Introducing the Confluent Parallel Consumer
Consuming messages in parallel is what Apache Kafka® is all about, so you may well wonder, why would we want anything else? It turns out that, in practice, there are a number of situations where Kafka’s partition-level parallelism gets in the way of optimal design. For example, when partition counts are fixed for a reason beyond your control, you need to call other databases or microservices—which can take a while to respond—or use queue-like semantics, where slow-to-process messages don’t hold up faster ones further back in the queue. These are just a few of the reasons why we wrote the Confluent Parallel Consumer, which provides an alternate approach to parallelism that subdivides the unit of work from a partition down to a key or even a message.
In essence, the Parallel Consumer is a JVM-based, Apache 2.0 client library that includes everything you’d expect in regular Kafka consumers: consumer groups, transactions/exactly-once semantics, etc., but also three new features in addition to these.
First, the Parallel Consumer makes it easy to process messages with a higher level of parallelism than the number of partitions for the input data. The Parallel Consumer also lets you define parallelism in terms of key-level ordering guarantees, rather than the coarser-grained, partition-level parallelism that comes with the Kafka consumer groups. It does this using a thread pool, with the library handling all the tricky bookkeeping required in Kafka. By switching from partition-level parallelism to key-level parallelism, you don’t have to over-provision topic partitions or change the ones you have just so you can scale your consumer group out.
Second, the Parallel Consumer makes it easy for you to call out to other services efficiently without stalling your application. For instance, if you need to look up customer details from a database or while you are processing messages, you can make these requests in parallel via non-blocking I/O.
Finally, the Parallel Consumer provides features for client-side work queues, including message-level acknowledgment and key-based processing. These are great for implementing low-latency task queues, a problem that isn’t well addressed by Apache Kafka today.
In looking at each of these features, we’ll discuss use cases that the library applies to and dive into the major technical themes of its implementation.
Usage example: Massively parallel web service requests
Consider a real-world application that validates the position of trains on a rail network. Around 10,000 trains are active at the same time, all sending their GPS location into a central Kafka cluster. The application has to validate the coordinates of each train by calling a legacy HTTP service. Originally, the system had five consumers in a consumer group working in parallel, but this setup only processes around 1,000 messages per second because each request to the HTTP service takes on average 50 ms to return. What is more, new consumers cannot easily be added to the consumer group as the topic is created with only five partitions. With many other applications consuming this data and expecting guaranteed ordering, changing the partition count isn’t the easiest option.
The Parallel Consumer addresses two issues with this implementation. We can increase the parallelism without increasing the partition count. We can also pipeline the calls to the legacy HTTP service. Both of these ensure that processing in key-order is maintained. The resulting application is up to 2,000 times faster than the initial implementation (assuming the HTTP service can keep up!).
There are many other use cases that can benefit from the Parallel Consumer. These are detailed in the Scenarios section of the README of the main project.
An alternative path to parallelism in Apache Kafka
In Kafka, the topic partition is the unit of parallelism. The more partitions, the higher the processing parallelism. For example, if a topic has 30 partitions, then an application can run up to 30 instances of itself—such as 30 Docker containers—to process the topic’s data collaboratively and in parallel. Each of the 30 instances will get exclusive access to one partition, whose messages it will process sequentially. Any instances beyond 30 will remain idle. Message ordering is also guaranteed by the partition construct—each message will be processed in the order in which it is written to the partition.
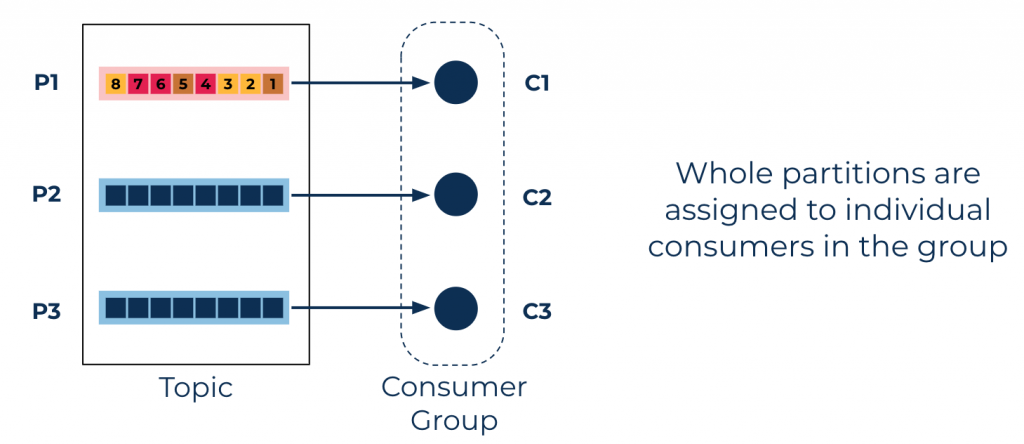 Consumer group partition-level parallelism using the Kafka consumer: Consumer C1 will process all the events in partition P1 sequentially. Consumers C2 and C3 will process partitions P2 and P3, respectively.
