Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
What Is Data Streaming?
Data streaming is a modern approach to data movement and processing that enables businesses to harness the value of data the moment it’s created. Rather than waiting for data to be collected and processed in batches, streaming makes it possible to react in real time.
At the core of most streaming systems is Apache Kafka®, the open-source technology that laid the foundation for real-time infrastructure. Built by the original creators of Kafka, Confluent is the category leader in data streaming.
Confluent’s data streaming platform extends Kafka with the enterprise-grade capabilities needed to connect systems, process data in motion, enforce governance, and operate reliably in any environment—cloud, on-prem, or hybrid.
Core Components of Data Streaming
What Is Streaming?
In the context of data, "streaming" means processing and acting on a continuous flow of real-time information or data “events.” It mirrors how the real world works—constantly changing and always in motion. Streaming allows organizations to analyze and respond to this dynamic data without delays from traditional data processing methods.
Streaming systems handle data from a wide variety of formats and volumes—ranging from financial transactions and ecommerce activity to telemetry from devices or digital experiences—aggregating it into a unified, real-time view.
What Is Streaming Data?
Streaming data refers to the continuous flow of data generated by countless sources: applications, databases, sensors, user interactions, logs, transactions, and more. Rather than waiting for data to accumulate before it’s processed, streaming data is captured and processed in real time—or near real time—to enable faster, smarter decisions.
Other Key Terms to Know
-
Stream processing: The real-time processing and analysis of streaming data.
-
Batch processing vs. Real-time stream processing: Batch processing collects data over time and processes it in chunks (often with delays of hours, days, or even weeks). Stream processing processes data instantly, enabling faster insights and actions.
-
Event-driven architecture: A system design where events (such as user actions, system outputs, or state changes) trigger downstream processes automatically.
-
Event streaming: The practice of capturing and processing streams of events as they happen.
-
Real-time/Near real-time: The ability to process and act on data as soon as it's generated, with minimal latency.
-
Data products: Reusable data assets designed for consumption by teams, systems, or applications. Data streaming enables more reliable and easily accessible data products by ensuring fresh, consistent data is always available in real time.
Industries Leading the Way With Data Streaming
Data streaming is being widely adopted across industries where real-time decisions and experiences matter most. These include:
-
Financial services: For fraud detection, payment processing, and real-time risk analysis
-
Retail and ecommerce: For personalized shopping experiences and dynamic inventory updates
-
Transportation and logistics: For GPS tracking, ETA predictions, and route optimization
-
Manufacturing: For predictive maintenance, quality control, automation, and supply chain visibility
-
Telecommunications: For optimizing network performance and customer service
-
Healthcare: For patient monitoring and system-wide data integration
-
Technology and software: For product telemetry, usage analytics, and system observability
How Data Streaming Works
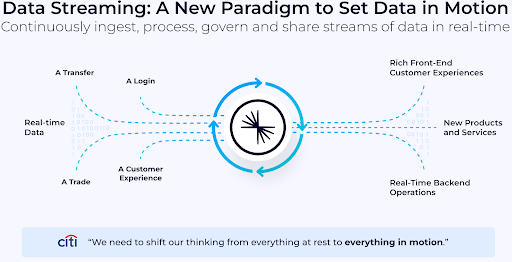
Streaming data architectures, often built on platforms like Apache Kafka®, allow organizations to work with data the moment it's created. Instead of waiting to collect and process data in batches, these systems continuously capture, organize, and analyze information in real time—helping teams make faster, smarter decisions.
By separating where data comes from and where it’s used, streaming architectures provide the flexibility to move quickly, scale efficiently, and adapt to changing business needs. The result: faster innovation, more reliable data pipelines, and the ability to deliver real-time, personalized customer experiences at scale.
Leading companies like Victoria’s Secret have greatly benefited from adopting a streaming architecture that allows them to turn their data into reusable data products that fuel a variety of high-impact use cases:
“We can tap into real-time data and build a matrix out of it so that…teams can then feed into that data to provide financial metrics, customer metrics, marketing preferences, and personalized recommendations to the customers.”
- Harikumar Venkatesan, Platform Engineering Lead, Victoria’s Secret
Frequently Asked Questions About Data Streaming
- Is data streaming the same as real-time analytics?
Not quite. Data streaming is the foundation that powers real-time analytics, but it also supports other use cases like automation, system integration, and AI. - What is Apache Kafka®’s role in data streaming?
Kafka is the technology many organizations use to power their real-time data streaming systems. It acts like a central hub that helps different parts of a business share and react to data quickly and reliably, as soon as it’s created. - Do I need a complete platform to succeed with streaming?
Kafka is a great foundation, but a complete data streaming platform like Confluent provides the enterprise features, integrations, and tools needed to scale streaming across your organization—without the need to dedicate time and resources to managing complex operations. - Why not just use batch processing?
Batch processing introduces latency, which limits your ability to act on data in the moment. Streaming is ideal for time-sensitive use cases where insights and decisions can’t wait. - Is data streaming only for tech companies?
Not at all. From banks and retailers to manufacturers and healthcare providers, streaming is becoming essential for every modern business.
