生成 AI とは?
生成型人工知能 (生成 AI) とは、学習に使用したデータに基づいて、テキスト、画像、音声、動画などの新しいコンテンツを生成する AI モデルを指します。生成 AI は、自然言語処理アルゴリズムと組み合わせたディープラーニングパターンを活用して、大規模データセット内のパターンを分析し、状況に応じた応答をリアルタイムで生成します。
ChatGPT
OpenAI が開発した ChatGPT は、人間のようにユーザーと対話する会話型 AI モデルです。質問への回答、説明の提供、幅広いトピックに関する対話に参加することができます。ChatGPT は、高度な自然言語処理 (NLP) 機能を活用することで、カスタマーサービス、教育、パーソナルアシスタントといった用途で使用され、高度な AI テクノロジーを一般の人々が利用できるようにしています。
GitHub Copilot
GitHub と OpenAI の共同プロジェクトである GitHub Copilot は、開発者がコードを記述するときにリアルタイムでコードスニペットと関数全体を提案して支援する AI 搭載のコード補完ツールです。開発者が記述しなければならない定型コードを減らし、コンテキストに応じた提案を行うことで、生産性の向上や初心者のスムーズなプログラミング習得を支援します。GitHub Copilot は、大規模言語モデルを活用し、さまざまなプログラミング言語に対応したコードの理解と生成を行います。
Stable Diffusion
Stable Diffusion は、テキストによる説明から高品質な画像を生成する高度な AI モデルです。拡散モデルを利用し、ユーザーのプロンプトに基づいてリアルで芸術的なビジュアルを作成します。このツールは、ビジュアルを迅速かつ効率的に生成する必要があるアーティスト、デザイナー、コンテンツクリエーターにとって特に価値があります。Stable Diffusion は、ビジュアルコンテンツ制作への参入障壁を下げることで、個人や中小企業が広範なリソースや技術的な専門知識なしでプロ級のグラフィックスを制作できるようにします。
生成 AI の仕組み
生成 AI はプロンプトから始まります。ユーザーがクエリを送信すると、生成 AI はユーザーに合わせて正確に調整された意味のあるコンテキストコンテンツを生成します。これらの出力を作成するために、AI モデルはディープラーニングのパターンと__自然言語処理 (NLP)__アルゴリズムという2つの主要なコンポーネントを組み合わせます。



__ディープラーニング__は、多層ニューラルネットワークを用いてデータ内の複雑なパターンをモデル化する機械学習の一部です。画像処理には畳み込みニューラルネットワーク (CNN)、シーケンシャルデータにはリカレントニューラルネットワーク (RNN) などのアーキテクチャを使用します。トレーニングには、逆伝播と勾配降下法を用いた重みの調整が含まれ、大量のデータセットとかなりの計算能力が必要です。ディープラーニングは、コンピュータビジョン、自然言語処理、音声認識などのアプリケーションで優れており、従来の機械学習方法では困難だったタスクでも最先端のパフォーマンスを発揮します。
生成 AI は一般的にディープラーニング技術を活用します。画像やビデオの生成などのタスクには CNN を使用し、特定のシーケンシャルデータタスクには RNN を使用できます。ただし、自然言語処理では、主にトランスフォーマーと呼ばれる高度なニューラルネットワークアーキテクチャを使用します。__トランスフォーマー__は、連続データの処理と長距離依存関係の把握に優れています。2017年に Vaswani らが論文『Attention is All You Need』で導入したトランスフォーマーアーキテクチャは、生成 AI で使用されているモデルを含む、多くの最先端の NLP モデルの基盤となっています。
トランスフォーマーは__ベクター__を使用し、単語を数値配列として表現します。これらのベクターは、各単語の他の単語に対する重要性を計算する自己注意メカニズムと、順序を付加する位置エンコーディングによって変換されます。マルチヘッドアテンション層とフィードフォワード層は、これらのベクターを複雑なデータ処理と生成のために改良します。



GPT のようなモデルは、膨大なテキストのコンパイルを通じて言語パターンを学習するためにトランスフォーマーで事前にトレーニングされ、その後、翻訳や要約などの特定のタスクに対して微調整されます。このアプローチにより、コンテキストの理解が深まり、転移学習が可能になり、広範なラベル付きデータの必要性が減少します。生成 AI の生成機能により、人間のようにテキストを作成したり、質問に答えたり、会話をシミュレーションすることができ、入力プロンプトやモデルパラメーターを調整することでテキスト生成を細かく制御できます。
__AI モデル生成__は、特定のタスクを実行するために AI システムを作成および改良するプロセスです。予測によく使用される従来の AI モデルは、過去のデータを分析して将来の結果を予測することに重点を置いています。これらのモデルは通常、売上予測、リスク評価、推奨システムなどの用途に使用され、過去のデータに基づいてパターンを��特定し、情報に基づいた予測や分類を行います。
LLM とは?
