New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
From Eager to Smarter in Apache Kafka Consumer Rebalances
Everyone wants their infrastructure to be highly available, and ksqlDB is no different. But crucial properties like high availability don’t come without a thoughtful, rigorous design. We thought hard about how to achieve this while maintaining at-least-once and exactly-once processing guarantees. To learn how we did it, it’s time to peel back the layers below ksqlDB and get your hands dirty with the Apache Kafka® rebalancing protocol.
Consumer groups and the rebalance protocol
The Kafka consumer group protocol allows for hands-off resource management and load balancing, a must-have for any distributed system to be practical for application developers and operators. By nominating a single broker to act as the point of contact for the group, you can isolate all of the group management in the group coordinator and allow each consumer to focus only on the application-level work of consuming messages.
The group coordinator is ultimately responsible for tracking two things: the partitions of subscribed topics and the members in the group. Any changes to these require the group to react in order to ensure that all topic partitions are being consumed from and that all members are actively consuming. So when it detects such changes, the group coordinator picks up its one and only tool: the consumer group rebalance.
The premise of the rebalance is simple and self-descriptive. All members are told to rejoin the group, and the current resources are refreshed and redistributed “evenly.” Of course, every application is different, which means that every consumer group is too. An “evenly” balanced load might mean different things, even to two consumer groups sharing the same broker for their group coordinator. Recognizing this, the rebalance protocol was long ago pushed into the clients and completely abstracted away from the group coordinator. This means that different Kafka clients can plug in different rebalancing protocols.
This blog post is focused on the consumer client and on Kafka Streams, which is built on the consumer client. Konstantine Karantasis gives a detailed discussion on the protocol followed by Kafka Connect in the blog post: Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
To allow the client to dictate the protocol followed by a group of non-communicating consumers, a single member is chosen to be the group leader for a rebalance, which then progresses in two phases. During the first phase, the group coordinator waits for each member to join the group. This entails sending an aptly named JoinGroup request, in which each member encodes a subscription including any interested topics and client-defined user data. The subscriptions are consolidated by the broker and sent in the JoinGroup response to the group leader.
The leader decodes the subscriptions, then computes and encodes the assignment of partitions to each consumer. This is then sent to the group coordinator in the leader’s SyncGroup request. This is the second phase of the rebalance: all members must send a SyncGroup request to the broker, which then sends them their partition assignment in the SyncGroup response. During the entire rebalance phase, individual members never communicate with each other directly. They can only propagate information to one another by talking to the broker-side group coordinator.
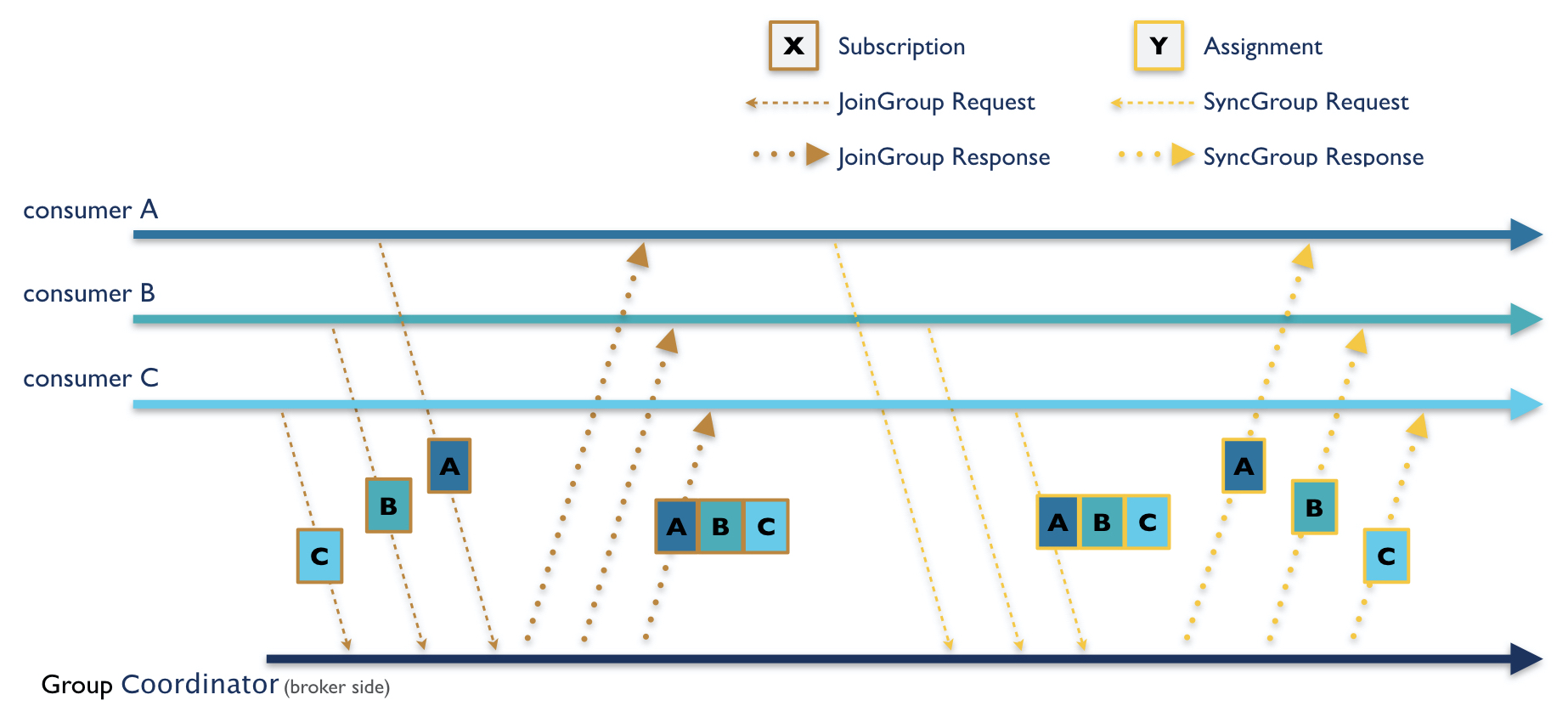 Figure 1. The two-phase rebalance protocol with three consumers. In this situation, consumer C is the group leader.
