Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
Creating Positive Behavioral Changes at Scale with Confluent and ksqlDB at Omada
At Omada, we change mindsets to change health by partnering with our care teams to discover the behavior change techniques that lead to optimal care pathways for members across our diabetes, diabetes prevention, hypertension, and musculoskeletal programs. Our data-driven integrated virtual clinic is run by humans, for humans, and we’re always looking for ways to improve how we treat people through continuous learning and innovation.
To help ensure our health coaches are sharing their full knowledge gained from their interactions with members, we created an internal decision support system called Coach Plays. We chose Confluent and ksqlDB to power this system because we needed to be able to drive real-time decisions from real-time events in the member journey, to contextualize moments in the member journey, and to guide our health coaches to promote behavior and mindset changes at scale.
The Coach Plays system
At Omada, our health coaches start by developing deep rapport with their members to bring unconscious behavioral patterns into conscious states of awareness. We call these “Moments.” Our Coach Plays system surfaces these moments such as spikes in blood glucose levels from our integrated continuous glucose monitoring devices and changes in dietary habits for our coaches to use to help members turn awareness of the moment into understanding and action.
Each Coach Play has three parts:
- Moment: An action that the member has taken (or not taken), such as eating the same breakfast every day of the week, that gets surfaced to the coach
- Intervention: The coach’s recommended behavioral change for the member in response to this particular moment
- Outcome: The change in member health that is tied to the intervention
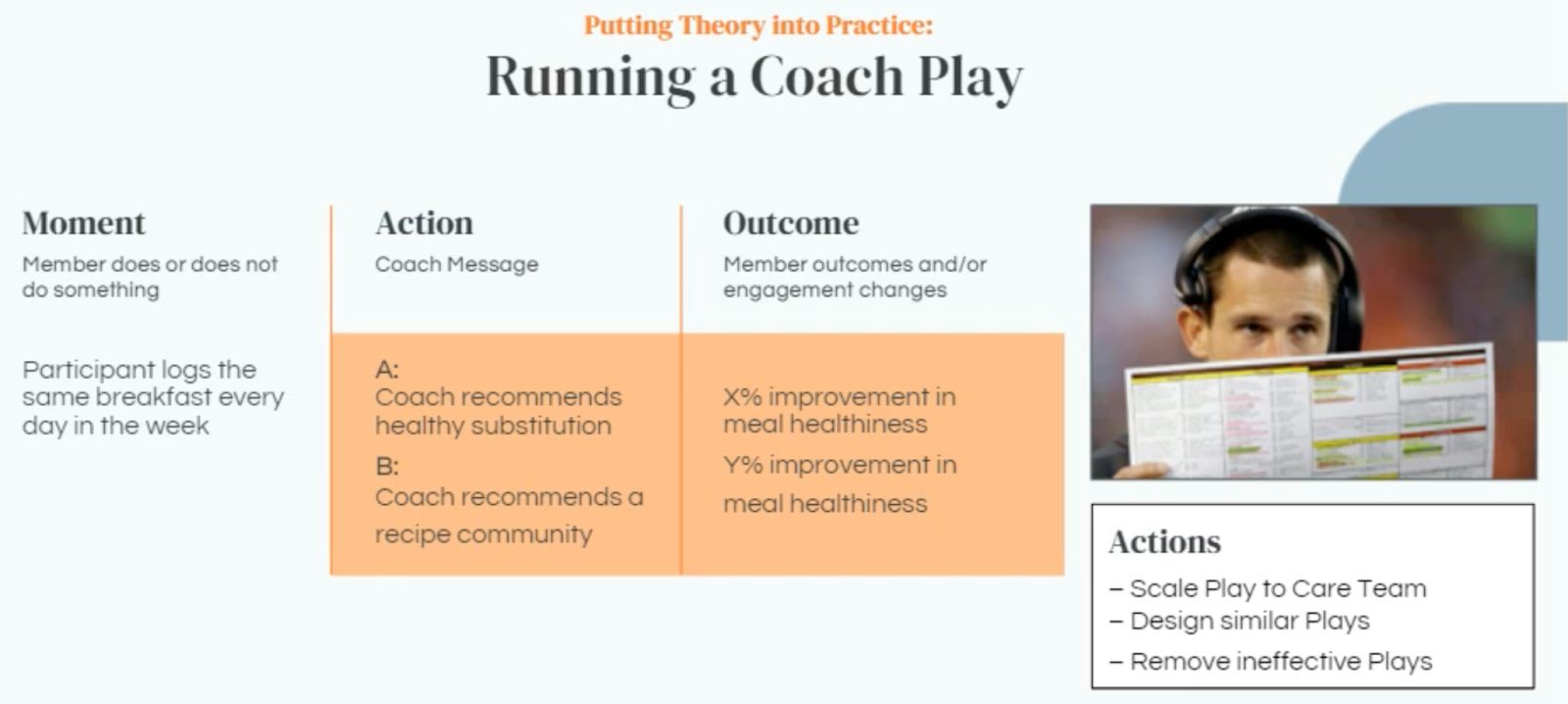
Source: The Power of Data Science and Innovation in Population Care Delivery
Where Confluent and ksqlDB come into play
Since we wanted to be able to run not just one but potentially hundreds of Coach Plays at once, we created an entire system consisting of three parts—a Moments API, PlayBook, and RePlay—to make Coach Plays programmatic and learnings easily shareable across our care teams.
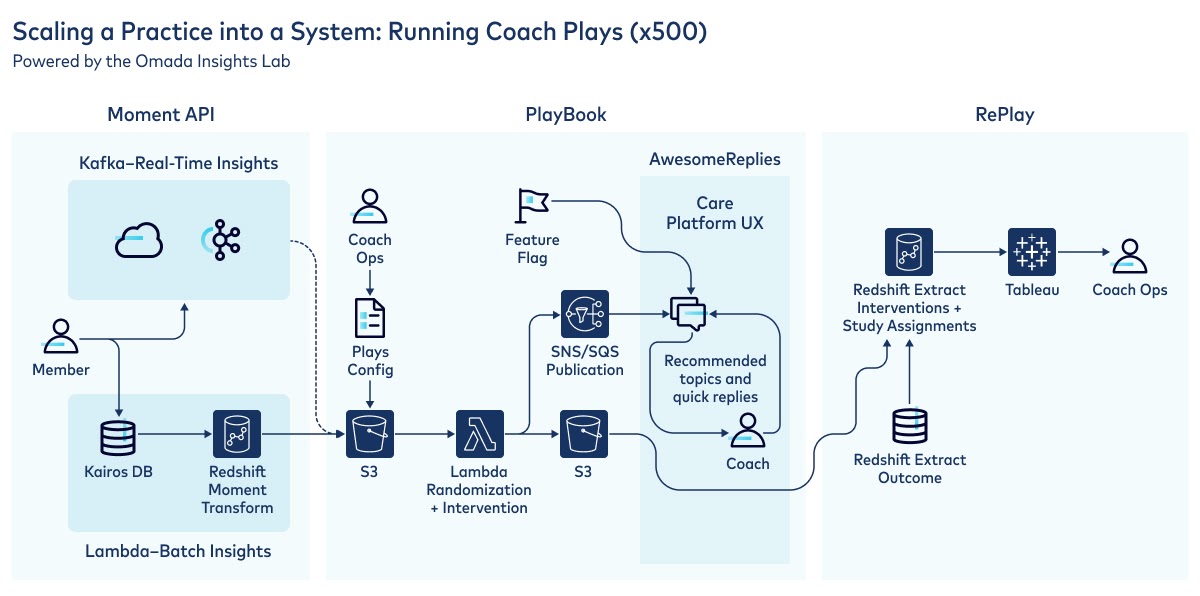
The Moments API is the part where Confluent and ksqlDB play a key role.
