New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Apache Kafka and SAP Integration with the Kafka Connect ODP Source Connector
SAP is a German multinational software corporation that develops and markets enterprise software to manage business operations and customer relations. SAP is most famous for its enterprise resource planning (ERP) solutions, such as SAP ECC and SAP S/4HANA. However, with each individual solution, there are multiple components. For example, if an enterprise wants to adopt SAP ECC, IT teams need to consider the different versions, architectures, integration options (e.g., proprietary and open interfaces and multiple SAP middleware options), and other third-party plug-in solutions. This blog post explores how SAP provides a modern, scalable approach for Apache Kafka® and SAP integration by leveraging Kafka Connect and INIT Software’s ODP connector.
Kafka and SAP integration – A never-ending story
There are multiple options for integrating Kafka and SAP systems, both on the data and application layers, which make it both challenging and critical for enterprises to pick the right approach. Some of the most common options are:
- Traditional middleware (ETL/ESB)
- Web services (SOAP/REST)
- Third-party turnkey solutions
- Kafka-native connectivity with Kafka Connect
- Custom glue code using SAP SDKs
Researching and deciding which option is right for you is not an easy task due to the variety of integration alternatives and SAP products, interfaces, and use cases. The blog post Kafka SAP Integration – APIs, Tools, Connector, ERP et al. explores the different options available, their use cases, and the pros and cons.
A key consideration is whether the project requires an external third-party integration solution (such as an ESB or ETL tool) or a Kafka-native integration solution (often based on Kafka Connect). Both approaches have their pros and cons. The blog post Apache Kafka vs. Enterprise Service Bus (ESB) – Friends, Enemies, or Frenemies? explores the different concepts and architectures between ESB/ETL tools and the Kafka ecosystem.
The following introduces an integration option based on Kafka Connect and SAP Operational Data Provisioning (ODP). This combination combines a fully supported turnkey solution with the benefits of Kafka Connect and Confluent Platform to provide high scalability and performance, simple installation and operations, and mission-critical support SLAs.
INIT Software’s SAP connector
Since its founding in 1996, INIT Individuelle Softwareentwicklung & Beratung GmbH’s central focus of its services portfolio are SAP-related projects in heterogeneous system landscapes, complex structures, and business processes, as well as distributed information. For the solution presented here, our practical project experience in the Hadoop ecosystem was particularly advantageous, as well as our ongoing focus on developing solutions for SAP integration using various technologies.
Architecture
The most important aspects for architectural decisions that we made when developing SAP connectors were scalability, performance, simplicity, a wide range of applicability, and a narrow scope inspired by modern microservices. Tight integration with the Kafka ecosystem via the Kafka Connect API allows you to take advantage of the central logging, monitoring, configuration, and maintenance capabilities provided by Confluent Platform, as well as consistent services like failover recovery and exactly-once delivery semantics using logical offsets, back-off recovery, data transformations into different data formats, schema handling, and much more.
The diagram below provides a high-level overview of the internal architecture chosen for the ODP Source Connector. It represents the most versatile, out-of-the-box design for gathering data out of SAP NetWeaver ABAP-based systems and writing them to Kafka using proven technology and interfaces.
