[Virtual Event] Agentic AI Streamposium: Learn to Build Real-Time AI Agents & Apps | Register
Machine Learning with Python, Jupyter, KSQL and TensorFlow
Building a scalable, reliable and performant machine learning (ML) infrastructure is not easy. It takes much more effort than just building an analytic model with Python and your favorite machine learning framework.
After all, machine learning with Python requires the use of algorithms that allow computer programs to constantly learn, but building that infrastructure is several levels higher in complexity. This is important to note since machine learning is clearly gainin g steam, though many who use the term do so by misusing the term.
Uber, which already runs their scalable and framework-independent machine learning platform Michelangelo for many use cases in production, wrote a good summary:
When Michelangelo started, the most urgent and highest impact use cases were some very high scale problems, which led us to build around Apache Spark (for large-scale data processing and model training) and Java (for low latency, high throughput online serving). This structure worked well for production training and deployment of many models but left a lot to be desired in terms of overhead, flexibility, and ease of use, especially during early prototyping and experimentation [where Notebooks and Python shine].
Uber expanded Michelangelo “to serve any kind of Python model from any source to support other Machine Learning and Deep Learning frameworks like PyTorch and TensorFlow [instead of just using Spark for everything].”
So why did Uber (and many other tech companies) build its own platform and framework-independent machine learning infrastructure?
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka® ecosystem as a central, scalable and mission-critical nervous system. It allows real-time data ingestion, processing, model deployment and monitoring in a reliable and scalable way.
This blog post focuses on how the Kafka ecosystem can help solve the impedance mismatch between data scientists, data engineers and production engineers. By leveraging it to build your own scalable machine learning infrastructure and also make your data scientists happy, you can solve the same problems for which Uber built its own ML platform Michelangelo.
Impedance mismatch between data scientists, data engineers and production engineers
Based on what I’ve seen in the field, an impedance mismatch between data scientists, data engineers and production engineers is the main reason why companies struggle to bring analytic models into production to add business value.
The following diagram illustrates the different required steps and corresponding roles as part of the impedance mismatch in a machine learning lifecycle:
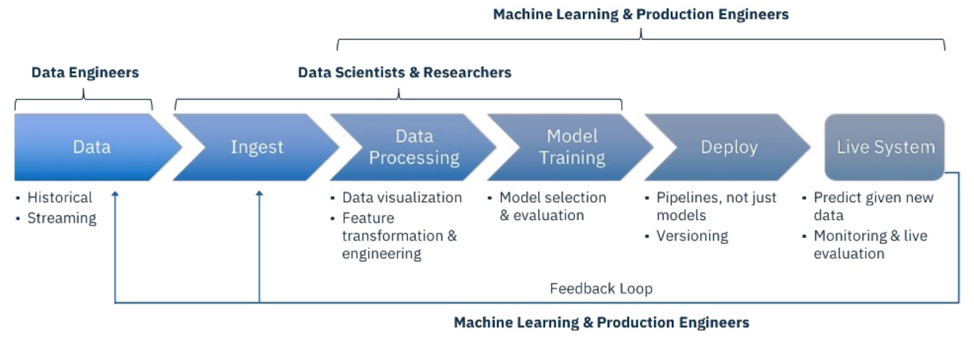
Impedance mismatch between model development and model deployment
Data scientists love Python, period. Therefore, the majority of machine learning/deep learning frameworks focus on Python APIs. Both the stablest and most cutting edge APIs, as well as the majority of examples and tutorials use Python APIs. In addition to Python support, there is typically support for other programming languages, including JavaScript for web integration and Java for platform integration—though oftentimes with fewer features and less maturity. No matter what other platforms are supported, chances are very high that your data scientists will build and train their analytic models with Python.
There is an impedance mismatch between model development using Python, its tool stack and a scalable, reliable data platform with low latency, high throughput, zero data loss and 24/7 availability requirements needed for data ingestion, preprocessing, model deployment and monitoring at scale. Python in practice is not the most well-known technology for these requirements. However, it is a great client for a data platform like Apache Kafka.
