Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
VERGLEICHEN
Confluent Cloud vs. Amazon MSK: Apache Kafka® – Kosten und Fähigkeiten
Um das volle Potenzial von Apache Kafka® ausschöpfen zu können, werden dedizierte Engineering-Ressourcen und umfassendes Know-how für verteilte Systeme benötigt. Bei zunehmender Nutzung wird selbstverwaltetes Kafka zu einem komplexen Balanceakt. Entweder müssen Kosten für überdimensionierte Cluster oder ein erhöhtes Risiko ungeplanter Ausfallzeiten in Kauf genommen werden.
Dieser ausführliche Vergleich von Confluent Cloud und Amazon MSK zeigt, wie beide in Bezug auf Skalierbarkeit, Ausfallsicherheit und Plattformfähigkeiten abschneiden – und wie Confluent die Gesamtbetriebskosten für selbstverwaltetes Kafka um 40 bis 70 % senkt.
70 % effizienterer Betrieb im Vergleich zu self-managed, gehostetem Apache Kafka®
Ob für die Entwicklung von Echtzeit-Daten-Pipelines oder KI-Agenten, Kafka ist die ideale Wahl. Sein verteiltes Design ist für hohe Durchsätze und niedrige Latenzzeiten ausgelegt, erfordert aber auch fundiertes Know-how, um es ohne kostspielige Überprovisionierung oder Ausfallrisiken zu verwalten, zu sichern und in großem Umfang zu optimieren.
Confluent, gegründet von den ursprünglichen Miterfindern von Kafka, hat 3 Millionen Entwicklungsstunden in die Neukonzipierung von Kafka investiert, um es bis zu 70 % effizienter in der Cloud betreiben zu können. Das Ergebnis: Kora, die Cloud-native Kafka-Engine, die unsere vollständig verwaltete Daten-Streaming-Plattform antreibt mit:
-
Serverlosen, automatisch skalierenden Clustern, die über die Hälfte der Infrastrukturkosten einsparen
-
Dreimal höherer Ressourceneffizienz als ein self-managed Single-Tenant-Cluster
-
~50 % geringerer Cluster-Latenz im Vergleich zu self-managed Clustern, um die Nutzung auszuweiten
-
Optimiertem Routing und API-Integrationen, die Netzwerkkosten senken
Heute treibt Kora 30.000 Confluent Cloud-Cluster an, die über 3 Billionen Nachrichten pro Tag über AWS, Google Cloud und Microsoft Azure hinweg verarbeiten.
Zum Kafka-Kosten-Webinar anmelden
MSK Zookeeper Migration: So wird ein kritisches Update zum strategischen Vorteil
Mit dem Ende des Supports von Kafka für ZooKeeper im Mai 2026 müssen alle Kafka-Nutzer, die einen auf ZooKeeper basierenden Cluster betreiben, eine umfassende Migration zu KRaft durchführen, um zu vermeiden, dass sie mit veralteten Kafka-Versionen arbeiten.
Was bedeutet das für MSK-Kunden?
-
Zookeeper-basierte Cluster erhalten von der Open-Source-Community keine kritischen Updates mehr – auch keine Sicherheitspatches und Fehlerbehebungen mehr. Das bedeutet, dass MSK-Kunden mit einer Self-Managed-Version von Kafka arbeiten werden, die potenzielle Sicherheits- und Steuerungsprobleme mit sich bringt.
-
MSK bietet kein In-Place-Upgrade: MSK-Kunden müssen einen neuen KRaft-fähigen Cluster einrichten und Daten sowie Workloads manuell migrieren.
-
Die MSK Express-Migration ist nicht nahtlos: Die Umstellung von MSK Provisioned Standard auf MSK Express erfordert ebenfalls zusätzlichen Aufwand.
Warum zu Confluent wechseln?
Diese wichtige Migration ist der perfekte Zeitpunkt für eine Neubewertung. Warum sich die Mühe machen, ohne Vorteile zu genießen? Jetzt auf eine vollständig verwaltete Daten-Streaming-Plattform umsteigen und von allen erweiterten Funktionen und Kosteneinsparungen profitieren!
-
Vollständig verwaltet und Cloud-nativ: Vollautomatisierter Kafka-Lebenszyklus (Bereitstellung, Upgrades, Skalierung und Partitionsausgleich), so dass sich die Nutzer auf die Anwendungen anstatt auf den Betrieb konzentrieren können.
-
Verbesserter Support: Fachkundiger Kafka-Support aus erster Hand und ein SLA von 99,99 % für die gesamte Streaming-Plattform, die zehnmal effizienter ist als MSK.
-
Umfassende/s Integrationen & Ecosystem: die größte Auswahl verwalteter Connectors, einschließlich weiterer AWS-Serviceintegrationen sowie Unterstützung für Multi-Cloud- und SaaS-Lösungen.
-
Data Governance: eine umfassende Suite von Governance-Features, darunter Schema Registry, die Datenqualität, Konsistenz und die zentrale Informationsquelle für alle Datenströme gewährleistet.
-
Überall: Confluent Cloud unterstützt Multi-Cloud-Deployments über AWS, Azure und Google Cloud sowie hybride Architekturen, die Cloud- und On-Premises-Umgebungen umfassen.
