Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Schema Validation with Confluent Platform 5.4
Robust data governance support through Schema Validation on write is now supported in Confluent Platform 5.4. Schema Validation enables the broker to verify that data produced to an Apache Kafka® topic is using a valid schema ID in Confluent Schema Registry that is registered according to the subject naming strategy. Enforcing data correctness on write is the first step towards enabling centralized policy enforcement and data governance within your event streaming platform.
Why centralized data governance is important
Data governance ensures that an organization’s data assets are formally and properly managed throughout the enterprise to secure accountability and transferability: different teams and projects within the organization can collaborate on the same contract of how data is generated, transmitted, and interpreted. Once an architectural luxury, data governance has become a necessity for the modern enterprise across the entire stack. It represents a mature set of well-established data management disciplines from the database world, but with event streaming systems, it takes on some new nuances:
- Any application or other producer sending new messages to the event streaming platform can “speak one language” that all others can understand at any time
- New types of messages conform to organizational policies, such as a prohibition on personally identifiable information (PII)
- All clients connecting to the cluster use recent (and efficient) protocol versions to avoid extra costs for protocol upgrade/downgrade at the server side
It is important to enforce data governance policies in a single place. The best place is inside the event streaming platform itself, so that we don’t have to audit each client to make sure their application code has respected all the rules. In a large organization with lots of teams and products all leveraging the platform to build their real-time business logic, trying to enforce such data governance policies is extremely difficult.
Take schemas as an example. Today, nearly everyone uses standard data formats like Avro, JSON, and Protobuf to define how they will communicate information between services within an organization, either synchronously through RPC calls or asynchronously through Kafka messages.
For Kafka, all producers and consumers are required to agree on those data schemas to serialize and deserialize messages. In practice, a schema registry service such as the Confluent Schema Registry is used to manage all the schemas associated with the Kafka topics, and all clients talk to this service to register and fetch schemas. Using a schema registry service makes it easier to enforce agreements between clients while ensuring data compatibility and preventing data corruption.
However, these schemas are only enforced as “agreement” between the clients and are totally agnostic to brokers, which still see all messages as entirely untyped byte arrays. In other words, we cannot prevent unformatted data from being published to and stored in Kafka servers. Today, there is no programmatic way of enforcing that producers talk to a schema registry service to serialize their data according to the defined schema before sending them to Kafka.
Although the schema contracts between clients can at least prevent consumers from returning unformatted messages to users, a mature data governance mechanism requires that we enforce schema validation on the broker itself.
Schema Validation: How hard is it?
To allow Schema Validation on write, Confluent Server must be schema aware.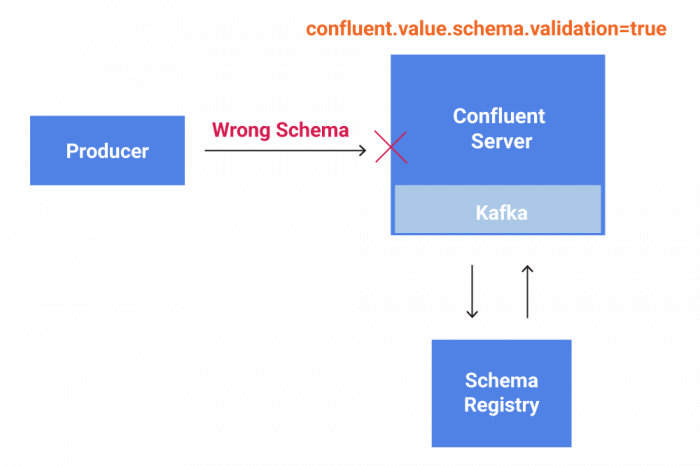
Confluent Server is a component of the Confluent Platform that includes Kafka and additional cloud-native and enterprise-level features. Confluent Server is fully compatible with Kafka, and users can migrate in place between Confluent Server and Kafka.
For Confluent Server to become schema aware, the broker has had to develop a direct interface to the Confluent Schema Registry, just like schema-managing clients have always done. We need to watch out for potentially significant overhead, as we are required to validate schema on a message-by-message basis.
The first step to checking every message’s schema is to add the confluent.schema.registry.url configuration parameter at the broker level—similar to what has been in use on the client side—to let brokers find the Confluent Schema Registry servers and fetch schemas from them. Then we allow users to turn on Schema Validation at the topic level with confluent.key.schema.validation and confluent.value.schema.validation. Setting these configurations to “true” indicates that schema IDs encoded in the keys and values of messages inbound to this Kafka topic will be validated against the Schema Registry service. We also extended the producer protocol to allow brokers to indicate which messages within the batch are rejected for schema validation reasons. Now when a producer gets an error indication in the producer response, the invalid messages will be dropped from the batch, and the callback indicates the error. For more details, please feel free to read KIP-467.
Get started in five minutes
To enable Schema Validation, set confluent.schema.registry.url in your server.properties file.
For example:
confluent.schema.registry.url=http://schema-registry:8081
By default, Confluent Server uses the TopicNameStrategy to map topics with schemas in Schema Registry. This can be changed for both the key and value fields via confluent.key.subject.name.strategy and confluent.value.subject.name.strategy within the broker properties.
To enable Schema Validation on a topic, set confluent.value.schema.validation=true and confluent.key.schema.validation=true. Value schema and key Schema Validation are independent of each other; you can enable either or both.
For example, this command creates a topic called test-validation-true with Schema Validation enabled on the value schema:
kafka-topics --create --bootstrap-server localhost:9092 --replication-factor 1 \ --partitions 1 --topic movies \ --config confluent.value.schema.validation=true
That’s it! If a message is produced to the topic movies that doesn’t have a valid schema registered in the Schema Registry, the client will receive an error back from the broker.
Conclusion
Schema Validation lays the foundation for data governance in Confluent Platform. With just one server configuration parameter, a Confluent Platform operator can now have better control over the data being written to the system down to the topic level. This is just the beginning of a series of data governance features to come.
For more information, see the Confluent Platform 5.4 documentation.
This work could not be done without my colleagues Tu Tran, Robert Yokota, Addison Huddy, and Tushar Thole.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.