AI モデルの作成、改良、最適化のプロセスは LLM の開発と強化に不可欠であり、高品質でコンテキストに適したコンテンツを生成し、幅広い言語関連のタスクを実行できるようにします。
生成 AI で使用される LLM は、洗練された AI モデル生成プロセスを使用します。そのいくつかの例を以下にご紹介します。
事前トレーニング
LLM は、最初に、多様で大量のテキストを含む広範なデータセットでトレーニングされます。このフェーズは、モデルが一般的な言語パターン、文法、および文脈的な関係を学ぶのに役立ちます。
微調整
事前トレーニング後、LLM は微調整プロセスを経て、より小規模なタスク固有のデータセットでさらにトレーニングされます。このステップは、言語翻訳、テキスト要約、質問応答などの特定のタスクを実行するためのモデルの能力を洗練させます。
反復的改善
モデルは、トレーニング、評価、調整のサイクルを通じて繰り返し改善されます。さまざまなタスクでのパフォーマンスからのフィードバックは、パラメータを改良し、精度と効率を向上させるために使用されます。
専門化
場合によっては、転移学習のような追加の手法が適用され、事前にトレーニングされたモデルが最小限のデータで新しいタスクに適応されることがあります。この特殊化により、モデルは特定のアプリケーションでより効果的になります。
What’s Different About GenAI: Reusable Foundation Models
Data engineering has evolved from mining historical data to a more real-time, prompt-based approach. Instead of relying on static data, GenAI uses prompts to pull relevant data in real time. This shift simplifies the process by eliminating the need for complex statistical functions, replacing them with a vector search. Vector searches, powered by machine learning, sift through unstructured data, offering a streamlined way to find relevant data points without the need for extensive data processing.
LLMs trained on generic, publicly available data can be enhanced with retrieval-augmented generation (RAG). RAG is an architectural pattern that integrates real-time, context-specific data to help LLMs at prompt time.
Traditional methods of training models on static data can lead to outdated results. For example, if flights are canceled due to a storm, an older model might not be aware of this recent development. In contrast, GenAI using an LLM-RAG pattern can access and utilize real-time data to generate more current and accurate responses.

予測型人工知能
予測型人工知能は、統計モデルを適用し、過去のデータのパターンに基づいて結果を予測します。これらのモデルは過去の行動や傾向を分析し、将来の出来事について情報に基づいた予測を行います。
これらのモデルを作成するには、綿密なデータエンジニアリングと特徴量エンジニアリングが必要です。データエンジニアは、データの品質と関連性を確保するために、データをキュレーションし、前処理を行う必要があります。特徴量エンジニアリングには、データ内の基礎的なパターンを効果的に捉える変数の選択と変換が含まれます。このオーダーメイドのアプローチは、特定のユースケースに合わせて機械学習モデルを調整し、予測を行う際の精度と信頼性を最適化します。
生成 AI
生成 AI はディープラーニングモデルを使用して、静的データとリアルタイムのプロンプトからカスタマイズされたコンテンツを迅速に作成します。広範な公開データセットでトレーニングされた再利用可能なモデル (基盤モデル) を採用しています。これらのモデルは、一度エンドツーエンドの学習を行うことで、さまざまなユースケースに対して汎用的かつ適用可能となり、新しい関連コンテンツの生成を最適化します。
特定のデータセットに関する広範な統計分析を必要とする従来のモデルとは異なり、LLM などの基盤モデルは、プロンプト時のデータエンジニアリングに依存しています。このアプローチでは、モデルに既に組み込まれている膨大な量のトレーニングデータを活用するため、特別なデータ準備の必要性が軽減されます。
LLM の幅広い適用性により、開発プロセスが合理化され、さまざまなドメインや業界にわたって迅速に展開および適応することが可能になります。
