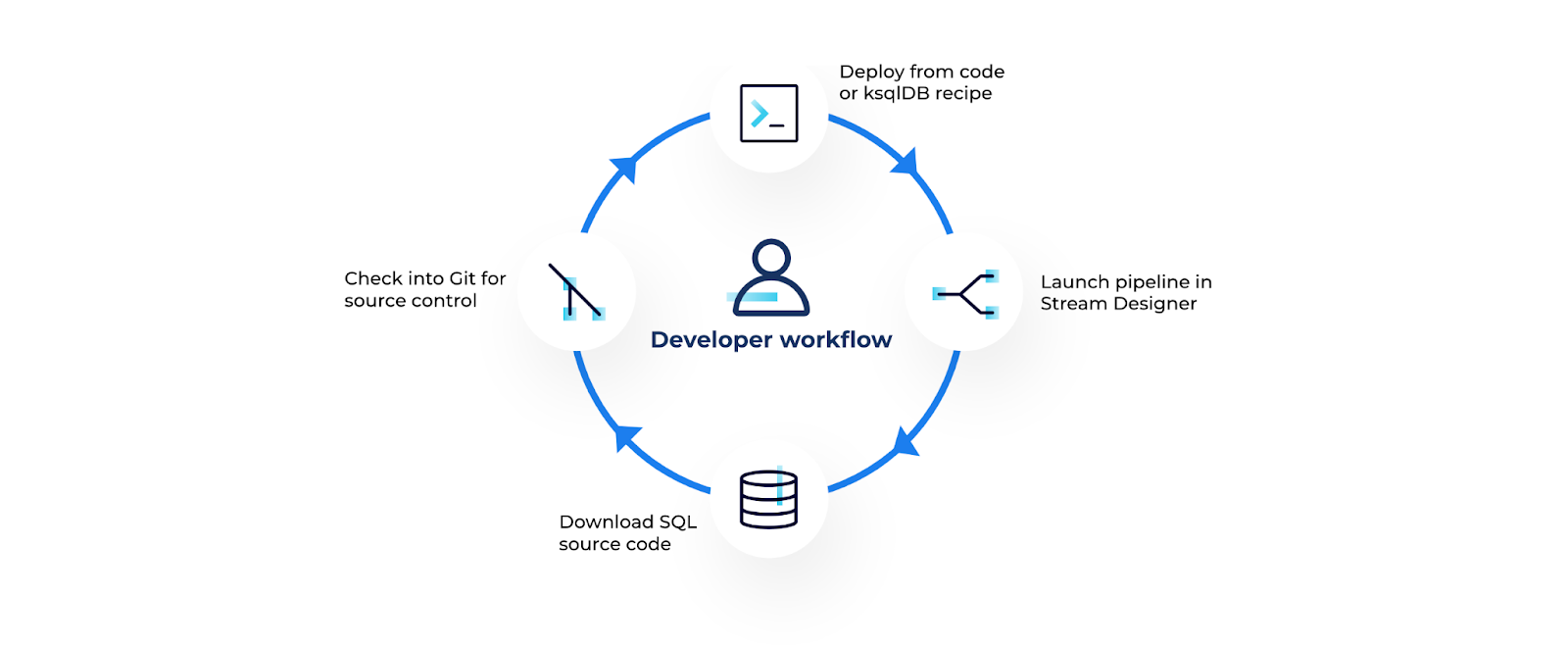
Leverage Stream Designer within your current DevOps workflow
Stream Designer allows multiple users to edit and work on the same pipeline live, improving collaboration and knowledge transfer. And with Confluent Cloud, Stream Designer enables teams to get started quickly without needing to set up infrastructure and take on additional operational burdens.
Let’s bring these Stream Designer features to life with a demo.
Demo: Build real-time product recommendations
Your company—we’ll call it Acme Corp—is an e-commerce company looking to serve real-time personalized product recommendations to site visitors based on their order and browsing history. Acme Corp stores customer order history in their Microsoft SQL Server database while website clickstreams data is owned by another team as a Kafka topic already available in Confluent Cloud. You want to create a streaming pipeline that joins the two data sources, aggregates the site visitor’s latest activities across past orders and product page views, and sends all that information to MongoDB Atlas which powers the AI/ML engine for real-time recommendations.
We’ll build this all out using Stream Designer. Fortunately, another team has shared part of their production-ready pipeline as SQL code, which we can use as a template instead of starting from a blank canvas.
To follow along yourself, check out our GitHub repo for an end-to-end pipeline example including SQL Server and MongoDB Atlas.
