Nouveau dans Confluent Cloud : rendre les données et les pipelines accessibles pour un streaming prêt pour l’IA | En savoir plus
Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
The last post in this microservices series looked at building systems on a backbone of events, where events become both a trigger as well as a mechanism for distributing state. These have a long history of implementation using a wide range of messaging technologies. But while Apache Kafka® is a messaging system of sorts, it’s quite different from typical brokers. It comes with both pros and cons and, like any technology we choose, this shapes the design of the systems we write.
Originally built to distribute the datasets created by large social networks, Kafka wasn’t designed to implement JMS or AMQP; it was designed to scale. It remains the fastest messaging system even today. Of its original authors, Jay and Neha were versed in distributed systems, with Jay cutting his teeth on the open source NoSQL store Voldemort. Jun was a long-time database researcher at IBM. None of the team had backgrounds in messaging systems, but they weren’t attacking the “messaging problem” directly—at least not in the traditional sense.
So Kafka was shaped by a different set of forces. A problem-space rethink, optimizing for scale and fault tolerance. Like many good outcomes in computer science, scale comes from simplicity. From workloads that flow with the grain of the underlying hardware. Kafka’s broker is, in many ways, the epitome of this. Distributed at its core, leveraging sequential workloads, and implemented with the rigor of a DBMS.
This change of tack is important. When building service-based systems we need to think about the synchronous and the asynchronous. We need access to datasets that are owned elsewhere. We need to react responsively. We need to iterate quickly and independently to get things done. Kafka’s focus on scale, throughput and retention, along with the decoupling effects of a broker, make it an ideal message backbone for service estates that need all of these things.
So this post is a more practical guide to building event driven systems using this unique type of broker. We’re going to examine how it differs from more traditional technologies, the key properties we should be leveraging in our system designs, configurations we should take note of and patterns we should implement or avoid. In later posts we’ll extend this further, pulling in the other elements of the wider Streaming Platform.
Leverage the Log: An Efficient Structure for Retaining and Distributing Messages
At the heart of Apache Kafka sits a distributed log. The log-structured approach is itself a simple idea: a collection of messages, appended sequentially to a file. When a service wants to read messages from Kafka it ‘seeks’ to the position of the last message it read, then scans sequentially, reading messages in order, while periodically recording its new position in the log.
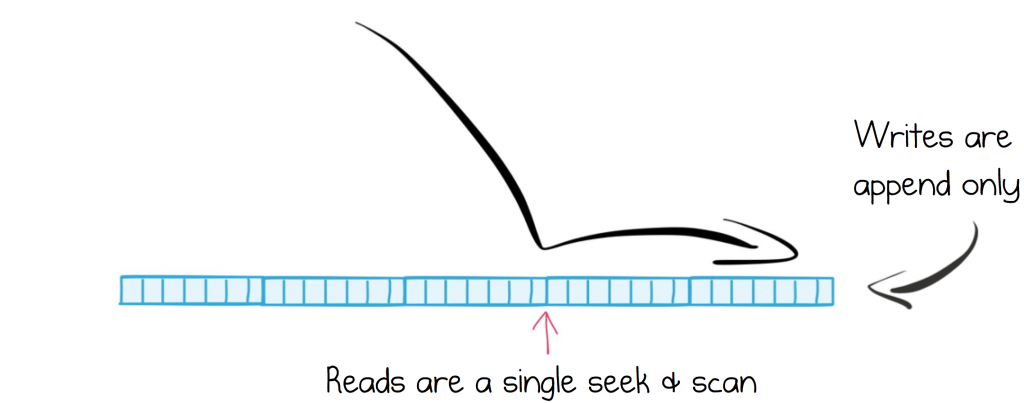
Taking a log-structured approach has an interesting side effect. Both reads and writes are sequential operations. This makes them sympathetic to the underlying media, leveraging pre-fetch, the various layers of caching and naturally batching operations together. This makes them efficient. In fact, when you read messages from Kafka, the server doesn’t even import them into the JVM. Data is copied directly from the disk buffer to the network buffer. An opportunity afforded by the simplicity of both the contract and the underlying data structure.