-
TCO-Einsparungen: Bei der Migration zu Confluent Cloud und durch die Nutzung von Funktionen wie PNI (Private Network Interface) und Auto-Scaling garantiert Confluent, die Kosten für AWS MSK zu halten oder zu unterbieten
„[Mit Confluent] haben wir unsere prognostizierten jährlichen Kosten um 69 % gesenkt und haben Monate an Planung [gespart], die wir andernfalls in Meetings und saisonale Prognosen hätten investieren müssen.“
Justin Dempsey, Senior Manager bei SAS Cloud
„Seit wir Horus, unsere globale IPV4-Scanning-Plattform, auf Confluent aufgebaut haben, konnten wir im Vergleich zu Open-Source-Kafka oder MSK über eine Million Dollar einsparen.“
Jared Smith, Senior Director, Threat Intelligence bei SecurityScorecard
„Mit Confluent erreichen wir true Elastizität, die für die Skalierung bei großen Einzelhandel-Events wie Black Friday oder bei Abschlüssen großer Neukunden entscheidend ist – und das alles mit einem höheren SLA.“
Ian Compton, Technology Director bei RevLifter
Kafka-Betriebskosten – MSK vs. Confluent
Wenn die interne Akzeptanz zunimmt und die Kafka-Präsenz wächst, müssen Unternehmen mehr Zeit und Ressourcen aufwenden für:
-
Planung, Dimensionierung und Verwaltung der Clusterbereitstellung
-
Software-Patching und -Aktualisierung
-
Failover-Design und Verfügbarkeitsplanung
-
Schließen von hochriskanten Governance- und Sicherheitslücken
-
Planung und Optimierung hoher Zuverlässigkeit
-
Manuellen Lastausgleich
Das volle Potenzial von Kafka auszuschöpfen, ist mit erheblichen finanziellen und Opportunitätskosten verbunden. Im Durchschnitt verstreichen mehr als 2 Jahre bis zur umfänglichen Produktionsphase und es entstehen Entwicklungs- und Betriebskosten für die Plattform von 3-5 Millionen Dollar. Sowohl Confluent Cloud als auch Amazon MSK versprechen, diesen operativen Aufwand zu übernehmen. Aber „verwaltete“ Kafka Services sind nicht alle gleich konzipiert und bei der Nutzung von gehostetem Kafka über Cloud-Service-Provider müssen Unternehmen weiterhin den größten Aufwand stemmen.
In diesem Vergleich verwalteter Kafka-Services zeigen wir, wie viel mehr mit wirklich verwaltetem, serverlosem Kafka und einer Daten-Streaming-Plattform, die einen ROI von 257 % liefert und sich in weniger als 6 Monaten amortisiert, erreicht und gespart werden kann.
Confluent Cloud kostenlos testen
| Confluent Cloud | Amazon MSK | |
|---|---|---|
| Zusammenfassung | Confluent beseitigt den Großteil des manuellen Aufwands dank Automatisierungen zur Skalierung von Kafka-Clustern und Connector-Instanzen. | Der operative Aufwand bleibt hoch, da Amazon MSK nur begrenzte Automatisierungen für Deployment-Aufgaben bietet, selbst für MSK Serverless Cluster |
| Automatisierte Produktfähigkeiten vs. manuelle Vorgänge und Custom-Entwicklung |
Self-managed:
Automatisiert auf allen Clustern:
Benutzerdefiniert:
*Auf allen Confluent Cloud-Clustern |
Self-managed:
Benutzerdefiniert:
Automatisiert:
*Nur auf MSK Serverless-Clustern |
| Die freie Wahl | Verfügbar auf AWS, Google Cloud und Microsoft Azure | Nur auf AWS verfügbar |
Verwaltung, Monitoring und Wartung auf Confluent Cloud vs. Amazon MSK
Obwohl MSK einige operative Lücken schließt, hat es immer noch viele Einschränkungen. Die Selbstverwaltung oder Nutzung von gehostetem Kafka birgt erhebliche direkte und indirekte Kosten, darunter:
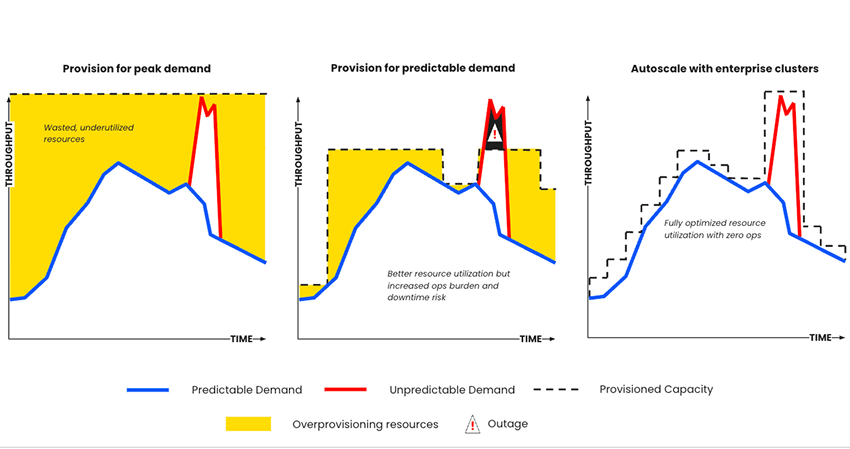
- Hohe Infrastrukturausgaben aufgrund überprovisionierter Cluster: Eine überdimensionierte Bereitstellung wird benötigt, um schwankende Nachfragen zu bedienen und aufgrund fehlender Möglichkeiten, Speicher zu skalieren, ohne die Rechenleistung zu erhöhen, sowie um Leistungseinbußen durch manuelle Konfigurationen, Upgrades, Patches und manuelles Rebalancing zu bewältigen.
-
Operativer Aufwand und begrenzte Ressourcen: Wertvolle Zeit und Ressourcen müssen für die Bereitstellung und Kapazitätsplanung, Upgrades und Monitoring anstatt für echte Differenzierung des Unternehmens aufgewendet werden. Zudem entstehen Kosten für die Rekrutierung, Einstellung und Bindung von Kafka-Experten
-
Ungeplante Ausfälle: Bei zunehmender Kafka-Nutzung für mehr Anwendungsfälle, Apps, Datensysteme, Teams und Umgebungen steigt auch das Risiko kostspieliger Downtime und Sicherheitsprobleme
Diese Kosten häufen sich zunehmend, was zu einer verzögerten Wertschöpfung, erhöhten Gesamtbetriebskosten und einem höheren Risiko von Umsatzverlusten aufgrund ungeplanter Ausfallzeiten, Sicherheitsverletzungen und Datenverlusten führt.
