Neu in Confluent Cloud: Daten & Pipelines für KI-fähiges Streaming zugänglich machen | Mehr erfahren
How Walmart Uses Apache Kafka for Real-Time Replenishment at Scale
Walmart’s global presence, with its vast number of retail stores plus its robust and rapidly growing e-commerce business, make it one of the most challenging retail companies on the planet for inventory-related use cases. Real-time inventory planning has become a must for Walmart in the face of rapidly changing buyer behaviors and expectations. But real-time inventory is only half of the equation.
The other half is real-time replenishment, which at a high level, we define as the way we can fulfill the inventory demand at every physical node in the supply chain network. As soon as inventory gets below a certain threshold, and based on many other supply chain parameters like sales forecast, safety stock, current availability of the item at node and its parents, we need to automatically replenish that item in a way that optimizes resources and increases customer satisfaction.
Walmart doesn’t just have physical stores, it also has hundreds of distribution centers (DCs) of varying types, in a multi-echelon ecosystem that makes accurate, reliable, real-time replenishment a very challenging proposition. Apache Kafka® is a big part of the cutting-edge IT architecture that makes it all happen.
The real-time replenishment challenge
A real-time inventory use case was one of our first successful deployments of Kafka in our ecosystem. Similar to that use case, Walmart’s real-time replenishment use case is uniquely challenging due to the sheer scale and complexity of Walmart’s operations and the amount of data and moving parts those operations involve. This scale becomes even more daunting when you consider the many IT architecture-dependent goals and expectations we have around establishing a forward-looking platform to handle all the necessary replenishment needs for the company:
- Cycle-time reduction: That is, reducing, as much as possible, the amount of time between the order being made and the inventory arriving at the store. The platform needs to consider the right input parameters around vendor calendars and DC picking calendars while running the plan for a large number of SKUs in a very short and stipulated amount of time.
- Accuracy: Accuracy in inventory quality and quantity is ever more important as customers become more and more specific with their needs. We can’t deliver items that aren’t in demand by the customer, and it takes up store space while not catering to the demand. The same goes for quantity—we need to be able to deliver the right amount at the right time.
- Speed: We need to optimize our supply chain to make it as efficient as possible, which means taking full advantage of every delivery trip from every distribution center, which in turn means there is very limited time to process orders according to the plan. We have a unique challenge when running and building the order plan for a large number of SKUs accurately in a very short span of time. This mandates that every section of the platform (including virtual machines (VMs), Kafka, databases, network) need to operate at optimal speed.
- Reduced complexity: We need to ensure that the platform is high performing as well as simple in design in order to allow for the quick addition of features to react to new supply chain needs. That also allows for quick debugging and analysis in case of any system and functional issues.
- Elasticity and scalability: Given the ever-increasing size of our data and varying functional needs, the platform is expected to scale horizontally and optimally as per the needs of the various micro-batch cycles. This allows for quickly catering to new requirements at optimal cost.
- Resiliency: At our scale and the sensitivity of our data and time of processing, it is extremely important for the platform to have necessary failover and resiliency when part or all of the platform is not responding or is slow, impacting our SLAs.