生成 AI が重要な理由 : メリット
McKinsey によると��、生成 AI はさまざまなユースケースで年間2.6兆ドル~4.4兆ドルを追加で生み出す可能性があります。McKinsey は「生成 AI のユースケースが提供できる価値の75%は、カスタマーオペレーション、マーケティングおよびセールス、ソフトウェアエンジニアリング、研究開発の4つの領域に当てはまる」と予測しています。生成 AI は、以下を始め、事業運営を変革する多くの利点を提供します。
生成 AI は、タスクを自動化し、膨大な量のデータを迅速に処理することで業務の進め方に革命をもたらし、意思決定の改善につながります。チャットボットやバーチャルアシスタントなどのツールは、リアルタイムの支援を提供することで顧客サービスを強化し、顧客が人間の介入なしに製品を選択できるように支援します。生成 AI は人を置き換えるのではなく、労働者の生産性を高め、タスクの効率を2倍にする可能性があります。このテクノロジーを活用する労働者のほとんどは、少なくとも10%のタスクが2倍の速さで完了 することを実感しています。例えば、生成 AI を使用する営業チームは、特定のタスクで生産性が2倍になる可能性があります。
生成 AI は、音声合成、デザインや画像の作成、ビデオ制作、音楽編集、コーディング、3D モデリングなどのさまざまなタスクで、時間とコストを大幅に節約します。生成 AIは、低レベルで時間のかかるタスクを実行することで、迅速な意思決定、効率の向上、運用コストの削減のための洞察を即座に提供します。
生成 AI は障壁を下げることにより、特に研究集約型産業におけるイノベーションを促進します。たとえば、製薬業界では、生成 AIは研究開発プロセスを迅速化し、創薬におけるリードの同定を数か月から数週間に短縮す�ることができます。小売業では、生成 AI により、企業は顧客データに基づいて新しいオファリングをパーソナライズし、顧客満足度を向上させることができます。
生成 AI は、新たなニッチを見つけた中小企業 (SMB) に機会を提供し、大企業とのコンテンツ、技術、人材のギャップを埋めるのに役立ちます。中小企業は、まるで航空母艦に比べてスピードボートが素早く方向転換するように、機敏に対応できます。生成 AI はこのプロセスを加速し、中小企業がリソースを最適化し、市場の変化や機会に迅速に対応できるようにします。
生成 AI は、創造的な取り組みに特に役立つ強力なツールキットです。映画のストーリーボードを即座に生成し、ライブフィードバックに基づいて改良することができます。マーケ�ティングコンテンツの作成や、追加する新製品の機能の決定についても同様です。生成 AI は、プロジェクトで何をすべきかについての推奨事項を即座に提示します。生成 AI が提供する情報のスピードと完全性により、意思決定プロセスが合理化され、より効果的な戦略とより良い結果がもたらされます。この機能により、企業やチームは、より迅速で包括的な開発プロセスで進化する市場の要求に応えることができます。
生成 AI は知識の習得プロセスを簡素化します。複数の検索エンジンを使って検索したり、無数のレビューやドキュメントをスクロールする代わりに、ユーザーは生成 AI にクエリを実行できます。生成 AI が生成するコンテンツの品質は、継続的に向上しています。たとえば、従来は高品質な動画の制作に多額の費用と多くのスタッフの関与が必要で、完成までに数週間を要していました。今では、高品質の動画をほぼ瞬時に作成できます。これにより、個人でも高コストかつ大規模なプロジェクトを迅速に実行でき、生成 AI を活用してさらに改善することで、より短時間で優れた成果を得ることができます。後処理も、精度を確保するうえで有効です。
Challenges and Considerations
Despite its immense potential, the adoption of GenAI poses several challenges:
Hallucinations can be compelling, articulate, thorough, and wrong. When wrong, these can have significant consequences–including legal repercussions–to business ops and reputation.
Understanding how GenAI works, building, and integrating it into existing workflows takes time and resources. Early adopters exist, but there is a significant gap before the entire developer population can implement GenAI effectively. Bridging this knowledge gap requires understanding advanced AI capabilities, how large language models (LLMs) work, the type of data needed to train models, and how to build patterns like retrieval-augmented generation (RAG). Continuous education on concepts like RAG is essential for AI adopters.