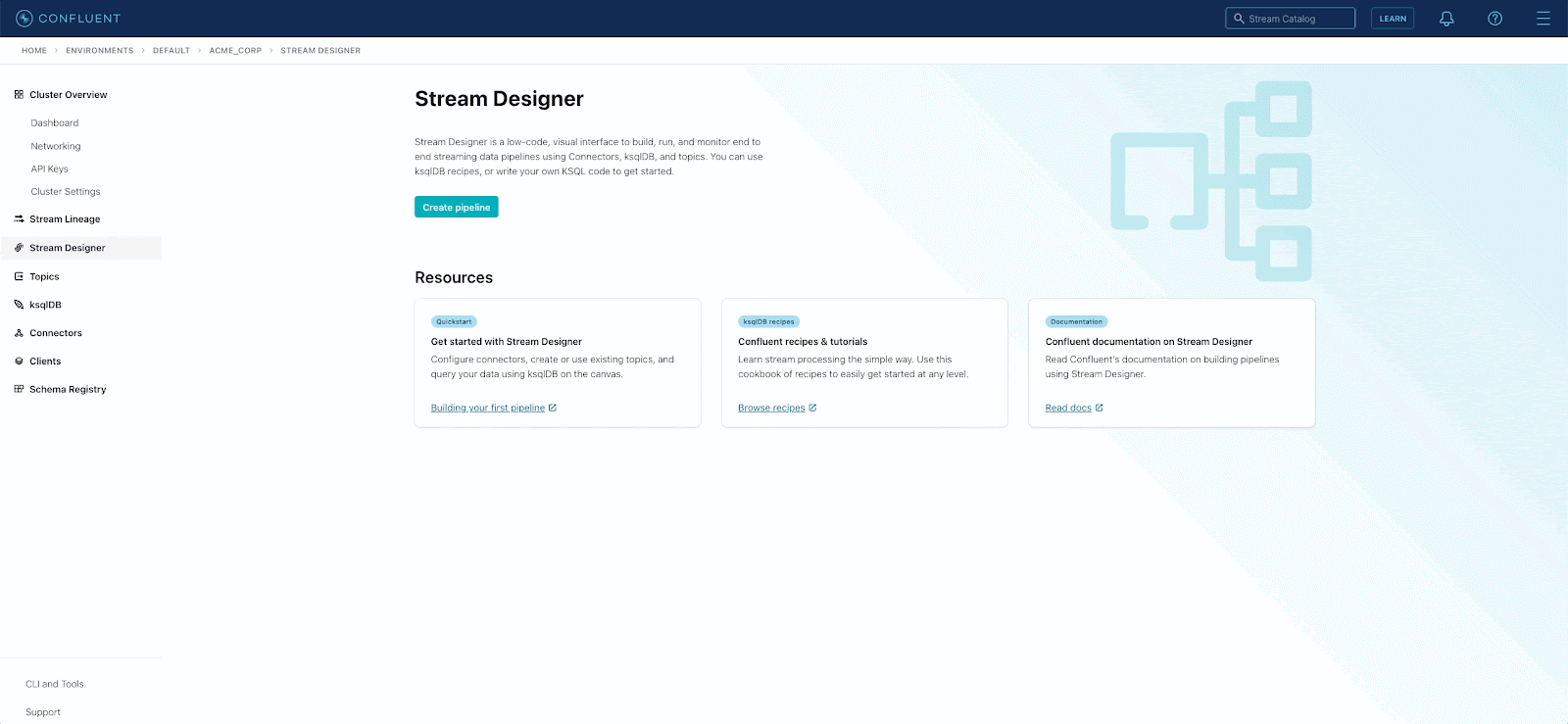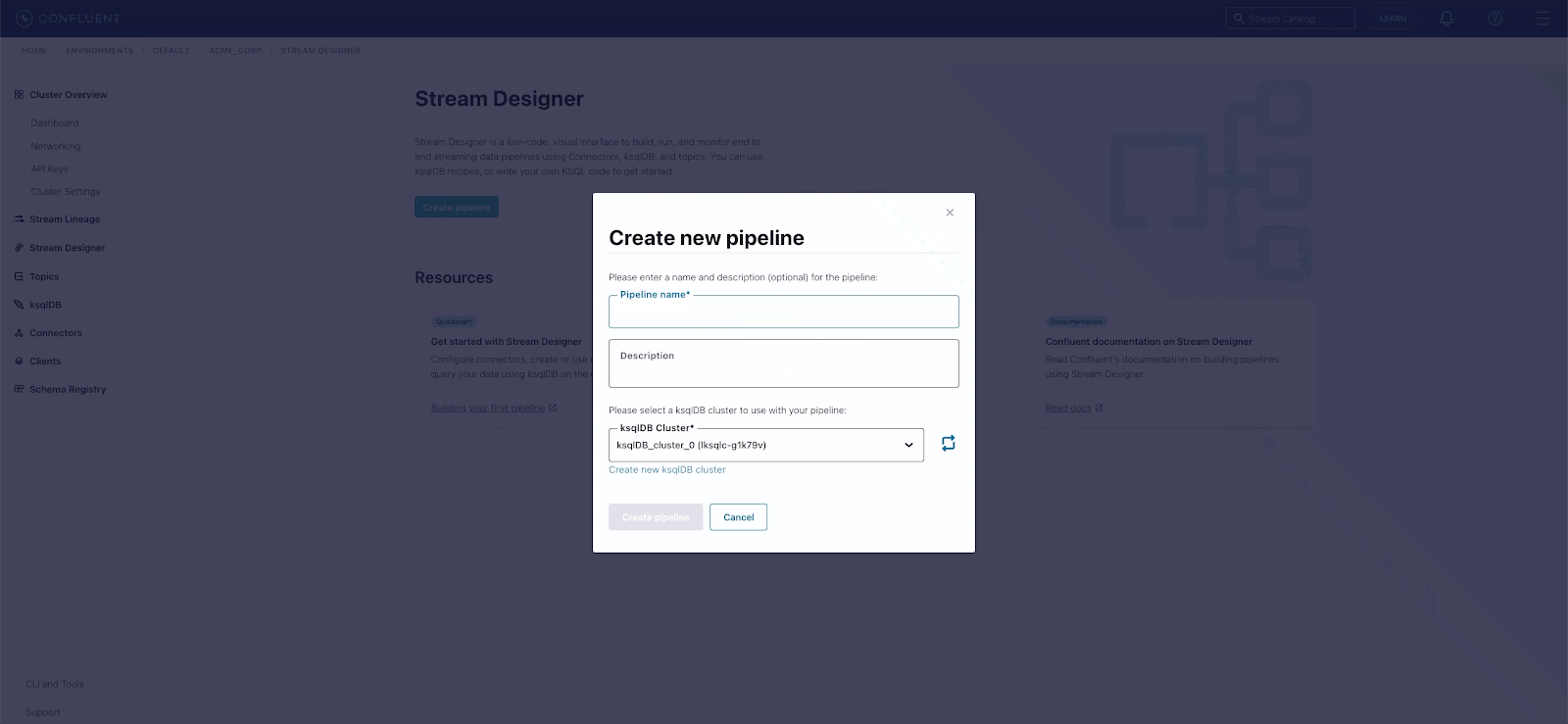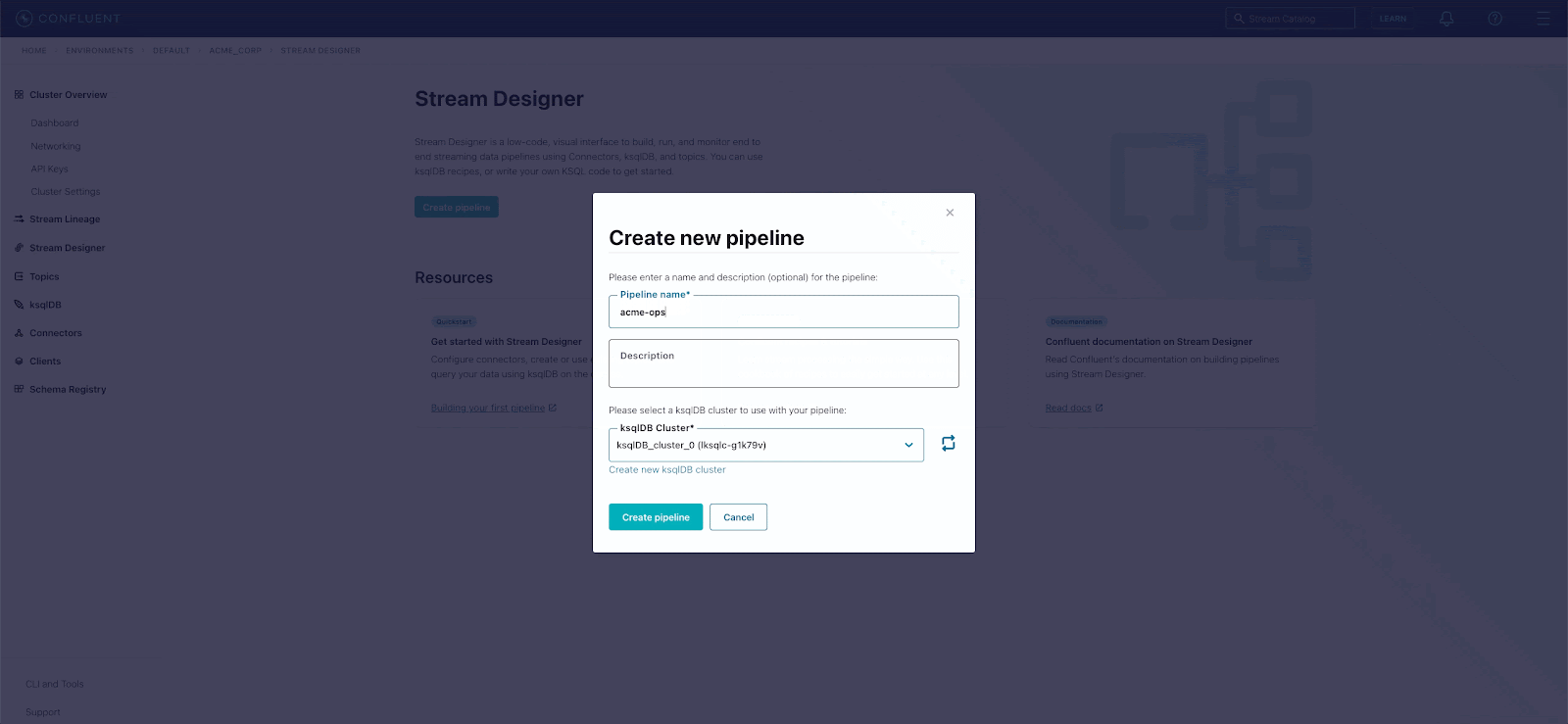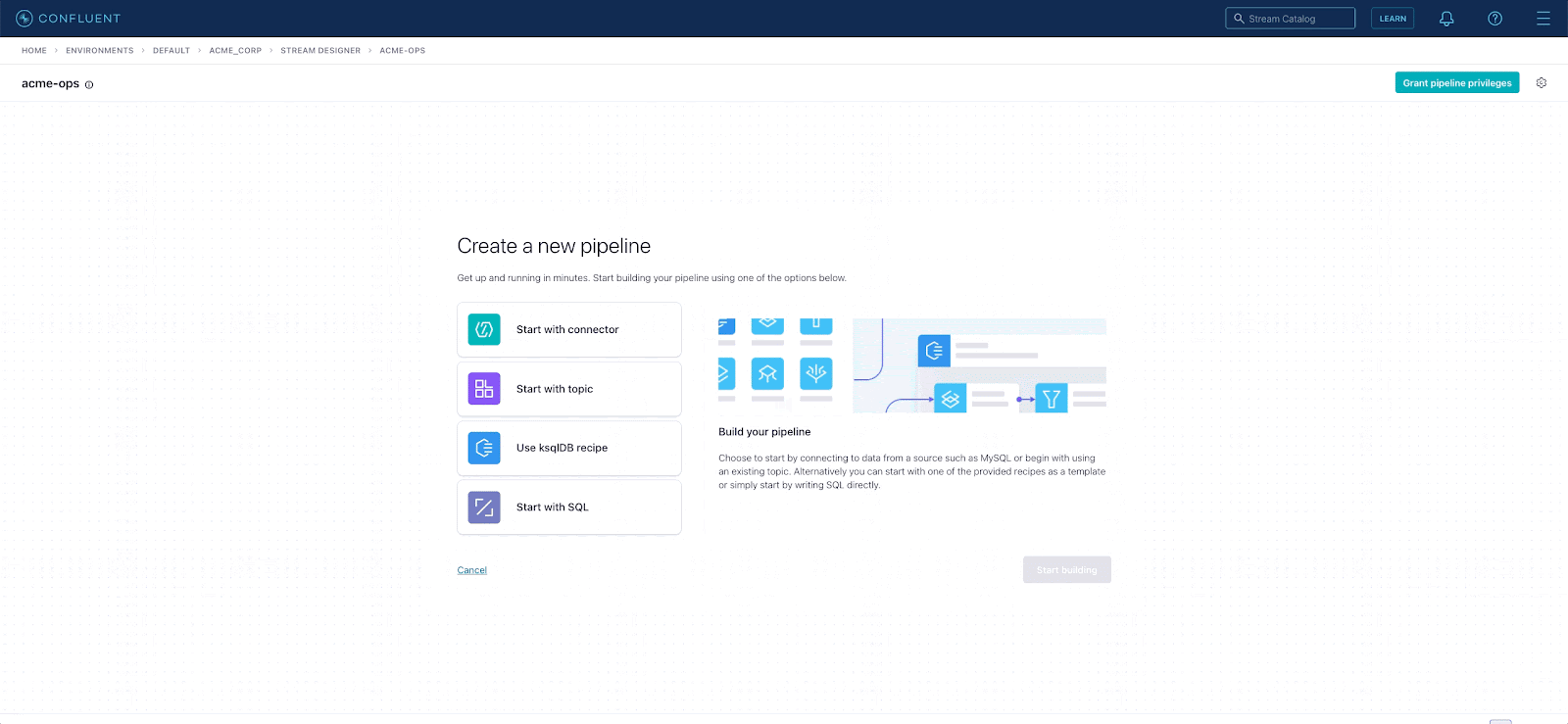
Create a new pipeline
Once a cluster is running in Confluent Cloud, Stream Designer will be available in the navigation bar on the left.