The problem is that writing the machine learning source code to train an analytic model with Python and the machine learning framework of your choice is just a very small part of a real-world machine learning infrastructure. You need to think about the whole model lifecycle. The following image represents this hidden technical debt in machine learning systems (showing how small the “ML code” part is):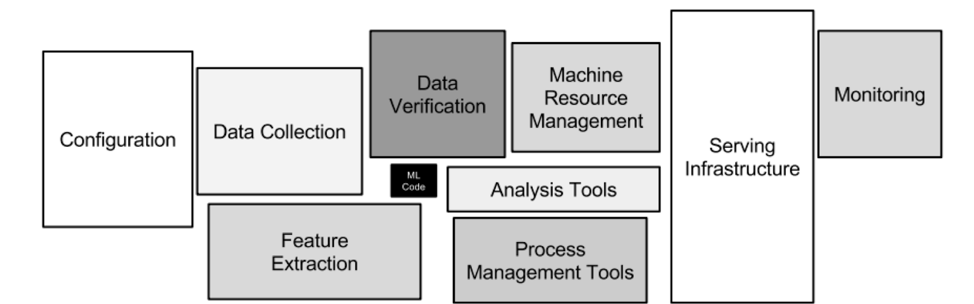
Thus, you need to train and deploy the model built to a scalable production environment in order to reliably make use of it. This can either be built natively around the Kafka ecosystem, or you could use Kafka just for ingestion into another storage and processing cluster such as HDFS or AWS S3 with Spark. There are many tradeoffs between Kafka, Spark and several other scalable infrastructures, but that discussion is out of scope for this blog post. For now, we’ll focus on Kafka.
Different solutions in the industry solve certain parts of the impedance mismatch between data scientists, data engineers and production engineers. Let’s take a look at some of these options:
- Official standards like Open Neural Network Exchange (ONNX), Portable Format for Analytics (PFA) or Predictive Model Markup Language (PMML): A data scientist builds a model with Python. The Java developer imports it in Java for production deployment. This approach supports different frameworks, products and cloud services. You do not have to rely on the same framework or product for training and model deployment. Consider ONNX, a relatively new standard for deep learning—it already supports TensorFlow, PyTorch and MXNet. These standards have pros and cons. Some people like and use them; many don’t.
- Developer-focused frameworks like Deeplearning4j: These frameworks are built for software engineers to build the whole machine learning lifecycle on the Java platform, not just model deployment and monitoring but also preprocessing and training. You can still import other models if you want (e.g., Deeplearning4j lets you import Keras models). This option is great if you: a) have data scientists who can write Java or b) have software engineers who understand machine learning concepts enough to build analytic models.
- AutoML for building analytic models with limited machine learning experience: This way, domain experts can build and deploy analytic models with a button click. The AutoML engine provides an interface for others to use the model for predictions.
- Embedding model binaries into applications: The output of model training is an analytic model. For instance, you can write Python code to train and generate a TensorFlow model. Depending on the framework, the output can be text files, Java source code or binary files. For example, TensorFlow generates a model artifact with Protobuf, JSON and other files. No matter what format the output of your machine learning framework is, it can be embedded into applications to use for predictions via the framework’s API (e.g., you can load a TensorFlow model from a Java application through TensorFlow’s Java API).
- Managed model server in the public cloud like Google Cloud Machine Learning Engine: The cloud provider takes over the burden of availability and reliability. The data scientist “just” deploys its trained model, and production engineers can access it. The key tradeoff is that this requires RPC communication to perform model inference.
While all these solutions help data scientists, data engineers and production engineers to work better together, there are underlying challenges within the hidden debts:
- Data collection (i.e., integration) and preprocessing need to run at scale
- Configuration needs to be shared and automated for continuous builds and integration tests
- The serving and monitoring infrastructure need to fit into your overall enterprise architecture and tool stack
So how can the Kafka ecosystem help here?
Apache Kafka as key component for solving the impedance mismatch
In many cases, it is best to provide experts with tools they like and know well. The challenge is to combine the different toolsets and still build an integrated system, as well as continuous, scalable machine learning workflow. Therefore, Kafka is not competitive but complementary to the discussed alternatives when it comes to solving the impedance mismatch between the data scientist and developer.
The data engineer builds a scalable integration pipeline using Kafka as infrastructure and Python for integration and preprocessing statements. The data scientist can build their model with Python or any other preferred tool. The production engineer gets the analytic models (either manually or through any automated, continuous integration setup) from the data scientist and embeds them into their Kafka application to deploy it in production. Or, the team works together and builds everything with Java and a framework like Deeplearning4j.
