Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Accelerate Cloud Database Modernizations and Migrations with Confluent
There is unprecedented growth in the volumes of data being generated by businesses today. Regardless of your industry, better data and data management translates into more informed, strategic decision making. It is now essential for enterprises to be able to contextualize and harness their data to have real-time insights into how their business is performing, enabling data teams to quickly make operational decisions in response to market conditions from anywhere, at any time.
Databases are at the core of every enterprise’s day-to-day operations, making them more challenging to move to the cloud without careful planning and execution. Today’s organizations need a modern, cloud-native database strategy that includes data in motion to enrich operations to be increasingly agile, elastic, and cost efficient, at scale as they develop cloud applications.
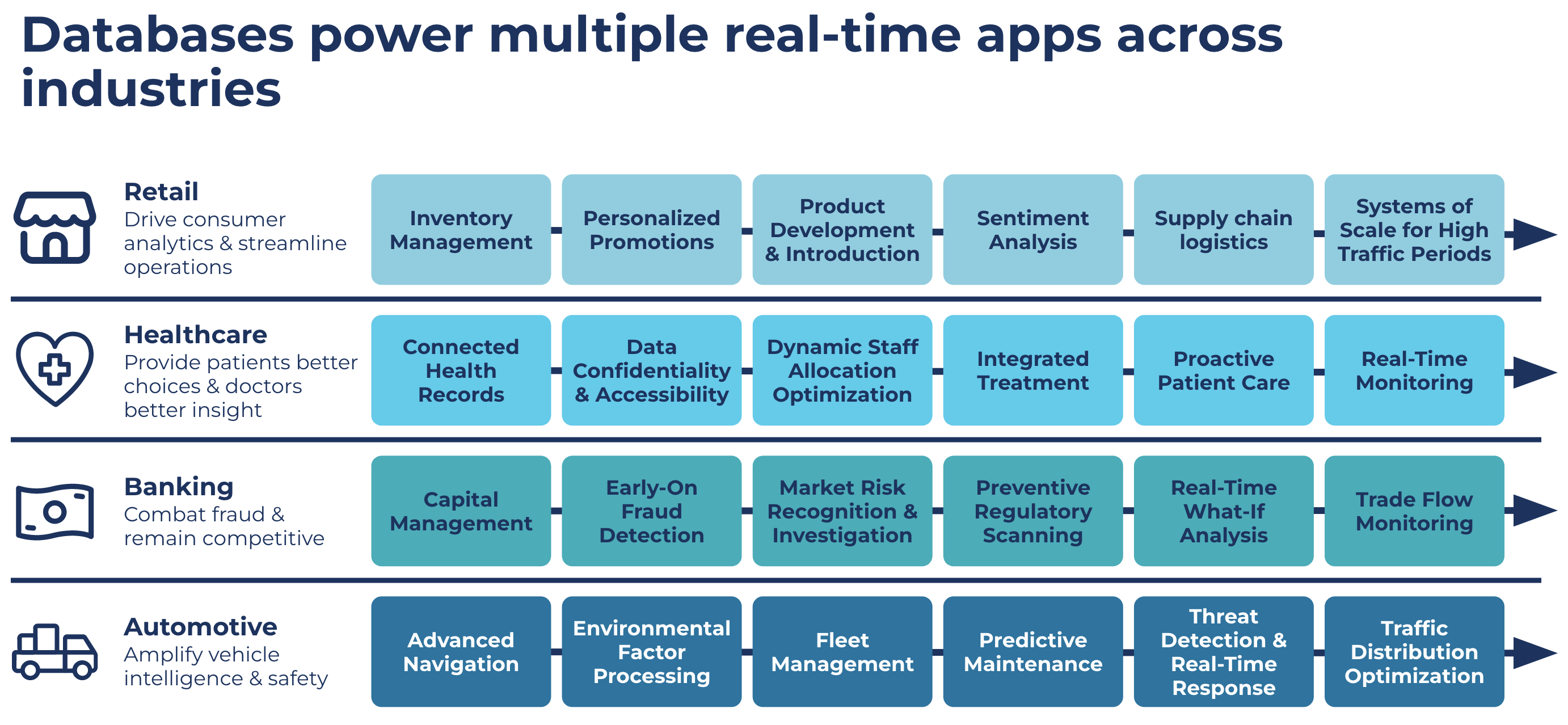
Furthermore, Gartner predicts that by 2023, 75% of all databases will be on a cloud platform with a market that has grown from $38.6B in 2017 to $80B in 2021. However, migrating to cloud-based databases is challenging and complex. Challenges often include patchy integrations and big downtime windows that create strains in the business and are based on batch processing with long latencies. Current migration offerings lock data to a single provider and favor first-party services that may not be the best option for your business.