Get started by clicking on “create a new pipeline.” Since Stream Designer is powered by ksqlDB to enable SQL extensibility, we’ll need to select a ksqlDB cluster to use with our pipeline.
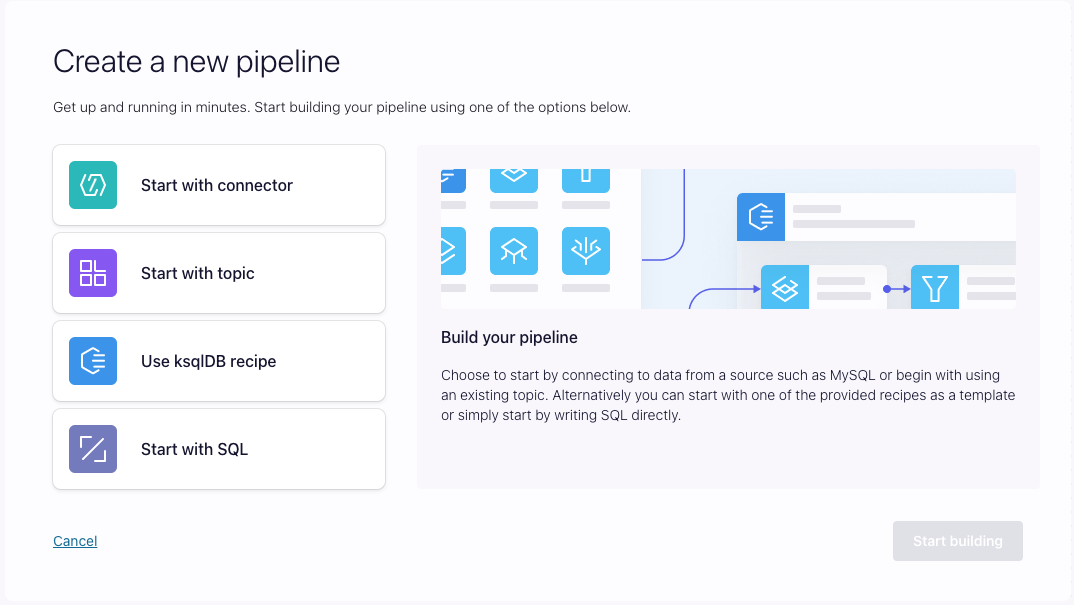
Start from a code template
Stream Designer gives you the flexibility to start building in a few different ways. You can start by configuring a source connector for pulling data from an external system. Or you can start with an existing Kafka topic if the data is already in Confluent. You can start with existing code as well, either from a stream processing (ksqlDB) use case recipe, or by importing your own code.
