Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
8 Years of Event Streaming with Apache Kafka
Since I first started using Apache Kafka® eight years ago, I went from being a student who had just heard about event streaming to contributing to the transformational, company-wide event streaming journey underway at Ricardo—the largest online marketplace in Switzerland with over 4 million members. This blog post highlights how far event streaming has come and the event streaming path that has led me to this discovery.
2012: First steps with Kafka
In 2012, I started my first job at a mobile-gaming company on the business intelligence (BI) team, where I was responsible for helping to ensure that the company’s data loading processes were up and running 24×7 so that we could reliably capture usage statistics from the many people playing our games. This meant being on call, often at night, ready to fix any issues with the flow of data.
To make sense of the data, it first had to be inserted into a database. That insertion process could break for any number of reasons. For example, if the schema was not properly updated when it should have been, then we would see database errors. In such cases, because the incoming flow of data from mobile games never ceased, we risked losing data unless we were caching it while we worked to resolve the issue.
In Kafka – Bringing Reliable Stream Processing to a Cold, Dark World, Jakob Homan talks about producers and consumers, with a broker between them. This concept was new at the time, but we saw that it could be used to address some of the issues we were having. If, for example, we had too much data flowing in, we could add more consumers to keep up with the increased load while the broker provided persistence to ensure that data was not lost.
Soon, Kafka had become a core technology for our team, even though—at version 0.6—it lacked many of the bells and whistles we’ve since come to expect from Kafka distributions today.
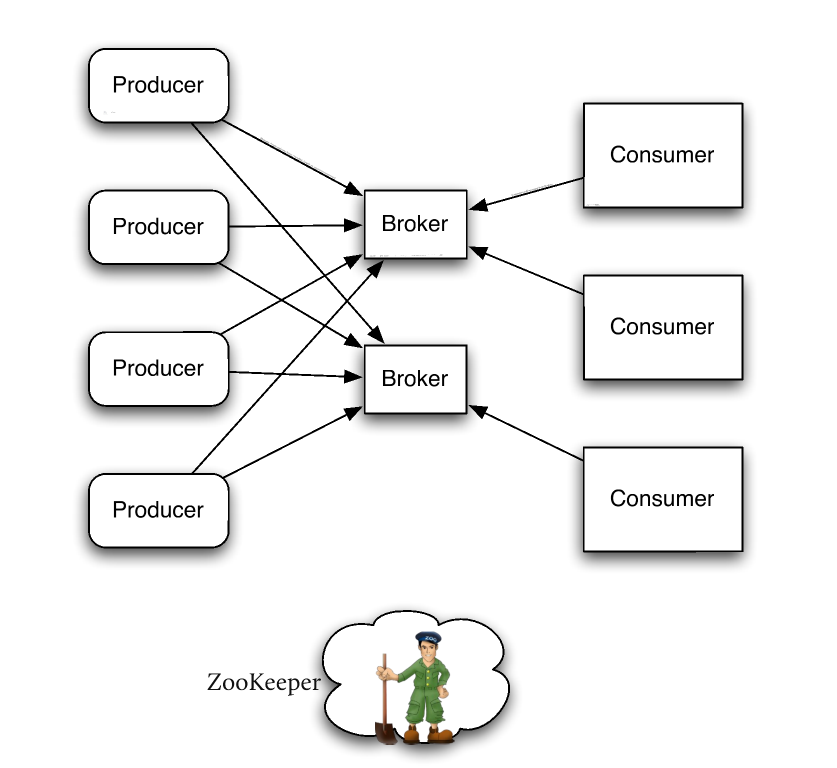
Source: Bringing Reliable Stream Processing to a Cold, Dark World
2014: Building automation for early streaming use cases
Two years later, Kafka was still relatively young. As a result, many of the features that you get for free today had to be built from scratch.
Tracking and managing offsets is a good example. Imagine a scenario in which an error occurs in the pipeline. At 11:00 p.m., in this example, the error prevents consumers from inserting records into the database. In the morning when we came in, someone had to manually calculate the Kafka file offset that corresponded to 11:00 p.m. in order to reset the consumer to resume processing from that point once the database error had been resolved.
To help automate this process, one engineer developed a tool that monitored all of our consumers and their offsets so that we could map offsets to a specific timestamp. A second tool was developed that could quickly find the offset in a topic given the timestamp. While these may seem like rudimentary capabilities now, it was revolutionary at the time.
The company was providing games for over 50 million monthly active users. It’s a bit surprising to think of it now, but we were running on a single Kafka broker. Because Kafka 0.6 didn’t have support for clusters, we were running a single instance of Kafka on one machine. Even so, when we added a new columnar database to our architecture, we were able to build a high-performance custom consumer capable of pulling data from Kafka and pushing it to the database, fully saturating the 1 Gbps uplink that we had set up.
