New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Building Real-Time Data Systems the Hard Way
A few years ago I helped build an event-driven system for gym bookings. The pitch was that we were building a better experience for both the gym members booking different classes and for the gyms and instructors managing things behind the scenes.
I joined the project toward the end of the initial R&D and I was instantly impressed by it. It’s always stayed in my mind as a business ahead of its time. The thing that made it really special was how alive the user experience was. You could go in and book a class on your phone and you’d instantly see your desktop app update to show the booking, and then your calendar would update too. Meanwhile, “off camera” you’d see the teacher’s attendance figures tick up, the receptionist’s view would instantly warn the teacher to expect a busy class, and the sales team would see their targets update—all in the same split second.
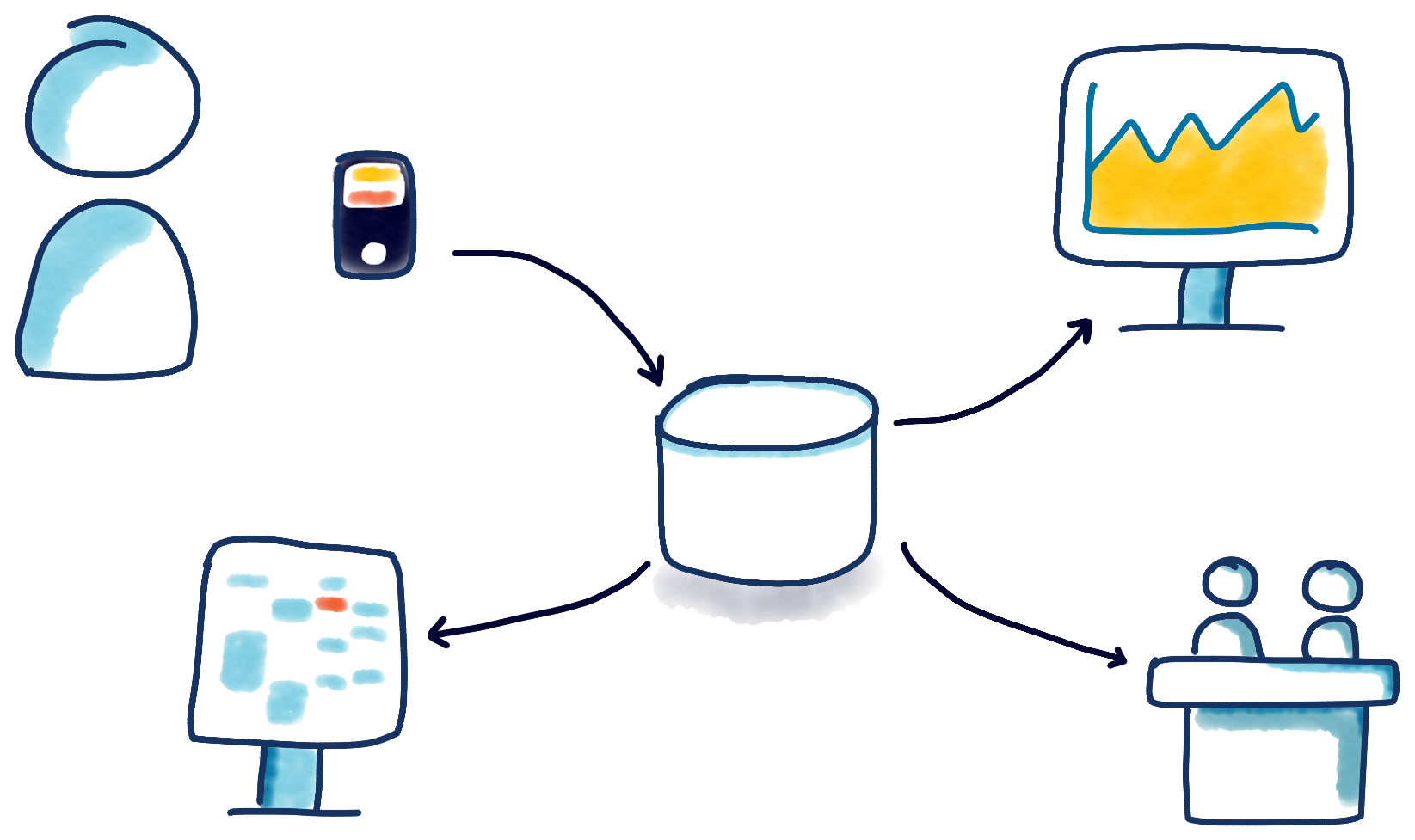
Everyone got a near-instant view of the things they cared about most. For the everyday users, it was a fantastic user experience, but the killer feature we were building was that every aspect of the business had an accurate, tailored view of the state of play. The whole business could see itself with unprecedented clarity. It started with the customers and rippled out to every kind of user because we’d architected for real-time intelligence from the very beginning.