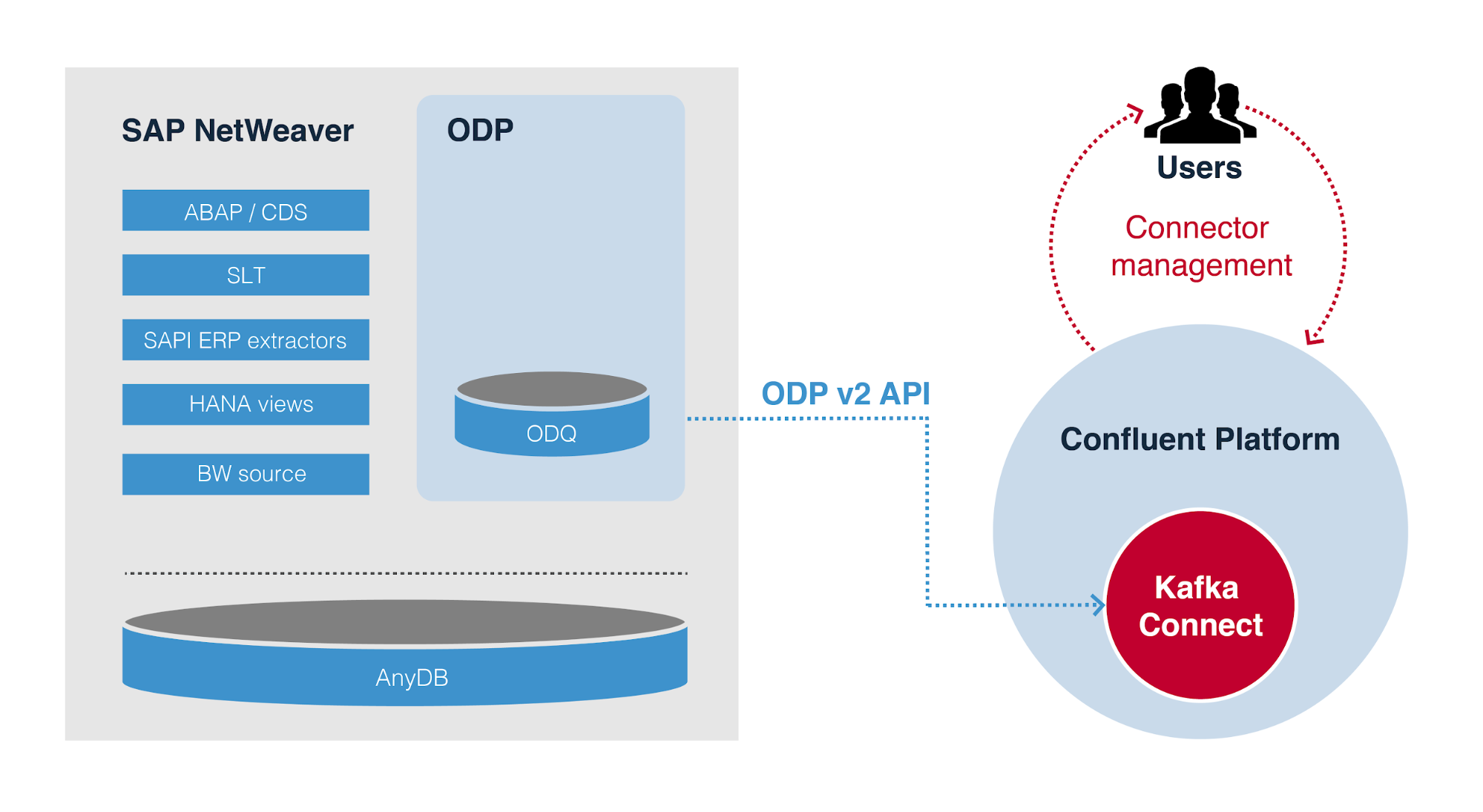
SAP Operational Data Provisioning (ODP)
SAP provides several solutions for interaction and data exchange with native SAP systems, one of which is ODP. ODP can be used for data extraction from SAP NetWeaver AS ABAP based systems like SAP ERP, ECC or S/4HANA. Therefore, it is not applicable to systems like SAP Ariba, Business One, Concur and SuccessFactors.
INIT chose SAP ODP as an integration approach for their source connector, because it provides a unique technical infrastructure for data extraction and replication. ODP has become the central infrastructure for data replication from SAP ABAP systems to SAP BW/4HANA. The ODP API v2.0 enables the connector to connect to different source types, called contexts, including the well-known SAPI DataSources (Extractors), HANA Views, BW InfoProviders, SLT and ABAP CDS, to name a few. The majority of historical business content data sources have been migrated to ODP. In addition to direct data access, full replication, change data capture (CDC) or delta replication, data initialization, real-time data replication, projections, and filters, ODP adds another layer on top of them to provide a unified data replication experience. This comes with a data extraction performance boost as opposed to requiring you to directly access the underlying 7.x data source. This also enables subscriptions from multiple consumers by persisting data in a compressed format in a delta queue.
Kafka Connect ODP Source Connector
Kafka Connect is a native open source component of Kafka and a framework for integrating third-party systems seamlessly with Kafka. It provides a high-level Connect API for the development of source and sink connectors, and it integrates with Confluent Platform.
The ODP connector is fully compliant with the Connect API and integrates seamlessly with Kafka Connect and Confluent Platform. In contrast to connectors that are developed with the low-level Consumer and Producer API, the Connect API provides tight integration with Kafka Connect. This significantly reduces the effort required to implement common functional behavior, such as back-off strategy and exactly-once semantics, leveraging the native logical offset management of Kafka Connect.
The installation process of the connector is as easy as downloading and unzipping the connector archive from Confluent Hub, which can be further codified by using the Confluent Hub CLI. There is only one external dependency that you need to take care of manually, which is copying the SAP Java Connector (SAP JCo) library into the connector’s classpath. The SAP JCo library can be downloaded from the SAP marketplace.
The connector is also fully integrated with the Confluent Control Center. When it comes to instantiation, maintenance, and configuration of the connector, Control Center guides you through every single step with a sophisticated web UI. You can also configure the connector using a simple properties file or the Kafka Connect REST API, but you will miss out on the interactive mode of Control Center, which shows/hides dependent properties and discovers metadata entries from the source system, providing on-the-fly data entry validation.