Consumer group partition-level parallelism using the Kafka consumer: Consumer C1 will process all the events in partition P1 sequentially. Consumers C2 and C3 will process partitions P2 and P3, respectively.
To further increase the processing parallelism, we can increase a topic’s partition count in place. The downside is that it breaks key-based ordering, as messages with the same key will likely be stored in different partitions before versus after the partition increase. The recommended procedure is therefore to create a new topic with the desired partition count, and copy the original topic’s messages into it. To perform repartitioning automatically, you can use tools like ksqlDB and Kafka Streams.
However, there are situations where this procedure—automated or manual—is not the best choice. In some cases, you might prefer not to duplicate the original topic. And in other cases, you might not be able to assess—through load-testing beforehand or even back-of-the-envelope calculations—how many partitions will be required for a certain use case (e.g., at the time of the first production deployment), even though you might want to do this assessment for every new topic.
The Confluent Parallel Consumer allows you to parallelize processing at three different levels:
- Key-level parallelism: Different threads will process messages from a single partition in parallel while maintaining Kafka’s key-based ordering guarantees.
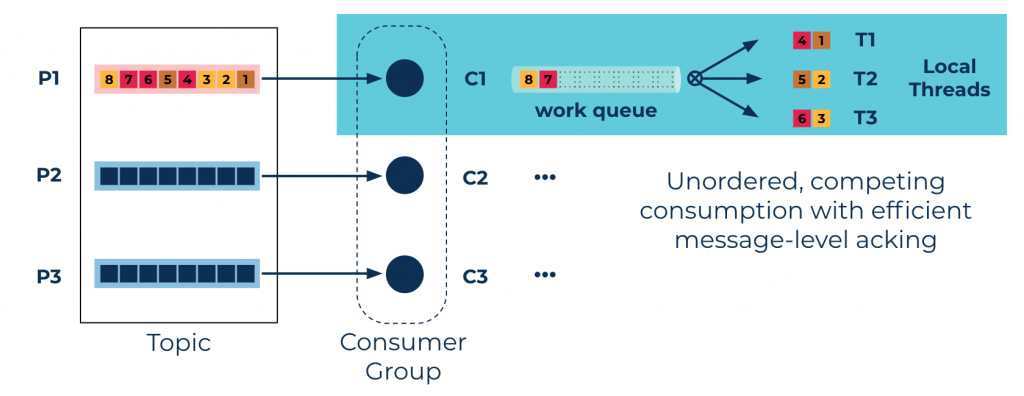
- Unordered parallelism: Different threads will process messages from a single partition in an arbitrary order. The library also includes the ability to commit messages individually to improve failure performance when implementing work queues, competing consumers, and other similar use cases.
- Partition-level parallelism: This provides the same semantics as a regular consumer group, as data in a single partition will always be processed in order. The difference is that the Parallel Consumer can provide these guarantees using fewer resources than an equivalent consumer group (a thread in the Parallel Consumer typically uses less resources than a single Kafka consumer in a consumer group). Say, a 50-partition topic might be processed using five instances of the Parallel Consumer, each running on separate machines (i.e., using Kafka’s consumer group feature where the number of consumers in the group is five). Each instance would process messages using multiple threads giving a total parallelism of 50. This is more efficient than using a consumer group of 50 consumer instances.