So batched, sequential operations help with overall performance. They also make the system well suited to storing messages longer term. Most traditional message brokers are built using index structures, hash tables or B-trees, used to manage acknowledgements, filter message headers, and remove messages when they have been read. But the downside is that these indexes must be maintained. This comes at a cost. They must be kept in memory to get good performance, limiting retention significantly. But the log is O(1) when either reading or writing messages to a partition, so whether the data is on disk or cached in memory matters far less.
From a services perspective there are a few implications to this log-structured approach. If a service has some form of outage and doesn’t read messages for a long time, the backlog won’t cause the infrastructure to slow significantly. A common problem with traditional brokers, which have a tendency to slow down as they get full. Being log-structured also makes Kafka well suited to performing the role of an Event Store, for those who like to apply Event Sourcing within their services.
Rely on a Broker that Scales Out Linearly
So the log is an efficient data structure for messaging workloads. But Kafka is really many logs. It’s a collection of files, filled with messages, spanning many different machines. Much of Kafka’s code involves tying these various logs together, routing messages from producers to consumers reliably, replicating for fault tolerance and handling failure.
While running on a single machine is possible, production clusters typically start at three machines with larger clusters in the hundreds. When you read and write to a topic, you’ll typically be reading and writing to all of them, sharding your data over all the machines you have at your disposal. Scaling is thus a pretty simple affair. Add new machines and rebalance.
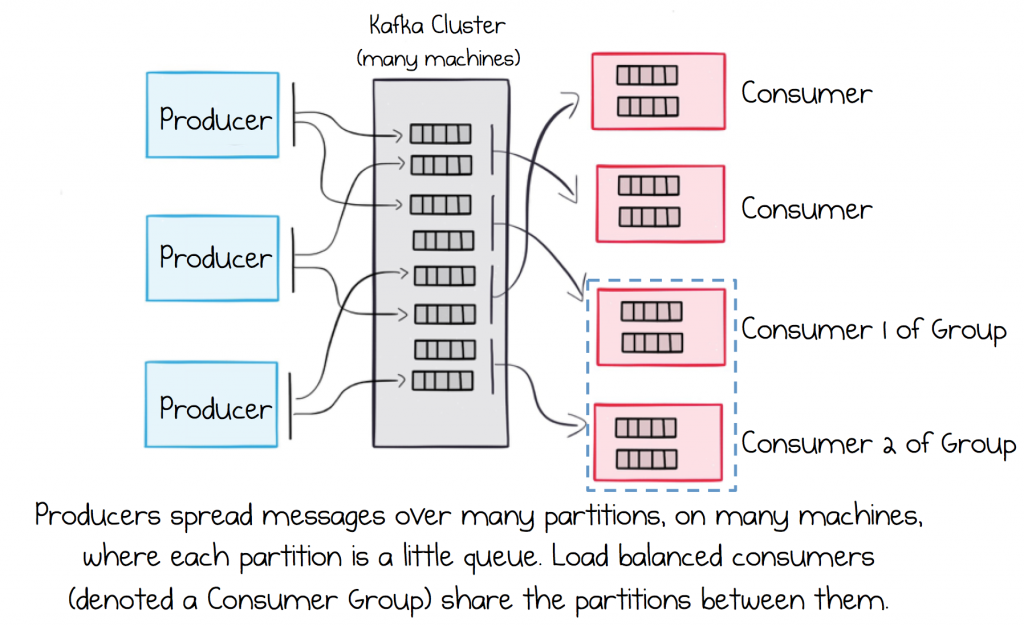
The main advantage of this, from a microservice perspective, is that it takes the issue of scalability off the table. With Kafka, hitting a scalability wall is virtually impossible in the context of business services. This is empowering, especially when ecosystems grow. So Kafka-based services tend to pick patterns that are a little more footloose with bandwidth and data movement.
Scalability opens other opportunities too. Single clusters can grow to company scales, without the risk off workloads overpowering the infrastructure. Topics with hundreds of terabytes are not uncommon, and with bandwidths carved up between the various services, using the multi-tenancy features makes clusters are easy to share.
Segregate Load in Multi-Service Ecosystems
Service architectures are by definition multi-tenant. A single cluster will be used by many different services. In fact it’s not uncommon for all services in a company to share a single cluster. But doing so opens up the potential for inadvertent denial of service attacks causing instability or downtime.
