Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Project Metamorphosis Month 5: Global Event Streaming in Confluent Cloud
This is the fifth month of Project Metamorphosis: an initiative that addresses the manual toil of running Apache Kafka® by bringing the best characteristics of modern cloud-native data systems to the Apache Kafka ecosystem served from Confluent Cloud. So far, we’ve covered elasticity, cost, infinite, and everywhere—a targeted set of features that make event streaming easier to use, deploy, scale, and operate. This month, we’re excited to announce a step-change release that makes event streams in Confluent Cloud 100% global.
In the video below, we introduce this month’s theme, Global, and walk through the structure of Project Metamorphosis.
Truly global systems are a relatively new phenomenon, only really coming of age in the last 10 or 15 years, but their growth has been rapid, and there is good evidence to support this. Cross-border data flows now account for more than $2.8 trillion of global GDP. To put that in context, it’s more than the total value of trade in physical goods—be it sugar from Mauritius or iPhones from China—and more than 45 times the level it was a decade ago.
We feel this shift to global systems intuitively too. When we turn on a TV, open a social network, swipe our credit card, flip a smart switch, or start our favorite music streaming service, we expect the software to behave in a certain way and that expectation is the same whether we’re sat at home, or traveling in a different country. What you may not know is that Kafka sits behind most of these technologies, moving data from place to place. A kind of digital central nervous system that connects the different facets of most global digital companies together.
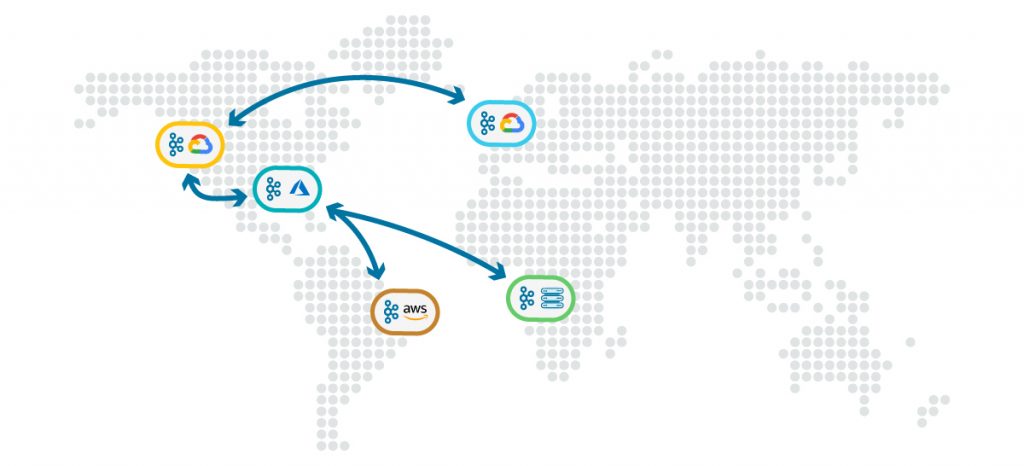
Despite Kafka’s deep market penetration, the tools that enable a global event streaming platform—tools like Confluent Replicator or Kafka’s MirrorMaker—still leave operators with a challenge. A plethora of clusters located in different datacenters around the world must be lashed together, somewhat clumsily, one at a time. Perhaps more importantly, while these tools transfer events reliably between Kafka clusters, the guarantees fall short of those Kafka provides inside a single cluster, and this disparity amplifies operational pains.
To address this, we are proud to announce Cluster Linking in Confluent Cloud. Linked clusters inherit all the best properties of previous solutions like Confluent Replicator or MirrorMaker: a zero-bottleneck, highly available architecture, and the ability to buffer indefinitely to support high latency and unreliable networks.
But Cluster Linking takes global replication a significant step further by incorporating many of the guarantees found in Kafka’s internal protocols. This allows event streams to travel seamlessly between different clusters around the globe, accurately preserving the exact order, partitioning, and offsets of the original data streams. They can be scaled up and down as regional workloads dictate. There are also no additional systems to maintain like MirrorMaker or Confluent Replicator, etc.
The result is something previously unobtainable: Kafka clusters, wherever they may be, can be linked via Confluent Cloud to create a single “virtual Kafka cluster” that spans the globe. So wherever your application runs, it will see precisely the same event streams.
For example, you can spin up a high-throughput Confluent Cloud cluster running in Google Cloud’s us-east1 datacenter. Next, you can choose to link this to a Kafka cluster running in a datacenter of your own in New York, extending the New York based orders, customers, and payments topics into the cloud. The resulting linked topics are identical to the source ones in every way.
You might then decide to filter the orders stream using Confluent Cloud’s ksqlDB, retaining only non-U.S. orders, and link the resulting event stream to a Confluent Cloud cluster running in AWS’s ap-southeast-2 region. Confluent Cloud will instantiate the new cluster, create the topic, back-populate it, and keep it up to date with the real-time stream of events.
The key innovation here is a technical one—making topics appear seamlessly and identically between different clusters—but the biggest benefit arguably comes from the improved workflow that emerges. Spinning up new clusters, linking them together, nominating topics to be replicated—are all carried out automatically with just a few commands. New clusters, new regions, exactly the same data, exactly the same storage offsets—all in real-time.
Let’s look into some of these use cases in more detail.
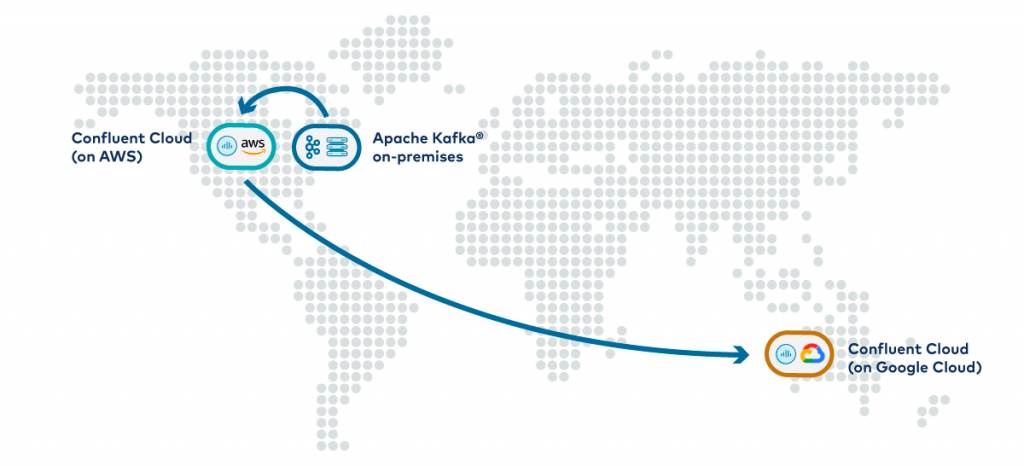
Hybrid cloud replication between on-premises Apache Kafka and Confluent Cloud
Hybrid cloud will be one of the primary challenges most companies will face over the coming decade. For those that started life on-premises, and are now in transition, this presents a particular dilemma. The public cloud provides enormous benefits in elasticity, cost, and developer productivity, but how can they get to the cloud when the primary systems that run the business are tightly tied to the on-premises infrastructure? New applications are inevitably sucked in by the gravitational pull of the data these existing systems own, thereby slowing the cloud transition tremendously.
One way around this problem is to federate the flow of data between Kafka and Confluent Cloud instances using Cluster Linking. Critical datasets, created by on-premises systems, are made available as event streams. These can be consumed either where they were created, or from Confluent Cloud, triggering applications into action or populating different types of databases or warehouses.
It’s also useful to think of the hybrid phase as a semi-permanent thing. Cloud transitions typically take years to complete, and for many companies, it remains cost-effective to exist in a hybrid state indefinitely. So, it’s important to take an approach that allows the architecture to evolve, regardless of its location. Global event streams provide the only truly practical way of doing this.
Cluster Linking provides specific advantages for use cases like these:
- An Apache Kafka (or Confluent Server) cluster, running on premises, can be linked directly to Confluent Cloud allowing seamless data transfer
- Topics in one region will be an exact mirror of the other, including the preservation of offsets, duplicate free, and including the replication of historical data
- Confluent Cloud clusters can be quickly spun up in different regions, populated with data, and scaled up and down as required
- With Kafka’s write once, read many paradigm, data only needs to traverse expensive network connections once, saving on cloud costs, in addition to limiting transfers to a single pipe that can easily be secured and monitored
Event streaming across different cloud providers
$ ccloud kafka link create aws-gcp $ ccloud kafka topic create --mirror metrics --link aws-gcp
Multi-cloud strategies, with several cloud vendors in use, are increasingly being adopted both as a purchasing strategy—to avoid the issue of lock in—as well as a software strategy—taking advantage of the different tools cloud providers offer on their specific platforms. For example, an enterprise might use AWS for its core application hosting needs but Google Cloud for their machine learning toolset.
For any enterprise leveraging either of these strategies, the movement of real-time data between different cloud providers will be a fundamental component of their solution. Kafka’s write once, read many paradigms makes the data that moves between cloud providers secure, observable, and, most importantly, cost effective. Just as Kafka is used to unify the movement of data among thousands of microservices, its same core characteristics are unifying the movement of data between datacenters and around the globe.