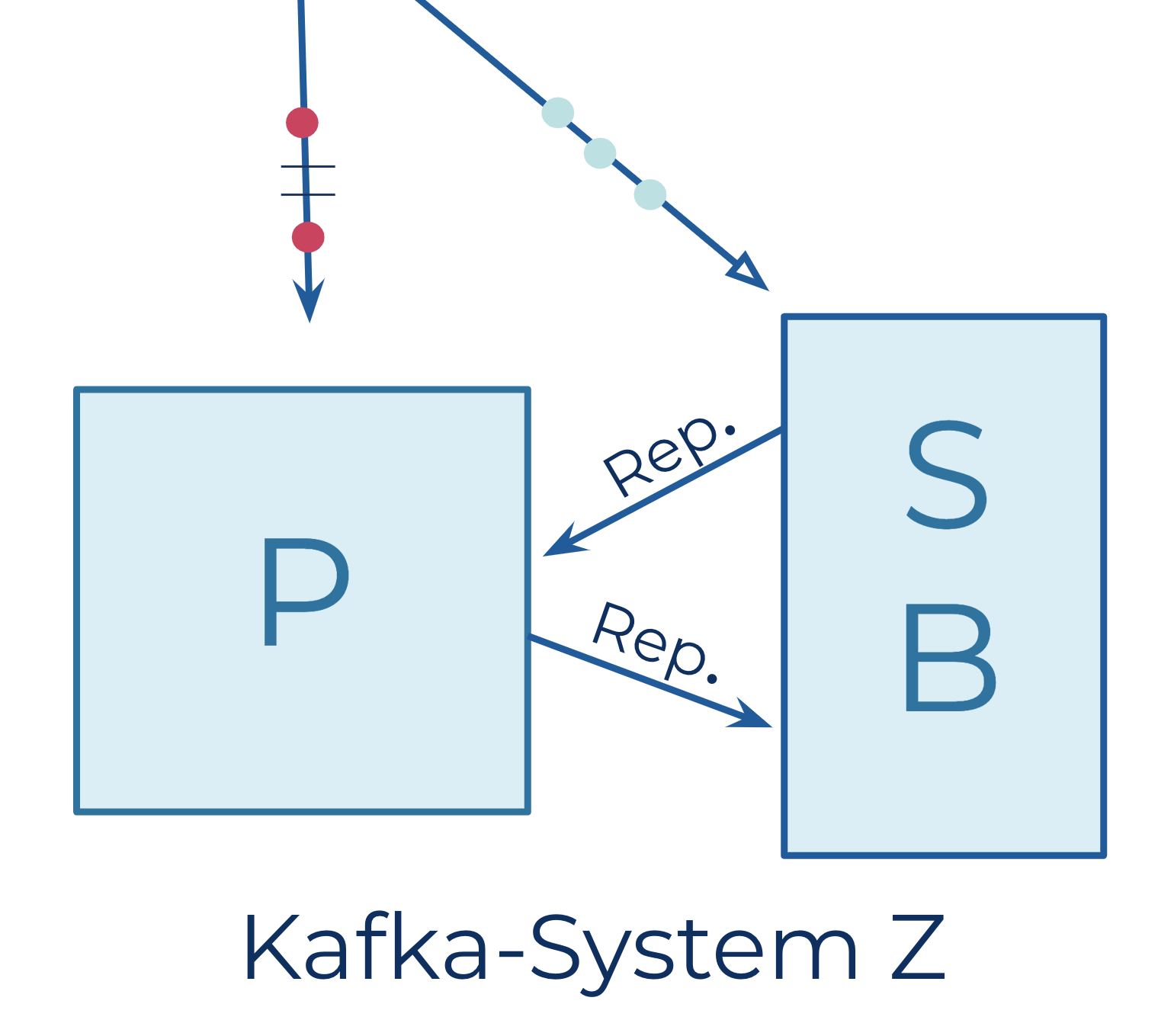
You may be wondering how we could sleep at night if we had just one broker running business-critical operations. We didn’t sleep all that restfully until we built a failover system that we named System Z. For this system, two engineers built homegrown replicators that consumed from one Kafka instance and produced into another instance. We used this technology to replicate from our primary instance (P) to our backup instance (B). If the primary instance went down, we could then route the data flow to a standby secondary instance (S). We could then consume new data from the secondary instance and existing data from the backup until the primary was repaired.