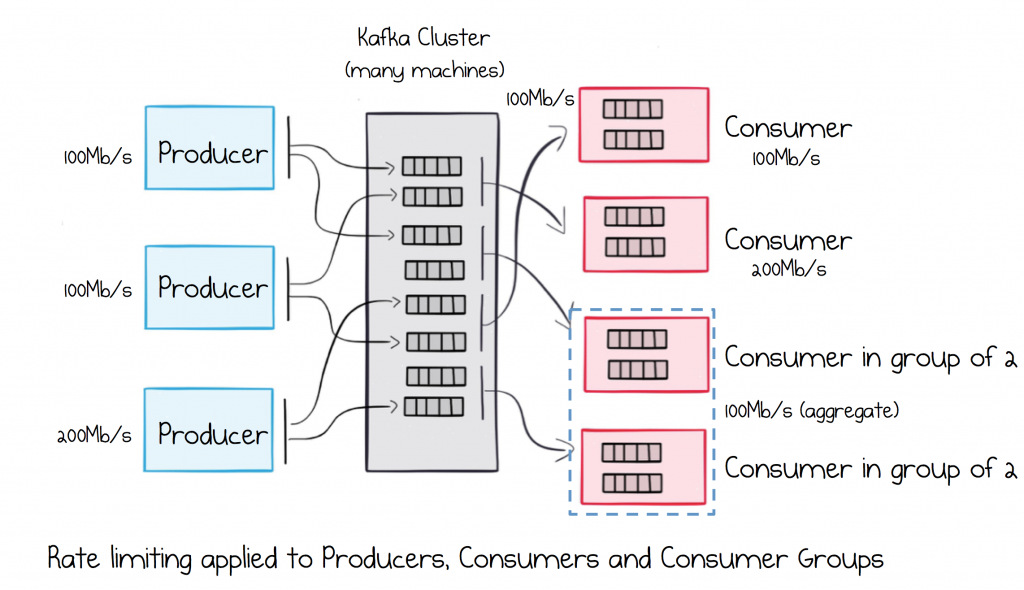
To help with this, Kafka includes a throughput control feature which allows a defined amount of bandwidth to be allocated to specific services, ensuring that they operate within strictly enforced SLAs.
Greedy services are aggressively throttled, so a single cluster can be shared by any number of services without the fear of unexpected network contention. This feature can be applied to either individual service instances or load balanced groups.
Maintain Strong Ordering Guarantees
While it often isn’t the case for analytics use cases, most business systems need strong ordering guarantees. Say a customer makes several updates to their Customer Information. The order in which these are processed is going to matter, or else the latest change might be overwritten with an older value.
There are a couple of things we need to consider to ensure strong ordering guarantees. The first is that messages that require relative ordering need to be sent to the same partition. This is managed for you, you supply the same key for all messages that require a relative order. So our stream of Customer Information updates would use the CustomerId, as their sharding key, so that all messages for the same Customer would be routed to the same partition, and hence be strongly ordered.