As organizations rethink their database strategy, they also have an opportunity to rethink how they build data pipelines. Confluent’s data streaming platform eliminates the need for point-to-point connections and provides a singular, global, and real-time data plane instead. This enables you to unlock valuable data from the systems, applications, and data stores that run across any number of global environments and stream that data in real time to your cloud database. Enterprises like Homepoint, Amway, and Rodan + Fields have all partnered with Confluent and their cloud providers to tackle this challenge head-on.
Modernize to your cloud database of choice seamlessly and cost efficiently
Many companies want to work across multiple cloud platforms to avoid vendor lock-in and to take advantage of the best-of-breed capabilities suited for their business. This often means connecting real-time data pipelines across multiple cloud and hybrid environments.
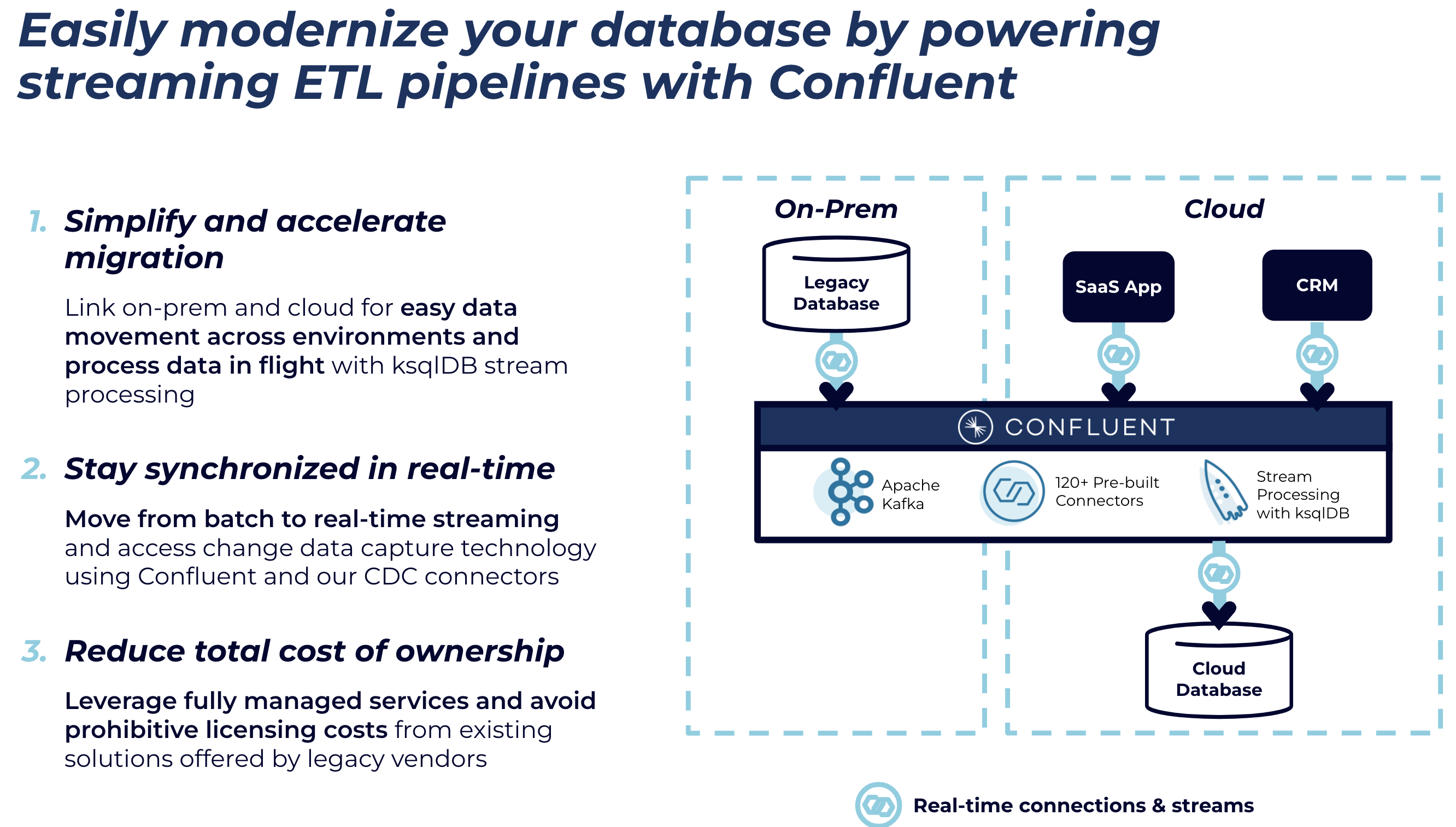
Organizations need a stepping stone as they migrate and modernize their cloud-based database. Specifically, they need a platform for data movement that delivers both familiarity and portability, while helping them drive real-time event streaming and ETL pipelines into databases across any environment (cloud or on prem).