Figure 1. The two-phase rebalance protocol with three consumers. In this situation, consumer C is the group leader.
The consumer client further abstracts away the assignment of partitions to consumers into a pluggable interface, called the ConsumerPartitionAssignor. If the partition assignor satisfies its contract of a one-to-many mapping of consumers to all partitions, the rebalance protocol takes care of the rest. This includes managing the transfer of partition ownership from one consumer to another, while guaranteeing that no partition may be owned by more than one consumer in a group at the same time.
This rule sounds simple enough, but it can be difficult to satisfy in a distributed system: the phrase “at the same time” may cause alarms to go off in your head.
Thus, to keep the protocol as simple as possible, the eager rebalancing protocol was born: each member is required to revoke all of its owned partitions before sending a JoinGroup request and participating in a rebalance. As a result, the protocol enforces a synchronization barrier; by the time the JoinGroup response is sent to the leader, all partitions are unowned, and the partition assignor is free to distribute them as it pleases.
It’s all good in terms of safety, but this “stop-the-world” protocol has serious drawbacks:
- No member of the group can do any work for the duration of the rebalance
- The rebalance duration scales with partition count, as each member has to revoke and then resume every partition in its assignment
Each of these is bad enough on its own. Combined, they present a significant problem to users of the consumer group protocol: downtime for all partitions and all members of the group, for the entire duration of the rebalance. This means that each consumer sits around doing nothing from the time it sends the JoinGroup request to the time it receives the SyncGroup response, as illustrated in Figure 2.
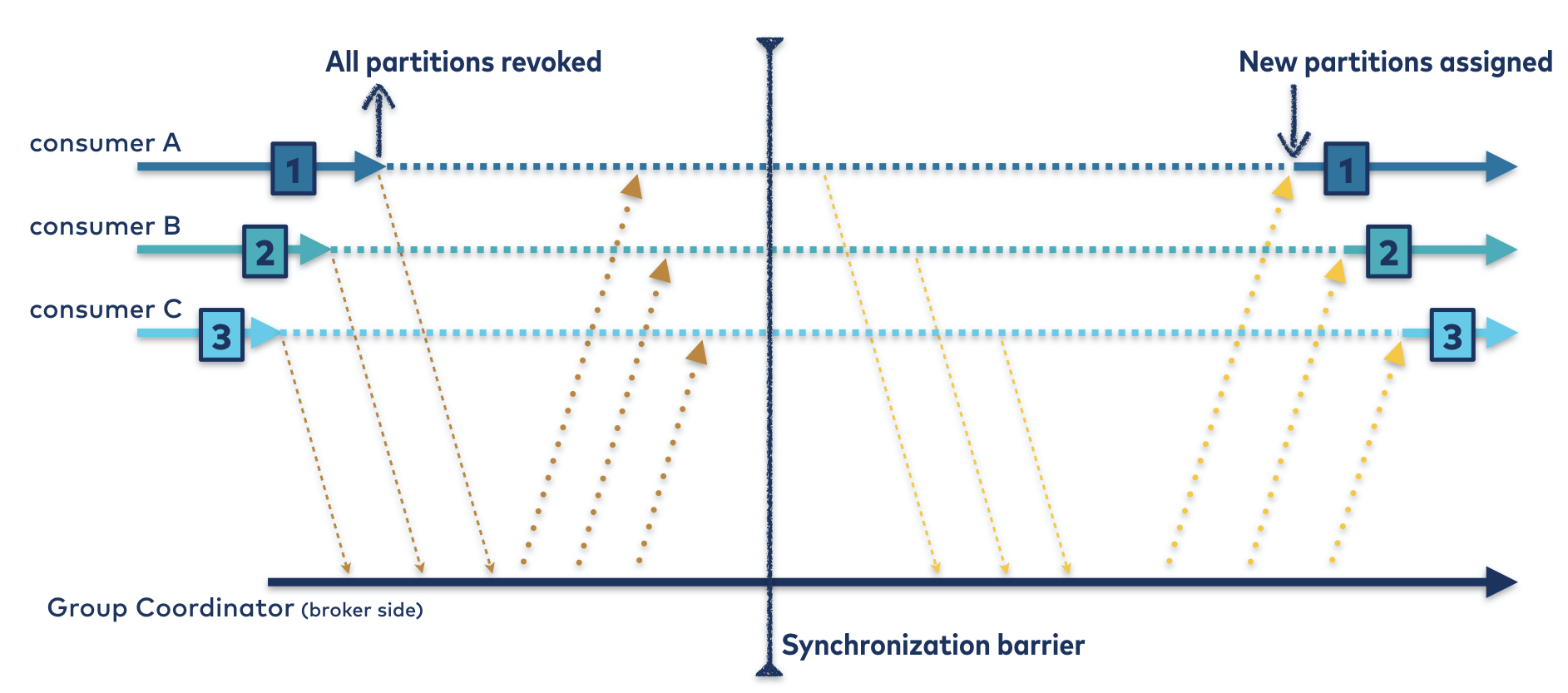 Figure 2. The eager rebalancing protocol. Even though every partition gets reassigned to its original owner, all three consumers are unable to consume for the duration indicated by the dotted line.