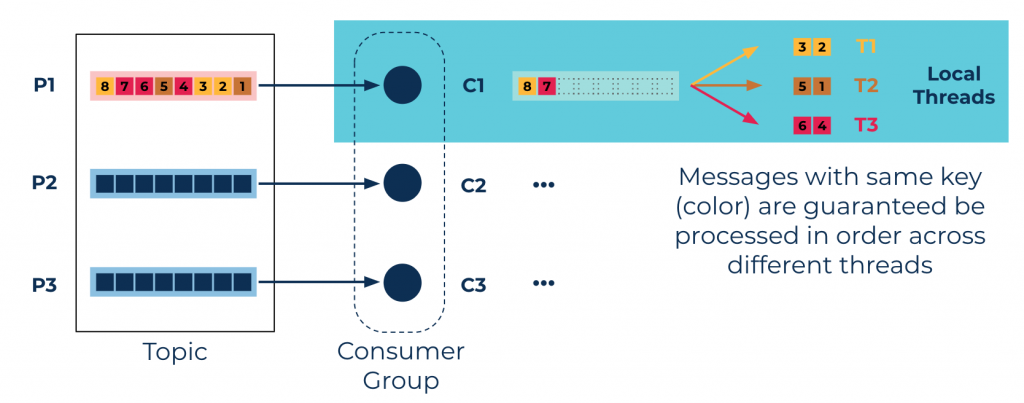 Partition level: key-level parallelism using the Confluent Parallel Consumer
Partition level: key-level parallelism using the Confluent Parallel Consumer
These modes of operation not only increase performance but also address what is referred to as the “slow consumer” scenario. If it takes a long time to process a particular message, then all messages in the same partition will be held up by this slow-to-process message.
Note that many factors can contribute to slow processing, including CPU, I/O, or network bound. Other examples are garbage collection or the slow response of a third-party system, such as a database or web server that you need to interact with. Both key-level parallelism and unordered parallelism help address this problem.
Key-level parallelism (which retains key-level ordering) will satisfy most use cases, in which partition ordering is not necessary. Thus, the Parallel Consumer allows you to take advantage of improved handling of slow consumers as well as a higher degree of parallel processing.
Where ordering is simply not a requirement, the Confluent Parallel Consumer also offers a queueing type of behavior called unordered parallelism, where each offset is tracked individually for completion. This is persisted to the broker so that after failure recovery or partition rebalancing, only messages that have not been completed correctly will be replayed regardless of the actual consumer protocol committed offset.
Each of these modes of operation have different performance profiles. The chart below demonstrates the relationship between partition-level processing in the Apache Kafka consumer versus key-level processing and unordered processing in the Parallel Consumer. Note how as the key space expands, the overall performance improves and approaches the unordered case.
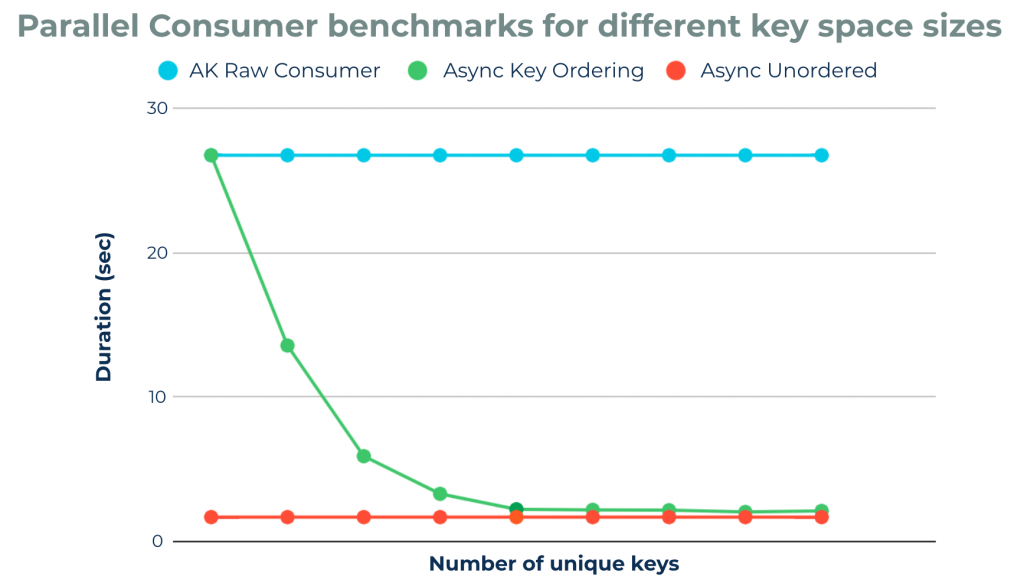 Time taken to process a large number of messages with a single Parallel Consumer versus a single Apache Kafka consumer, for different key space sizes: As the number of unique keys in the data set increases, the key-ordered Parallel Consumer performance starts to approach that of the unordered Parallel Consumer. The raw Kafka consumer performance remains unaffected by the key distribution.
Time taken to process a large number of messages with a single Parallel Consumer versus a single Apache Kafka consumer, for different key space sizes: As the number of unique keys in the data set increases, the key-ordered Parallel Consumer performance starts to approach that of the unordered Parallel Consumer. The raw Kafka consumer performance remains unaffected by the key distribution.