GenAI is only as good as the data set it is trained on. To prevent knowledge gaps and hallucinations, the model needs access to more data sets, such as real-time, domain-specific data, proprietary data within an organization, customer data including PII, in order to generate meaningful and accurate responses. However, data is often spread across databases, data warehouses, SaaS applications, message queues, and file systems, creating rigid enterprise data architectures with tightly coupled producers-consumers, point-to-point connections, and batch processing. These complexities, along with data governance and security issues, contribute to stale, low-quality data.
Staying updated on the latest AI technologies and best practices is essential for successful adoption. To navigate GenAI’s ever-changing landscape, users need to discern which LLM, language processor, vector database, and vector embedding to use. In addition to the many options available, new ones are constantly coming into the market.
There are also tradeoffs between using smaller versus big-name tools. While smaller tools offer flexibility, concerns exist around the need for rewriting existing components. On the other hand, big-name tools may offer robustness, but their slower pace in implementing new features could be a disadvantage.
Developing custom AI tools can have significant business impacts, particularly regarding AI governance, enterprise data management, and legal and privacy issues. For example, if a customer service AI chatbot provides false answers or reveals sensitive information, it could lead to customer dissatisfaction, churn, and potential litigation, damaging the brand and reputation. Similarly, job sites using LLMs to analyze resumes must address data privacy concerns. Ensuring AI governance, security, and trustworthiness is crucial to mitigating these risks.
While organizations can leverage an LLM as a starting point, they need people and technology resources to build and support customer-facing GenAI applications. The availability of AI-specialized architects, developers, and data engineers is uneven across regions. Ensuring access to these skilled professionals is crucial for the successful implementation and maintenance of GenAI solutions.
生成 AI のユースケース
生成 AI は、多くの業界やユースケースで幅広い用途に応用されています。ここでは、一般的なリアルタイム生成 AI の使用例をいくつか紹介します。
セマンティック検索
生成 AI はクエリのコンテキストとセマンティクスを理解することで検索機能を強化し、より正確で関連性の高い結果を提供します。
カスタマーサービス
生成 AIを搭載したチャットボットとバーチャルアシスタントは、リアルタイムでサポートを提供し、顧客の問い合わせに効率的に回答して問題を解決することで、全体的な顧客満足度を向上させます。
コンテンツの発見と推奨
生成 AI は、ユーザーの嗜好や行動に基づいてコンテンツをパーソナライズし、ユーザーのエンゲージメントと満足度を高めます。
エージェント (タスク自動化)
生成 AI は、スケジューリング、データ入力、レポート作成などの定常的なワークを自動化することにより、業務効率を向上させ、従業員がより戦略的な活動に集中できるようにします。
物流の最適化
GenAIは、サプライチェーンの運用を分析および最適化することにより、ロジスティクスを改善します。ルート計画、在庫管理、需要予測に役立ち、タイムリーな配送を確保し、運用コストを削減します。これにより、物流およびサプライチェーンネットワークの全体的な効率と信頼性が向上します。生成 AI 対応の物流には多額の投資が行われていますが、このユースケースはまだ他のアプリケーションほどの成功を収めていません。
Additional GenAI use cases include:
GenAI is used for tasks like writing and summarizing text, generating code, and creating chatbots. It helps computers understand and respond to human language more effectively.
GenAI can transcribe spoken words, making it easier to input information without typing. Similarly, it can generate audio from text. GenAI can also analyze sounds to detect patterns or issues, such as determining the purity of metals or diagnosing engine problems by listening to specific noises, offering valuable applications in industries like manufacturing and logistics.
GenAI can produce images and videos, quickly visualizing concepts and generating new creative content. In retail, it assists in training warehouse robots. In the automotive industry, it aids self-driving cars by gathering and processing live image data from many cars driving on different roads, enhancing navigation capabilities and reducing the need for extensive model training. Live data feeds from cars can train LLMs to visually recognize objects like cars, pedestrians, and trees.
Synthetic data expedites the testing process and accelerates the training of machine learning models. Enabling quicker development cycles, synthetic data serves as a rapid and efficient method for prototyping and building applications.