Benefits of Data Streaming
Modern data streaming platforms offer both technical and business advantages. By enabling data to move and be acted upon in real time, streaming helps organizations become more agile, data-driven, and efficient.
Technical Benefits
-
Decouples systems: Producers and consumers can operate independently for more flexible architectures
-
Optimized for high throughput: Handles massive volumes of fast-moving data
-
Horizontally scalable: Easily scales across distributed infrastructure
Business Benefits
-
Faster decisions: Power fraud detection, recommendations, or alerts in milliseconds
-
Operational efficiency: Automate manual processes with real-time triggers
-
Improved customer experiences: Deliver personalized and context-aware interactions
-
AI and ML enablement: Feed models with up-to-date data for better accuracy and performance
-
Cost savings: Reduce the burden of siloed systems, data duplication, and batch inefficiencies
Data Streaming Use Cases
Data streaming powers a nearly limitless number of use cases that deliver real-world business value. Here are just a few examples:
Industry: Financial Services
Company: Citizens Bank
Use Case: Real-time data processing that reduced false positives for fraud detection and sped up loan processing
Results: Citizens Bank saw a 15% reduction in false positives for fraud detection, saving ~$1.2M annually. The company also achieved a ten-point increase in net promoter score (NPS), due in part to 40% faster loan processing times.
Industry: Retail & Ecommerce
Customer: Instacart
Use Case: Real-time data pipelines that enable fast onboarding of new customers and more accurate views of inventory availability
Results: Instacart scaled rapidly, onboarding 500,000 shoppers across the United States in just six weeks. The company is also better able to ensure customer order fulfillment due to real-time inventory tracking
Industry: Software (AI)
Company: Notion
Use Case: Instant processing and enrichment of data that enables advanced product features like generative, AI-powered Autofill
Results: Notion tripled its productivity, overcame scaling limitations, and unlocked new product capabilities
Industry: Manufacturing
Company: Michelin
Use Case: Real-time data streams that fuel accurate views of the company’s inventory across its entire ecosystem
Results: Michelin improved the reliability of reporting and monitoring for raw and semi-finished materials, enhancing the efficiency of its global supply chain. The company also saved 35% in operations costs after moving from self-managed Kafka to Confluent’s fully managed data streaming platform.
Industry: Media & Entertainment
Company: Audacy
Use Case: Streaming live audio to over 200 million listeners at scale with low latency and high reliability
Results: Audacy reduced latency of live streaming audio from 90 seconds to 30 seconds, increasing listener engagement and driving more monetization opportunities.
Challenges of Scaling Real-Time Data Streaming
While Apache Kafka® has become the de facto standard for data streaming, operating it at scale is complex and costly—especially for enterprises.
Common Technical Challenges of Kafka
-
Scalability: As data volumes grow, maintaining reliability and performance becomes harder
-
See Apna’s story to discover how Confluent allowed them to overcome scaling challenges
-
-
Durability & Fault Tolerance: Streaming systems must be resilient to failures and prevent data loss
-
See Swiggy’s story to learn how Confluent provides enhanced reliability and resilience at scale
-
-
Latency Management: Streaming requires consistently low-latency processing and delivery
-
See Vimeo’s story to discover how Confluent enabled best-in-class user experiences with zero buffering
-
-
Operational Overhead: Managing Kafka requires teams to handle upgrades, monitoring, scaling, and more
-
See Booking.com’s story to learn more about the challenges of self-managed Kafka operations
-
Why a Data Streaming Platform Matters
Kafka is powerful but doesn’t provide out-of-the-box solutions for processing, security, governance, or integrations. Confluent goes beyond Kafka with a complete data streaming platform that includes:
-
Real-time stream processing with Apache Flink®
-
Over 120+ pre-built connectors to reduce custom coding and streamline system integrations
-
99.99% uptime SLA for mission-critical workloads that require always-on availability
-
Elastic scaling for effortless expansion as data volumes grow
-
Stream governance and data quality tools to ensure well-managed data across teams and environments
-
Enterprise-grade security and compliance for protecting sensitive data and meeting regulatory requirements
-
Multi-cloud and hybrid deployment flexibility
By reducing the financial and opportunity costs of self-managing Kafka, Confluent enables teams to focus on building business value—not infrastructure.
Why Confluent: The Complete Data Streaming Platform
Early data streaming tools were powerful but incomplete. Kafka introduced durability, scalability, and data reusability—but running it at scale is difficult and resource-intensive. That’s where Confluent comes in.
Built by the original creators of Apache Kafka®, Confluent is the only data streaming platform that delivers the full range of enterprise capabilities organizations need to connect, process, and govern data in real time. With Confluent, you can:
-
Connect everything: Stream data across legacy systems, SaaS apps, cloud services, and databases
-
Process data in motion: Enrich, aggregate, and react to data in real time with Apache Flink®
-
Govern with confidence: Enforce data quality, traceability, and compliance from source to sink
-
Stream everywhere: Deploy natively across clouds and on-prem, with global availability
Used by companies like Walmart, Expedia, and Bank of America, Confluent helps leading enterprises accelerate digital initiatives, unlock AI, and deliver better customer experiences with data that’s always fresh and always flowing.
Interested in learning more?
Resources for IT leaders:
Resources for data practitioners: