New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Deploying Kafka Streams and KSQL with Gradle – Part 1: Overview and Motivation
Red Pill Analytics was recently engaged by a Fortune 500 e-commerce and wholesale company that is transforming the way they manage inventory. Traditionally, this company has used only a few massive warehouses and shipped out from these locations to all customers regardless of geographic location or delivery style. But these legacy warehouses were slow to ship from and couldn’t keep up with more modern inventory management strategies, including same-day dropshipping or bringing the product physically to their customers’ locations using industrial vending. So our customer planned their rollout of the first of possibly hundreds of smaller, nimble, strategically located distribution centers.
The customer knew that their legacy warehouse management system was not designed for these new inventory paradigms and selected Oracle Warehouse Management Cloud (formerly LogFire and hereafter called Oracle WMS Cloud) for the new distribution centers. Oracle’s WMS Cloud is a complete cloud-based solution managing:
- Inventory additions, subtractions and adjustments
- The item picking process
- Inventory auditing
- Warehouse staff management
- Other ancillary functions
Oracle WMS Cloud provides a series of cloud-available APIs for integrations with other enterprise systems…and this is where we came in. Red Pill Analytics was hired to first design and th en implement all the necessary data integration processes required to connect Oracle WMS Cloud with their on-premises systems. These connections needed to be bidirectional and included PeopleSoft as their corporate ERP, an in-house order management system, and an in-house legacy warehouse management system. These systems acted as both sources and targets for Oracle WMS Cloud and were represented by a host of different APIs, including relational tables, file-based interactions, SOAP and REST.
The customer was heavily invested in MuleSoft®, and as part of the project, the MuleSoft team abstracted many of these different sources/targets as simple REST APIs. This left us with only two data integration requirements to solve: relational tables and REST APIs.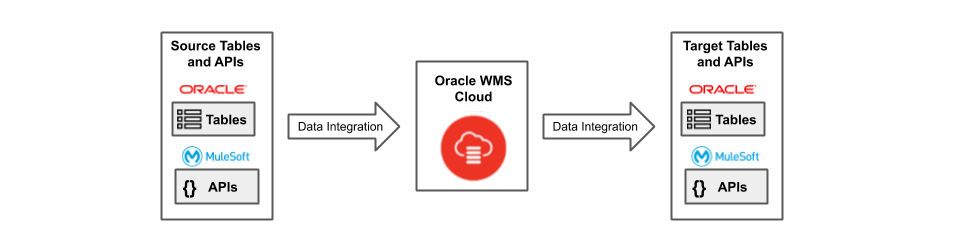
Figure 1. All disparate patterns are abstracted to either relational tables or REST APIs.
The customer had traditional ETL tools on the table; we were in fact already providing them services around Oracle Data Integrator (ODI). They asked us to evaluate whether we thought an ETL tool was the appropriate choice to solve these two requirements. It’s true that any half-decent ETL tool could solve these requirements, as they have support for relational tables and functionality for interacting with REST APIs (even if that support is often somewhat forgettable). But the main gap is the way that traditional ETL tools reason about the events that needed processing—that they exist in batches, not in streams.
Robin Moffatt examines this fundamental shift in ETL processing in his post The Changing Face of ETL. He describes the traditional way of segmenting systems as either analytic or transactional, with transactional systems being the ones that generate useful data, and analytic systems being the ones that use that data for decision-making and reporting. He argues that the world is no longer this neat and tidy—we have more uses now for data generated by transactional systems than simply passive reporting.
In the digital economy, the product is our data, and we need to reconsider the way we extract, transform and load in light of this shift. Events move in streams: continuous, closed-loop processes without defined batches. The trend for the customer was clear: Their systems needed to operate just in time to be more efficient with inventory levels, delivery times and delivery approaches.
Driven by this, we designed and delivered an architecture using Apache Kafka® and the Confluent Platform. Let’s first discuss the streams of data going into Oracle WMS Cloud: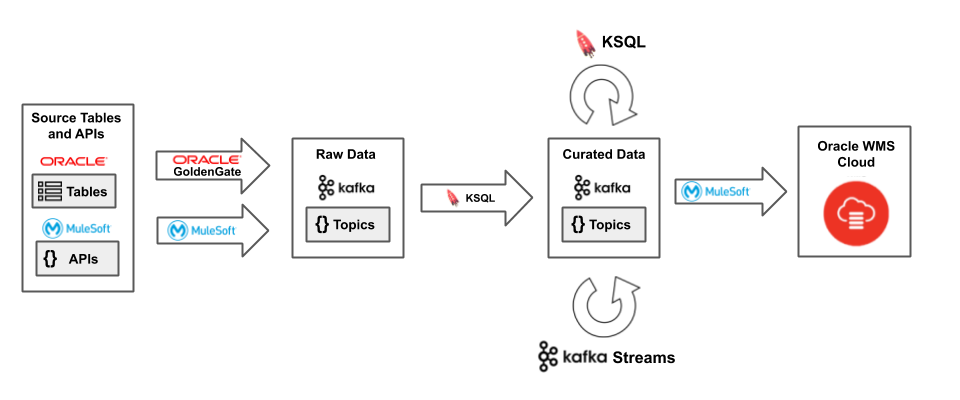
Figure 2. Streaming data into Oracle WMS Cloud
The customer was already invested in Oracle GoldenGate and had in-house expertise there, so it was very easy to use Oracle GoldenGate for Big Data 12c (OGG for BD) to deliver relational data change events to Kafka. For reference, Robin also has a blog post that walks through the setup and basic functionality for OGG for BD. The MuleSoft team abstracted all the other disparate source APIs and wrote services to produce those payloads to Kafka using the Kafka producer API.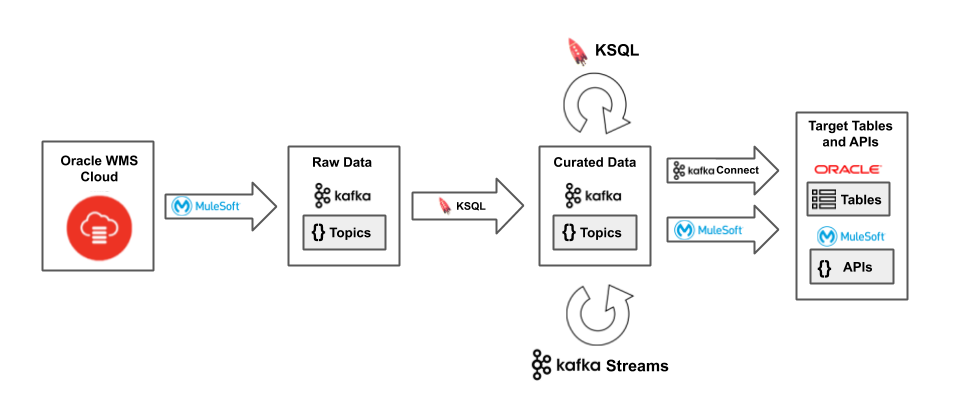