As you can imagine, a lot of complex code had to be written to make this work well. Nowadays you don’t have to write your own replicator—even if you want to replicate across datacenters—and Kafka has many more built-in capabilities that support failover and disaster recovery.
2016: From batch to event streaming (data at rest to data in motion)
In 2016, I switched jobs, where a commonly encountered use case was synchronizing data from one system to another: from one machine to another machine, from one database to another database, or from an on-premises system to the cloud. Often, these use cases involved batch jobs—managed via Cron, Jenkins, or some similar mechanism—in which data was exported from the original system to JSON or CSV and then imported into the target system.
There are some well-known drawbacks to batch processing. First, batch processes tend to be point to point. If you build a batch process to get data from A to B, but later find out that C needs the data as well, then you’ll likely have to build another process from the ground up. This can lead to data silos, as the first team usually just builds processes that serve their own original use case, and expanding these processes requires knowledge that the second team does not have. When the second team then tries to reuse the data, it might need some additional data and only a subset of the original export from the first one. After several circles of this, teams decide to just build and maintain their own processes and silos.
Second, the frequency of the batch runs is always an issue. If you run the batch process every 24 hours, then the business is operating, in effect, on data that’s a day old. And from an operations perspective, problems with batch processes aren’t detected right away. If you introduce a schema error on Friday, then on Saturday when the problems start, the on-call team is going to have to come in to fix the issue.
Event streaming, however, can address these challenges. Instead of trying to increase the batch frequency, from once each day, to twice, to 24 times, we could use event streams to move the data in near real time. Once we had produced a topic to get data from A to B, other departments could begin consuming from that topic immediately.
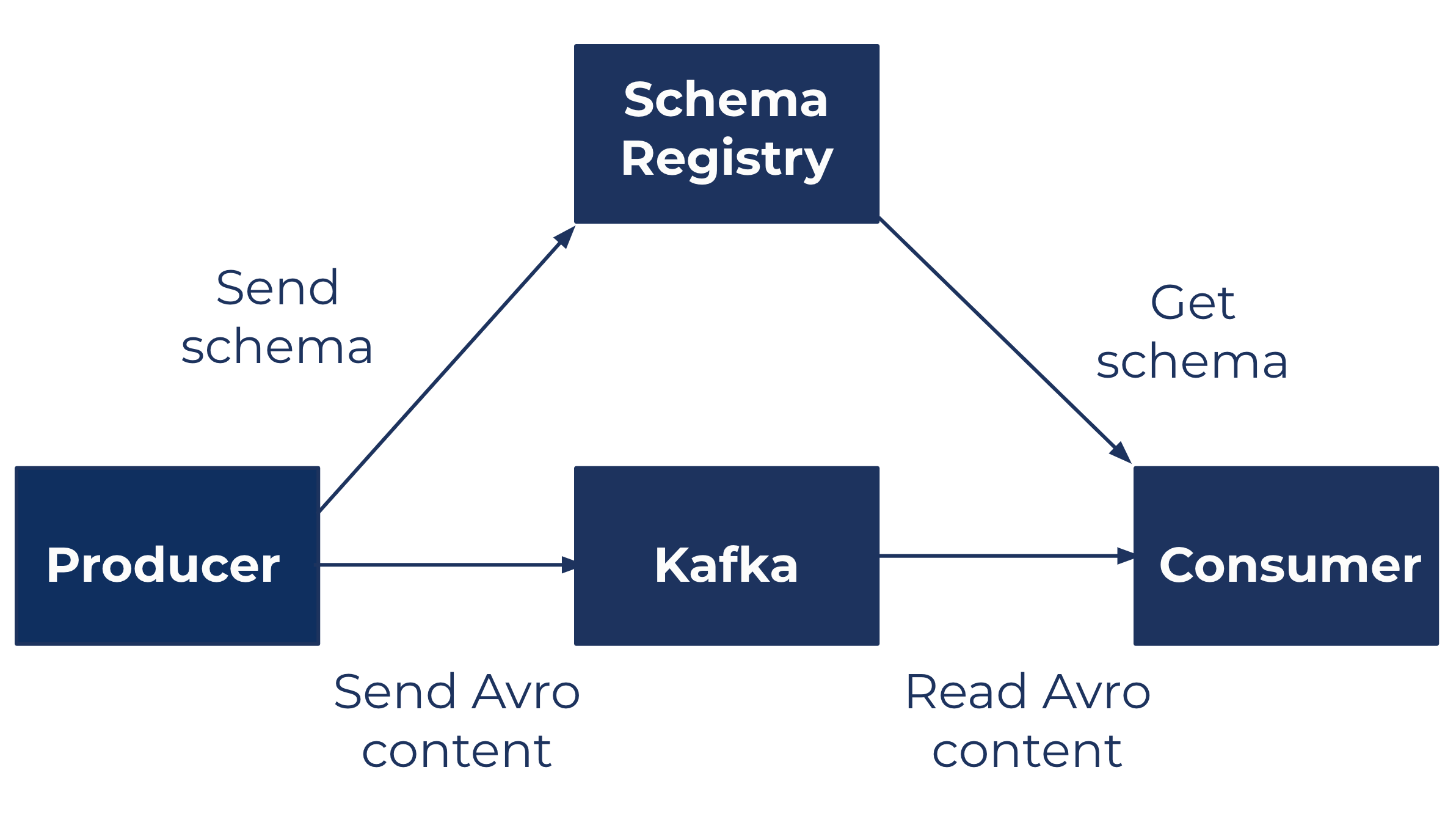
I continued to read up on the latest Kafka developments and came across this introduction to schemas by Stéphane Maarek, which introduced us to the Confluent Schema Registry. Schema Registry solves one of the other big challenges of synchronizing data between systems: ensuring consistency between the source schema and the destination schema.