It could have been great… but it didn’t survive.
It didn’t survive for reasons that were probably 20% technology and 80% management1—but in a better world it would have thrived. I’ve always wished it had. I find myself thinking about that UX often. About how that kind of clarity should be the default business experience, and about that 20% technology gap that I’d love to go back and get right. I’m convinced we made the right choice of architecture—real-time event streaming—but we started with a relational database and ended up reinventing a real-time engine on top of it. In the end that hurt us.
Before I go any further I should say I have a long background in relational databases and I think they’re great. I’m still staggered that astonishingly high-quality projects like PostgreSQL are free. So please don’t take this as a post bashing relational databases—that’s absolutely not the point. My point is that for this project there was an impedance mismatch between event streaming and relational which I think is worth exploring.
That said, here’s why if I ever got the chance I’d like to do that project again with Apache Kafka® at the core…
1These are, of course, scientifically accurate percentages with which the former management team would completely agree.
Watching for new events needs to be trivial
The core question for real-time systems is, “What’s the new data?” All the data is important, but the data that’s just arrived is especially important. It demands your immediate attention.
Relational databases are okay at this. You can build in what’s missing. Provided you stick an index on the event ID and keep track of the last_event_id_processed, you can pull out the oldest row that’s newer than your marker and that keeps the, “What’s new?” query reasonably efficient. Something like:
SELECT * FROM some_event_type WHERE event_id > last_event_id_processed ORDER BY event_id ASC LIMIT 1
(Depending on the specific database it might also be smart enough to realize that the index matches the ORDER BY clause, so it can process the LIMIT while it’s reading the index, rather than after it’s fetched and sorted all the rows. That can greatly reduce the number of rows processed to get the answer.)
You’ll have to stay on top of the workload. As the set of unprocessed rows grows the index becomes less and less useful, until past a certain point it becomes slower than just scanning the whole table. But that’s usually manageable enough. You’re planning to process everything as soon as it comes in anyway so that working set should stay small most of the time.
You’ll also need to worry about persisting that last_event_id_processed marker you’re tracking. Sooner or later your server’s going to restart and you’ll need to pick up where you left off. Again, that’s okay. You could write that marker to disk, or even better, store it transactionally in the database.
That’s all achievable and it’s basically what we did. But without knowing it we’d reinvented a less efficient version of exactly what Kafka consumers are built to do. With Kafka, asking for the latest piece of data is about as cheap as reading a file pointer, and Kafka consumers take care of persistently advancing that pointer as time marches on. Logically, relational databases find the newest information in the same way they find any information—by slicing and sorting a set as efficiently as possible. Meanwhile, Kafka finds the newest information the same way you find your place in a book—by leaving a bookmark.
So while our relational solution was fine, we’d already done extra work to make a core operation behave efficiently, instead of it being efficient by design. That’s a theme that continued as the project evolved.