Achieving all the above system and platform architecture demands while catering to ever-changing customer behavior is not trivial. This image illustrates a quick summary of our scale:
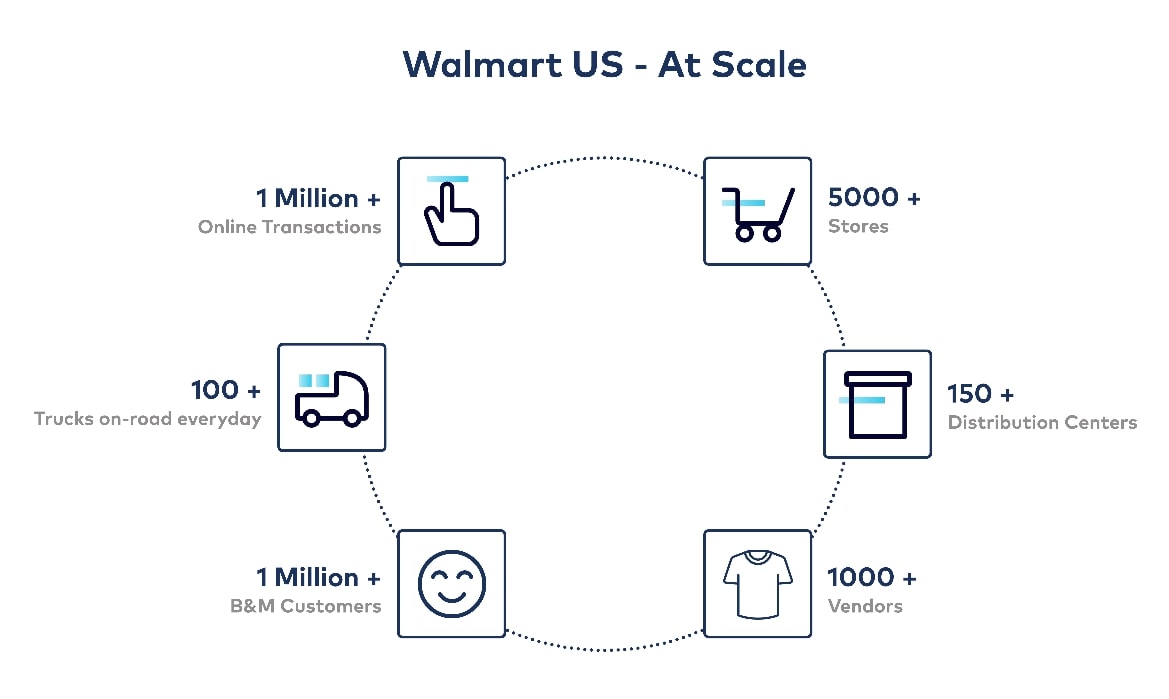
This challenge gets even bigger as we grow multifold with our data and real-time system messaging needs year after year.
The Kafka framework
On any given day, Walmart’s real-time replenishment system processes more than tens of billions of messages from close to 100 million SKUs in less than three hours. We leverage an array of processors to generate an order plan for the entire network of Walmart stores with great accuracy and at high throughputs of 85GB messages/min. While doing so, it also ensures there is no data loss through event tracking and necessary replays and retries.
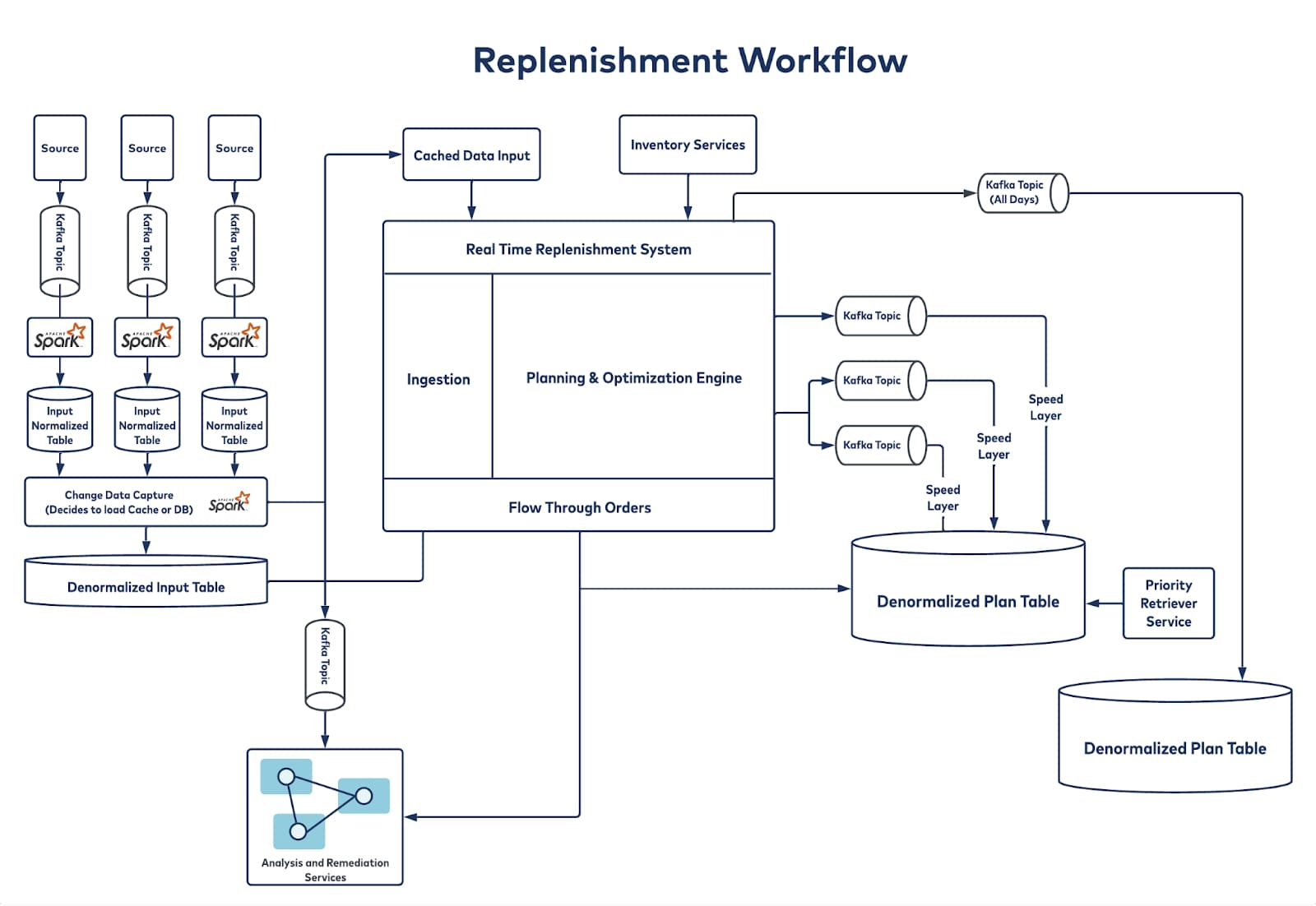
Our event-processing framework uses a micro-batch architecture, with most of the inputs coming in through Kafka. From Kafka, the data gets streamed through change data capture (CDC) and brought into a denormalized view so that it’s readily and quickly accessible. The data is then processed in a planning engine that contains all the inventory positions, forecasts, safety stocks, lead times, and calendars, while considering all the constraints (logistical and otherwise) of the distribution centers, stores, and shipping methods. This is all accomplished within the three-hour daily timeframe in which Walmart processes close to 100 million SKUs. This entire plan is then published through different Kafka topics for different layers, and each Kafka topic has different consumers who listen and formulate different actions accordingly. To give you an idea of the scale, we leverage 18 Kafka brokers and manage 20+ topics, each of which has more than 500 partitions.
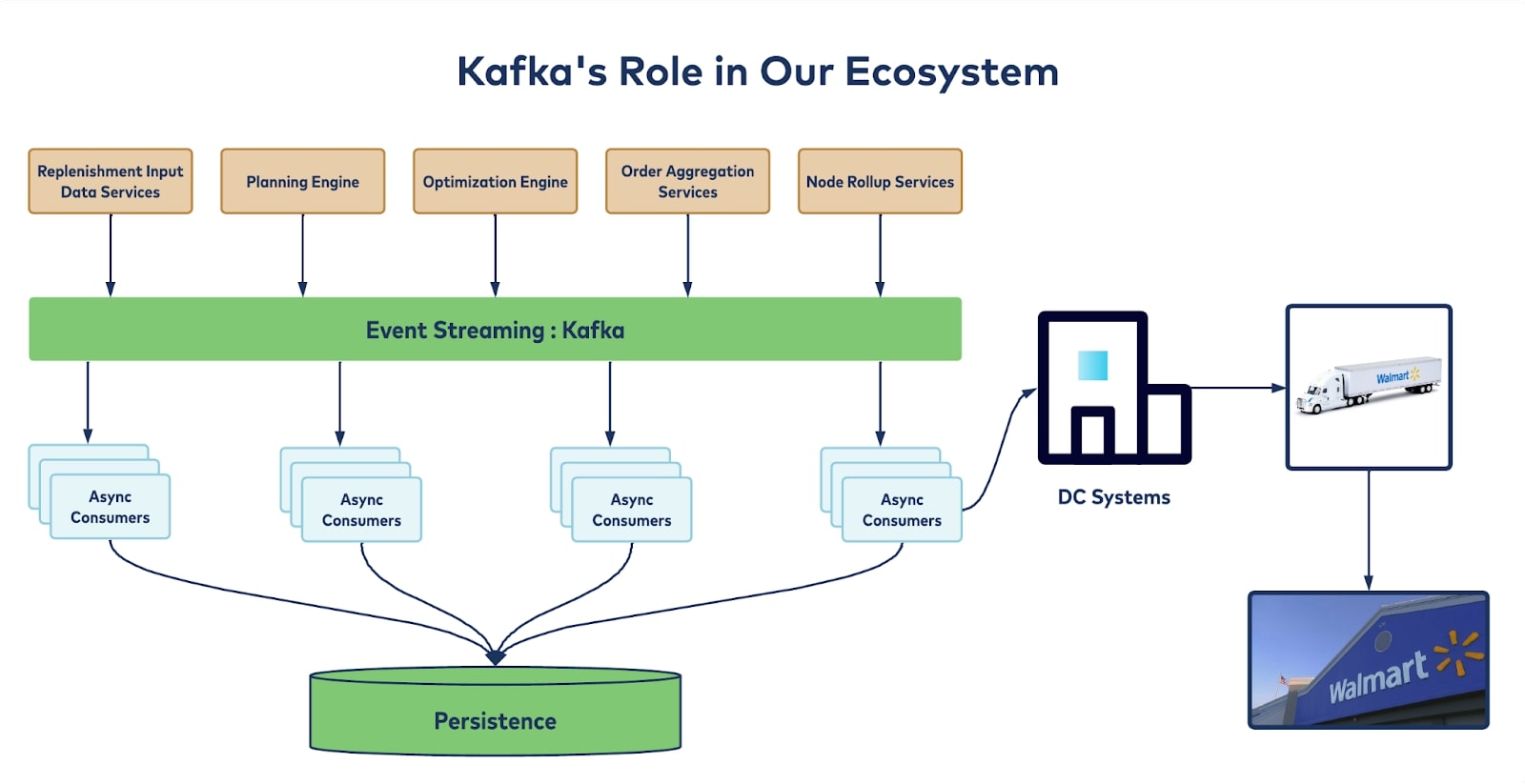
Key architectural considerations
In addition to the aforementioned resiliency and horizontal scalability for future needs, there were many other important architectural challenges and goals around setting up our real-time replenishment system, including:
- Real-time replacements powered by real-time input changes: For replenishment to happen in real time, inputs need to be ingested in real time. So, a very important tenet of our architecture is to stream in real-time inputs, be it through Kafka or real-time batch feeds.
- Multi-tenancy: With a presence in more than 24 countries, we need a single platform in which the tenants actually carry the features and that doesn’t break when new features are added.
- Real-time decision-making by diverse downstream consumers on near-real-time replenishment orders and plans: We need Kafka’s flexibility to stream real-time data into different layers so that consumers can read data from all these Kafka topics whenever we publish the data.
- Tighter contracts between inputs and the replenishment engine: We need very tight contracts between the inputs and the engine itself, because the inputs and the values or attributes we get from them are extremely important for plan accuracy. Whenever we do achieve data capture, we want to know what’s changing, so it’s very important to have a concrete contract between the input and the replenishment engine.
Other platform architecture decisions
Certain architectural decisions at the platform level have helped a lot.
