New in Confluent Cloud: Making Data & Pipelines Accessible for AI-Ready Streaming | Learn More
Introducing Self-Service Apache Kafka for Developers
New Confluent Cloud and Ecosystem Expansion to Google Cloud Platform
The vision for Confluent Cloud is simple. We want to provide an event streaming service to support all customers on their journey to an event-driven enterprise. Realizing that vision requires two things. First, an event streaming service that provides the reliability and scalability required by operations teams, but also delivers a lightweight and agile option for developers. Second, an ecosystem of developer tools around the streaming platform, which may be provided by the open source ecosystem or the leading public cloud providers. We introduced Confluent Cloud Enterprise a year ago, as the first step in realizing our cloud vision. Cloud enterprise enables enterprises in their transition to an event-driven organization, without the burden of operating Kafka at scale. We have been successfully running Confluent Cloud Enterprise for a year now, far exceeding the 99.95% availability SLA committed to our customers. Our customers are now benefiting from a fully-managed, private, secure, and high-performance Kafka- based streaming platform for their mission-critical applications. This has established the first milestone in our vision for Confluent Cloud.
But this initial introduction of Confluent Cloud Enterprise was only the first step towards realizing our vision. It did not cover the needs of development teams that are asking us for a self-service offering that can be provisioned in minutes, and charged based on actual usage. And it was only available on AWS, limiting access to leading public cloud services like Google’s BigQuery and TensorFlow.
The Developer Challenge
While our enterprise customers are already leveraging the benefits of Confluent Cloud Enterprise in a simple and highly available managed service, developers wanting to build their applications on a Kafka-based event streaming platform continue mostly to operate all the parts of the platform themselves. This means you have to plan infrastructure to run Kafka and its various platform components before you can get started writing your application.The following examples might sound familiar to you:
- Bob is a machine learning developer building an application to predict what a customer is most likely to purchase next. He wants to use TensorFlow time series algorithms on data being served from Kafka. This requires him to run Kafka on GCP, pull data from its current source, and then finally load it into TensorFlow. Below is an illustration of where Bob spends most of his time today, before he gets his data into TensorFlow. For any developer focused on an end-user’s problem, this is extremely frustrating!
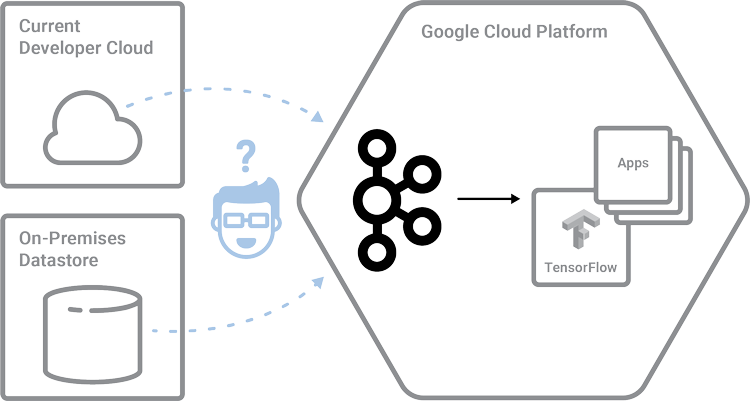
- Mary is an analytics developer in a ride hailing startup trying to identify the highest-demand locations at various times of day and various days of the week. While this data comes from Kafka in real time, she needs to run BigQuery on historic data in the data warehouse to do so. However, her Kafka deployment and the data warehouse are both on a different cloud provider! To write this application, she’ll have to mirror Kafka to GCP and migrate historic data to Google Cloud Storage before she could even start writing her application.
These examples expose some things that a cloud-native developer needs. Specifically:
- A lightweight, easy-to-use streaming platform based on Apache Kafka that you don’t have to setup and operate yourself.
- The need to use an ecosystem of tools around the streaming platform. The tools you want may be offered by specific cloud providers or available in the open source ecosystem.
- A path for your operations team (or you, the consummate devops professional) to run it at scale, without adding to the security, compliance, or operational needs of your organization. This is addressed emphatically by Confluent Cloud Enterprise.