Im Folgenden beleuchten wir, wie sich Confluent Cloud und Amazon MSK hinsichtlich der Reduzierung des operativen Aufwands und der Lösung häufiger Kafka-Herausforderungen unterscheiden.
Whitepaper zu Kafka vs. Confluent vs. MSK lesen
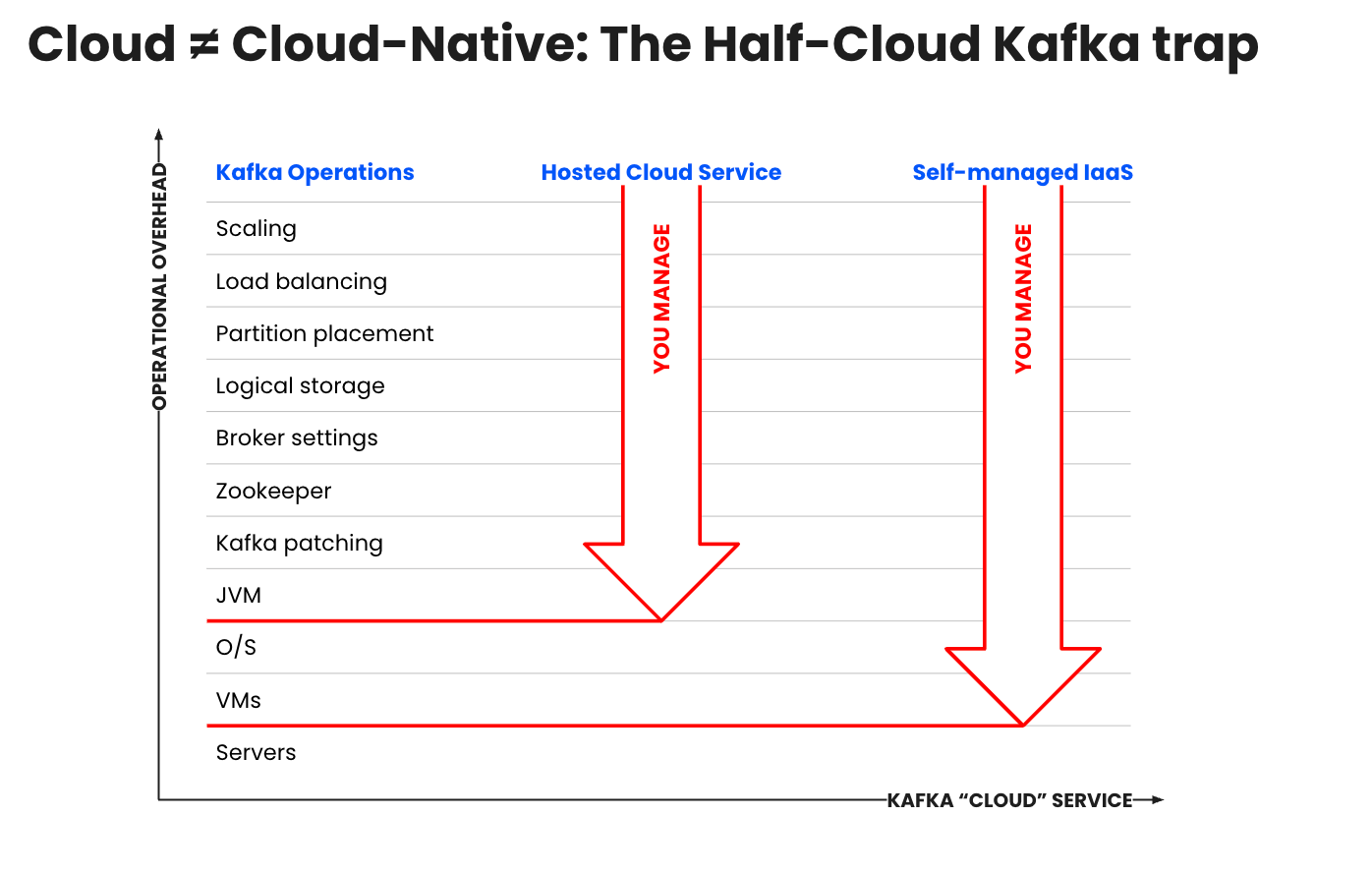
| Service | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Bereitstellung | Self-Service, On-Demand für Kafka, Schema Registry und Flink | Self-Service, On-Demand nur für Kafka | Self-Service, On-Demand nur für Kafka |
| Autoskalierung | Serverlose, automatisch skalierende Cluster, abgestimmt für jeglichen Workload-Umfang | Manuelle Skalierung | Elastische Skalierung auf begrenzte Kapazität (200/400 MBps) |
| Cluster-Typen | Flexible, kostengünstige Clustertypen für jede Workload und jeden Anwendungsfall | Standard- und Express-Cluster, die beide eine manuelle Skalierung erfordern | MSK Serverless-Cluster sind die vorab bereitgestellten Cluster von MSK, geeignet für unvorhersehbare, unternehmenskritische Workloads |
| Infrastructure as Code | Sowohl für die Steuerungsebene als auch für die Datenebene | Nur für die Steuerungsebene | Nur für die Steuerungsebene |
| Infrastruktur-Monitoring | Proaktives Monitoring | Manuelles Monitoring | Proaktives Monitoring |
| Topic-Monitoring | Kostenlose, voraggregierte Metriken | Metriken auf Topic-Ebene kosten extra | Standard-Monitoring ist kostenlos |
| Upgrades | Immer die neueste stabile Version | Eingeschränkte Versionsunterstützung | Eingeschränkte Versionsunterstützung |
| Software-Patches | Proaktive Korrekturen | Reaktive Fixes | Reaktive Fixes |
| Cluster-Erweiterungen | Elastische Skalierbarkeit | Manuelles Daten-Rebalancing | Elastische Skalierbarkeit |
| Connectors skalieren | Vorgefertigt und vollständig verwaltet | Selbst entwickelt und verwaltet | Selbst entwickelt und verwaltet |
Wie vereinfachen Confluent Cloud und Amazon MSK die Cluster-Dimensionierung?