Any option can pair well with Apache Kafka. Pick the pieces you need, whether it’s Kafka core for data transportation, Kafka Connect for data integration or Kafka Streams/KSQL for data preprocessing. Many components can be used for both model training and model inference. Write once and use in both scenarios as shown in the following diagram:
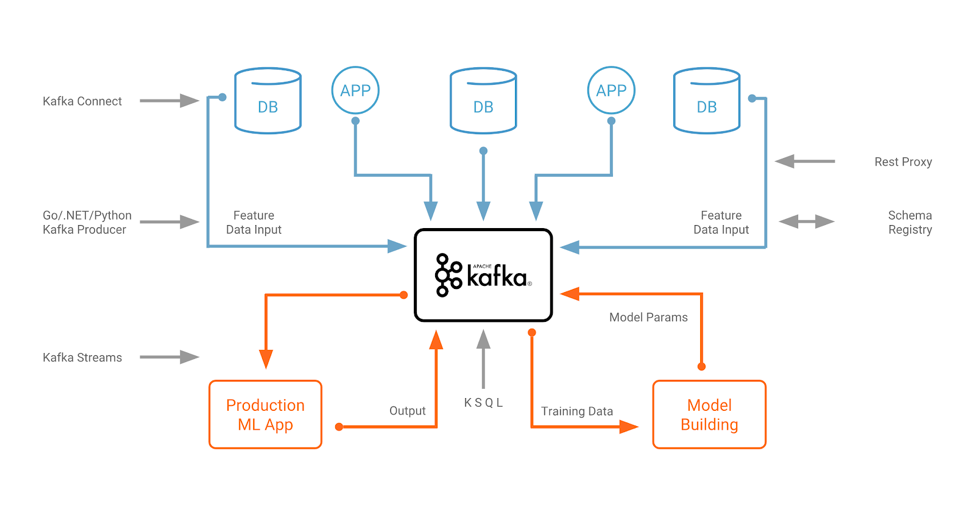
Leveraging the Apache Kafka ecosystem for a machine learning infrastructure
Monitoring the complete environment in real time and at scale is also a common task for Kafka. A huge benefit is that you only build a highly reliable and scalable pipeline once but use it for both parts of a machine learning infrastructure. And you can use it in any environment: in the cloud, in on-prem datacenters or at the edges, where IoT devices are.
Say you wanted to build one integration pipeline from MQTT to Kafka with KSQL for data preprocessing, and use Kafka Connect for data ingestion into HDFS, AWS S3 or Google Cloud Storage, where you do the model training. The same integration pipeline, or at least parts of it, can be reused for model inference. New MQTT input data can directly be used in real time to make predictions.
We just explained various alternatives to solving the impedance mismatch between data scientists and software engineers in Kafka environments. Now, let’s discuss one specific option in the next section, which is probably the most convenient for data scientists: leveraging Kafka from a Jupyter Notebook with KSQL statements and combining it with TensorFlow and Keras to train a neural network.
Data scientists combining Python and Jupyter with scalable streaming architectures
Data scientists use tools like Jupyter Notebooks to analyze, transform, enrich, filter and process data. The preprocessed data is then used to train analytic models with machine learning/deep learning frameworks like TensorFlow.
However, some data scientists do not even know “bread-and-butter” concepts of software engineers, such as version control systems like GitHub or continuous integration tools like Jenkins.
This raises the question of how to combine the Python experience of data scientists with the benefits of Apache Kafka as a battle-tested, highly scalable data processing and streaming platform.
Apache Kafka and KSQL for data scientists and data engineers
Kafka offers integration options that can be used with Python, like the Confluent’s Python Client for Apache Kafka or the Confluent REST Proxy for HTTP integration. But this is not really a convenient way for data scientists who are used to quickly and interactively analyse and preprocessing data before model training and evaluation. Rapid prototyping is typically used here.
KSQL enables data scientists to take a look at Kafka event streams and implement continuous stream processing from their well-known and loved Python environments like Jupyter by writing simple SQL-like statements for interactive analysis and data preprocessing.