For robotics and manufacturing, synthetic data helps create a digital twin of a factory for testing process flows. This optimizes interactions between humans and robots and identifies potential bottlenecks in manufacturing inefficiencies, such as machine placement issues causing delays. This knowledge enables adjustments to enhance overall production, including relocating machines to minimize disruptions and mitigate risks (e.g., eliminating the cross-traffic risk of a human running into a robot).
Synthetic data also aids time-motion studies to optimize factory output. These studies involve direct and continuous observation of tasks to reduce production costs, a method initially pioneered by Ford. Traditionally, time-motion studies require significant human time and effort. In contrast, machine learning can run numerous scenarios autonomously, providing the most optimized flow for manufacturing lines, air traffic control, or airport construction. For instance, machine learning insights might indicate the need for larger landing lanes on the east side of a terminal, informing airport design based on accumulated data.
For information privacy, GenAI can generate synthetic data without breaching trust, privacy or security. This synthetic data allows for sharing with business partners for testing and integration purposes, without exposing sensitive information like personal identifiable information (PII). Additionally, generating data schemas provides a clear understanding of how the data will be used and processed.
GenAI creates realistic 3D models for virtual prototyping and testing real-world scenarios in various industries. In urban planning, GenAI simulates traffic flows to predict congestion patterns and optimize transportation routes. In manufacturing, it simulates production processes to identify potential bottlenecks before they occur. For logistics, GenAI minimizes delays through rapid analysis of real-time data, dynamically adjusting shipping routes based on real-time weather, traffic, or delays to identify the most efficient, cost-effective, and shortest land and sea routes.
