3 Reasons Why Storyblocks Chose Confluent Over Other Apache Kafka Services
Storyblocks is the world’s first stock media subscription service offering video, audio, and images. To support this fast-growing business, the Storyblocks platform produces millions of events every day, ranging from video metadata and encoding events to billing transaction events. Our product managers and analysts leverage this data in real time to power our products and develop critical features, new apps, machine learning models, and dashboards to better understand our customers. Lack of schema validation from cloud provider messaging services was a big pain point for us, along with latency and scalability limitations, so we ended up choosing the de facto standard for event streaming, Apache Kafka®, to enable asynchronous communications and data movement at scale across various services.
Kafka enables us to separate each event into its own topic, making pub/sub and real-time monitoring of specific communication channels extremely easy. In addition to each event having its own topic, we also configured our producers and consumers to publish invalid or failed events to their own topics, letting engineers quickly identify and triage bugs.

Why Confluent?
While Kafka is a powerful technology, we quickly realized it required us to spend valuable time and resources building and managing Kafka components, where we’d be on the hook for integrating various data sources and sinks, scaling and load balancing, ensuring high availability, data governance, and more. We determined that we were not in the business of managing low-level data infrastructure, which is why we decided to go with a fully managed Kafka service instead of managing it ourselves in-house.
During our initial evaluation period, we tried a few different cloud-based Kafka services and eventually chose Confluent. There are three major reasons that we decided on Confluent over other hosted Kafka services.
A complete platform beyond Apache Kafka
Validating schemas was one of our key objectives while using Kafka. During Kafka Summit last year, Confluent launched a full set of data governance capabilities designed specifically for Kafka and streaming data, including Stream Quality, Stream Catalog, and Stream Lineage. We’re excited about this offering because this is a great extension of Schema Registry, which we’re heavy users of today. These features allow us to better manage and govern our schema repository in a more automated fashion and understand potentially complex data flows end to end.
Schema Registry is a key component for our event pipeline because it lets us create a central repository for our platform’s data schema (everything from video metadata to billing events) and build developer-friendly continuous integration. Engineers can make a simple pull request to the schema’s repository and automated checks tell them if their changes would break downstream processes. Best of all, Confluent Cloud provides a fully managed Schema Registry to simplify and automate schema management across all our services without any operational overhead.
Another major differentiator of Confluent is that it provides connectors to over 100 popular sources and sinks, fully supported and ready out of the box.
Storyblocks uses Confluent connectors to import the last month of data in our important event topics to Elasticsearch, giving us a detailed index of recent data. This lets product managers, engineers, analysts, and data scientists easily create real-time dashboards and configure anomaly detection for the events they care about in Kibana with all of the benefits of Elasticsearch. When our sales team needed to export data from a new Salesforce integration, Confluent offered a source connector that gave us a zero-code solution that took less than a day to implement. We also used a sink connector to update Salesforce data based on our own internal events. Confluent’s connectors drastically reduced the engineering time, lines of code, and technical debt for these implementations, offering the greatest selection of connectors compared to any other hosted Kafka vendor in the market.
A truly cloud-native service
Kafka is extremely useful as a tool to create an immutable log of your entire organization’s data. Storyblocks originally implemented this using Kafka Connect and a data lake in Amazon S3, but we were drawn toward Confluent Cloud’s Infinite Storage, which innovatively separates compute and storage in an event streaming platform, to make storing increased amounts of data in Kafka even simpler and more cost-effective.
Our engineers have already benefited from infinite retention on topics because it gave them the ability to “replay” old events into consumers while completely doing away with the time and effort needed to wrangle the original data. Combined with Kafka’s partitioned topics, Confluent’s Infinite Storage literally makes replaying history in your app as simple as pressing a button. Even sweeter, the cloud-native nature of Confluent allows us to only pay for what we use for compute and storage individually, which helps us lower TCO compared to other options in the market.
Besides Infinite Storage, Confluent Cloud also offers many cloud-native features that other hosted Kafka services lack, such as automated Kafka patching with zero downtime, capacity planning and sizing, load balancing, and elastic scaling without the overhead of dealing with ZooKeeper, partitions, and JVMs. All of these features significantly reduce our operational burdens so our engineers can better focus on what really matters to the business.