Our Moments API is a flexible playground for our data scientists, in collaboration with our care teams, to design and publish clinical decision support insights for our coaches in both batch and real time.
Two key types of insights surfaced via the Moments API are:
- Changepoint detection from remote monitoring devices, where an inflection point on continuous measures indicates it’s time for a coach to review and take some action.
- NLP-based pattern matching, where we put the changepoint detection information into the context of other behaviors via multiple streams of information (a meal log and a continuous glucose monitoring log, for example) for cross-correlations.
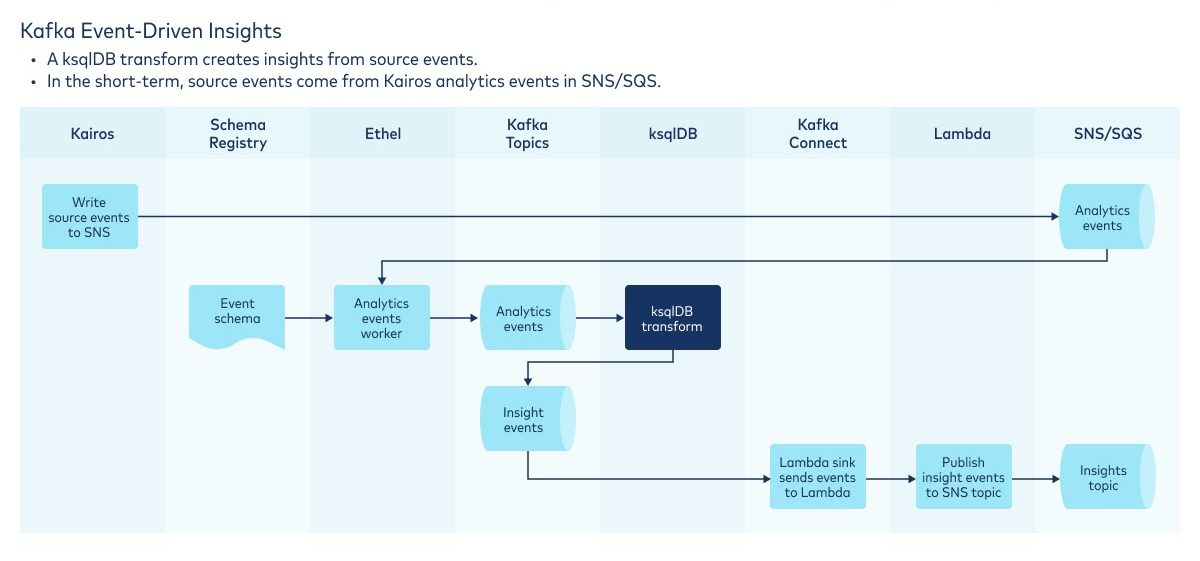
Confluent and ksqlDB play an important role in managing these data streams, which then create the knowledge and insights that get pushed out to our coaches via coach-facing applications.
The PlayBook is a content management system (CMS) that the health coach team leads use to design Plays by configuring a unique combination of a Moment, Intervention, and Outcome. The PlayBook hosts a vast library of moments that are accessible to the health coach team leads via a drop-down menu. Once configured, the health coach team leads can then publish and make the Plays available to the full workforce so that any coach can try the newly configured Play.
The RePlay feature then aggregates all of the information about Moments, Interventions, and Outcomes into an easy-to-interpret dashboard, so Health Coach Operations can learn which Plays were most effective in the latest release cycle. With this information in hand, Health Coach Operations can decide to scale the Plays that are most effective for members and remove the Plays that were ineffective.
ksqlDB’s ease of use
The great thing about using ksqlDB is how well it fits into our existing ETL data pipeline. Because the Data Science and Analytics team were already well-versed in SQL for doing batch transformations with other tools, the transition to using ksqlDB in our Coach Plays system to start processing streams of events stored on Confluent Cloud in real time was seamless. Because ksqlDB and other components of Confluent Cloud were fully managed, it allowed our team to avoid maintaining low-level infrastructure and instead focus our development efforts on improving the long-term health and well-being of our members through the Coach Plays system.