One is the use of active-passive data replication, which means we have mechanisms in place to switch to a secondary data center if the primary data center has issues. An important consideration with this sort of active-passive environment is if there is an issue with the primary DC, you should know what offset it stopped processing from. You can then either start from that point onward, or, if you’re unable to do that, ensure your consumer or client can identify it and avoid processing duplicate messages. Active-active is another type of configuration to consider, but it comes down to what really works for a given use case and what sort of intervention, if any, one needs to prepare for.
We’ve also designed for resiliency and have mechanisms in place where if any computer or virtual machines go down, there are automatic mechanisms that will bring them up within a certain period of time.
The other thing we’ve done is enable Kafka retries. And on top of that, we’ve developed an in-house audit and replay mechanism that will really help us to come back from any kind of failure. We send the message to the topic, and it will store it in our database, and then our replay mechanism takes care of the rest.
We’ve also set up a fallback mechanism for when we may not be able to send the message to the topic itself—a rest service that will directly go and write to the database, and then the rest is taken care of by the replay mechanism.
We also have alerts and notifications, so we know what’s going on with our system. It’s an in-house subscription-based alerting mechanism that works at both the application level and at the infrastructure level.
Key tuning and optimizations
Of course, a key part of making Kafka work well for us was finding the right balance for our working ecosystem including the producers, Kafka cluster, and the consumers. Any lag in the producer or consumer layer can cause overall slowness and risk of missing SLAs. Having everything in balance is key. Below are some of the optimizations we made.