Figure 2. The eager rebalancing protocol. Even though every partition gets reassigned to its original owner, all three consumers are unable to consume for the duration indicated by the dotted line.
While this may be acceptable in some environments with infrequent rebalancing and few resources, most applications do not fall into that category. We’ve already made significant improvements to reduce the number of unnecessary rebalances in unstable environments. But as long as there are resources to manage, there’s going to be a need for rebalancing. Maybe we can make the rebalancing experience less painful with a smarter client-side protocol.
The ideal rebalancing protocol
To approach this, take a step back and ask what the optimal rebalancing protocol would look like in an ideal world. Imagine a world without node failures, network partitions, and race conditions—nice, right? Now think about the easiest way to redistribute partitions as group members come and go. Take this specific example of scaling out:
Consumers A and B are consuming from a three-partition topic. Two partitions are assigned to A and one to B. Noticing the uneven load, you decide to add a third consumer. Consumer C joins the group. How would you hope for this rebalance to work?
All you have to do is move one partition from consumer A to consumer C. All three consumers must rejoin the group to confirm their active membership, but for consumer B, that’s where the involvement should end. There’s no reason, in this ideal world, for consumer B to ever stop processing its partition, much less to revoke and/or resume it. This means no downtime for consumer B, as illustrated in Figure 3.
Consumer A, of course, does have to revoke a partition, but only one. Once it has given up its second partition, it can happily return to processing its remaining partition. Instead of sitting idle for the entire rebalance, consumer A’s downtime lasts only as long as it takes to revoke one partition.
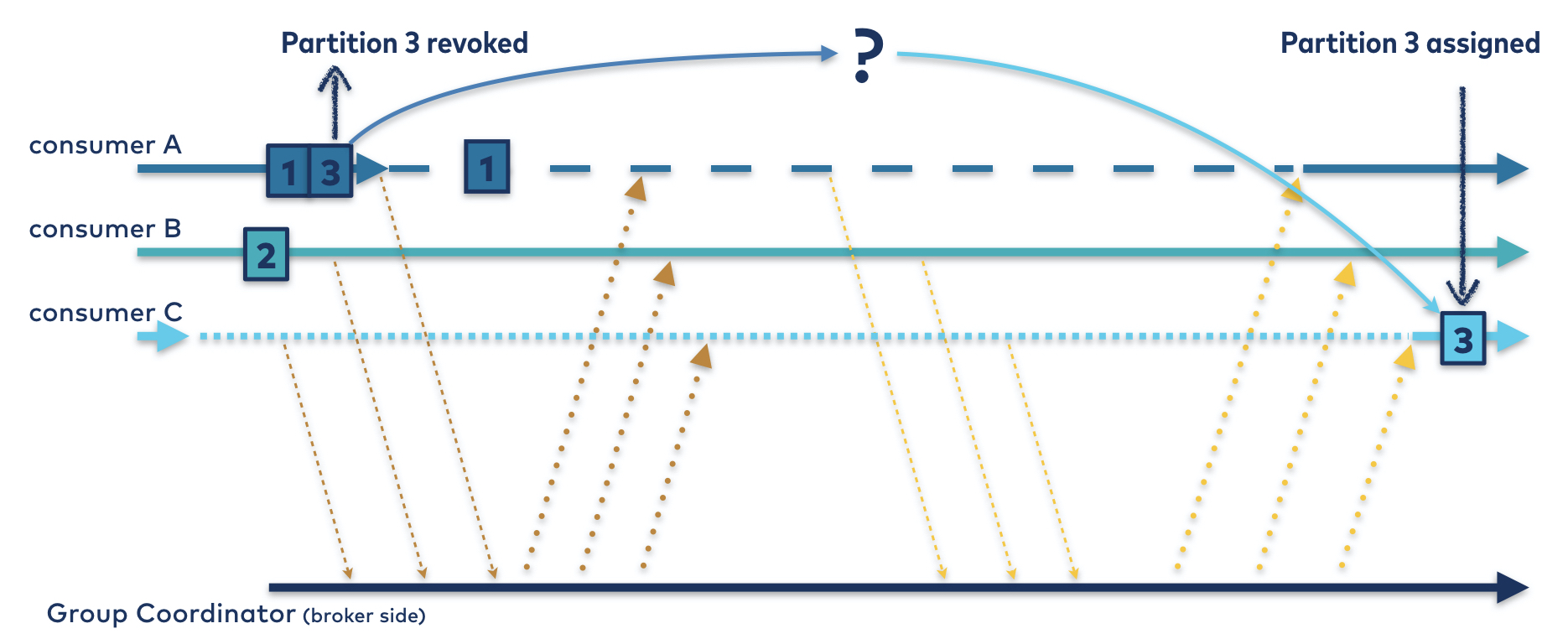 Figure 3. The rebalance protocol you wish you had. Partitions 1 and 2 are continuously consumed, and partition 3 is only down for the time it takes to transfer ownership from consumer A to C.