Implementing this type of processing is simple. Here is an example:
var options = ParallelConsumerOptions.builder()
.consumer(kafkaConsumer)
.ordering(KEY)
.maxConcurrency(1000)
.build();
parallelConsumer = createEosStreamProcessor(options);
parallelConsumer.poll(record -> {
log.info("Concurrently processing a record: {}", record);
});
For more usage information, please see the README.
Calling microservices and databases efficiently in message-at-a-time processing
Another benefit of the Confluent Parallel Consumer is that it automatically handles the pipelining of requests to external resources like databases or the REST interfaces exposed in many microservice architectures. An example is shown in the figure below.
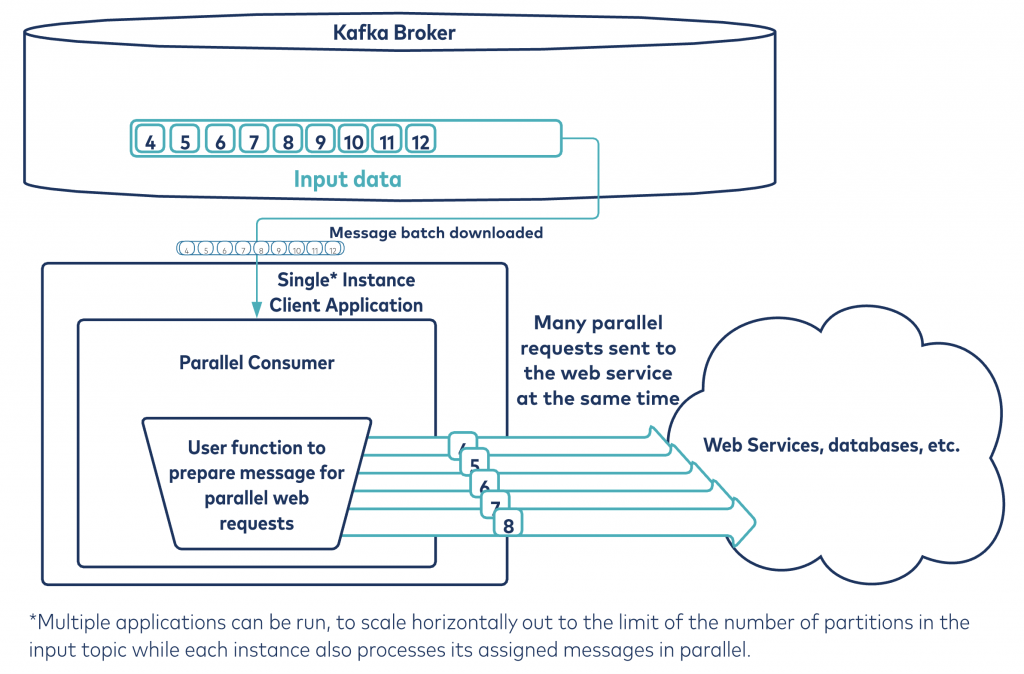
To speed up the message processing system even more, the library includes an optional Vert.x integration extension, which supplies non-blocking interfaces that allow for higher levels of concurrency without being restricted to thread pool sizes.
As an example, you can call an HTTP endpoint for each message by simply returning an object that represents the request. The Vert.x HTTP engine will handle the rest using its non-blocking engine.
var resultStream = parallelConsumer.vertxHttpReqInfoStream(record -> {
Map params = UniMaps.of("recordKey", record.key(), "payload", record.value());
return new RequestInfo("localhost", "/api", params);
});
See many more examples on the project homepage.
Combining the Parallel Consumer with Kafka Streams
Kafka Streams doesn’t yet have an asynchronous processor node option yet (KIP-311 and KIP-408), so its concurrency is still bound to the partition count. However, any given preprocessing can be done in Kafka Streams to prepare the messages. Using the Parallel Consumer, you can consume from the intermediary topic produced by Kafka Streams to post-process the messages in parallel, regardless of the partition count.
For a code example, see the Kafka Streams Concurrent Processing section of the README.
Wrapping Up
Adding parallel processing to a Kafka consumer is not a new idea. It is common to create your own, and other implementations do exist although the Confluent Parallel Consumer is the most comprehensive. It lets you build applications that scale without increasing partition counts, and it provides key-level processing and elements of queuing. We encourage you to clone the repository and try it out in your projects!
Note that this library is experimental, and Confluent does not currently offer support for it at this time. If you have any feature ideas or questions as well, please get in touch, and we will help you work on submitting a PR.
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.