Cluster Linking lowers the bar for any business looking for this kind of heterogeneous multi-cloud strategy. Notably:
- Confluent Cloud is present in all major cloud providers, which makes linking clouds a simple affair
- Use pre-committed spend on different cloud providers to share data between them
- Stream data in the safety of a trusted secure, observable environment
How to start linking clusters
Cluster Linking is in early access on selected regions of Confluent Cloud and will be available for experimental use cases. We will be rolling it out globally across Confluent Cloud in the near future. For on-premises customers, the feature will be in preview in the upcoming Confluent Platform 6.0 release.
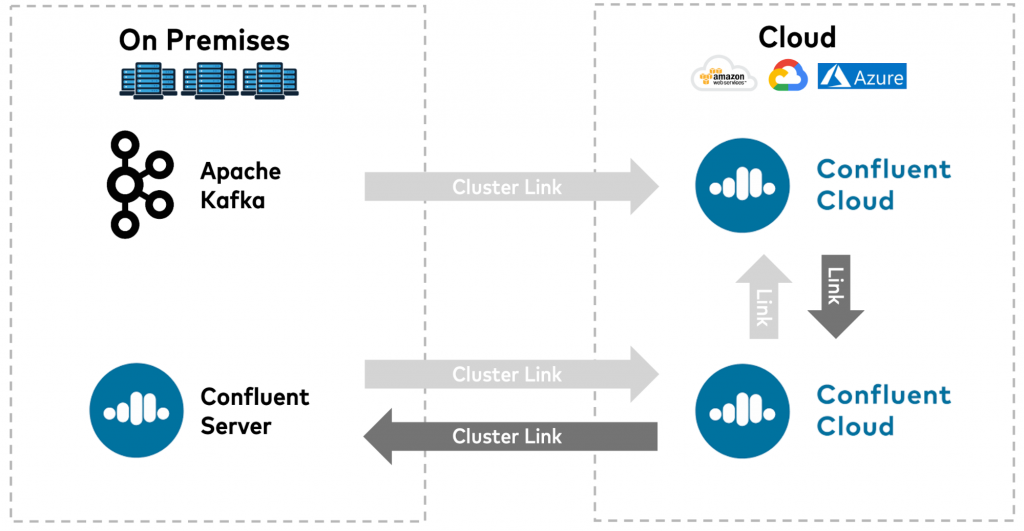
You can cluster link Confluent Cloud to any existing Apache Kafka 2.4+ cluster for unidirectional data transfers into the cloud or into a Confluent Server cluster. Bidirectional replication is available only among different Confluent Cloud or Confluent Server clusters, or a combination thereof.
Where are we taking Cluster Linking next?
The initial version of Cluster Linking is the first step of a longer journey. The initial feature set is in early access, but let’s take a look at some up-and-coming enhancements.
Making networking easier
Anyone that works in a cloud-native enterprise will know that networking is one of the biggest pain points when getting up and running with new tools and architectures. With Cluster Linking today, connections originate from the destination cluster. But this might not be desirable in some cases, particularly where the connection reaches from the public cloud back into an on-premises datacenter.
In the near future, you’ll be able to establish Cluster Links from either the source or destination side, removing the need for custom firewall rules and making it easier to comply with the InfoSec requirements that most enterprises mandate.
Easier cross-cluster high availability
$ ccloud kafka link reverse aws-gcp
To ensure the operational continuity of your business, disaster recovery often needs to extend beyond a single availability zone or region. Imagine that the AWS us-east-1 region goes down (yes, this can happen). The risk of revenue loss imposed by halting operations can be prohibitive in both cost terms and in the resulting damage to the company’s reputation.
Confluent’s Multi-Region Clusters provide an ideal solution for this problem on premises as it stretches a single Kafka cluster over regions, but for those wanting the advantages of physically separate clusters in each region, Cluster Linking provides a simple solution.
While the disaster recovery use case is theoretically possible with the first version of Cluster Linking, one of the most challenging aspects of high-availability deployments is the failback process. In the near future, Cluster Links will have the ability to be reversed, making the failover and failback processes near effortless.
The future of global event streaming
Event streams have already become a building block of most digital businesses, connecting vast application estates together with real-time data. This trend will inevitably grow in importance, spurred on by companies transitioning to the cloud and the effects of burgeoning digital globalization. Our goal with Confluent Cloud is to make event streaming simple, ubiquitous, and future proof. Cluster Linking is a primary foundation for this: Many Kafka clusters with one ubiquitous event streaming platform.
If you’d like to get started, you can use the promo code CL60BLOG for $60 of additional free Confluent Cloud usage.* No pre-provisioning is required, and you pay for only the storage being used.
To learn more, check out the Global page dedicated to this announcement.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.