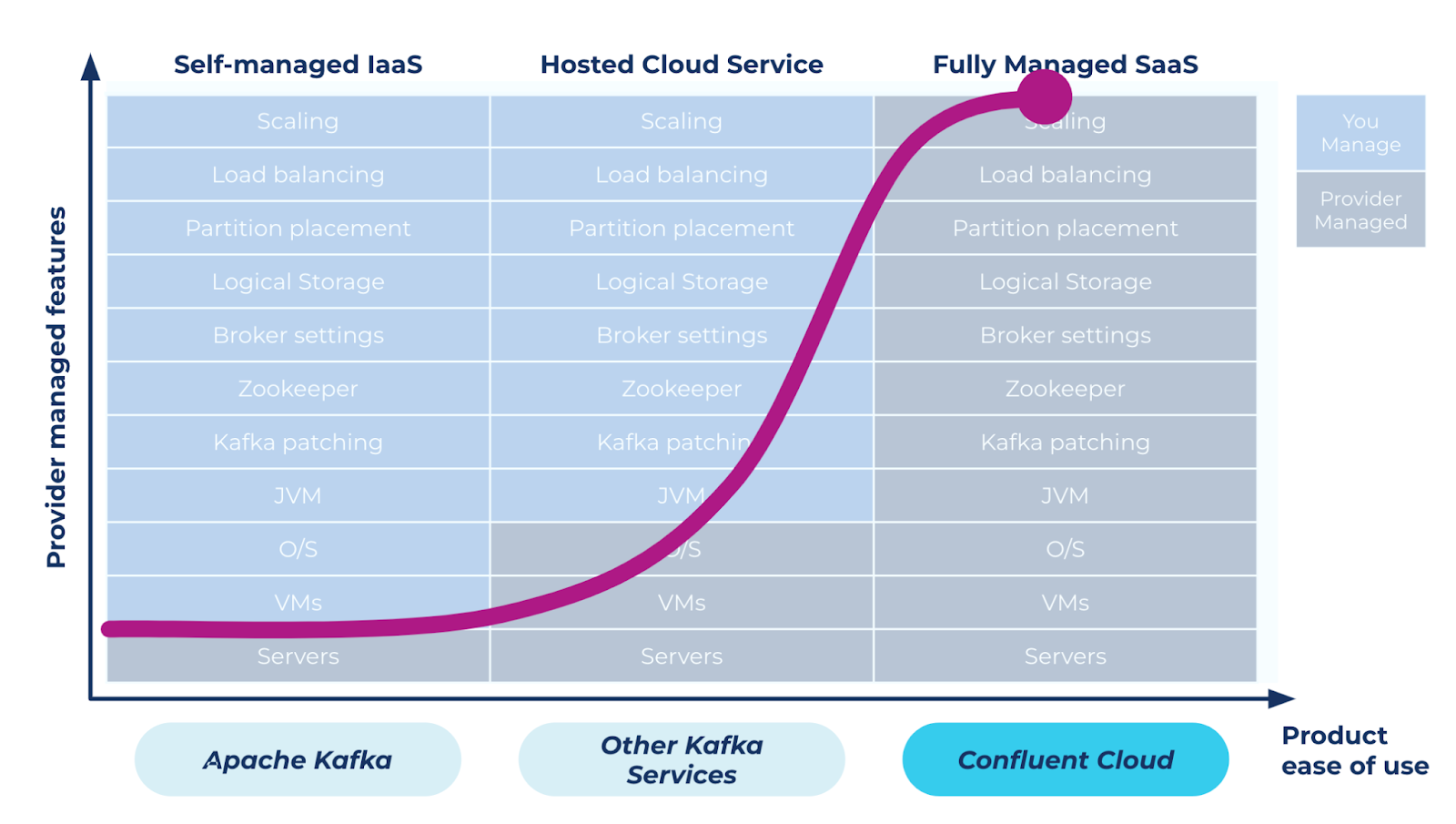
Storyblocks saw significantly reduced Kafka operational burdens with Confluent.
Committer-led support and services
Managing Kafka wasn’t always easy, especially as a fast-growing startup, where we really wanted our engineers to have simple workflows and focus on solving problems that differentiated our business. While there are multiple vendors in the market offering hosted Kafka services, no other company has as much Kafka experience and expertise as Confluent. Founded by the Kafka creators, Confluent has been responsible for more than 80% of Kafka commits, driving the vision and direction of the entire Kafka ecosystem.
Whenever we ran into issues, it was really valuable for us to speak with Kafka technical experts to triage and solve these problems quickly to reduce downtime and disruption. In my experience, Confluent is the only company able to provide the Kafka expertise needed to truly support mission-critical use cases from early stage to large scale. Early in our implementation, we used Apache Spark to stream from all of our topics into our data lake, and while the stream worked correctly, it operated much too slowly. After struggling for a while, we contacted Confluent support for the first time and within an hour a specialist responded with screenshots of our Schema Registry traffic and suggested a fix for our message decoding logic. We have also routinely had questions about Kafka Connect improvements, and Confluent has always been responsive and receptive to tickets/suggestions. This expertise and peace of mind have been invaluable and a major advantage compared to other options we evaluated.
Next steps
We are only just beginning our journey with event-based streaming and communication. Our engineers and data scientists are becoming more familiar with these patterns and are starting to use our event pipelines in everyday tasks. Soon, we want to transform most of our analytics data from batch to streaming so our analysts can easily create live dashboards, and we want to launch dozens of machine learning jobs to stream user events and update the user experience in near real time. Confluent provides a complete, reliable, and cloud-native event streaming platform so that our engineers can focus on continuing to innovate and push these use cases forward.
Check out Confluent’s data streaming resources hub for the latest explainer videos, case studies, and industry reports on data streaming.
If you’re ready to get started with Confluent Cloud, sign up for a free trial and use the code CL60BLOG for an additional $60 of free usage.*
このブログ記事は気に入りましたか?今すぐ共有
Confluent ブログの登録


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.