The figures below depict a connector instance running in Confluent Platform. These were taken during a delta initialization test extracting about 2 million datasets and roughly 1 GB of data from creditor bookings.
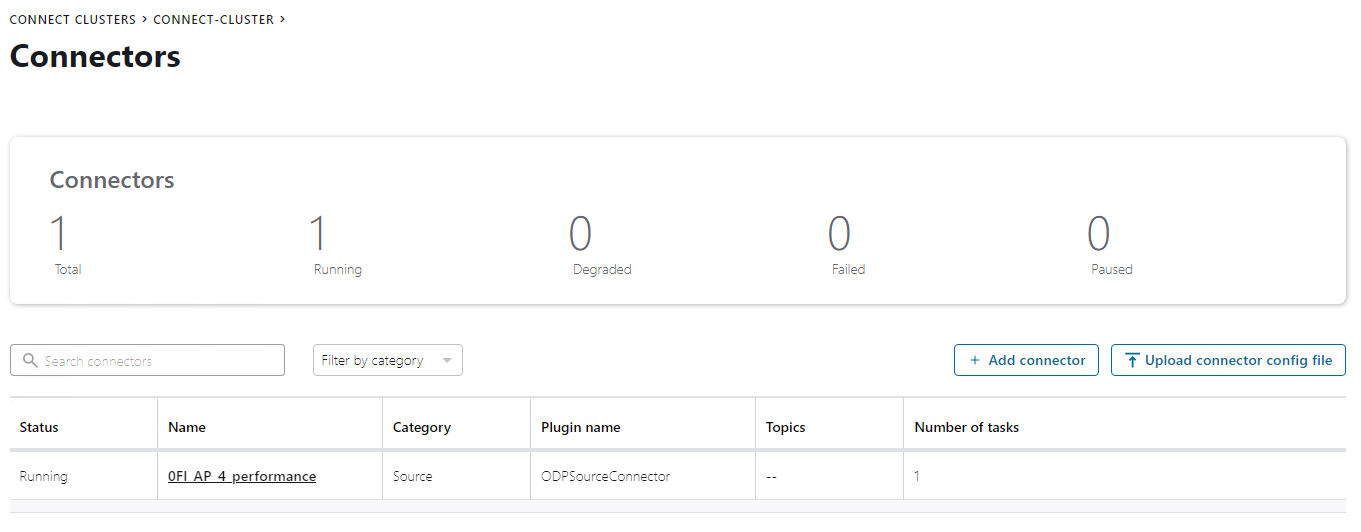
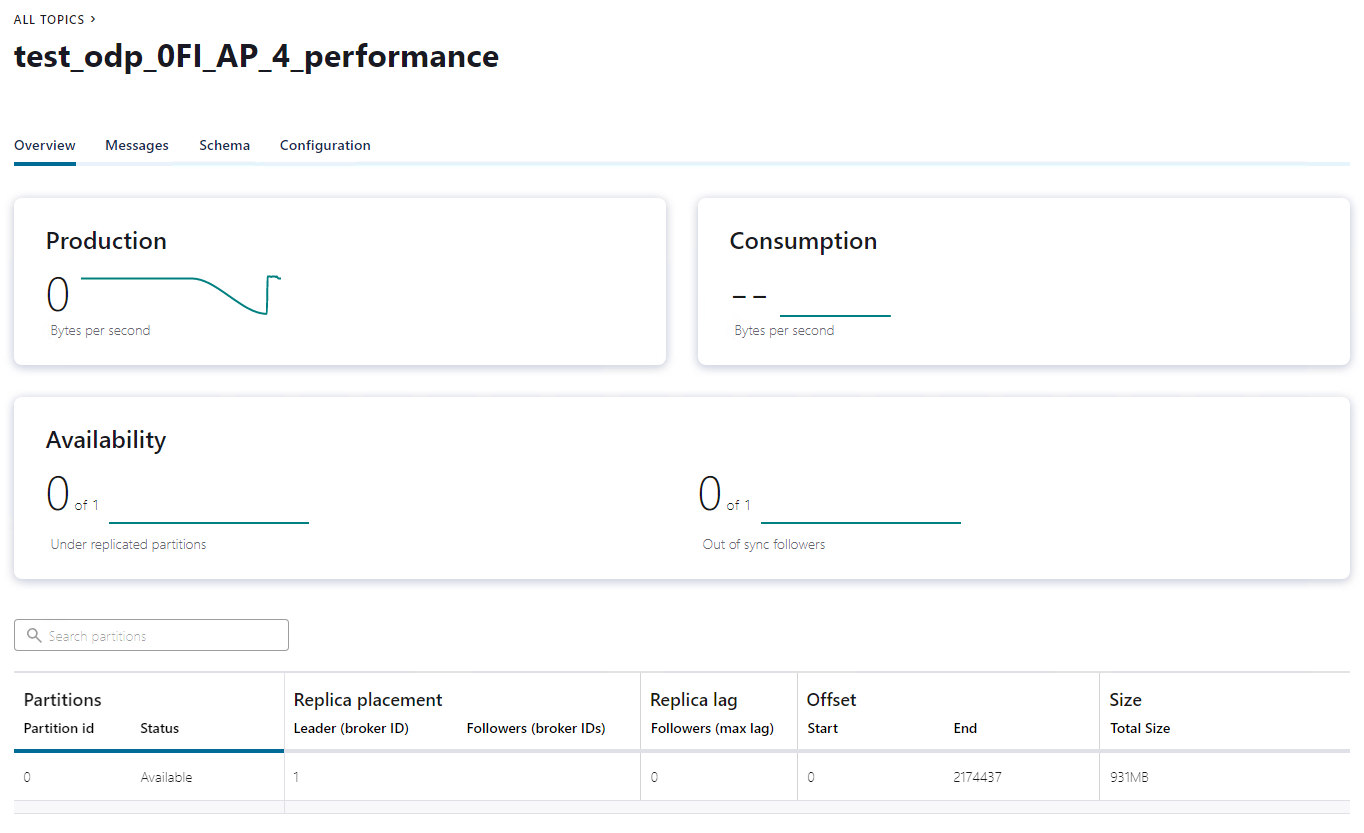
SAP ODP can be consumed either via RFC or OData. The connector uses SAP JCo instead of OData to establish RFC-based connections for optimal performance when it comes to data replication of very large datasets. Moreover, JCo provides additional native service characteristics for SAP, including system load balancing using SAP message server logon groups, data integrity by applying Secure Network Communication (SNC), single sign-on authentication, and data encryption.
For more detailed information about the connector together with introduction videos, please refer to the INIT documentation.
Use case: CDC-enabled data extraction from SAP in near real time
At the time of this writing, there are already multiple connectors available in Confluent Hub that support data extraction from various SAP systems. Both the Confluent JDBC connector, combined with the HANA JDBC driver (ngdbc.jar), and the SAP HANA connector can be used to extract data from and insert data into the SAP ERP system’s underlying HANA database, and can be used with most of the SAP business applications. The downside of such an approach, like with all related database connectors, is the direct integration with the data persistence layer and consequently bypassing the application layer. In most scenarios, the database contains pure technical information, spread across multiple tables, and the business object is derived in the application logic that processes that data.