Figure 3. The rebalance protocol you wish you had. Partitions 1 and 2 are continuously consumed, and partition 3 is only down for the time it takes to transfer ownership from consumer A to C.
To sum it up, an optimal rebalance would only involve those partitions that need to be moved to create a balanced assignment. Rather than completely wipe out the old assignment to start with a fresh slate, you would start at the original assignment and incrementally move partitions to reach the new assignment.
Between the ideal world and here
Unfortunately, the time has come to return to the real world. Consumers crash, get out of sync, and refuse to cooperate. All you can hope for, before this happy vision fades away completely, is a concrete plan to return one day. So why not dust off the old cartography tools and try to map the way from the eager protocol you live with now to one a little more…cooperative?
To chart this course forward, you first need to understand what’s blocking the way. This comes back to the rule that was introduced above: at no time can two consumers claim ownership of the same partition. Any time the synchronization barrier is dropped, this is put at risk. Remember, the barrier is currently maintained by forcing all members to revoke all partitions before rejoining the group.
Is that too strict? You can probably guess that the answer is yes. After all, this barrier only needs to be enforced for partitions that are transferring ownership. Partitions that are reassigned to the same consumer trivially satisfy the rule. The others pose a challenge since consumers do not know a priori which of their partitions will end up reassigned elsewhere. Obviously, they will have to wait for the partition assignor to determine the new mapping of partitions to consumers. But once the new assignment has been sent to all members of the group, the synchronization is over.
If a partition is to be migrated from consumer A to consumer B, B must wait for A to relinquish ownership before B can take the partition. But B has no way of knowing when A has finished revoking the partition. Keep in mind, revocation can be as simple as removing the partition from an in-memory list or as complicated as committing offsets, flushing to disk, and cleaning up all associated resources. For example, Kafka Streams users launching heavily stateful applications know all too well how long it can take to revoke a partition.
Clearly, you need some way for a consumer to indicate when it is safe to reassign one of its old partitions. But consumers can only communicate during rebalances, and the last rebalance has just ended.
Of course, there’s no law saying that you can’t have two rebalances in a row. If you can make each rebalance a less painful experience, a second rebalance doesn’t sound so bad. Can this somehow be leveraged to get where you want to go? Is there a light at the end of the eager rebalancing tunnel?
The incremental cooperative rebalancing protocol
Good news! You already have all the pieces you need to form a safe and sound rebalancing protocol. Let’s take a step back and walk through this new incremental cooperative rebalance.
Just as before, all members must start by sending a JoinGroup request. But this time, everyone gets to hold onto all of their owned partitions. Instead of revoking them, each consumer just encodes them in their subscription and sends it to the group coordinator.
The group coordinator assembles all the subscriptions and sends them back to the group leader, also as before. The leader assigns partitions to consumers however it wants, but it must remove any partitions that are transferring ownership from the assignment. The assignor can leverage the owned partitions encoded in each subscription to enforce the rule.
From there, the new assignment—minus any to-be-revoked partitions that are currently owned—is passed on to each member. Consumers take the difference with their current assignment, then revoke any partitions that don’t appear in their new assignment. Likewise, they will add any new partitions in the assignment. For every partition that appears in both their old and new assignments, they don’t have to do a thing. Very few rebalances require a significant migration of partitions between consumers, so in most cases, there will be little or absolutely nothing to do.
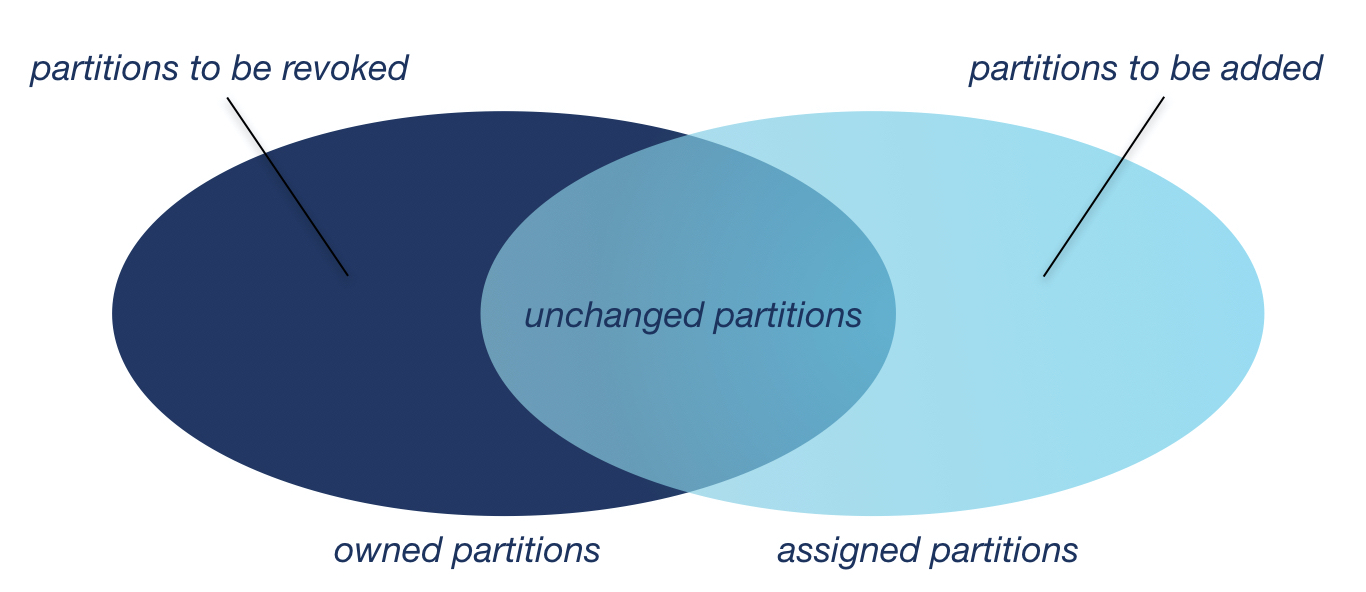 Figure 4. The Venn diagram of partitions. Why revoke everything when you can just revoke what needs to be revoked?