Producer configuration
With the producer configuration, there are a few configs Kafka provides that have really helped us in our journey to achieve the scale we set out for. One of these was a custom partitioning strategy through which we identified a few of the key aspects of our message and assigned a murmur hash function. We then used that to get to the partition where we want to send the message, instead of using the default round-robin strategy, which would lead to all the messages from the 150 distribution centers (we are reading within 3-4 hours) to get jumbled in cases where the plan processing for a few distribution centers run slow. This allowed us to get the speed while catering to necessary data isolation and accuracy.
The other important producer config optimization was using linger.ms and setting a batch size, both of which work in combination with each other. Linger.ms is the delay time the producer takes before sending out the next batch of messages, and we set the default batch size to around 16,000 bytes to optimize speed.
Finally, there are acks, which denotes the number of brokers that must receive the record before we consider the write to be successful. In our case, data consistency was important, and we wanted to make sure we didn’t lose any messages, so this was a critical setting we had to configure to “all” to ensure all the in-sync replicas receive the record from the producers.
Consumer configuration
There are a few consumer configurations that have helped us scale a lot better. The first are max.poll.records and max.poll.interval.ms tuning. Max.poll.records are the number of messages fetched in a single full poll, and max.poll.interval.ms is the amount of time the consumer has to process these messages. Since we deal with a lot of external services, we have to make sure our contracts and SLAs are airtight.
The next configuration is enable.auto.commit. Enable.auto.commit asks your consumer to make sure they acknowledge the messages they’re processing. Once all of the messages that are part of the whole request are completed, it will commit the offset. To help ensure no data loss, we basically disabled the enable-auto-commit flag to make sure we fully process all of the messages we receive before committing the offset.
Finally, you have session.timeout.ms and the heartbeat.interval.ms optimization. These two configs work in tandem with each other to help you recover from any client failures. Session timeout sets the amount of time that your consumer needs to recover from any kind of failure. Now, the typical consumer has multiple virtual machines and computes, and there’s always a possibility that a compute instance or a VM goes down. So, you need to leave a certain amount of time for your consumer to recover. Otherwise, when your consumer comes back up, or the compute instance comes back up, it’s going to need to rebalance, thus causing constant rebalance which is not an ideal scenario. The <codeheartbeat.interval.ms makes sure your client sends the heartbeat to the group coordinator to make sure it is alive and doing well.
Thanks to Kafka-backed real-time replenishment:
- Different teams within Walmart now have a more controlled view of the replenishment order plans for various layers of our multi-echelon supply chain network.
- Developers can rely on data directly from production using a consumer to perform thorough testing, reduce bugs, and test scenarios that they would only be able to test in production.
- Our developer teams have access to a rich ecosystem to work on innovative technology and new use cases.
- Architecture simplicity is achieved at consumer layer of the platform as the same data is leveraged by various consumers and acted upon differently as per the need.
- Accuracy and speed of replenishment is achieved by running replenishment planning cycles closer to pick time at the distribution while ingesting inputs real time.
For retailers looking to build real-time replenishment or real-time inventory use cases, here is some advice:
- Make sure you take a close look at your data infrastructure to ensure you have data pipelines in place that can give you real-time access to data.
- If your current architecture can’t support those needs, then focus on simplicity in the design and invest upfront in that architecture (this is one area where Kafka shines).
- Have a clear sense of the end result to help you realize the value of any platform you invest in.
- Decouple services within the architecture using producers and consumers. Kafka is a better source of decoupling than any other technology within the last 10 years.
Conclusion
This blog post shared Walmart’s journey with Kafka and highlighted the real-time replenishment use case we’re currently using it for. Being the world’s largest retailer, real-time replenishment plays a key role in catering to the needs of millions of our online and walk-in customers by ensuring timely and optimal availability of needed stock using Kafka and its ecosystem. We are excited to continue to unlock new use cases using a real-time streaming platform and to continue to lead retail industry innovation for many years to come.
Want to learn more?
- For more details on how Suman helped implement the real-time replenishment use case and it’s predecessor (real-time inventory management) at Walmart, signup for this fireside chat
- For details on Walmart’s real-time inventory management, check out the blog post Walmart’s Real-Time Inventory System Powered by Apache Kafka
Disclaimer: the views and opinions expressed in this article are those of the author and do not necessarily reflect the official policy or position of Walmart Inc. Walmart Inc. does not endorse or recommend any commercial products, processes, or services described in this blog