Offering cloud independence and liberating developers from the operational burden of running a streaming platform has been a key focus of Confluent Cloud’s vision. To address this, you need a fully managed, low-cost, self-service, Kafka-based event streaming platform, and the freedom to access this service and your data on any public cloud provider.
It is precisely these pain points that we want to address. To this end, we are excited to announce the launch of self-service Confluent Cloud and availability on Google Cloud Platform.
Confluent Cloud: Liberating the Cloud-First, Event Streaming Developer
Today, we are announcing the public availability of Confluent Cloud as a fully managed, low-cost, self-service, Kafka-based event streaming platform. Running a streaming platform isn’t easy, and Confluent Cloud frees you from that operational burden by offering a fully managed Apache Kafka service, built on the Confluent Platform. It is also perfect for projects anywhere from development to production applications. It offers the legendary performance of Apache Kafka, compatibility with open source Kafka tools and APIs, automatic upgrades to the latest version of Apache Kafka built at Confluent, and additional features that enable you to focus on actually building your application. If you’re a cloud-native developer (or just aspire to be one), then this is how Confluent Cloud helps you build your event-driven applications right away:
- Self-service provisioning with zero upfront commitment. You don’t even need to enter a credit card until you actually spin up a cluster.
- Elastically scale production workloads from 0 to 100 MB/s and down instantaneously without ever having to size or provision a cluster.
- World-wide availability, ensuring your data is adjacent to your applications or in your jurisdiction.
- The same open-source Apache Kafka APIs and wire protocol you would expect. This means you can integrate any library or client application compatible with Kafka from the large and thriving open-source ecosystem around it.
- Consumption-based pricing so you only pay for what you use and not for provisioned capacity.
- Cloud independence: bridging hybrid clouds to make your data available on GCP, Azure, or AWS. To the streaming developer, this provides Confluent Cloud on multiple cloud providers, giving users the ability to leverage various cloud-native services along with Kafka.
Confluent Cloud on GCP: Expanding the Kafka Ecosystem
To that end, we are pleased to announce that we are also expanding Confluent Cloud to Google Cloud Platform. This is a significant development because many Kafka developers and enterprise customers want to use GCP services such as BigQuery and TensorFlow. The new Confluent Cloud on GCP enables users to combine the leading Kafka service with GCP services to support a variety of use cases. Let’s now take a look at how Bob and Mary can use Confluent Cloud on GCP to start focusing on their applications in minutes:
- Bob signs up for Confluent Cloud and creates a cluster on the Google Cloud Platform. He then uses a source connector to connect his data source to the cloud and writes up a client based on the language of his choice to push data into this cluster. Once this data is in the Kafka cluster, Bob can leverage Kafka’s storage capabilities to retain data, process data (using Kafka-native frameworks like Kafka Streams or ksqlDB or GCP-native tools like Dataflow or Dataproc), or stream data to TensorFlow, until he completes his time series models. With Confluent Cloud, Bob is now able to focus on the time series that will make a difference to his end user!
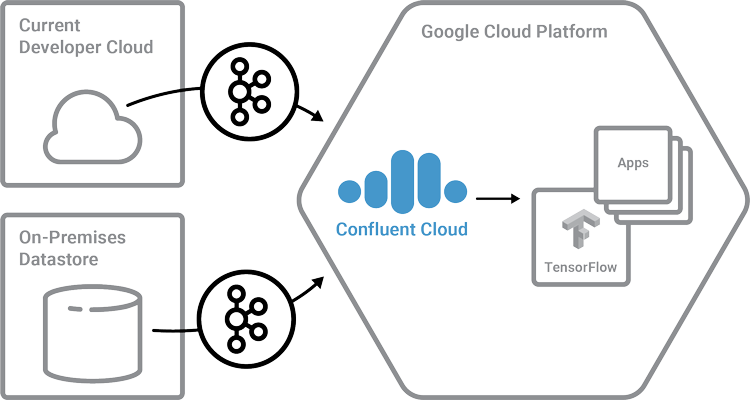
- While Mary’s scenario is slightly more complex, Confluent Cloud helps her start writing her application with ease. Once Mary creates herself a cluster on GCP and her other cloud provider, she will use a Kafka Connect connector to load data from her existing data warehouse to Confluent Cloud. After that, the Confluent Replicator will keep the GCP cluster in sync with all the real-time and historic data while even keeping consumer offsets straight between the two clusters and also maintain the right offsets for her. All of this data can be streamed into Google Cloud Storage, which makes it available to her BigQuery applications.