Traditional self-managed databases are difficult to manage at scale. You need to consider computing resources, storage capacity, patching the underlying infrastructure, and patching the database itself. Integrating with other systems is non-trivial and scaling is slow at best. However, migrating your on-prem database or connecting databases across clouds to unlock innovation doesn’t need to be a complex and multi-year effort. Confluent helps accelerate database modernization initiatives by allowing enterprises to move to the cloud by connecting multicloud and hybrid data to the cloud database of their choice in real time. Organizations using Confluent services can significantly reduce the complexity and cost associated with building real-time applications in the cloud using the database of their choice. Combining Confluent with your database helps you:
- Link on prem and cloud systems for easy data movement across environments and process data in flight with ksqlDB stream processing
- Move from batch to real-time streaming and access change data capture (CDC) technology using Confluent and our CDC connectors
- Leverage fully managed services and avoid prohibitive licensing costs from existing solutions offered by legacy vendors
See our solution in action with MongoDB in this demo and learn how to build a persistent pipeline for continuous migration from a legacy database to a modern, cloud database through the use of Confluent, connectors, and ksqlDB!
Simplify and accelerate migration
For open source Apache Kafka® and Confluent Platform users, Confluent’s Cluster Linking technology allows you to reach into on-premises Kafka clusters from Confluent Cloud and create an easy-to-use bridge to bring data into Confluent Cloud in your cloud service provider. You set up security and networking once and reuse this persistent bridge every time you want to move data across environments.
Moving your database and your Kafka to the cloud will help you reduce the TCO of your entire data platform and allow you to build faster at scale. Go above and beyond Kafka to build real-time apps quickly, reliably, and securely with pre-built and fully managed connectors, stream governance, stream processing powered by ksqlDB, built-in management & monitoring, and enterprise-grade security. With Confluent, businesses reduce total cost of ownership (TCO) by 60% and increase speed to market by up to 75% with Confluent Cloud compared to open source Kafka.
By moving to real-time streaming and pulling data from any environment across cloud and on prem, businesses can provide application teams with the data they need faster and deliver new features and capabilities to customers at scale.
Stay synchronized in real-time with Confluent’s CDC connectors
Confluent offers five pre-built, fully managed CDC connectors for Oracle, Microsoft SQL Server, MySQL, PostgreSQL, and Salesforce. Highly suitable for database modernization efforts by allowing the source database to stay online and operating throughout the migration. These connectors identify and capture changes made in a database in real-time, in contrast with batch-based approaches (i.e. polling intervals). Changes including inserts, updates, and deletes are captured in transaction logs, from which the CDC connector reads and writes into Kafka topics. This unlocks high-value data in a cost-effective, easy, and reliable way to stream real-time changes from, for example, your Oracle databases to modern, cloud-based systems without the operational overhead and management complexity.
Reduce your total cost of ownership
Choosing a cloud-first approach opens up additional challenges that must be considered. Migrations can be expensive, time-consuming, and risky. Timelines can drag on and scope regularly increases, leaving customers frustrated. It can take months to transfer all of your accrued data via appliances or one-off systems. Constraints like compute power or transfer bandwidth are hard to bypass. Companies must be able to identify and coordinate interdependencies between multiple applications and teams, while not losing data integrity.
Forrester identified TCO savings of nearly $2.58 million for businesses that used Confluent instead of self-supporting open source Kafka in-house. Their research included interviewing multiple customers with experience using Confluent, understanding their costs and challenges with managing open source Kafka on their own, and then aggregating their experiences and benefits to determine the true value that Confluent can help organizations realize.