-
Confluent Cloud nutzt eine durchsatzbasierte Dimensionierung: Diese eliminiert umständliche Leistungstests und reduziert die Infrastrukturkosten mit elastisch bis auf null skalierbaren Clustern, bei denen nur für die tatsächliche Nutzung bezahlt wird.
-
MSK Provisioned nutzt eine Broker-basierte Dimensionierung: Für Leistungstests zur Bestimmung der Brokertypen und -anzahl sowie für die überdimensionierte Bereitstellung von Infrastruktur, um spätere komplexe Erweiterungen aufgrund mangelnder automatischer Skalierung zu vermeiden (vier Vorgänge pro Tag), müssen Zeit und Ressourcen eingeplant werden.
-
MSK Serverless nutzt Durchsatz-basierte Dimensionierung: Kafka-Cluster zusammen mit Glue Schema Registry und Flink bereitstellen. Für Connectors und Kafka-Proxy sind individuelle Anpassungen erforderlich.
Wie automatisieren Confluent Cloud oder Amazon MSK die Bereitstellung und Verwaltung?
-
Confluent Cloud bietet Self-Service, On-Demand-Provisionierung für die gesamte Plattform: Kafka-Cluster zusammen mit jeder anderen Confluent Cloud-Komponente bereitstellen, einschließlich Schema Registry, Connect und Confluent Cloud für Apache Flink®. Außerdem können Terraform-Provider genutzt werden, um die Verwaltung sowohl von Ressourcen der Steuerungsebene (wie Cluster und Schema Registry) als auch von Ressourcen der Datenebene (wie Topics und ACLs) zu automatisieren.
-
Amazon MSK bietet Self-Service, On-Demand-Provisionierung, aber nur für Kafka: Kafka-Cluster zusammen mit Glue Schema Registry und Flink bereitstellen. Für Connectors und Kafka-Proxy, sowohl für MSK Provision als auch für MSK Serverless, sind benutzerdefinierte Schritte erforderlich. Terraform kann nur Ressourcen der Steuerebene bereitstellen und verwalten. Für die Verwaltung der Datenebene-Ressourcen werden Custom-Operatoren und Prozesse benötigt.
Bieten Confluent Cloud oder Amazon MSK sofort einsatzbereites Monitoring?
-
Confluent Cloud bietet proaktives Infrastruktur-Monitoring und kostenlos aggregierte Metriken für Topic-Monitoring. So liegt der Fokus dank proaktivem Cluster-Monitoring und proaktiver Wartung durch die Kafka-Experten stets auf der App-Entwicklung. Infinite Storage ermöglicht Anwendungsfälle mit unbegrenztem Speicher auf Cluster-Ebene und verringert das Risiko von Ausfällen im Zusammenhang mit Festplattenspeicher. Zentrale, vorab auf Topic- und Cluster-Ebene aggregierte Metriken, sind ohne zusätzliche Kosten verfügbar und können über die Metrics API im bevorzugten Drittanbieter-Monitoring-Service genutzt werden.
-
MSK Provisioned bietet manuelles Infrastruktur-Monitoring und Topic-Level-Metriken gegen Aufpreis. Für das Monitoring von Broker-Metriken wie der CPU-Auslastung zur proaktiven Verwaltung der Cluster-Performance müssen Ressourcen zugewiesen werden. Um Fehler aufgrund der Speicherkapazität zu verhindern, müssen zudem Alerts erstellt und überwacht werden. Durch die Nutzung und manuelle Aggregation von Metriken je Broker und Topic-Level für das Monitoring der Gesamtnutzung entstehen weitere Kosten.
-
MSK Serverless-Cluster bieten proaktives Infrastruktur-Monitoring und kostenloses Standard-Topic-Monitoring. Dies ermöglicht eine Fokussierung auf die App-Entwicklung dank proaktivem Cluster-Monitoring und proaktiver Wartung. Infinite Storage ermöglicht Anwendungsfälle mit unbegrenztem Speicher auf Cluster-Ebene und verringert das Risiko von Ausfällen im Zusammenhang mit Festplattenspeicher. Kostenloser Zugriff auf Topic-Level-Metriken über die CloudWatch-Konsole, einem separaten Monitoring-Tool für mehrere AWS-Produkte. Metriken auf Partitions-Level oder native Integration mit beliebten Monitoring-Tools wie Datadog und Dynatrace werden nicht unterstützt.
Wie erfolgt die Kafka-Wartung in Confluent Cloud im Vergleich zu Amazon MSK?
-
Confluent Cloud wird immer auf die neueste stabile Version aktualisiert und Bugs und Schwachstellen werden proaktiv behoben. Es bietet ein SLA von 99,99 %, einschließlich Kafka, Fehlerbehebungen, Patching und vieles mehr.
-
Amazon MSK bietet eingeschränkte Versionsunterstützung und reaktive Fehlerbehebungen: MSK unterstützt lediglich ein Subset der Kafka-Releases und Upgrades müssen manuell ausgelöst werden, sobald AWS diese nach dem geplanten Apache-Release ermöglicht. MSK bietet ein SLA von 99,9 % und bietet nur ausgewählte Versionen von Kafka an. Fehler aufgrund von Kafka-Software sind nicht durch MSK-Uptime-SLAs abgedeckt. Die Nutzung eines Subsets von Releases führt zwangsläufig zu einem reaktiven Ansatz bei der Behebung von Schwachstellen. Bei serverlosen MSK-Clustern sind aufgrund von unterbrechungsfreien, fortlaufenden Upgrades keine Eingriffe erforderlich – MSK unterstützt nur ein Subset von Kafka-Versionen, wobei die neueste Version unbekannt und vollständig abstrahiert ist.