生成 AI モデルの種類
生成 AI はニューラルネットワークを利用して既存のデータ内のパターンを識別し、新しいオリジナルコンテンツを生成します。ラベルのない大量のデータでトレーニングされた LLM などの基礎モデルを使用しています。生成 AI モデルにはさまざまな種類があります。
拡散モデル
拡散モデルは、リアルな画像やまとまりのある文章など、高品質の出力を作成します。これらのモデルは、データセットにノイズを追加することで学習し、進行性のノイズ除去によってプロセスを逆転させ、このノイズ化プロセスを逆転させることでデータを認識して生成することを学習します。
敵対的生成ネットワーク (GAN)
ディープラーニングアーキテクチャの一種である GAN は、現実的なデータサンプルを生成するために連携する2つのニューラルネットワークで構成されています。一方のネットワークはデー�タを生成し (ジェネレーター)、もう一方のネットワークはデータを評価します (ディスクリミネーター)。GAN は互いに競争することで絶えず改善され、より信頼性の高い出力を生み出します。
変分オートエンコーダ (VAE)
VAE は、入力データを潜在空間 (本質的な特徴をコンパクトに表現したもの) に圧縮し、それを再構築します。この潜在空間からサンプリングすることで新しいデータサンプルを生成し、斬新で多様な出力の作成を可能にします。
自己回帰モデル
自己回帰モデルは、同じシーケンスからの以前の入力を分析して、シーケンス内の次の要素を予測します。これらのモデルは、各単語が前の単語に基づいて生成されるテキスト生成などのタスクでよく使用され、文中の次の単語を予測するようなタスクに頻繁に用いられます。
リカレントニューラルネットワーク(RNN)
RNN(リカレントニューラルネットワーク)は、時系列や連続データを処理するために、前のステップの情報を保持しながら動作するよう設計されたニューラルネットワークアーキテクチャの一種です。これらのモデルは、トランスフォーマーモデルが登場する以前は、テキスト予測などのタスクで高い精度を誇る定番の手法でした。LLM と組み合わせることでその強みを生かすことができますが、トランスフォーマーほど効率的ではありません。
トランスフォーマーモデル
トランスフォーマーモデルは、自己注意メカニズムと自然言語処理能力で知られるニューラルネットワークアーキテクチャの一種です。これらのモデルは、GPT、Claude、Llama、Gemini の基礎として機能し、LLM 内で RNN を組み合わせています。通常、公開データでトレーニングされたこれらのモデルは、コンテキストを理解し、シーケンス内の将来の要素を高精度で予測します。
Confluent を使用した生成 AI の構築



__データ拡張 : __多くの場合、生成 AI アプリケーションを構築する最初のステップは、検索拡張生成 (RAG) 用のベクターストアの開発とデータの入力です。Confluent はこのプロセスで重要な役割を果たしています。まず、データ拡張と、生成 AI アプリケーションのためにリアルタイムのコンテキストナレッジベースを構築する方法について説明します。
Confluent は、包括的なコネクタ戦略を通じて、企業全体の異なるデータの統合を簡素化します。Confluent は120点を超えるコネクタを備えており、リアルタイムのデータソースと同期を容易にします。例えば、S3 と Salesforce からのデータを統合する必要がある場合、Confluent には、このデータをシームレスに Confluent に取り込んで統合するための事前構築された Confluent Connector があります。この機能により、顧客や業務運営に関連する独自データの最新バージョンに即座にアクセスでき、生成 AI アプリケーションを強化することが可能になります。


これらのデータストリームには未加工の情報が含まれていることが多いため、データをより使いやすい��形式に変換するための処理が不可欠です。ストリーム処理を使用すると、個々のストリームをさまざまなアクセスパターンに適したビューに変換、フィルタリング、集約できます。
次に、Flink SQL モデル関数を使用して、ベクター埋め込みサービスでデータのチャンク化と埋め込みを処理し、その後、処理されたデータをベクターストアに渡すことができます。Confluent は、MongoDB、Pinecone、Weaviate、Zilliz などの主要なベクターストアとのネイティブ統合を構築しています。