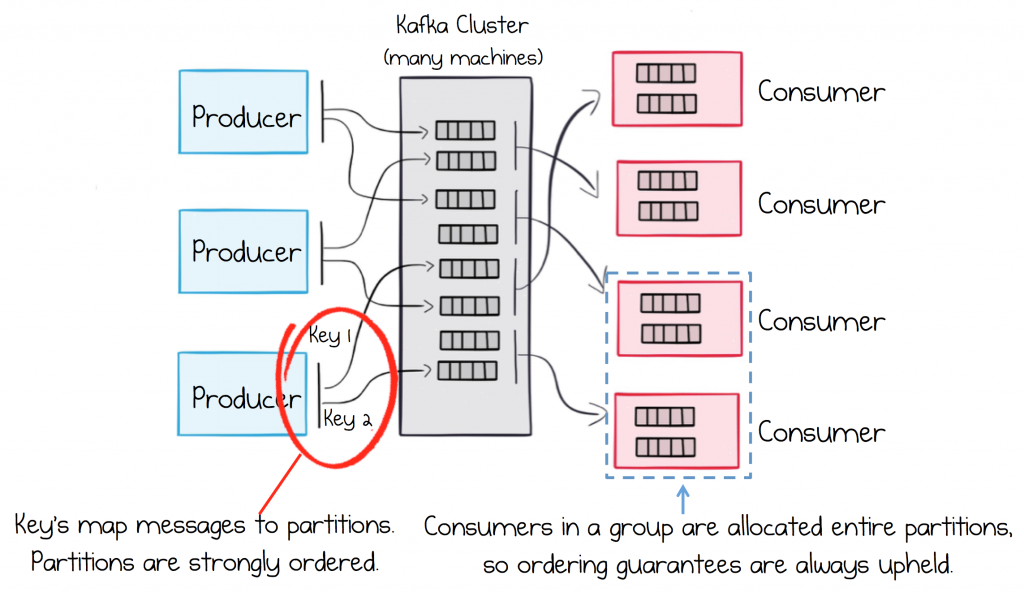
Sometimes key-based ordering isn’t enough, and global ordering is required. This often comes up when you’re migrating from legacy messaging systems where global ordering was an assumption of the original system’s design. To maintain global ordering use a single partition topic. Throughput will be limited to that of a single machine, but this is typically sufficient for most use cases of this type.
The second use case we need to be careful of is retries. In almost all cases we want to enable retries in the producer, so that if there is some network glitch, long running GC, failure, etc, any messages that fail to be sent to the broker will be retried. The subtlety is that messages are sent in batches, so we should be careful to send these batches one at a time, per destination broker, so there is no potential for a reordering of events when failures happen and whole batches are retried. This is simply something we configure (max.inflight.requests.per.connection).
Ensure Messages are Durable
Kafka provides durability through replication. This means messages are written to a configurable number of machines so that, should one or more of those machines fail, the messages will not be lost. If you configure a replication factor of three, two machines can be lost without losing data.
To make best use of replication, for sensitive datasets like those seen in service-based applications, configure three replicas per partition, set acknowledgements to “all” and min.insync.replicas to 2. This ensures that data is always written to at least two replicas, but Kafka will continue to accept messages should you lose a machine. Finally, as discussed earlier, configure retries in the producer.
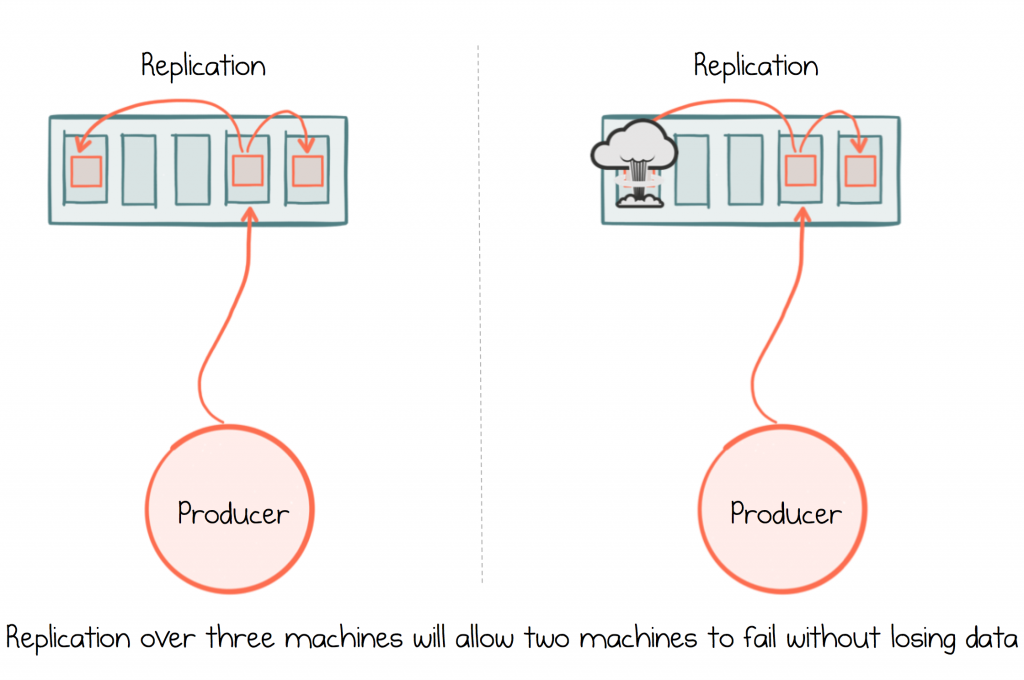
Highly sensitive use cases may require that data be flushed to disk synchronously. This can be done by setting log.flush.interval.messages = 1 — but this configuration should be used sparingly. It will have a significant impact on throughput, particularly in highly concurrent environments. If you do take this approach, increase the producer batch size, to increase the effectiveness of each disk flush on the broker (batches of messages are flushed together).