The following Python example executes an interactive query from a Kafka stream leveraging the open source framework ksql-python, which adds a Python layer on top of KSQL’s REST interface. Here are a few lines of the Python code using KSQL from a Jupyter Notebook:
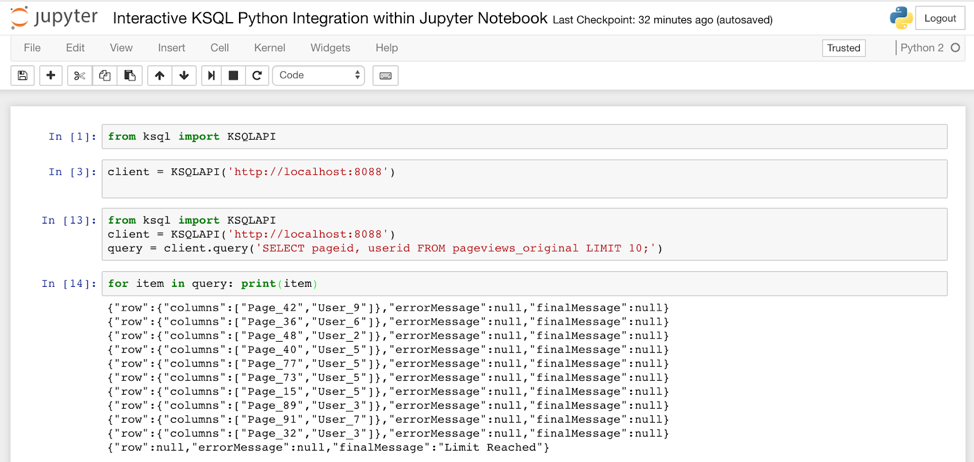
The result of such a KSQL query is a Python generator object, which you can easily process with other Python libraries. This feels much more Python native and is analogous to NumPy, pandas, scikit-learn and other widespread Python libraries.
Similarly to rapid prototyping with these libraries, you can do interactive queries and data preprocessing with ksql-python. Check out the KSQL quick start and KSQL recipes to understand how to write a KSQL query to easily filter, transform, enrich or aggregate data. While KSQL is running continuous queries, you can also use it for interactive analysis and use the `LIMIT` keyword like in ANSI SQL if you just want to get a specific number of rows.
So what’s the big deal? You understand that KSQL can feel Python native with the ksql-python library, but why use KSQL instead of or in addition to your well-known and favorite Python libraries for analyzing and processing data?
The key difference is that these KSQL queries can also be deployed in production afterwards. KSQL offers you all the features from Kafka under the hood like high scalability, reliability and failover handling. The same KSQL statement which you use in your Jupyter Notebook for interactive analysis and preprocessing can scale to millions of messages per second. Fault tolerant. With zero data loss and exactly once semantics. This is very important and valuable for bringing together the Python-loving data scientist with the highly scalable and reliable production infrastructure.
Just to be clear: KSQL + Python is not the all-rounder for every data engineering task, and it does not replace the existing Python toolset. But it is a great option in the toolbox of data scientists and data engineers, and it adds new possibilities like getting real-time updates of incoming information as the source data changes, or updating a deployed model with a new and improved version.
Jupyter Notebook for fraud detection with Python KSQL and TensorFlow/Keras
Let’s now take a look at a specific and detailed example using the combination of KSQL and Python. It involves advanced code examples using ksql-python and other widespread components from Python’s machine learning ecosystem, like NumPy, pandas, TensorFlow and Keras.
The use case is fraud detection for credit card payments. We use a test dataset from Kaggle as a foundation to train an unsupervised autoencoder to detect anomalies and potential fraud in payments. The focus of this example is not just model training but the whole machine learning infrastructure, including data ingestion, data preprocessing, model training, model deployment and monitoring. All of this needs to be scalable, reliable and performant.
For the full running example and more detailed information, see the documentation.
Let’s take a look at a few snippets of the Jupyter Notebook.
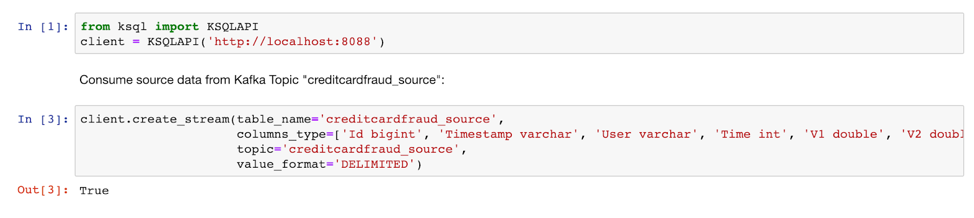
Connection to KSQL server and creation of a KSQL stream using Python:
Preprocessing incoming payment information using Python:
- Filter columns that are not needed
- Filter messages where column ”class” is empty
- Change data format to Avro for convenient and further processing

Some more examples for possible data wrangling and preprocessing with KSQL:
- Drop columns, filter messages where value “class” is empty and change data format to Avro:
- Anonymization (mask the two leftmost characters, e.g., “Hans” becomes “**ns”):
- Augmentation (add -1 if “class” is null):
- Merge/join data frames:
The Jupyter Notebook contains the full example. We use Python + KSQL for integration, data preprocessing and interactive analysis, and combine them with various other libraries from a common Python machine learning tool stack for prototyping and model training:
- Arrays/matrices processing with NumPy and pandas
- ML-specific processing (split train/test, etc.) with scikit-learn
- Interactive analysis through data visualisations with Matplotlib
- ML training + evaluation with TensorFlow and Keras
Model inference and visualisation are done in the Jupyter notebook, too. After you have built an accurate model, you can deploy it anywhere to make predictions and leverage the same integration pipeline for model training. Some examples of model deployment in Kafka environments are:
- Analytic models (TensorFlow, Keras, H2O and Deeplearning4j) embedded in Kafka Streams microservices
- Anomaly detection of IoT sensor data with a model embedded into a KSQL UDF
- RPC communication between Kafka Streams application and model server (TensorFlow Serving)
Python, KSQL and Jupyter for prototyping, demos and production deployments
As you can see, both in theory (Google’s paper Hidden Technical Debt in Machine Learning Systems) and in practice (Uber’s machine learning platform Michelangelo), it is not a simple task to build a scalable, reliable and performant machine learning infrastructure.
The impedance mismatch between data scientists, data engineers and production engineers must be resolved in order for machine learning projects to deliver real business value. This requires using the right tool for the job and understanding how to combine them. You can use Python and Jupyter for prototyping and demos (often Kafka and KSQL might be overhead here and not needed if you just want to do fast, simple prototyping on a historical dataset), or combine Python and Jupyter with your whole development lifecycle up to production deployments at scale.
Integration of Kafka event streams and KSQL statements into Jupyter Notebooks allows you to:
- Use the preferred existing environment of the data scientist (including Python and Jupyter), and combine it with Kafka and KSQL to integrate and continuously process real-time streaming data by using a simple Python wrapper API to execute KSQL queries
- Easily connect to real-time streaming data instead of just historical batches of data (maybe from the last day, week or month, e.g., coming in via CSV files).
- Merge different concepts like streaming event-based sensor data coming from Kafka with Python programming concepts like generators or dictionaries objects, which you can use for your Python data processing tools or ML frameworks like NumPy, pandas or scikit-learn
- Reuse the same logic for integration, preprocessing and monitoring, and move it from your Jupyter Notebook and prototyping or demos to large-scale test and production systems
Python for prototyping and Apache Kafka for a scalable streaming platform are not rival technology stacks. They work together very well, especially if you use “helper tools” like Jupyter Notebooks and KSQL.
They work well with all categories of machine learning. In the case of supervised machine learning, it’s where the learn data from the program is labeled by a data scientist who is supervising the process. Unsupervised machine learning doesn’t use labels but rather figures the data cluster on its own. And reinforcement machine learning programs react based on positive and negative feedback to make improvements.
Please try it out and let us know your thoughts. How do you leverage the Apache Kafka ecosystem in your machine learning projects?
Interested in more?
- Download the Confluent Platform and use the quick start
- Learn about ksqlDB, the successor to KSQL, and see the latest syntax
- Ask questions in the Confluent Community Slack
Did you like this blog post? Share it now
Subscribe to the Confluent blog



From Dumb Pipes to a Smart Data Plane: Introducing Schema IDs in Apache Kafka® Headers
Confluent’s Schema IDs in headers transform Kafka from "dumb pipes" to a "smart data plane." By moving metadata out of payloads, teams can schematize topics without breaking legacy apps or requiring big-bang migrations. This unlocks governed, AI-ready data for Flink and lakehouses with ease.


Queues for Apache Kafka® Is Here: Your Guide to Getting Started in Confluent
Confluent announces the General Availability of Queues for Kafka on Confluent Cloud and Confluent Platform with Apache Kafka 4.2. This production-ready feature brings native queue semantics to Kafka through KIP-932, enabling organizations to consolidate streaming and queuing infrastructure while...