LLM クエリでのリアルタイムのナレッジベースとコンテキスト化のためのデータの準備
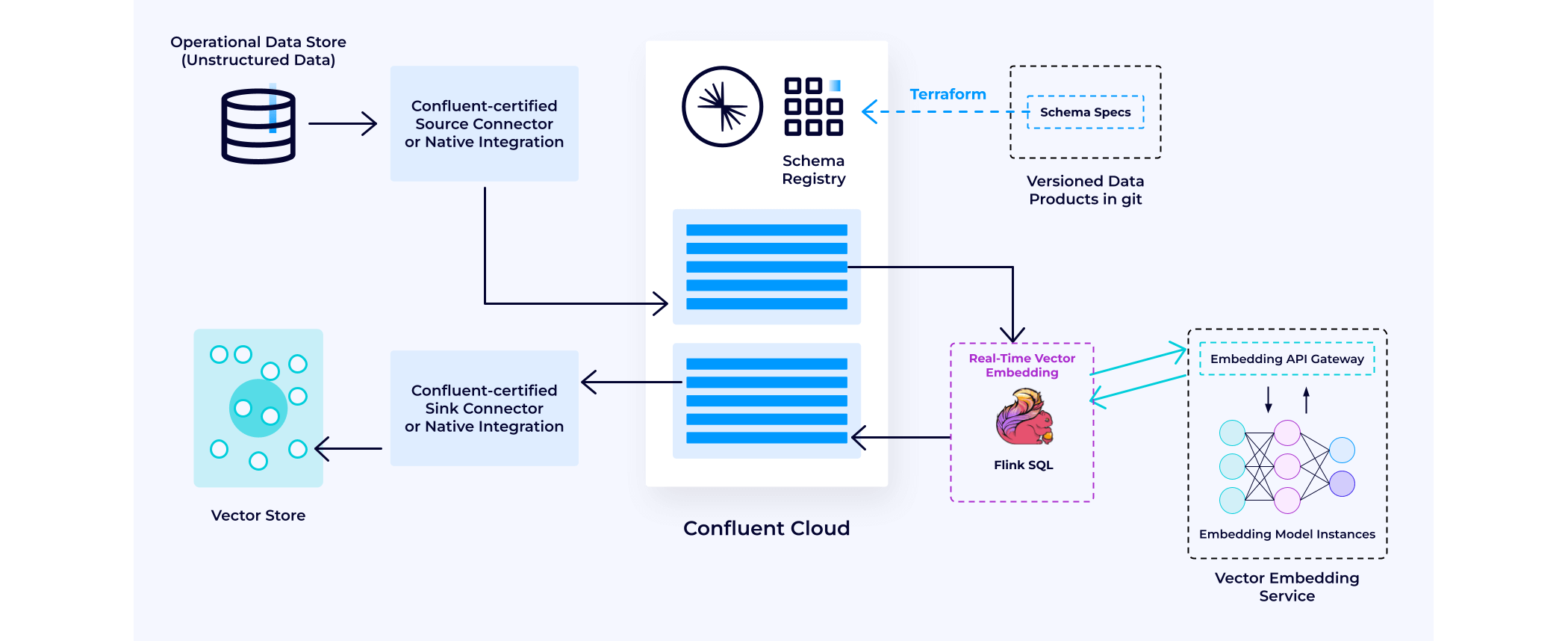
このパターンにより、ベクターストアの継続的なリアルタイム更新が可能になります。これにより、面倒なポイントツーポイントのバッチETLプロセスを使用せずに、ベクターデータベースを入力・管理することができ、情報の遅延を本質的に防ぎます。
これらはすべて、イベントドリブン型アーキテクチャパターンに基づいて構築されています。つまり、企業のナレッジがベクターストアにエンコードされると、アクセス可能なパターンで将来のプロンプトに意味的に関連付けることができます��。新しいプロンプトが到着すると、Confluent は最も関連性の高い企業ナレッジを特定し、それを LLM に提供して、将来の応答を強化します。
生成 AI アプリケーションを構築するための4つのステップ
LLM 対応アプリケーションは、通常、以下の4つのステップに従って構築されます。各ステップの概要と Confluent の使用方法は次のとおりです。
データ拡張
これには、生成 AI アプリが最新かつ更新済みのデータセットにアクセスし、それを LLM クエリにおいてコンテキスト化できるようにするためのデータ準備が含まれます。これにより、生成 AI アプリケーションのためのリアルタイムナレッジベースが構築されます。
Confluent は、さまざまなデータソースからデータストリームを継続的に取り込み、処理して、リアルタイム�のナレッジベースを作成します。このフェーズでは、Flink SQL のようなツールがベクター埋め込みサービスを呼び出し、データをベクターで拡張することができます。処理されたデータは、シンクコネクタを使用してベクターデータベースに格納されます。この設定により、継続的に更新される情報を含むベクターデータベースに対する検索拡張生成 (RAG) が可能になります。
推論
このステップでは、ユーザークエリのコンテキスト化と、生成 AI アプリケーションがそれらの応答を効果的に処理できるようにすることに重点が置かれます。
Confluent では、コンシューマーグループが Kafka Topic からユーザーの質問とプロンプトを取得し、ベクターストアデータベースのプライベートデータでそれを充実化します。このプロセスでは、ユーザーのクエリを調べ、それを使用してベクターデータベース内でベクター検索を実行し、関連する結果を追加のプロンプトとして追加します。たとえば、フライトが欠航となった場合、KNN (k 近傍法) 検索により、次に利用可能な最適なフライトオプションを特定できます。このように充実化され、コンテキストに関連したデータは LLM サービスに送信され、包括��的な応答が生成されます。
ワークフロー
これには、自然言語を解析し、高品質な情報を合成し、状況に応じた推論を即座に適用することが含まれます。
生成 AI アプリケーションが単一の自然言語クエリを構成可能な複数の論理クエリに分割し、リアルタイムで情報を利用可能にするために、推論エージェントがよく使用されます。このアプローチは、クエリ全体を一度に処理するよりも効果的です。 このようなワークフローでは、一連の LLM 呼び出しが使用され、推論エージェントがプロンプトの出力に基づいて次のアクションを決定し、シームレスな対話とデータ取得を可能にします。
後処理
このステップでは、より透明性の高いモデルを使用してビジネスロジックとコンプライアンス要件を強制し、LLM が妥当で信頼できる回答を確実に返せるようにします。
多くの組織は、LLM の出力にそのまま依拠することにまだ不安を感じています。自動化されたワークフローでは、すべてのアプリケーションにビジネスロジックとコンプライアンス要件を適用するステップが含まれています。イベントドリブン型パターンを使用すると、生成 AI ワークフローを後処理から切り離すことができ、独立した開発と進化が可能になります。Confluent は、LLM の出力を検証し、ビジネスロジックとコンプライアンス要件を強制して、信頼できる回答を保証します。これにより、AI ドリブン型ワークフローの信頼性と精度が向上します。
その他のリソース
利用の開始
Confluent Cloud の利用を無料で開始し、生成 AI ユースケースのためのリアルタイムでコンテキスト化された信頼できるナレッジベースを構築し始めましょう。