Let’s start with SQL and use a code block that configures a Microsoft SQL Server CDC source connector and loads the contents of orders and products tables to their corresponding topics.
CREATE SOURCE CONNECTOR "SqlServerCdcSourceConnector_0" WITH ( "after.state.only"='true', "connector.class"='SqlServerCdcSource', "database.dbname"='public', "database.hostname"='', "database.password"='*****************', "database.port"='1433', "database.server.name"='sql', "database.user"='admin', "kafka.api.key"='*****************', "kafka.api.secret"='*****************', "kafka.auth.mode"='KAFKA_API_KEY', "max.batch.size"='1', "output.data.format"='JSON_SR', "output.key.format"='JSON', "poll.interval.ms"='1', "snapshot.mode"='initial', "table.include.list"='dbo.products, dbo.orders', "tasks.max"='1' );
CREATE OR REPLACE STREAM "orders_stream" (CUSTOMER_ID STRING, ORDER_ID STRING KEY, PRODUCT_ID STRING, PURCHASE_TIMESTAMP STRING) WITH (kafka_topic='sql.dbo.orders', partitions=1, key_format='JSON', value_format='JSON_SR');
CREATE OR REPLACE STREAM "products_stream" (PRODUCT_ID STRING KEY, PRODUCT_NAME STRING, PRODUCT_RATING DOUBLE, SALE_PRICE INTEGER) WITH (kafka_topic='sql.dbo.products', partitions=1, key_format='JSON', value_format='JSON_SR');
When you click Apply changes, the pipeline automatically renders on the canvas. Let’s examine what has been built so far with the code template.
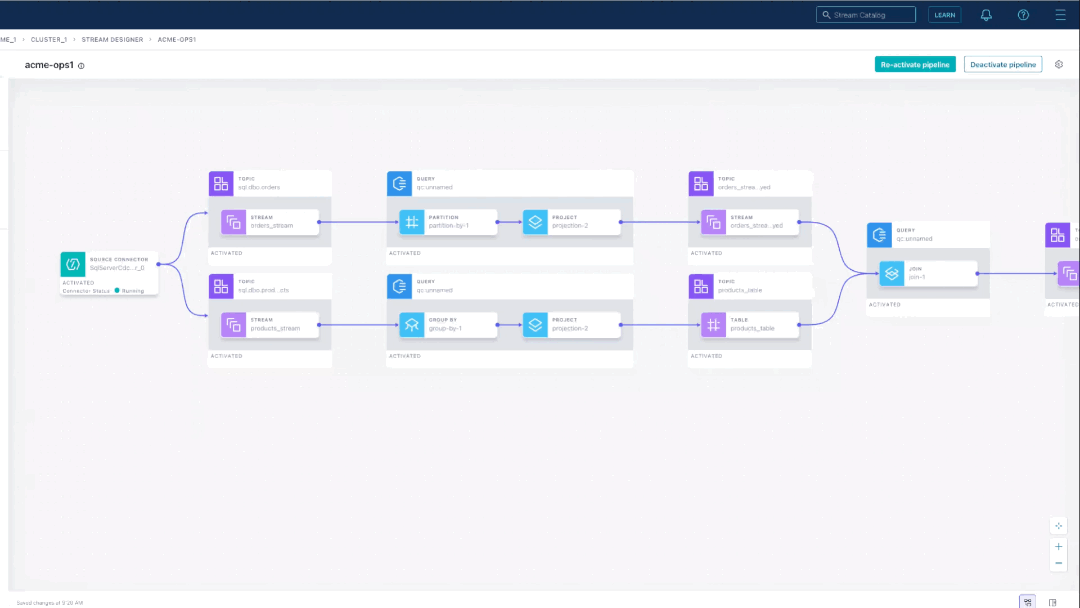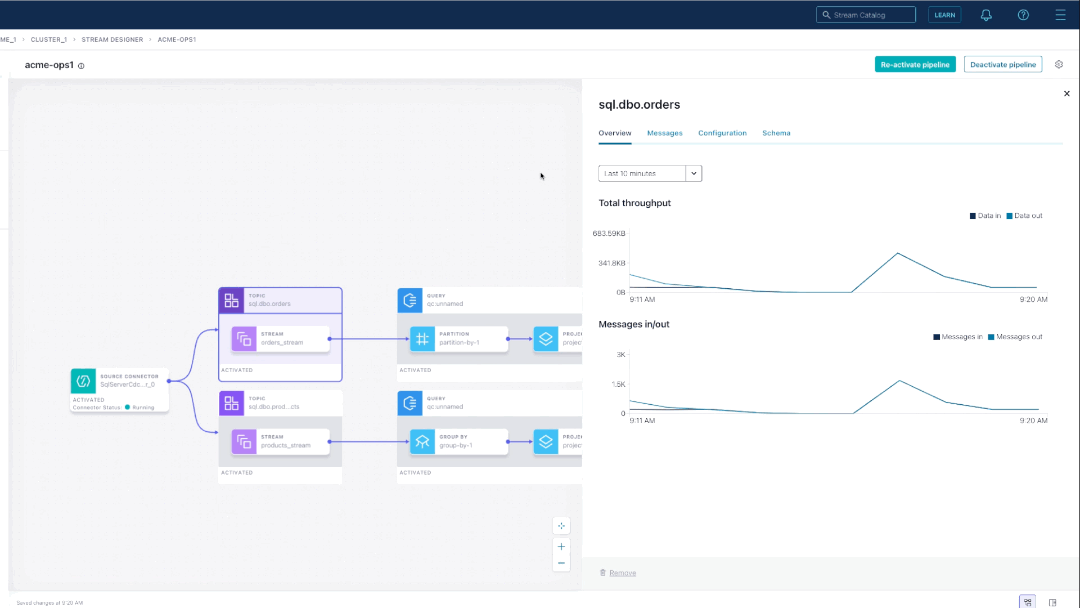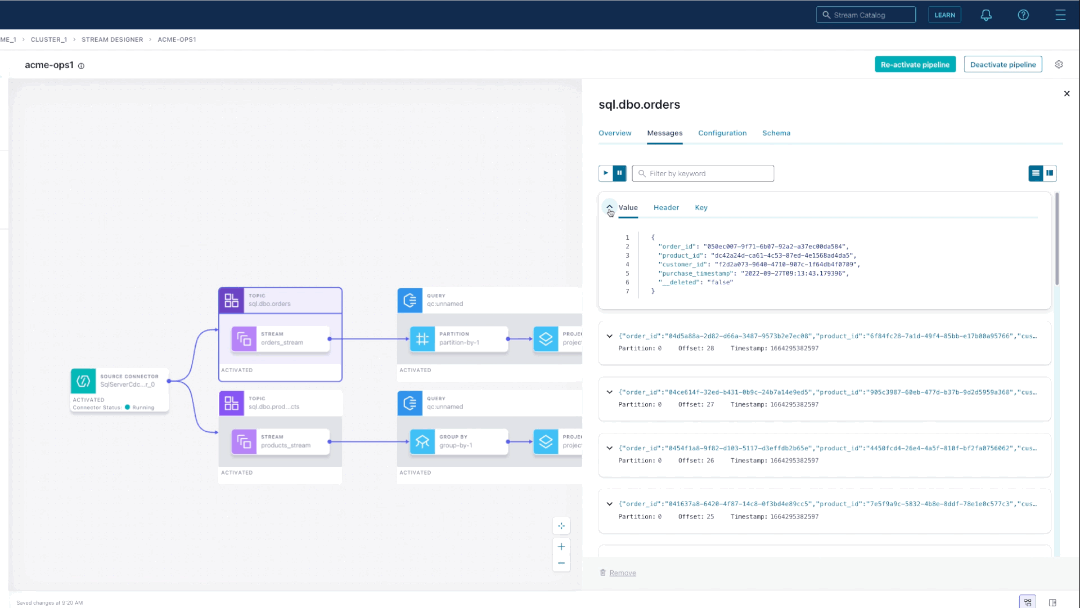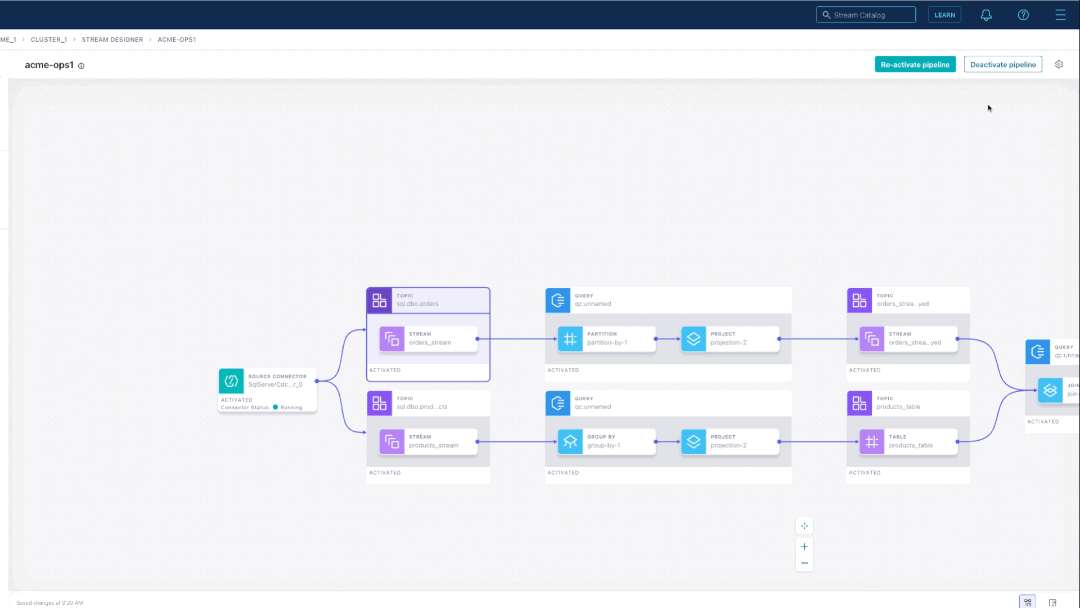
The code snippet configures a SQL Server CDC source connector, which streams customer order and product data into Kafka topics. Change data capture (CDC) is an easy way to continually extract every change to the database so that as new orders come in, we can send that event in real time to our target database to provide the AI/ML engine with the latest and greatest information.