Wie erweitern und verkleinern Confluent Cloud und Amazon MSK Cluster?
-
Confluent Cloud skaliert automatisch und weist Clustern automatisch Ressourcen zu: Confluent bewältigt Consumer-Lag, wenn der Durchsatz im GBit/s-Bereich hoch- und herunterskaliert, dank vollständig elastischer, automatisch skalierender Cluster, die über die Hälfte der Infrastrukturkosten einsparen. So wird eine überschüssige Bereitstellung von Cluster-Rechenleistung vermieden, während Vorhaltungszeiten dank unbegrenztem Speicherplatz selbst festgelegt werden können.
-
Amazon MSK erfordert manuelles Daten-Rebalancing für Provisioned-Cluster und für selbst entwickelte, self-managed Connectors: Nachdem Broker zu einem Cluster hinzugefügt wurden, ist ein manueller Daten-Rebalancing-Prozess mit Cruise Control notwendig. Tiered Storage ist verfügbar, benötigt aber immer noch EBS-Volumes, die auf bis zu 16 TB je Broker mit einem Limit von 30 Brokern skaliert werden können. Es können selbst oder Community-entwickelte Connectors genutzt werden, jedoch ohne direkten technischen Support von AWS, da lediglich grundlegende MSK Connect-Infrastruktur abgedeckt wird.
-
MSK Serverless-Cluster verfügen über elastische Skalierung bis zu einer bestimmten Höchstgrenze und benötigen trotzdem selbst entwickelte, self-managed Connectors: Müheloses Hoch- und Herunterskalieren von 0 auf 200 MBit/s dank automatischem Cluster-Rebalancing verhindert eine überschüssige Bereitstellung von Cluster-Rechenleistung, wenn die Topic-Vorhaltung mit Infinite Storage verlängert wird.
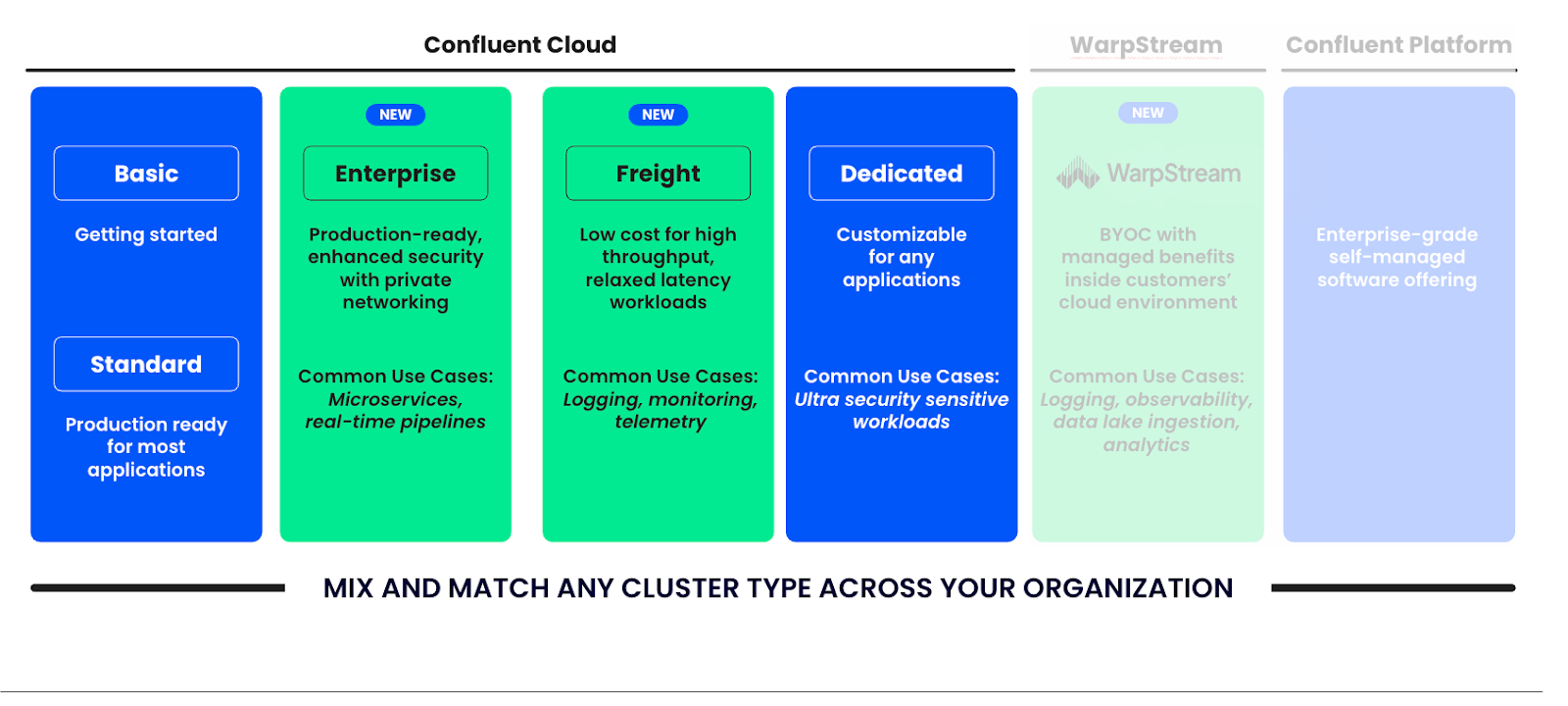
Die umfassende Daten-Streaming-Plattform von Confluent im Vergleich zu gehostetem Kafka auf AWS
Warum vertrauen Unternehmen branchenübergreifend auf Confluent? Confluent bietet Fähigkeiten auf Enterprise-Niveau, die weit über das Feature-Set von MSK hinausgehen, und stellt eine umfassende Daten-Streaming-Plattform bereit, um unzählige Daten-Streaming-Anwendungsfälle zu erschließen.