There are also other non-Kafka Connect-based solutions available when it comes to the replication of SAP data into Kafka, but there are good reasons to take Kafka Connect into consideration when it comes to integrating external systems into Kafka.
The ODP Source Connector is a perfect fit if you need to ingest business entities from SAP AS ABAP into your Kafka event streaming platform. ODP offers a variety of source system contexts and extractors to choose from. SAP has put a lot of effort into migrating most of the Business Content Extractors, which have been mainly used to replicate SAP entities to SAP BI and then to ODP.
The connector supports delta-enabled ODP data sources, where the data is persisted in a Operational Delta Queue (ODQ). In this scenario, CDC and other optional characteristics like real-time data acquisition are implemented as part of the extractor. The ODQ on top of the extractor enables recovery scenarios, multiple subscribers, asynchronous communication, and data compression. For each replication, of any amount of datasets, a unique request is created that can be monitored in the corresponding SAP source system monitor (ODQMON). This request also keeps track of the status of the data extraction itself and works similarly to an offset commit in Kafka. The connector makes use of the request status handling on the SAP side and the Connect API logical offset handling on Kafka’s side to store the information about which dataset has been finally written to Kafka on both sides of the connector. This forms the basis for exactly-once delivery guarantees, also in situations where you have to start or stop the connector instance or even when the connector or the whole platform becomes unavailable.
An ODQ request is further divided into packages of configurable size. If the connector is configured for data extraction out of multiple data sources, the task management and fair package-based extraction scheduling over multiple sources ensures fast and consistent response times for the connector. This strategy supports continuous and scalable operation in the case of event streaming or even batching, e.g., when performing a delta initialization load with huge datasets.
As per usual for event streaming platforms, the connector is designed to be configured and started once and run forever without the need for complex administration tasks. Besides different kinds of metadata requests from SAP, this is enabled by an integrated exponential back-off strategy in the event of downtime or communication issues with the SAP system. Based on a differentiated interpretation of error messages and exceptions, the connector knows if it faces a permanent error or a potentially temporal issue. The back-off strategy is only applied to temporal issues and tries to reconnect to SAP repeatedly by applying different wait times in between until it reaches a maximum amount of retries. All of this is configurable via Confluent Control Center.
ODP has been proven by INIT and others to provide increased performance. Together with a sophisticated design, JCo as a high-performant interface technology, and Kafka as a modern distributed event streaming platform, the connector offers high scalability and performance when processing data in near real time or in batches.
Benefits and limitations
The following overview summarizes the most important benefits and limitations of the ODP Source Connector.
Benefits
- Gold verified by Confluent for meeting standard integration requirements
- Supports Confluent Hub CLI, Control Center, Schema Registry, SMTs and converters for easy installation, configuration, administration, integration, and monitoring
- Includes proper data type mappings from SAP ABAP, DDIC, and JCo data types to the internal Kafka Connect data model
- Compatible to different data type converters; changing the data format used to store messages in Kafka is just a matter of updating configuration settings (this has been tested with existing JSON and Avro converters)
- Makes heavy use of SAP metadata and therefore supports fully automated discovery of complex and nested schemas offered for consumption by Schema Registry
- Provides exactly-once delivery semantics
- Applies a back-off strategy in case of source system downtime or communication issues
- Compatible with Single Message Transformations (SMTs)
- Uses data retention in ODQ for asynchronous transfer and recovery purposes
- Supports SAP NetWeaver AS ABAP on AnyDB
- Tested with S/4HANA, BW, and ERP with different customers
- Uses JCo, a high-performance JNI-based RFC middleware
- Can be used with various pre-delivered business content data sources (refer to SAP Note 2232584), ABAP CDS views, and others
- Can be customized to use one connector instance per data source or multiple data sources per connector instance; these scenarios have pros and cons, like enabling the use of a limited amount of tasks for an exceeding amount of data sources or independency in case of failures related to a source running in the same instance
- Provides full support for ODQ request monitoring in SAP (via transaction ODQMON)
- Natively integrated and compatible with Kafka Connect
- Integrates with Kafka Connect logging using SLF4J
Limitations
- The ODP connector is a source connector only. It supports a wide range of source types, but SAP ODP has not been designed for bi-directional data exchange. INIT provides several other connectors using different integration protocols to enable additional source and even sink scenarios.