Figure 4. The Venn diagram of partitions. Why revoke everything when you can just revoke what needs to be revoked?
Any member that revoked partitions then rejoins the group, triggering a second rebalance so that its revoked partitions can be assigned. Until then, these partitions are unowned and unassigned. The synchronization barrier hasn’t been dropped at all; it turns out that it just needed to be moved.
When the follow-up rebalance rolls around, all successfully revoked partitions will by definition be absent from the encoded owned partitions. The partition assignor is free to assign them to their rightful owner.
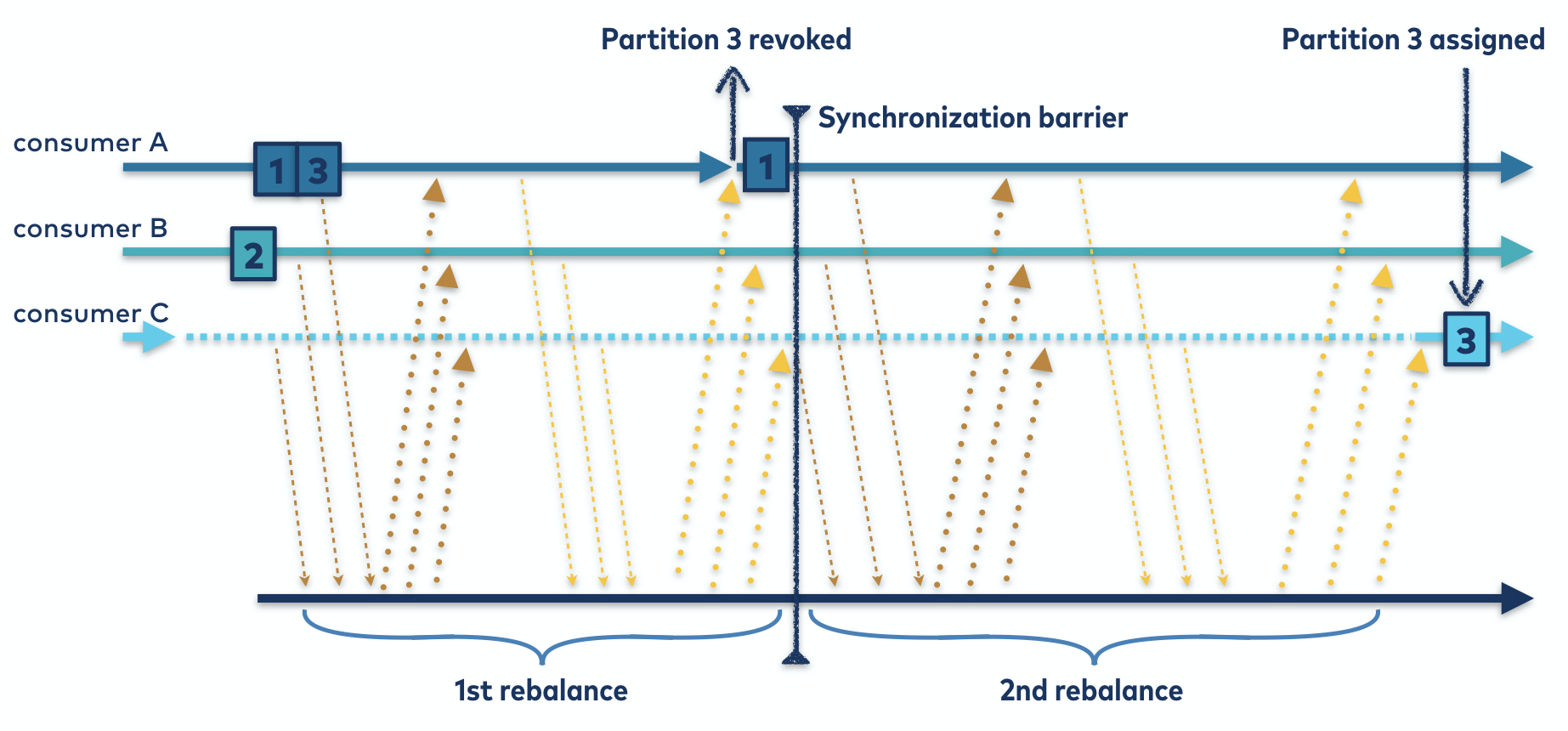 Figure 5. The cooperative rebalancing protocol. By trading off a second rebalance to enforce the synchronization barrier, you can avoid revoking all partitions of all consumers.
Figure 5. The cooperative rebalancing protocol. By trading off a second rebalance to enforce the synchronization barrier, you can avoid revoking all partitions of all consumers.
DIY cooperative rebalancing
As you may have guessed, it’s up to the partition assignor to make this work. What might be less obvious is that it’s up to only the partition assignor—you can turn on cooperative rebalancing by simply plugging in a cooperative assignor.
Luckily, a new out-of-the-box partition assignor has been added to the toolbox: the CooperativeStickyAssignor. You may be familiar with the existing StickyAssignor—the CooperativeStickyAssignor takes things a step further and is both sticky and cooperative.
We introduced this assignor to make enabling cooperative rebalancing in Apache Kafka as easy as setting a config, without the need to introduce yet another client config. But the more subtle motivation lay in packaging it as a sticky assignor. By doing this, we can guarantee that the assignor plays along nicely with the cooperative protocol.
What does this mean, and why is it so important? Take the RoundRobinAssignor as an example, which does not play nicely with cooperative rebalancing. The assignment produced by the round robin assignor changes every time the group membership or topic metadata changes. It makes no attempt to be sticky—to return partitions to their previous owners. But remember, this is the incremental cooperative rebalancing protocol. The whole algorithm works by letting the assignment change incrementally, partition by partition, from the old one to the new. If the new assignment is entirely different than the previous one, then the incremental change is the entire assignment. You would just end up back at the eager protocol where you started, but with more rebalances.
So the sticky aspect is just as important as the cooperative in the new assignor. And thanks to the owned partitions encoded in the subscription, being sticky is as easy as ever.
Besides being sticky, the CooperativeStickyAssignor must also be sure to remove any partitions that must be revoked from the assignment. Any assignor that claims to support the cooperative protocol must fulfill that contract. So if you’re looking to DIY with a custom cooperative assignor, you can write one from scratch or even adapt an old eager assignor; just make sure it satisfies the new rules.
One final word of caution to anyone looking to switch to the new protocol with a live upgrade or assignor swap: follow the recommended upgrade path. A rolling upgrade will trigger rebalances, and you don’t want to get caught in the middle of one with half the group following the old protocol and half the group on the new one. For more details on how to safely upgrade to cooperative rebalancing, read the release notes.
Can you DIY in Kafka Streams?
If you are a Kafka Streams user and have made it this far, you’re probably wondering how all this affects you. How can you use this new protocol when you can’t choose which partition assignor gets used?
Fortunately, you don’t have to. The management and choice of the rebalancing protocol is embedded in the StreamsPartitionAssignor, and cooperative rebalancing is now turned on by default. You just need to start your application and watch it run. In fact, you don’t even need to watch it—but monitoring your app is always a good practice.
So what does this actually mean for Streams? To understand what’s changed and what hasn’t, let’s follow the adventures of an imaginary Kafka Streams developer—call him Franz. Franz is running an application using version 2.3 of Kafka Streams. His topology uses a lot of local state stores, his input topics have hundreds of partitions, and his application relies on the interactive queries (IQ) feature to query the data in these state stores during processing.
Things appear to be going smoothly, but thanks to responsible monitoring, Franz notices that his instances are running at their maximum capacity. It’s time to scale out. Unfortunately, adding new instances requires the entire group to rebalance. Franz is frustrated to see that every single instance has stopped processing every single partition, and the interactive queries are disabled for the duration of the rebalance. Plus, the rebalance takes so long, which is no surprise given how many state stores and partitions need to be closed and reopened. But, do they really need to?
Fortunately, he sees that Kafka 2.4 introduced a new rebalancing protocol, which he hopes will help. Franz upgrades his Streams application, carefully following the specific upgrade path outlined in the release notes to ensure a safe rolling upgrade to the cooperative protocol. As soon as the group has stabilized, he tries to scale out once again.
This time, things are much better. Instead of every store closing and reopening, only the few partitions that end up on the new instance are revoked. Franz also discovers that IQ remains available on all running instances, and instances that were still restoring data to their state stores are able to continue doing so throughout the rebalance. Standby replicas also continue consuming from their stores’ changelog topics, giving them time to catch up with their active counterparts and take over with little restoration time in the event of failure.
Even better, when Franz upgrades to the most recent version of Kafka, he discovers that even the running active tasks can continue to process new records throughout the rebalance, and the entire application stays up and running for the whole time. No longer is he forced to make a choice between scaling and avoiding application-wide downtime.
Eager vs. cooperative: Who wins?
While there are clear advantages to cooperative rebalancing, concrete numbers always have the last word. So we ran a benchmark to quantitatively compare the two rebalancing protocols and identify the winner.
We ran a benchmark of a simple stateful Kafka Streams app with 10 instances. To simulate a common rebalance-triggering scenario, we performed a rolling bounce once the group reached a steady state of running. The total throughput of the application over time is displayed below. The throughput here is measured as the number of records processed per second, aggregated over the 10 instances with error bars to reflect their variance. The start and end of the rolling bounce are quite apparent from the drop in throughput alone.