| Service | Confluent Cloud | Amazon MSK | MSK Serverless |
|---|---|---|---|
| Kafka UI | Vollständig verwaltet | Nicht verfügbar | Nicht verfügbar |
| Authentifizierung | Umfassende Authentifizierung | Umfassende Authentifizierung | Eingeschränkte Authentifizierung |
| Verschlüsselung | Ende-zu-Ende-Verschlüsselung | Nicht unterstützt | Nicht unterstützt |
| Connectors | Vorgefertigt und vollständig verwaltet | Individuell entwickelt und self-managed | Individuell entwickelt und self-managed |
| Data Governance | Vollständig verwaltet | Nicht verfügbar | Nicht verfügbar |
| Datenstromverarbeitung | Vollständig verwaltet | Erhöht die Komplexität | Erhöht die Komplexität |
| Zero-ETL für Streams-to-Tables | Jetzt mit Tableflow verfügbar | Nicht verfügbar | Nicht verfügbar |
Welche Sicherheit-Features auf Enterprise-Niveau bieten Confluent Cloud und Amazon MSK?
-
Confluent Cloud unterstützt umfassende Authentifizierung für alle Cluster-Typen: Nur authentifizierte Clients erhalten Zugriff auf Cluster. Confluent Cloud unterstützt SASL/PLAIN und SASL/OAUTHBEARER (in Preview) als Authentifizierungsmechanismen. Client-Side Field Level Encryption in Confluent Cloud bietet eine zusätzliche Sicherheitsebene, indem sensible Daten auf dem Client verschlüsselt und sowohl auf dem Client als auch auf dem Server geschützt werden. Außerdem wird die Sicherheit während der Datenübertragung zwischen Producern und Consumern aufrechterhalten.
-
Amazon MSK unterstützt umfassende Authentifizierung für MSK Provisioned-Cluster, eingeschränkte Authentifizierung für MSK Serverless, aber keine Verschlüsselung: Alle MSK-Cluster lassen nur authentifizierten Zugriff zu, aber MSK Provisioned-Cluster unterstützen SASL/SCRAM, mTLS und IAM als Authentifizierungsmechanismen, während MSK Serverless-Cluster nur IAM als Authentifizierungsmechanismus unterstützen.
Welche Arten von Kafka-Connectors bieten Confluent Cloud und Amazon MSK an?
-
Confluent Cloud bietet über 120 vorgefertigte Connectors und über 80 vollständig verwaltete Connectors: Diese ermöglichen eine nahtlose und mühelose Integration in moderne und Legacy-Lösungen, sowohl On-Premises als auch in Public Clouds, mit einem kontinuierlich wachsenden Portfolio von mehr als 120 Connectors, die entweder als vollständig verwaltete oder als vorgefertigte Komponenten mit Confluent-Support verfügbar sind.
-
Amazon MSK unterstützt nur individuell entwickelte, self-managed Connectors: Kafka kann entweder mit selbst entwickelten oder einem kleinen Subset von Community-entwickelten Connectors in Datenlösungen integriert werden. Custom-Connectors erfordern Wartung, und Kafka-Community-Connectors werden nicht vom technischen Support von AWS abgedeckt.
Welche Governance-Fähigkeiten bieten Confluent Cloud und Amazon MSK?
-
Confluent Cloud bietet Stream Governance, eine Suite vollständig gemanagter Services, die die Verfügbarkeit, Integrität und Sicherheit der Daten verwalten: Stream Governance basiert auf drei zentralen strategischen Säulen: Stream Lineage, Stream Catalog und Stream Quality. Data Quality Rules garantieren qualitativ hochwertige Streams.
-
Amazon MSK erfordert die Verwendung von kostenlosen Community-Tools ohne Support oder von kostenpflichtigen Tools von Drittanbietern zur Verwaltung von Daten in Kafka-Topics: MSK verfügt nicht über Lineage- oder Catalog-Funktionen. Zur Sicherstellung der Datenqualität können MSK und MSK Serverless in Confluent und Glue Schema Registry integriert werden. Broker-seitige Schema Validation, die Data-Producer zwingt, die Schema Registry zur Steuerung der Schema-Evolution zu verwenden, Data Quality Rules zur Validierung und Einschränkung einzelner Feldwerte innerhalb eines Datenstroms und Schema Linking, das Schemas über verschiedene Umgebungen hinweg synchronisiert, werden jedoch nicht unterstützt.
Welche Fähigkeiten zur Stream-Verarbeitung bieten Confluent Cloud und Amazon MSK?
-
Confluent bietet Serverlose Stream-Verarbeitung mit Confluent Cloud für Apache Flink®: Nutzer können einfach einen Flink-Cluster erstellen und mit der Stream-Verarbeitung in einer SQL-ähnlichen Sprache loslegen. Confluent Cloud unterstützt zudem den vollständig verwalteten AWS Lambda-Service.
-
Amazon MSK bietet Stream-Verarbeitung mit Flink, allerdings mit zusätzlicher Komplexität: MSK unterstützt Managed Service für Apache Flink (MSF), der zwar leistungsstark ist, aber auch Komplexitäten mit sich bringt. Nutzer müssen das Netzwerk konfigurieren, ein MSF Studio-Notebook erstellen, den Job mit einer SQL-ähnlichen Syntax erstellen, den Code testen und paketieren, auf S3 hochladen und aus dem hochgeladenen Code eine MSF-Anwendung erstellen.