2018: Data intelligence at Ricardo
At Ricardo, we embarked on our own event streaming journey just the year before I joined the data intelligence (DI) team. The engineering team was using Kafka Connect to ingest data from a SQL Server database into Kafka. They were using Java and Golang to write producers and consumers, and they had begun writing production stream processing applications using the Kafka Streams API.
The teams within Ricardo that had started using Kafka were focused on their own specific use cases. For example, the team responsible for auction transactions had a topic that handled just that information. Our DI team, however, needed a much broader view. When the CEO asks us how many items are in auction, how many have sold in the past 24 hours, how many customers have outstanding fees, and so on, we need information from all of the teams.
To obtain this information, we had to communicate with multiple teams, which required certain standards. We came up with the concept of envelopes to address this need. An envelope has a timestamp that lets you see when it was accepted into the system and includes routing information that enables sorting and filtering without having to see the contents of the envelope. By comparing the timestamp on the envelope with the time in which the event occurred, we can also measure the lag in our system.
Once we had settled on the envelope concept, we needed to agree upon a serialization standard. We chose a combination of Protobuf and JSON. The Java and Golang implementations of Protobuf made it a good choice for us, and we chose JSON so that the data would be human readable. When you are investigating a bug (using a tool like kafkacat, for example), a human-readable format is much easier to work with. Yes, there are tools that you can use when working with a binary format, but as long as performance is not an issue, we recommend starting with JSON. Making it work, making it easy to understand, and making it easy to debug is the primary consideration; you can always switch to binary serialization later.
2019: Moving to the cloud
Once we made the decision to transition to the cloud in 2019, we canceled our contract with the datacenter. At that point, there was no going back; there would be no half-migration. Everyone at Ricardo was aware that we would be in the cloud by the target date, no excuses. For the DI team, that meant moving our data warehouse, which was running in the datacenter, as well as our batch-based import processes.
We were already using Kafka for on-prem event streaming, which made the move to the cloud easier, especially given that our company had help from Confluent engineers. With the support that we received from Confluent and our cloud provider, moving our on-prem Kafka deployment to Confluent Cloud went well, as did the overall cloud migration. We met our aggressive deadline with no machines left behind. In fact, we were able to sell off our remaining datacenter hardware, auctioning much of it on our own site.
Confluent Cloud gives us peace of mind as the operation is handled by the original people who wrote the software itself. We have visibility into our cluster through monitoring and dashboards, but we don’t have to think about backup strategies. Plus, we can benefit from the newest innovations, while never having to deal with upgrading it.
Final thoughts
Since moving to the cloud, the DI team at Ricardo has been implementing new event streaming pipelines with Google BigQuery, as well as a framework for batch and stream processing pipelines and a stream processing technology. We just released a solution to production that joins two large streams, while accessing a key-value store, to avoid having to perform the join in BigQuery, where it would be more costly.

One of the greatest advantages of Kafka is that it’s open source and backed by Confluent, a company founded by the original co-creators of Kafka. Because Kafka is open source, chances are that for any system you want connected to it, there is already a tool or library that you can use. Just like English enables many of us to talk with each other, Kafka makes it possible for our systems to communicate with different systems. It’s true that JSON does that in the batch model too, but Kafka adds all the advantages of event streaming.
It’s important to keep questioning old patterns and looking for better ones, keep learning, and keep sharing what you’ve learned to contribute back to our vibrant Kafka community.
If you’d like to learn more about event streaming at Ricardo, check out my talk from Confluent Streaming Event 2020.