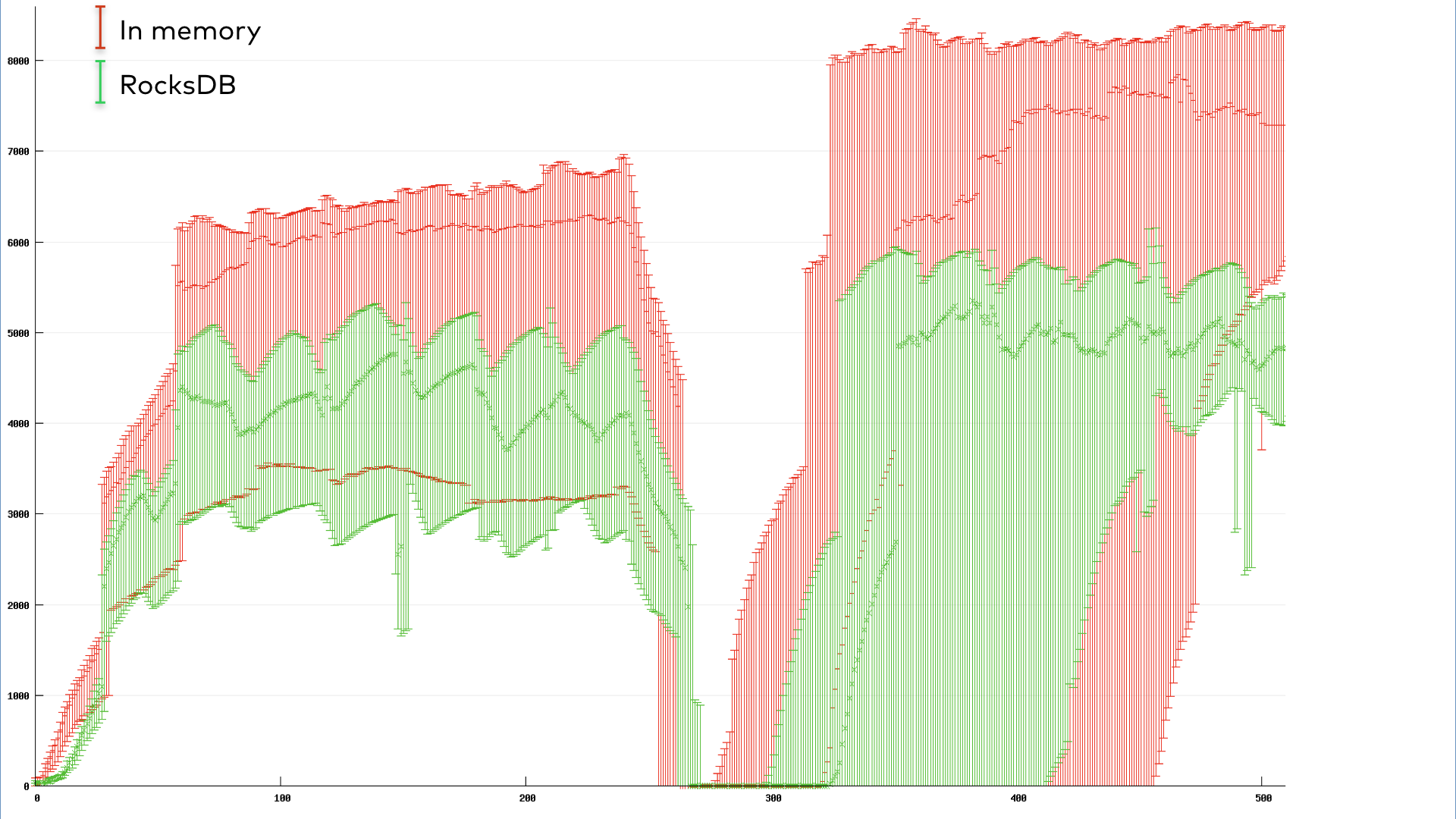
Figure 6. Throughput (records/s) vs. time (s) for a 10-instance eager rebalancing Streams app going through a rolling bounce.