Hybrid- und Multicloud mit Confluent vs. Vendor-Lock-in auf AWS
Konzipiert für Skalierbarkeit mit cloud-nativem Daten-Streaming ohne dabei an einen einzigen Cloud-Anbieter gebunden zu sein. Im Gegensatz zu Amazon MSK (nur auf AWS verfügbar) bietet Confluent echte Deployment-Flexibilität, um jede Kombination von On-Premises, Hybrid- und Multi-Cloud-Architekturen für eine nahtlose Dateninteroperabilität zu unterstützen:
-
Konsistenter, vollständig verwalteter Service auf AWS, Microsoft Azure und Google Cloud
-
Cloud-native, selbstverwaltetes Daten-Streaming mit Confluent Platform
-
Kontrolle und Kosteneffizienz mit WarpStream BYOC
Darüber hinaus bietet Cluster Linking eine beständige Brücke, um Daten zwischen jeder Umgebung in Echtzeit zu synchronisieren.
Individuelle Kosteneinsparungsschätzung erhalten
Jetzt einen individuellen Kostenvergleich erhalten, um die Einsparungen mit Confluent Cloud im Vergleich zu Amazon MSK zu ermitteln. Einfach das Kontaktformular ausfüllen und ein Mitglied unseres Teams meldet sich, um bei der Berechnung der Einsparungen mit Confluent zu helfen und weitere Fragen zu beantworten.
Noch nicht bereit, mit dem Vertrieb zu sprechen? Jetzt weiterführende Ressourcen entdecken:
Confluent Cloud vs. Amazon MSK: FAQs
Is Confluent Cloud more cost-effective than Amazon MSK?
Yes, Confluent Cloud is more cost-effective than Amazon MSK because of cost savings from:
-
Reduced infrastructure costs: Confluent Cloud’s serverless, cloud-native architecture eliminates the need for over-provisioning that is common with MSK’s node-based pricing. Features like Infinite Storage and Tiered Storage decouple compute and storage, further reducing infrastructure spending. For example, SecurityScorecard saved over $1M in infrastructure and operational costs by migrating to Confluent Cloud
-
Lower operational overhead: Offloading complex and time-consuming operational tasks—such as capacity management, scaling, and upgrades—to Confluent Cloud allows you to reallocate valuable engineering resources to innovation instead of infrastructure management. One customer reported they would have needed to hire at least 10 more people to manage Kafka themselves.
-
Minimized downtime and risk: Confluent Cloud offers a 99.99% uptime SLA for production workloads. Compared to MSK (with a 99.9% SLA with exclusions for Kafka failures and customer configuration failures), Confluent’s SLA delivers higher reliability and reduces the substantial hidden costs associated with downtime.
Choosing Confluent Cloud can reduce your self-managed Kafka costs by 40-70%.
What are the main cost drivers of Confluent Cloud vs Amazon MSK?
The main cost drivers of Confluent Cloud are:
-
Usage based consumption: Confluent Cloud’s pay-as-you-go pricing is based on actual usage (e.g., throughput) rather than provisioned infrastructure. This pay-as-you-go model eliminates the need for over-provisioned, underutilized clusters that typically lead double the infrastructure costs for self-managed Kafka vs fully managed on Confluent.
-
Managed horizontal scaling: Elastic Confluent Units for Kafka (eCKUs) are a Confluent Cloud’s unit of horizontal scalability for billing. eCKUs autoscale up and down based on workload. The cost includes the complete management of the platform, from infrastructure and scaling to monitoring and support, which is designed to reduce or eliminate the separate operational and support costs customers would otherwise incur.
The main cost drivers of Amazon MSK are:
-
Higher infrastructure spend: MSK uses node-based pricing, requiring users to pay for provisioned compute and storage, which often leads to over-provisioning to handle peak loads. Networking, particularly cross-Availability Zone (cross-AZ) traffic, can also become a significant hidden cost, sometimes accounting for 80-90% of total infrastructure expenses.
-
Self-managed operations and management: Since MSK is not a fully managed Kafka service, significant engineering resources are required for manual tasks like sizing, scaling, rebalancing partitions, patching, and monitoring. This includes the cost of hiring and retaining specialized Kafka talent.
-
Custom development and maintenance: MSK requires significant custom platform development and maintenance, which can take 2+ years to bring to production and cost $3-5M or more in costs. Because MSK is a hosted service rather than a complete platform with essential components included out-of-the-box, engineering teams must spend valuable time and resources building and maintaining their own solutions for developer tools, DevOps automation, infrastructure enhancements for reliability and disaster recovery, monitoring, integration, security controls, and governance.
-
Unplanned downtime and higher business risk: MSK's 99.9% SLA excludes failures in the underlying Kafka software, as well as failures due to customer errors in configuration, leaving customers responsible for resolving failures that can easily turn into major outages. The risk of outages due to storage limitations, manual scaling errors, or unresolved bugs can lead to substantial hidden costs, including lost revenue and reputational damage.
What are the pros and cons of MSK Serverless vs Confluent Cloud?
Confluent Cloud pros and cons include:
-
Pro: Confluent Cloud offers a complete, serverless experience that automates all operational aspects, from capacity planning and elastic scaling (to GBps+) to upgrades and monitoring.
-
Pro: Confluent Cloud goes far beyond core Kafka, providing a rich ecosystem of 120+ connectors, serverless Flink for advanced stream processing, and an enterprise-grade Stream Governance suite.
-
Pro: Confluent Cloud delivers significant cost savings through cost-efficient autoscaling and usage-based consumption (which prevents overprovisioned and underutilized clusters and cuts infrastructure costs by 50%+), lowers TCO 40-70% compared to self-managed Kafka by eliminating $1M in development and operations costs over 3 years, and with a 99.99% uptime SLA that reduces business risk.
-
Con: For smaller teams, projects with predictable workloads, or organizations that already have in-house Kafka expertise, Confluent's fully managed service and advanced features may not present a clear upfront financial advantage.
MSK Serverless pros and cons include:
-
Pro: MSK Serverless addresses some of MSK's operational challenges with pre-provisioning
-
Pro: MSK Serverless can elastically scale to a given quota without the need for manual rebalancing.