Here’s an example ksqlDB query we used for our re-engagement Coach Play:
CREATE OR REPLACE STREAM IF NOT EXISTS user_health_behaviors_stream
CREATE TABLE IF NOT EXISTS user_health_behaviors_table AS
SELECT
user_id,
health_behavior_key,
max(time) as latest_time
FROM user_health_behaviors_stream
GROUP BY user_id
CREATE OR REPLACE STREAM IF NOT EXISTS health_behaviors_joined_events_stream AS
SELECT
uhbt.user_id,
uhbt.health_behavior_key,
uhbs.time AS stream_time,
uhbt.latest_time AS table_time,
FROM user_health_behaviors_stream uhbs
LEFT JOIN user_health_behaviors_table uhbt
ON uhbs.account_id = uhbt.account_id
GROUP BY uhbt.health_behavior_key
CREATE OR REPLACE STREAM IF NOT EXISTS moment_reengagement_meal_tracking_30d_inactive AS WITH ( KAFKA_TOPIC='moment_reengagement_meal_tracking_30d_inactive' ) AS
SELECT USER_ID, HEALTH_BEHAVIOR_KEY, STREAM_TIME, TABLE_TIME, CAST((STREAM_TIME - TABLE_TIME)/1000.0 AS BIGINT) AS delta_seconds FROM health_behaviors_joined_events_stream WHERE TABLE_TIME IS NOT NULL AND CAST((STREAM_TIME - TABLE_TIME) AS BIGINT) >= (CAST(30 AS BIGINT) * 24 * 60 * 60 * 1000) AND HEALTH_BEHAVIOR_KEY = 'meals_tracked'
The future
We’ve barely scratched the surface of what we can do with the Coach Plays platform powered by Confluent. We have three real-time Coach Plays lined up, one of which is already in production:
-
- Goal celebration: When a member of our program achieves a certain goal, we want our coach to be there and celebrate with them
- Re-engagement: When a member stops tracking their behavior for a while, we want to create a re-engagement protocol to get the member back on track
- Device data: We’re continuing to think through how we can leverage device data to drive positive behavioral changes and health outcomes
We’re always soliciting ideas to find more real-time moments on which our coaches can act. As we build out a portfolio of these moments, more and more of our coaches can intervene in real time to drive the right recommendations for a member and improve their lives. We have a strong belief that acting in the moment makes more sense than delayed intervention and is the most effective and powerful way to create lasting change.
We want to acknowledge the following individuals’ efforts in enabling improved outcomes for our members, while pioneering and scaling real-time Coach Plays and Apache Kafka® at Omada using Confluent’s solution:
Product: Priyanka Bhojwani
Engineering: Jimmy Do, Greg Capra, Ricardo Rojas, Vivek Bhansali, Jonathan Wrobel, Anna Sobolewska
Coach Plays: Luke Armistead, Tina Yeung, Devin Ellsworth
Security & Compliance: Ray Reynolds, Patrick Curry, Veronica Sander
Leadership: Kalika Kekkar, Franck Verrot
Special thanks to Bill Dougherty, who has continued to support our partnership with Confluent.
Ist dieser Blog-Beitrag interessant? Jetzt teilen
Confluent-Blog abonnieren


InfiniteWatch + Confluent: Turning Customer Interaction Data into Real-Time Intelligence
InfiniteWatch is building an AI-native customer interaction intelligence platform that unifies these streams into a continuous, real-time understanding of customer behavior and operational state. At its core is Confluent.


Focal Systems: Boosting Store Performance with an AI Retail Operating System and Real-Time Data
Discover how Focal Systems uses computer vision, AI, and data streaming to improve retail store performance, shelf availability, and real-time inventory accuracy.