Aggregating needs to be cheap
The next core operation in an event streaming system is asking, “What’s the current state of the world?” That turns into questions like, “When we’ve considered all those booking and cancellation events for a given class, what’s the current attendance level?”
Rollup questions like that are everywhere in an event-based system, so answering them needs to be fast to run and easy to write. Relational databases get full marks for the “easy to write” part here. SQL makes defining complex rollups trivial. Most questions are just a clever GROUP BY statement away. But performance-wise they aren’t exactly cheap, and you have to make some trade-offs between speed and liveness.
The first approach is to run that GROUP BY query every time the question is asked—that’s always up to date, but can get very expensive because you’re rescanning the event history every time. Not exactly practical.
As an improvement you can create a materialized view—effectively a cache of the query results that make repeating the query cheap. Whilst that’s an easy performance improvement, the answer risks getting stale—you have to refresh the view regularly if you want the answers to stay accurate. In most databases, refreshing on demand is easy to do, but the cost of computing that fresh answer stays high.
Lastly, some relational databases offer a form of efficiently recalculated materialized view which takes a stale materialization and works hard behind the scenes to bring it up to date efficiently. The downside is that support for that feature varies wildly by database engine, and even the best implementations have severe limitations on what can be recalculated efficiently.
In contrast, I think this is a point where Kafka—and in particular ksqlDB—really shines. ksqlDB lets you define aggregates in SQL, and the answers are cached just like a materialized view. But unlike an ordinary materialized view the results are automatically and efficiently updated every time there’s a new underlying event. You can query that aggregate at any time for the latest results, but even better, you can subscribe to it so you get notified every time there’s a change. That makes it trivial to create something that looks like a table of class bookings, updates as efficiently as receiving a new row, and sends notifications out every time the attendance changes.
Actually, I think ksqlDB might be my favorite Kafka feature—all the convenience of a high-level language like SQL, but with efficient real-time processing baked in from the very start.
Recovering from downtime is hard
In our gym business we took another approach altogether with aggregates—we solved it at a language level. We used Haskell2 which is naturally great at rolling up a (potentially infinite) stream of events and producing aggregates. Defining new aggregates was a trivial, in-memory operation in a high-level language that was well-suited to the job. That part I loved, but it didn’t solve the whole problem.
Here we get into operational concerns. What happens when the server needs to restart? Either for happy reasons like new releases or sad reasons like a server crash. That in-memory aggregation is lost! For a good while you can cope with rebuilding the aggregate from scratch. The system is small, and the rebuild is quick. But gradually you amass an ever-growing list of events and an ever-larger set of queries to satisfy. The time to restart gets longer and longer, and sooner or later, you have to start snapshotting. You have to take your in-memory aggregate and periodically write it to disk (or better yet, transactionally back to the database), and then pre-load that saved state after you restart.
I forget now whether we started work on that incremental-snapshot system for our aggregates, or if that fun was yet to come. What I do know is that it’s yet more work that’s fairly easy in theory, a bit more work than you think in practice, and already available for free with ksqlDB. It’s a problem that’s already solved at least as well as we’d ever have time to do it.
2Allow me to talk your ear off about how great Haskell is sometime…
We’ve reached the “yes, but is it worth it?” line
Up to this point I’ve talked about things we built to serve the business. Now let’s cross over the line, into the realm of things that would have taken so long to get right we’d have stopped being a gym business and started being a real-time database business instead.
Managing an avalanche of notifications
The next big bottleneck to face in a system like this is outbound messaging. When the crux of the business is, “We’re going to tell you everything you need to know, as soon as you need to know it,” you end up pushing out vastly more notifications and messages than you’d expect in a typical business. That’s good—that’s a feature—but you’ve got to support it.
Processing-wise, this is just another example of the “What’s new?” problem we’ve already discussed. Scale-wise it’s much harder, for two reasons.