- Some business content data sources provided by SAP won’t work out of the box and require individual configuration, e.g., logistic data sources. Some even need to schedule collection batch jobs running in the SAP system consuming additional hardware resources besides OLTP tasks.
- The connector supports delta-enabled data sources only. This is a design decision, as regular full extractions do not fit the idea of event streaming adequately and CDC should be part of the source.
- No support for ODP real-time data acquisition is offered, as this does not match the Connect API.
- The connector scales up to one ODP source per Kafka Connect worker task. Breaking processing units and parallelization further down would break guarantees for sequential order.
- SAP RFC via JCo is a legacy and closed source communication protocol.
- ODP API v2.0 requires an SAP_BASIS release ≥ 730 (refer to SAP Note 1931427).
- The connector requires a direct RFC connection between SAP and Kafka.
Does the ODP connector apply to your business case?
If your business use case depends on integrating business content from an SAP AS ABAP module into Kafka and goes beyond simple data replication on the database level, the ODP connector might be the best choice for you. Find out how INIT introduced the connector with a customer for replication of vendor bookings from SAP FI: Evaluation of integrating SAP NetWeaver™-based systems in Apache Kafka®.
Lightweight, Kafka-native SAP integration
The ODP Source Connector is a cost-effective, Kafka-native, lightweight, and scalable solution for consuming business information out of SAP AS ABAP-based systems in Kafka. It is the right choice for you if:
- The above-mentioned limitations of the connector do not apply to your use case or can be avoided
- You do not already operate another solution offering similar functionalities, like one of the third-party ETL tools, SAP Data Hub/Data Intelligence, Cloud Platform Integration, Data Services, HANA SDI, or SAP BW
- The existing integration solution does not provide sufficient service guarantees, e.g., it does not scale, is not cost effective, adds exceeding latency, or is not able to deliver in real time, lacks sufficient SLAs, or adds unnecessary complexity
- You prefer a thin and well-integrated solution with service guarantees like exactly-once semantics and built-in recovery, which are easy to maintain
Simple installation, management, and monitoring without additional tools
Most of the alternative solutions required to install and maintain additional applications or monolithic systems not only concentrate on data replication but also ETL transformation logic or analytics. These can be a data hub Kubernetes cluster, data services job servers, an SDI data provisioning server, a complex SAP BW system, an SAP PO instance, or SAP cloud platform subscription. Most of these additional layers of data integration do not just increase total cost of ownership (TCO), but they also increase the latency of data transfer – or even worse – are not able to meet the requirements for modern event streaming infrastructures.
When using the ODP Source Connector, you do not need to install additional systems beyond Kafka Connect for data replication and ETL. When developing the connector, we concentrated solely on one-to-one data replication and corresponding service characteristics. Instead of inventing the wheel twice, the connector relies on other features of Kafka and established analytic frameworks and tools when it comes to transformations, data cleansing, analytics, predictive tasks, and others.
Scalable and performant Kafka and SAP integration with the SAP ODP connector
There is huge demand across the globe to integrate SAP applications with Kafka for real-time messaging, data integration, and data processing at scale. The demand is true for SAP ERP (ECC and S/4Hana), as well as for most other products from the vast SAP portfolio.
Kafka integrates with SAP systems well. Different integration options are available via SAP SDKs and third-party products for proprietary interfaces, open standards, and modern messaging and event streaming concepts. The Kafka Connect ODP Source Connector from INIT Software provides a scalable and performant Kafka-native integration option. To learn more, join me for an online talk on March 30th, 2021, at 11:30 a.m. CEST, where I’ll share more technical details about the integration.
If you want to try out this integration option, use the Confluent Platform Docker image and follow the screen recordings from INIT’s getting started guide for a free 30-day evaluation of the connector.
Did you like this blog post? Share it now
Subscribe to the Confluent blog