Build visually using the canvas
We already have a head start with the SQL code template, so let’s finish building out the pipeline using Stream Designer’s visual point-and-click interface.
We want to add clickstreams data from the website so that we can get a comprehensive view of the site visitor’s activities. We also want to enrich that clickstream data with the CDC order data from the database to correlate the two channels and better personalize customer experiences.
In this case, the necessary data is already in a Kafka topic and it’s easy to bring this into Stream Designer. On the left components panel, select “Topic” to add a topic block on the canvas and choose the clickstream topic from a list of existing topics.
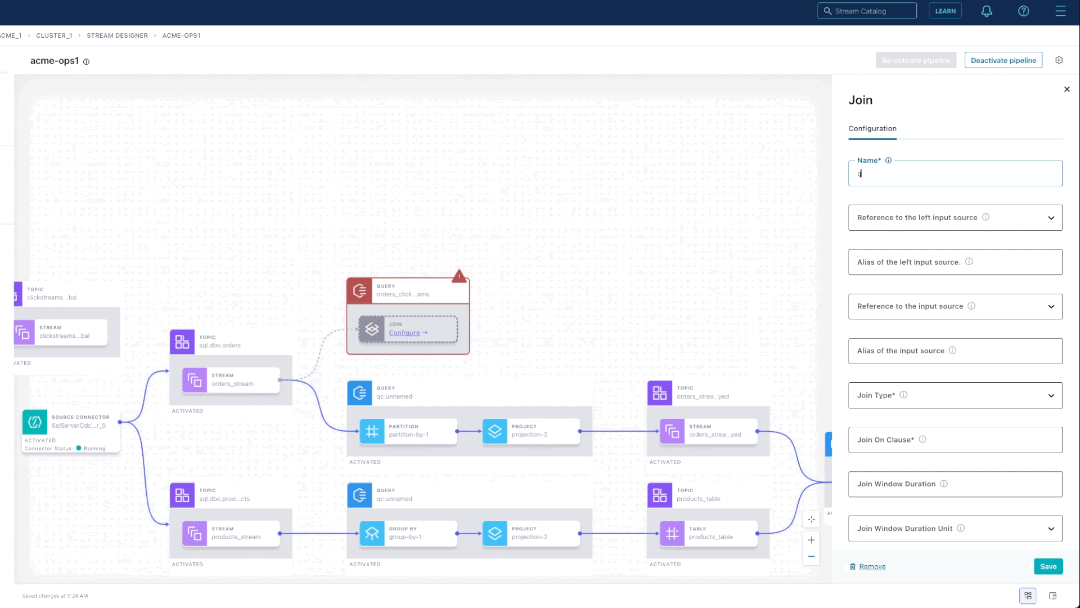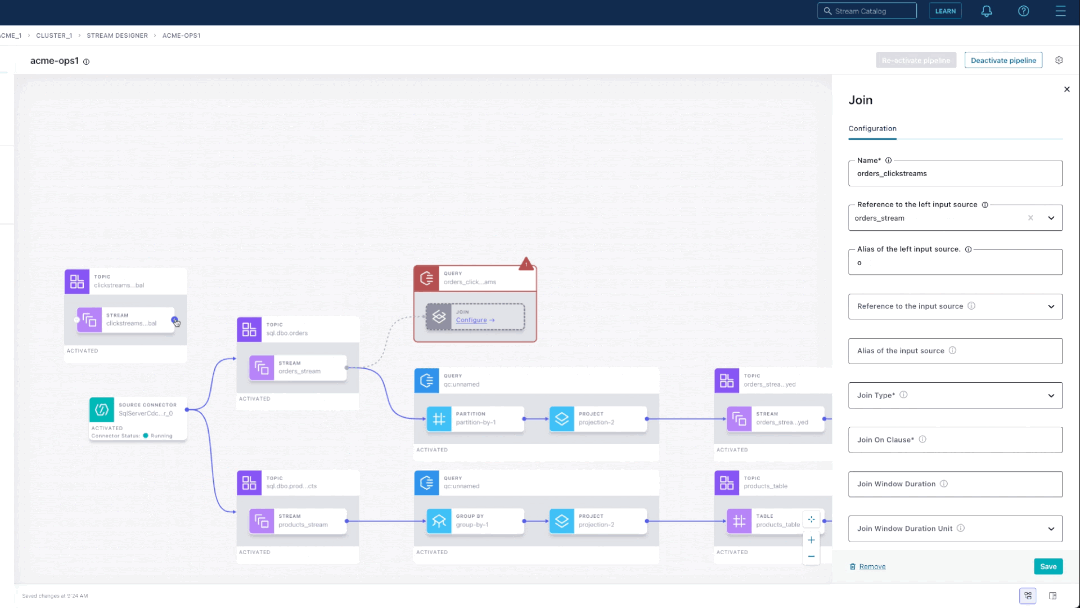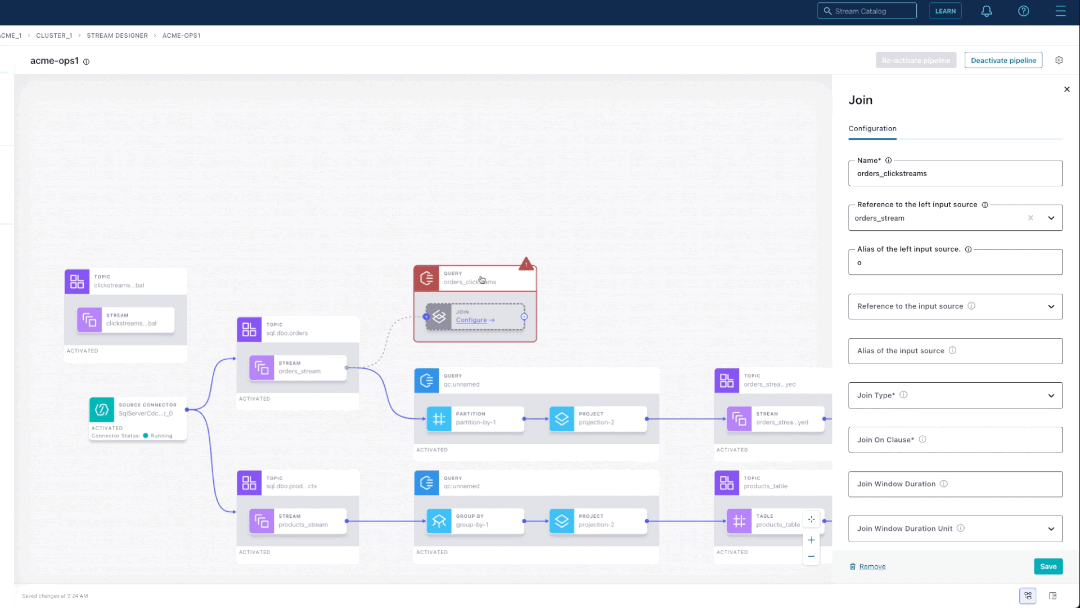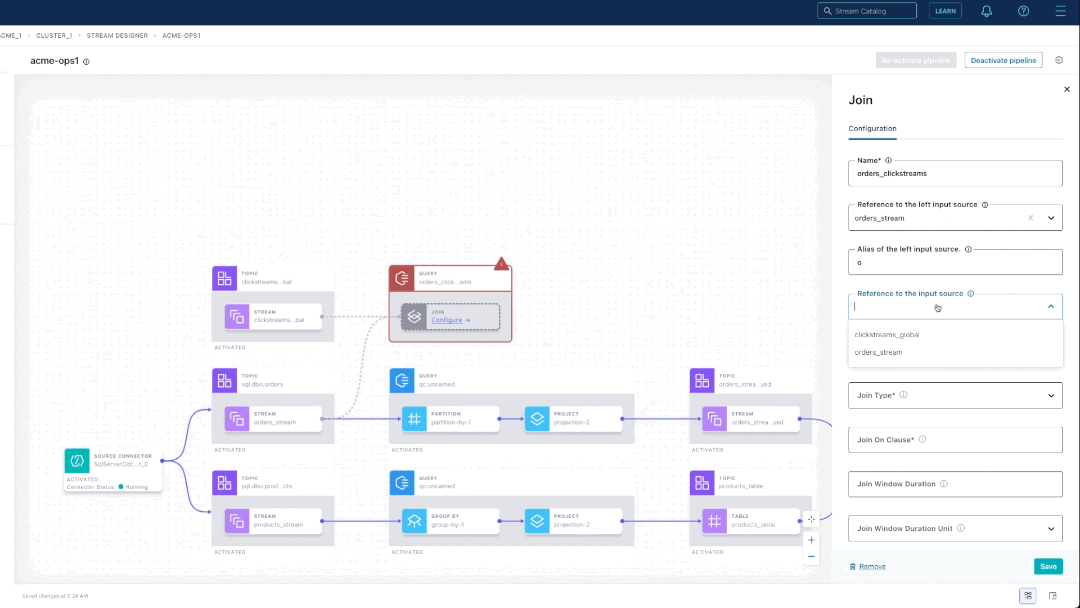
Next, we’ll combine the clickstreams topic and the order topic with a join operation. Hovering over the right node of the “orders_stream” component, there’s a list of operations to add next. Select “join” to add the component to the canvas.
To configure the join component, you provide a name, the join type, and join expression, and time window details. On an activated pipeline, you can examine messages flowing through each step. For example, we can check that the topic containing the join output is what we expected.
To complete the pipeline, you can configure sink connectors as well. We’ll add the MongoDB Atlas sink connector to send the insights to our database. Once more, we can either paste in connector configuration code or use our connector configuration UI that provides step-by-step guidance through configuration fields and recommends default config properties.
Once the configurations are saved, re-activate the pipeline to launch the connector and start streaming data into MongoDB. And voila! We have completed building our pipeline on Stream Designer using a combination of the graphical UI and SQL.
What’s next and getting started
Stream Designer is only the beginning of Confluent’s journey to democratize data streaming and bring data in motion to the mainstream. We’re excited to share more in future releases with new UI features, more automation for developer workflows, and support for additional integrations.
Ready to get going? If you’ve not done so already, sign up for a free trial of Confluent Cloud and start building with Stream Designer within a matter of minutes. And with the promo code CL60BLOG, you’ll get an additional $60 of free Confluent Cloud usage.*
Interested in learning more? Be sure to register for the upcoming Stream Designer webinar to get hands-on.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.