-
Pro: MSK Serverless offers unlimited storage (with a per-partition quota) without the manual configuration required by MSK Standard brokers.
-
Con: MSK Serverless has a strict throughput limit of 200MBps ingress and 400MBps egress, with no upgrade path for workloads that exceed this.
-
Con: MSK Serverless lack many mission-critical components, including a rich connector ecosystem, integrated stream processing (like Flink), and comprehensive, enterprise-grade security and governance tools.
-
Con: MSK Serverless has the same weak 99.9% SLA as MSK Provisioned, which does not cover Kafka-related failures.
-
Con: Like all MSK offerings, MSK Serverless has no multicloud support and is locked into the AWS ecosystem.
How does Confluent Cloud autoscale throughput compared to MSK?
Confluent Cloud offers true elastic, automated scaling from 0 to GBps, while Amazon MSK's elastic scaling capabilities are more limited and manual:
-
Confluent Cloud provides fully managed, automated, and elastic scaling. It can automatically scale clusters up and down from 0 to GBps+ to meet demand without interruption. Its cloud-native Kora engine uses an intelligent control plane and self-balancing algorithms to manage capacity, rebalance partitions, and eliminate the need for overprovisioning and underutilizing clusters to avoid outages. As a result, customers can save 50% or more on infrastructure costs.
-
Standard clusters on MSK Provisioned require manual sizing, scaling, and rebalancing. While you can add brokers to scale up, you cannot easily scale down and are more likely to have a large number of overprovisioned clusters at any given time. Modifying storage capacity can take anywhere from 6 to 24 hours. Express clusters on MSK Provisioned offer faster scaling and rebalancing, but it is still a manual process.
-
MSK Serverless offers some autoscaling but only within a lower quota limit (up to 200 MBps ingress and 400 MBps egress). There is no solution to upgrade beyond this quota without moving to a different offering.
How do Confluent and MSK differ in cluster provisioning speed?
Confluent Cloud can provision clusters in minutes, whereas provisioning an Amazon MSK cluster can take from 30 minutes to over an hour.
Is Confluent Cloud more reliable and performant than MSK?
Yes, Confluent Cloud is architected to be more reliable and performant than Amazon MSK and significantly reduces the risk of unplanned downtime compared to MSK:
-
Confluent's Kora engine provides native resilience with continuous monitoring, proactive replacement of degraded nodes, and automatic rebalancing to maintain availability without operator intervention. MSK lacks these native self-healing capabilities, requiring customers to manually identify and replace failed brokers.
-
Confluent Cloud offers a 99.99% uptime SLA that covers all components, including Kafka-related failures. This translates to a maximum of 0.876 hours of downtime per year. Amazon MSK offers a 99.9% SLA (a maximum of 8.76 hours of downtime per year), but that SLA explicitly excludes failures caused by the underlying Apache Kafka or Zookeeper software, placing the burden of resolving these critical issues on the customer and significant increasing the actual maximum hours of downtime per year MSK customers may experience.
Which platform offers stronger developer tooling, Confluent Cloud or Amazon MSK?
Confluent Cloud offers significantly stronger and more comprehensive developer tooling than Amazon MSK:
-
Confluent Cloud provides a robust Terraform provider that allows developers to manage both control plane resources (like clusters and Schema Registry) and data plane resources (such as Topics and ACLs). This enables complete automation of infrastructure deployments as code. Amazon MSK offers more limited IaC capabilities, as its Terraform support can only manage control plane resources. Managing data plane resources requires building custom operators and processes.
-
Confluent Cloud offers a rich set of APIs for point-and-click operations and automation. It also provides a user-friendly and intuitive cloud UI that allows developers to easily manage and monitor their Kafka clusters and data streams. MSK does not have a dedicated Kafka UI and developers must often build their own tools on top of MSK’s APIs. For example, MSK lacks a native REST proxy for non-Java clients, a feature available in Confluent.
-
Confluent Cloud supports multi-language client development, providing client libraries for several non-Java languages including C/C++, Go, Python, and .NET. Users can generate the necessary configuration details (including cluster credentials and API keys) directly from the Confluent Cloud Console and paste them into client application code. Amazon MSK also supports non-Java clients but enabling them to interact with MSK requires some additional work when setting up and configuring the clients for authentication and authorization.
Does Confluent Cloud offer better support than Amazon MSK?
Yes, Confluent provides customers with guidance from the world's foremost Kafka experts. Confluent was founded by the original co-creators of Kafka, and its support and professional services teams have millions of hours of Kafka experience. MSK support is limited and does not have the same depth of Kafka-specific knowledge.
What are the feature differences around connectors and schema management?
Confluent Cloud provides 120+ pre-built connectors and 80+ fully managed connectors, enabling instant integration with a wide range of popular data sources and sinks both inside and outside the AWS ecosystem. In contrast, Amazon MSK has very limited connector support. It offers fewer than 10 direct or "half-supported" integrations and primarily provides just the underlying Connect infrastructure, requiring users to bring, manage, and maintain their own connectors. This results in additional operational burden and cost. In fact, Confluent offers instant, fully managed connectivity to more native AWS services than Amazon MSK does.
Confluent Cloud includes Stream Governance, a comprehensive, fully managed suite that provides Schema Registry, Data Portal, Stream Lineage, and Data Quality Rules. With features like broker-side schema validation and the ability to tag data containing personally identifiable information (PII), your data streams are discoverable, trustworthy, and secure. Amazon MSK integrates with AWS Glue Schema Registry but lacks a full suite of governance tools, such as schema validation, data lineage, or a data catalog.
Does Confluent Cloud support multicloud deployments?
Yes, Confluent Cloud supports multicloud deployments. It is designed for both multicloud and hybrid environments, whereas Amazon MSK is an AWS-only service. Confluent customers can use its fully managed Kafka service on all three major public clouds and use its Cluster Linking feature to replicate data across clouds.