First, the number of notification types leaps up—you’ll end up sending more notifications, about more events, to more groups of users, across more media. The flow of instant messages sent to customers about their classes competes with the flow of intranet WebSocket notifications to the sales dashboard. That’s a tidal wave of data to read/aggregate and push out across the net.
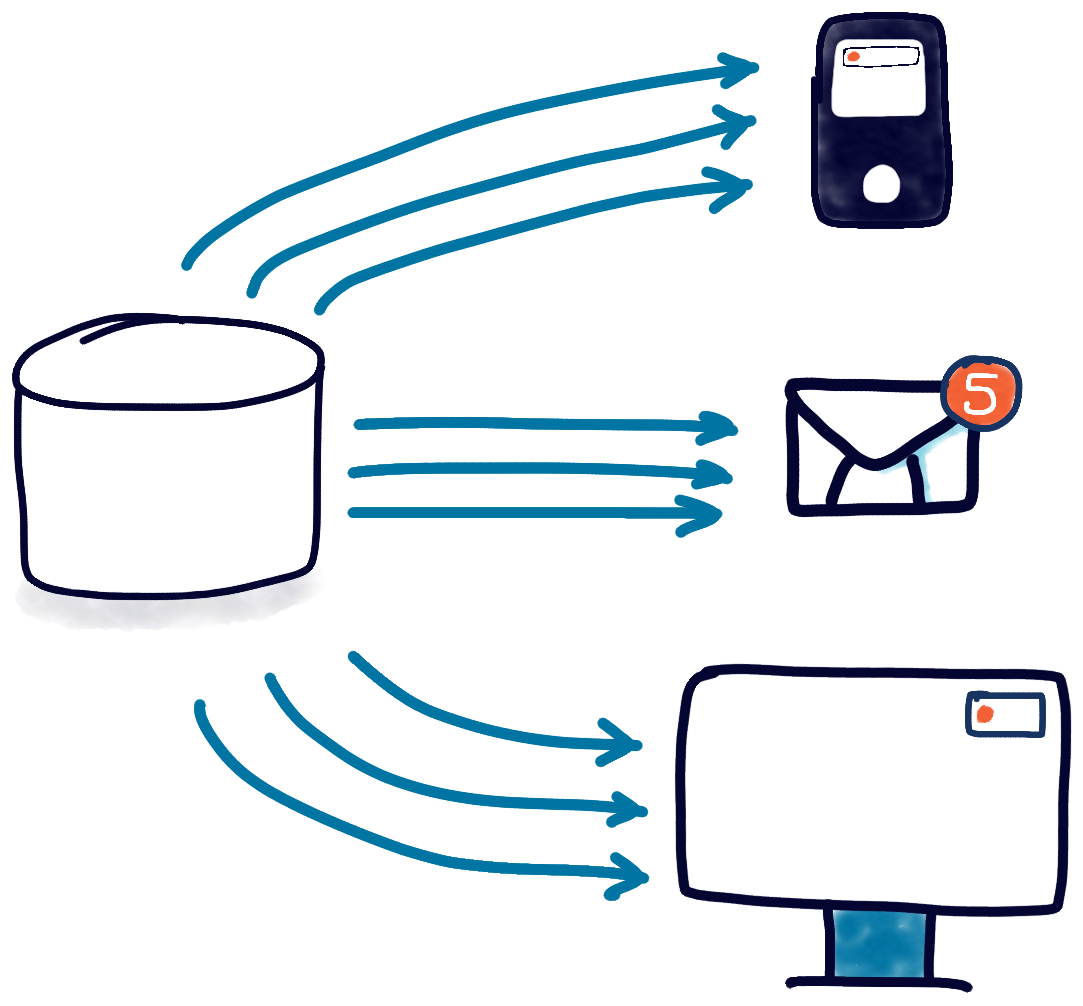
Well, we have a strategy for the aggregation part, and the reading part’s certainly manageable. Relational databases are excellent at scaling reads. Even if we blow out the read-volume of a single database, most relational databases these days can spin out read-only copies without too much effort3. A read-only copy puts a bit of a thorn into our recovery mechanism—if we’re persisting that last_event_id_processed to the database, it’ll have to be written back to the primary, so we’ll need a read-only connection to the secondary database and a writable connection to the primary. Doable, but a pain.