Figure 3. Streaming data out of Oracle WMS Cloud
The data streaming out of Oracle WMS Cloud and back into on-premises systems follows a similar pattern. Oracle GoldenGate is only a source for Kafka, not a sink. So we used the Kafka Connect JDBC Sink connector to deliver data back into legacy systems using interface tables the customer had already built for previous integrations: database procedures accepted and processed new rows of data similar to an API call. When more proper APIs were present, MuleSoft consumed the relevant topics and translated them into the required API calls.
You’ll notice in both the ingress and egress diagrams, we have the concept of curated data, which is a term we used during the project to signify that data streams have been “processed” (joined, filtered, aggregated, reduced, etc). We had to prepare data streams that exactly matched either interface tables or MuleSoft REST API contracts. MuleSoft is a powerful tool capable of complex data transformations, but we wanted to make the data consumable as streams at every stage of the process, by MuleSoft or other possible consumers that didn’t even exist yet. So we chose to use the Confluent Platform and specifically KSQL to curate our streams of data.
Enter KSQL…and Kafka Streams
Kafka Streams was missing from our initial designs for the architecture and from our roadmap—at least during the first few sprints of the project. We had basic (though still fuzzy) ideas of how the streams needed to be processed. Oracle WMS Cloud was a completely new product for the customer, and they were still formulating which APIs to use and how these APIs mapped to their datasets.
When these specs were finalized, we discovered that Kafka Streams was the appropriate choice for the final packaging of messages for MuleSoft, and eventually Oracle WMS Cloud, to consume. Specifically, Oracle WMS Cloud expected singular, nested messages containing both header and detail records for things like shipments and orders, and KSQL doesn’t yet provide the ability to combine data from multiple rows into a single, nested message.
We considered using MuleSoft to do the final packaging of these messages, but MuleSoft would have required an independent state store to properly prepare the nested payloads. Kafka Streams already has a built-in state store, which made it an easy choice. In many cases, we were able to use just the Kafka Streams DSL, and in others, we interacted with the state store in a programmatic way.
Our final solution was to use KSQL primarily as the functional engine for expressing streaming data transformations, and Kafka Streams for the final packaging of payloads before shipping them off to specific APIs. As KSQL uses Kafka Streams under the hood—and both use Kafka topics and Kafka offset management as the interface between processes—the integration was seamless.
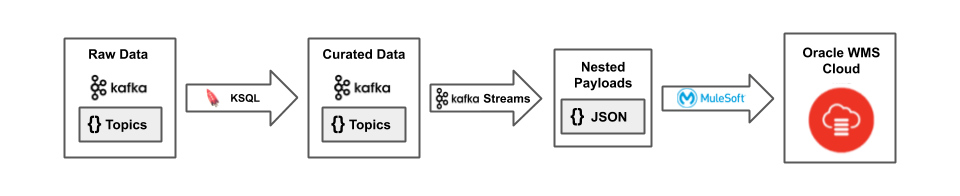
Figure 4. The packaging of payloads for Oracle WMS Cloud
KSQL in a DevOps world
While KSQL is a natural choice for expressing data-driven applications, we had to spend time understanding how to work with it in our established DevOps processes and automations. In part 2 of this series, we will look at some of the challenges that we encountered and how we addressed them, including the development of our own Gradle plugin. We’ll also look at how SQL scripts should be represented in source control, and once there, how we express the dependencies that exist between them in our KSQL pipelines. In part 3, we’ll look at the development and deployment of KSQL user-defined functions (UDFs) as well as Kafka Streams microservices.
Interested in more?
Download the Confluent Platform and learn about ksqlDB, the successor to KSQL.
Other articles in this series
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Why ELT Can't Keep Up in the Era of High-Scale Data Engineering
Batch ELT pipelines create duplication, cost spikes, and governance gaps as data scales. Here’s why enterprises are rethinking legacy integration models.



How to Protect PII in Apache Kafka® With Schema Registry and Data Contracts
Protect sensitive data with Data Contracts using Confluent Schema Registry.