Source: The Total Economic Impact™ of Confluent Cloud, a Forrester Total Economic Impact™ survey commissioned by Confluent
Database data is not just for databases anymore. Confluent enables companies to quickly connect new data sources to their database with our rich ecosystem of 120+ connectors for faster development. With Confluent sink connectors, enterprises can take the same data powering their database and send it to additional analytics applications no matter what cloud or environment they live in.
Get started on the cloud database of your choice!
Confluent’s database modernization solution works with any cloud database. Building upon your existing Confluent or open source Kafka footprint, Confluent can help you migrate (and pre-consolidate) your data from any on-prem data store and move it into your new cloud-based database. Additionally, by migrating to a cloud-hosted system, organizations can decrease TCO by lowering operating costs and increasing agility through native integrations and modern features.
Choose one of the following to see how this works on your cloud provider.
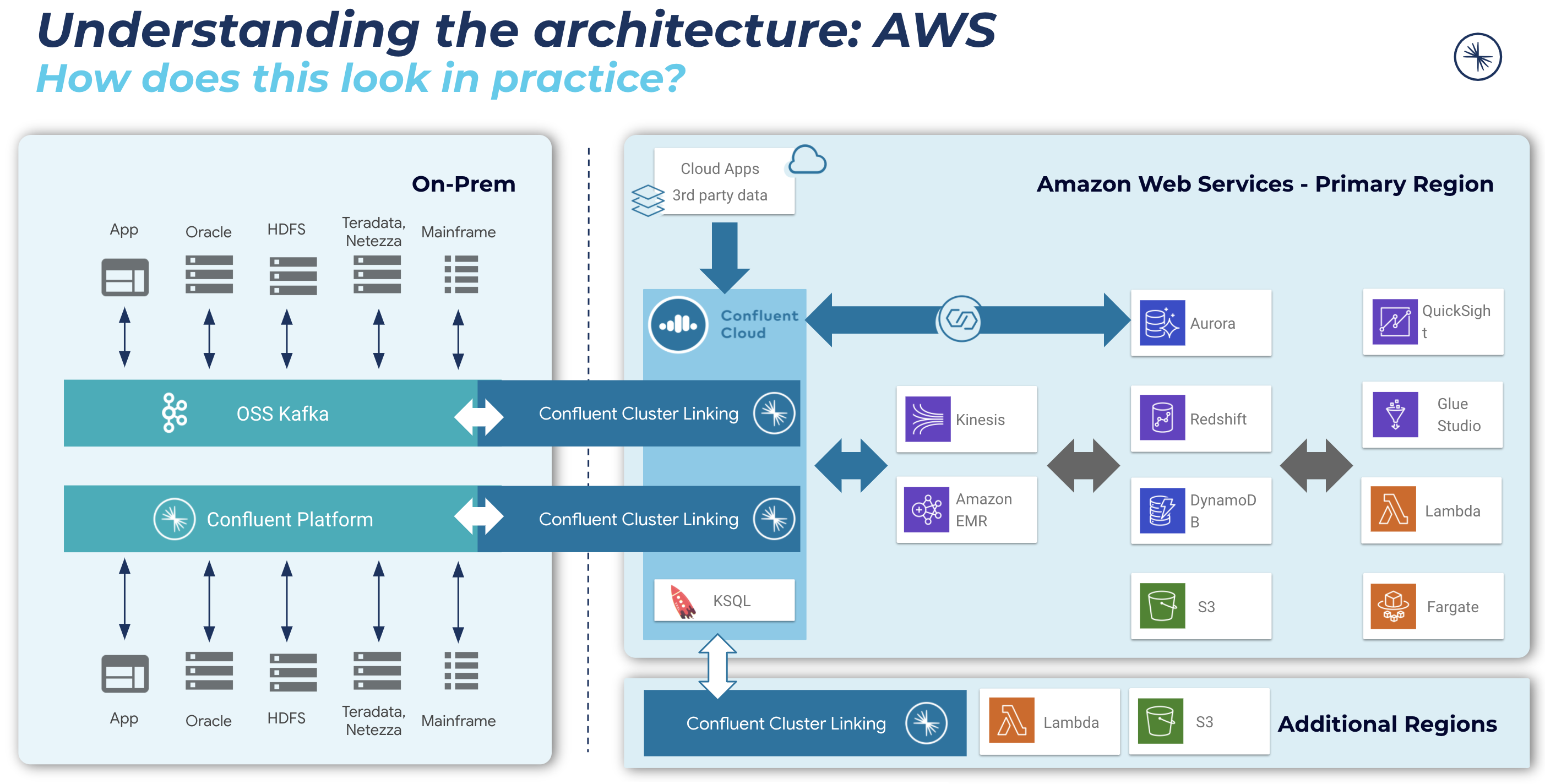
Amazon Aurora
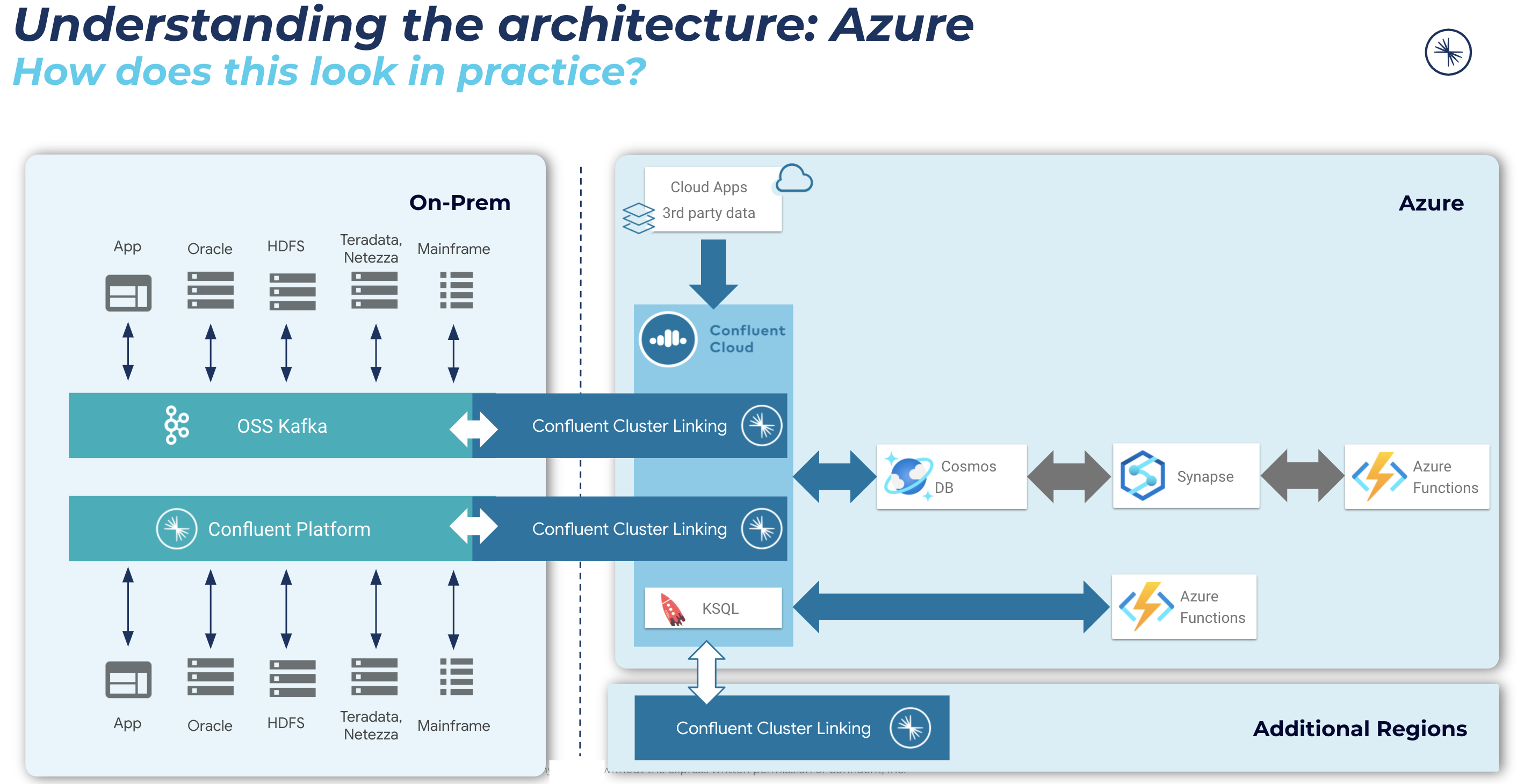
Microsoft Cosmos DB
Google Cloud SQL
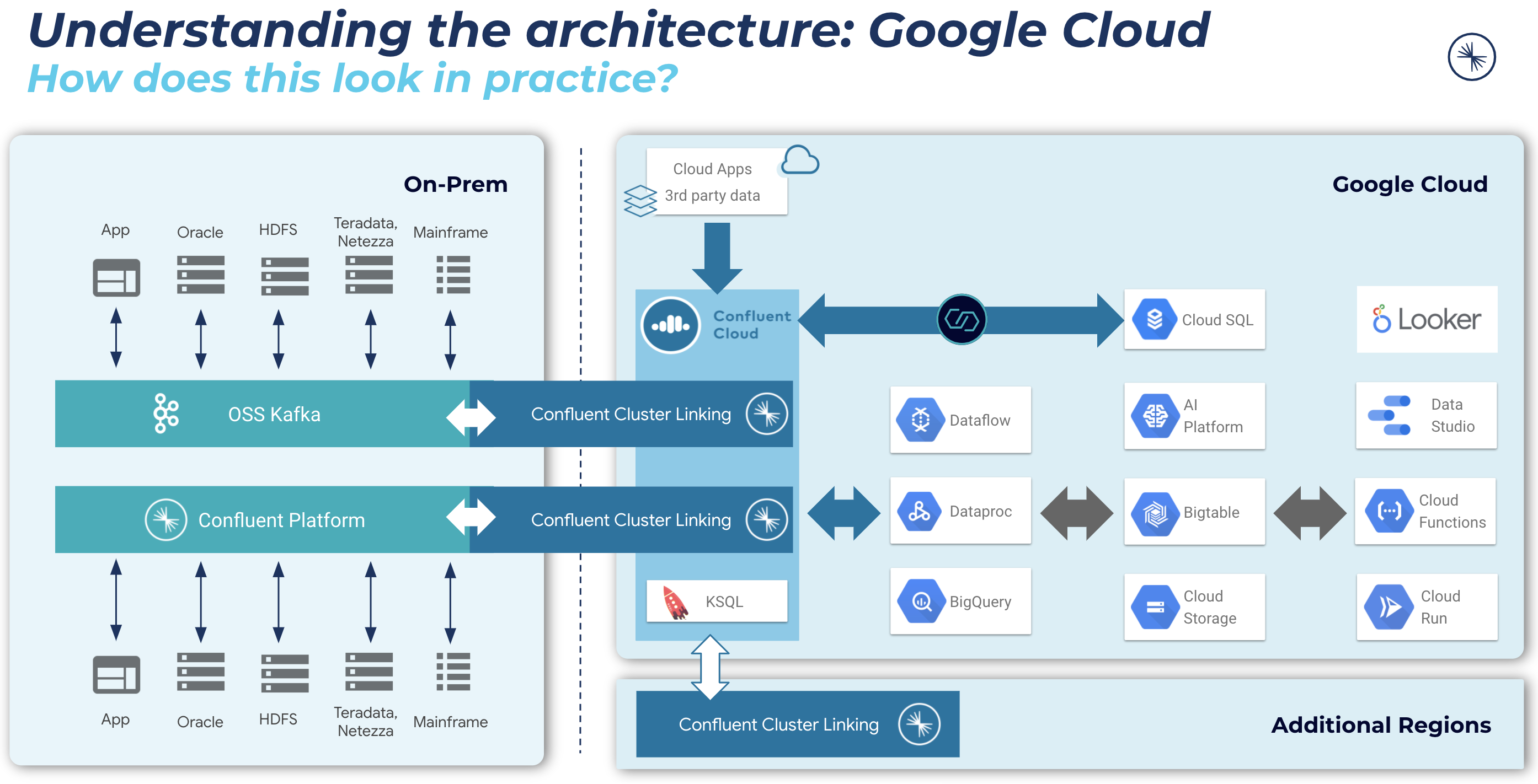
Next steps – Supporting your journey to the cloud, no matter where you are
Migrate and connect data from anywhere (on prem, multicloud) to the cloud database of your choice and seamlessly link everything all together in real-time to create a consistent data layer across your business.
With Confluent, enterprises can use our cloud native Apache Kafka service to significantly reduce the complexity and cost associated with building real-time applications in the cloud using the database of your choice. To jump-start your journey please check out the resources below:
- Solutions page: Database Modernization Solutions Page
- Solution Brief: Database Modernization
- Demo: Modernize your Cloud Database
- Try the demo yourself and go to our Github repository
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.