The second and much bigger problem—which I think lies far over the “worth it” line—is throughput. Sending emails and instant messages isn’t slow, but it isn’t exactly fast either. We can easily get into a state where we’re accruing messages faster than we’re sending them. To keep throughput high enough you need a work-sharing system, sending the outbound emails across a bunch of email servers, texts across multiple SMS gateway servers, and so on.
That opens up a whole raft of problems I don’t want to solve myself: What’s the sharing strategy? Is it highly-tailored to the systems under the most stress or generic enough to cover all our use cases? How do you deal with downtime on a single worker—does its workload get picked up by the others, or are they just held up until the server comes back online? Can you add more machines without rewriting your sharing code or reconfiguring your cluster? And how do you ensure each message gets processed exactly once? That last one’s particularly hard to get right.
Now let’s be clear—when you’re a startup trying to become a real business, these kinds of scale problems are lovely problems to have. Finding out that your business is more successful than you can cope with is the most joyful of headaches4. But they’re problems you can see coming, and while you don’t want to solve them on day one, you want to have a plan for solving them before they arise.
The best plan in this case is to have someone else solve them for you. Kafka has a number of battle-tested techniques for scaling out event notifications.
It has native partitioning and replication, so we can shard different types of messages by some aspect of their information, and then spread reads out along those lines. It has consumer groups that make it easy to share a stream of messages out among several workers, without writing any custom application code. And those consumer groups are automatically scaled and load-balanced as workers are added and removed for any reason. Cleverest of all, it has exactly-once semantics (EOS) for its core stream processing tools, so you can ensure every message is handled, but none are handled twice.
That last point is important, nuanced, and super-hard to get right. It took about six years—and a huge engineering effort—for Kafka to get EOS. I’m especially glad we didn’t try to tackle that one as a sideline to the gym business; it would have swallowed us whole.

3They generally do this by writing events to an append-log log, replicating that log out, and then aggregating over those events to build up readable tables. That’s an interesting architecture, wouldn’t you say? 😉
4I’ve been there. It’s terrifically motivating.
Focusing on work not done
Whenever people debate programming languages there’s always someone who says, “Smart people can work with any tools,” or “You can do anything with any language.” And those people are absolutely right. You could write a distributed real-time database in BASIC and SQLite if you wanted, provided you had a limitless supply of time and energy. But time and energy are precious commodities5.
In reality, you have to choose where you’re going to spend the resources you have. I’m glad we spent our time rethinking and rebuilding the UX of an entire business, and I’m proud of what we accomplished with the tools we had. But as I said earlier, one day I’d like to try a project like this again, with the benefit of hindsight and the advantage that someone’s solved a lot of the technical problems of real-time systems already. It would let us focus on the things that made that business truly unique.
5 If you doubt this, stop reading and go and have children. Three years from now you’ll understand.
Good places to keep learning
If you’re just getting started with Kafka take a look at our Getting Started Guides for many popular languages and our Kafka 101 course. For more on the marriage of SQL and event streaming we have a course on ksqlDB. If you want to learn more about how to architect event streaming systems (with or without Kafka) we have a library of Event Streaming Design Patterns. And if you want to see a real-time system being built with Kafka you can watch me live-coding a business dashboard in 30 minutes.
Related content
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Streaming Data Integration with Apache Kafka®
Streaming data integration supports enriched, reusable, canonical streams that can be transformed, shared ,or replicated to different destinations, not just one.



Data Streaming Platforms: The Cornerstone of Enterprise AI
Discover how a data streaming platform helps you unlock the full potential of your AI—and translates it into measurable business value.