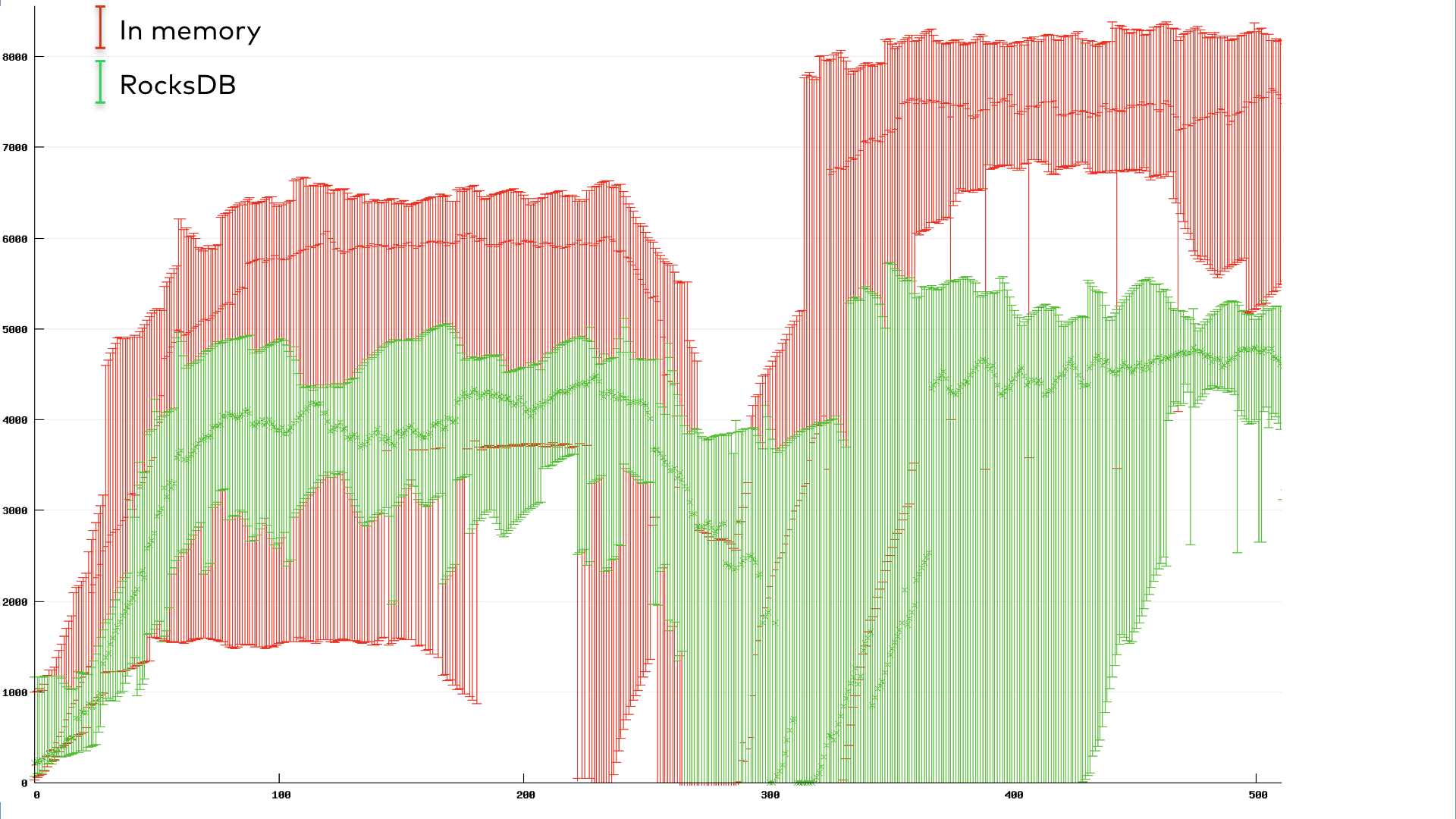
Figure 7. Throughput (records/s) vs. time (s) for a 10-instance cooperative rebalancing app going through a rolling bounce.
The green corresponds to an application using the default RocksDB-backed state stores, while the red corresponds to in-memory stores. The cooperative RocksDB app shows only a slight drop in throughput during the bounce due to the rebalancing overhead. Interestingly, the cooperative in-memory app appears to still take a large hit in throughput, although it does recover faster than the eager case. This reflects an inherent trade-off in the choice of backing state store: an in-memory store will be faster in the steady state but suffer a larger setback upon restart, as it must restore all of its ephemeral data back into memory from the changelog topic.
The graphs in Figures 6 and 7 provide a visually striking case for the cooperative protocol. But the numbers are just as striking: the eager protocol had a total pause time of 37,138 ms, while the cooperative protocol spent only 3,522 ms paused. Of course, the numbers will vary from case to case. We encourage you to try out cooperative rebalancing in your application and measure the difference yourself.
Conclusion
The stop-the-world rebalancing protocol has been haunting users of the Kafka clients, including Kafka Streams and ksqlDB up the stack, since the very beginning. But rebalances are essential for distributing resources effectively and evenly, and will only become more common as more and more applications move to the cloud and demand dynamic scaling. With incremental cooperative rebalancing, this doesn’t have to hurt.
The basic cooperative rebalancing protocol was introduced in version 2.4 of Apache Kafka. The ability to poll new data and unleash the full power of incremental cooperative rebalancing was added in version 2.5. If you’ve been living under the shadow of frequent rebalancing, or in fear of the downtime of scaling out, download the Confluent Platform, which is built on the latest version of Kafka.
Further work to improve the availability of Kafka Streams and ksqlDB applications that manage large amounts of state is coming soon. With KIP-441, we will begin to warm up tasks on new instances before switching them over, closing another availability gap that scales with the amount of state. Combined with incremental cooperative rebalancing, it will allow you to launch a truly scalable and highly available app—even during rebalances.
Whether you’re building a plain consumer app from the ground up, doing some complicated stream processing with Kafka Streams, or unlocking new and powerful use cases with ksqlDB, the consumer group protocol is at the heart of your application. This is what allows your ksqlDB application to scale and smoothly handle failures. It’s interesting to peek under the covers and understand what’s going on, but the best part about the rebalance protocol is that you don’t have to. As a user, all you have to know is that your ksqlDB application can be fault tolerant without sacrificing high availability.
Interested in more?
Now that you have some insight into what goes on when you launch an application:
- Learn more about smooth scaling and uninterrupted processing on the Streaming Audio podcast
- Head over to ksqldb.io to get started and see what you can do with a highly available streaming database.
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.