How can I get started with Confluent Cloud?
Below is a quick demonstration of how you can get started within minutes.
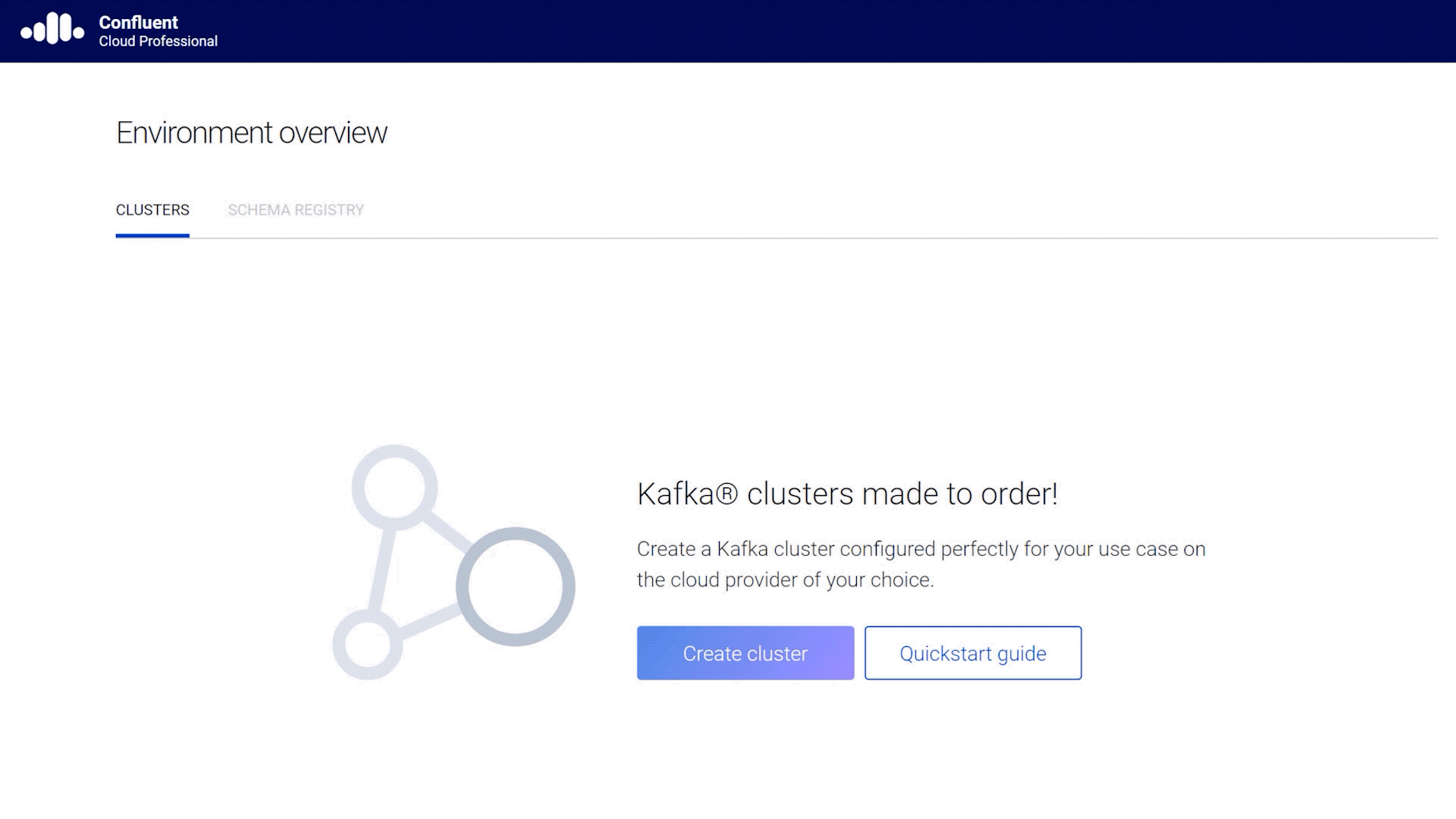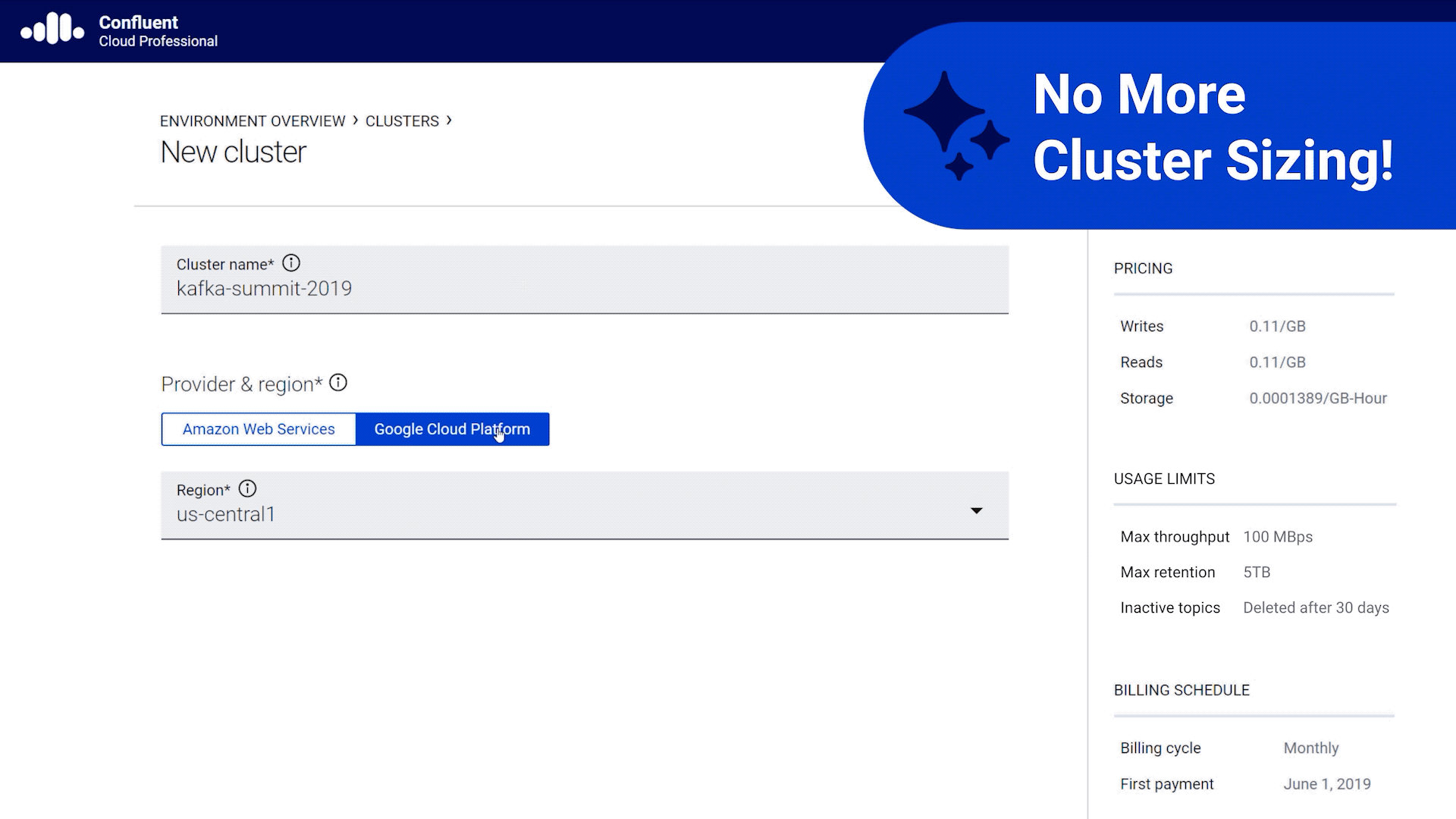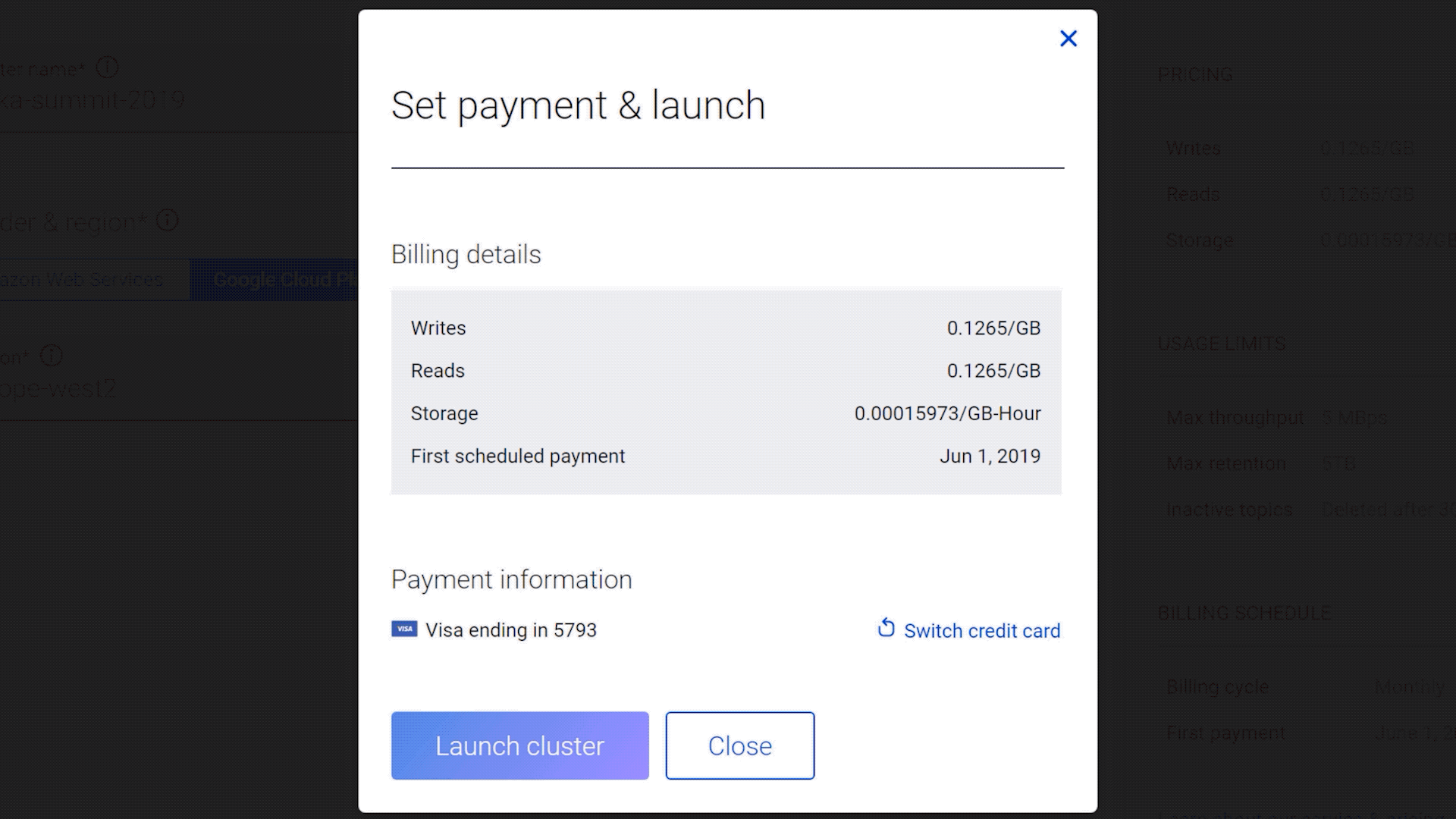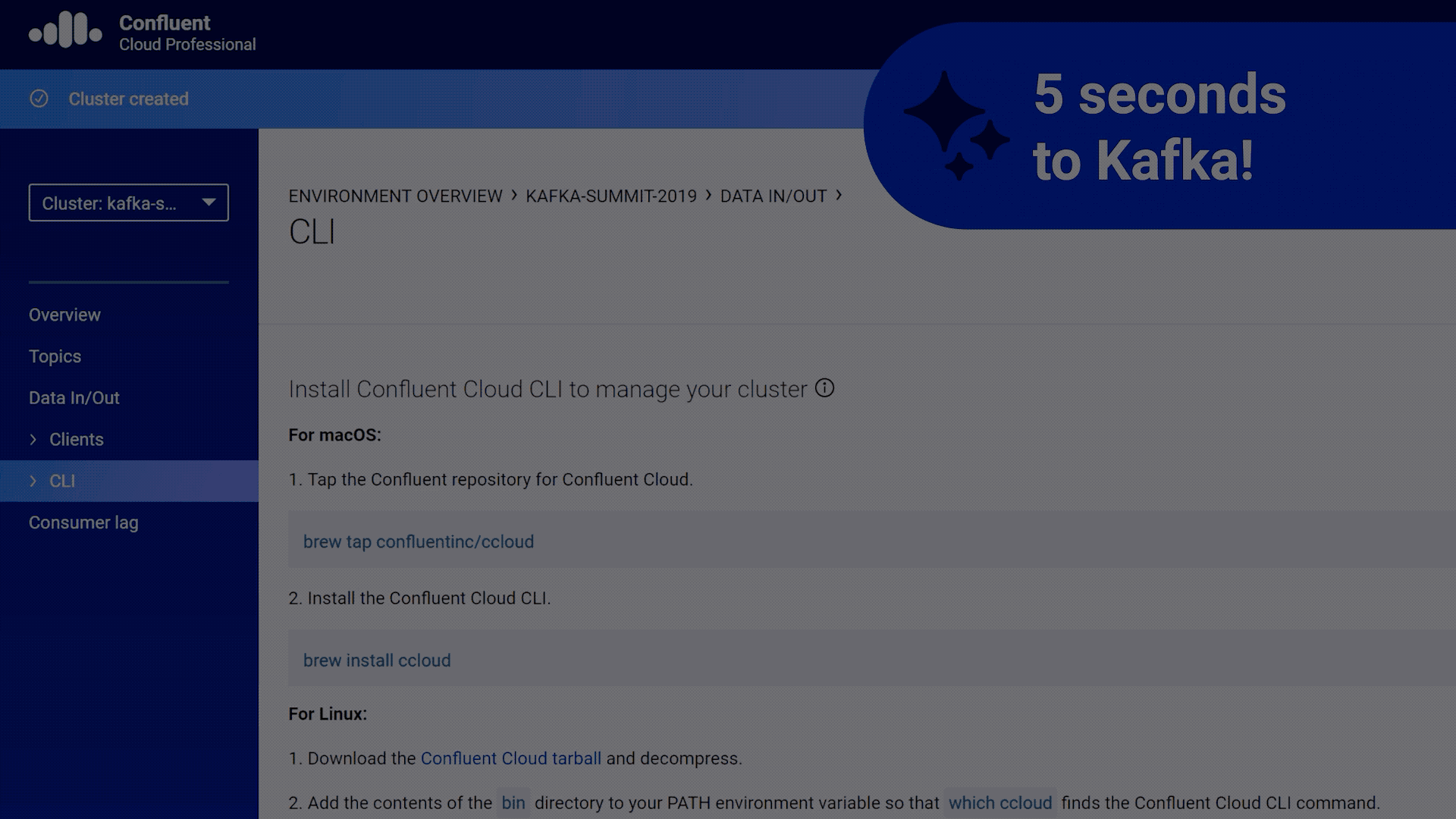
Click here to experience the ease of building your applications on Confluent Cloud. And as with the first launch of any product, we look forward to your feedback on the user experience, the product and features that’ll help you build applications on Confluent Cloud more effectively. Join us in our Slack Community in the #confluent-cloud channel.
Summing It Up
The twin capabilities of offering a self-service Apache Kafka for developers and access to a broad cloud ecosystem are highly significant developments for you, the Kafka developer. It now allows you to focus on leveraging Kafka without worrying about the operational burden of running one. It also offers a choice of technology and tools, that are best suited to the application. At a grassroots level, these are stepping stones that every developer has wanted. At Confluent, these capabilities help us provide you with the key cornerstones of every enterprise’s journey to become an event-driven organization—building applications that analyze data at massive scale, without an operational burden on the developer!
Did you like this blog post? Share it now
Subscribe to the Confluent blog



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.