Load Balance Services and make them Highly Available
It’s common to run services in a highly available, load balanced configuration. So we might have two instances of the Orders service, reading messages from the Orders topic. In this case Kafka would assign half of the partitions to the first service instance, the other half to the second, so the load is spread over the two instances.
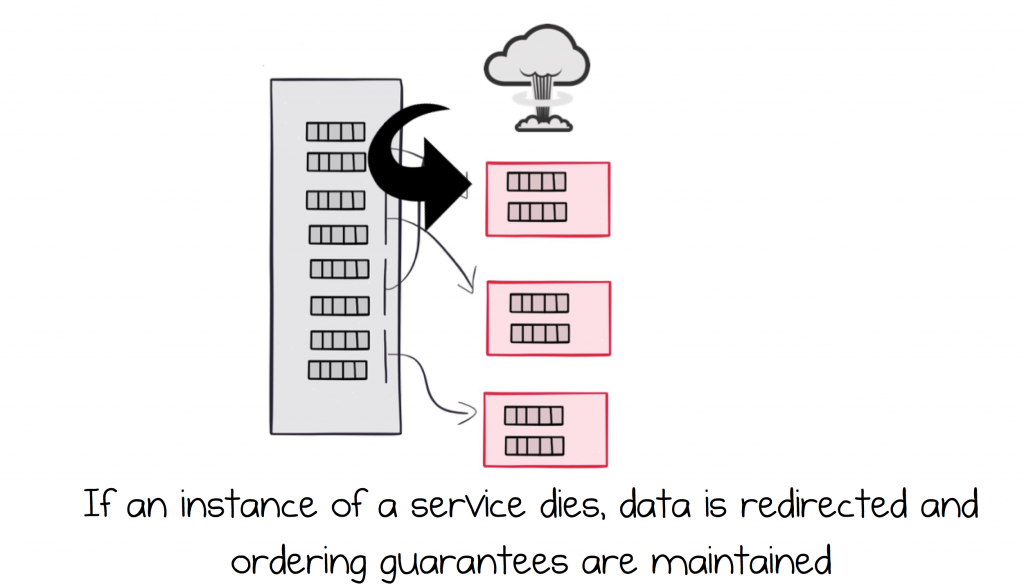
Should one of the services fail, for whatever reason, Kafka will detect this failure and re-route messages from the failed service to the one that remains. If the failed service comes back online, load flips back again.
This process actually works by assigning whole partitions to different consuming services. A strength of this approach is that a single partition can only ever be assigned to a single service instance (consumer). This is an invariant, implying that ordering is guaranteed, even as services fail and restart.
So services inherit both high availability and load balancing, meaning they can scale out, handle unplanned outages or perform rolling restarts without service downtime. In fact Kafka releases are always backwards compatible with the previous version, so you are guaranteed to be able to release a new version without taking your system offline.
Hold Key-Based Datasets in a Compacted Form
By default, topics in Kafka are retention based: messages are retained for some configurable amount of time. Kafka also ships with a special type of topic that manages keyed datasets: that’s to say data that has a primary key (identifier) and you might put in, or get from, a database table. These ‘Compacted Topics’ retain only the most recent events, with any old events, for a certain key, being removed. They also support deletes.
Compacted topics work a bit like simple LSM trees. The topic is scanned periodically and old messages are removed if they have been superseded (based on their key). It’s worth noting that this is an asynchronous process, so a compacted topic may contain some superseded messages, which are waiting to be compacted away.
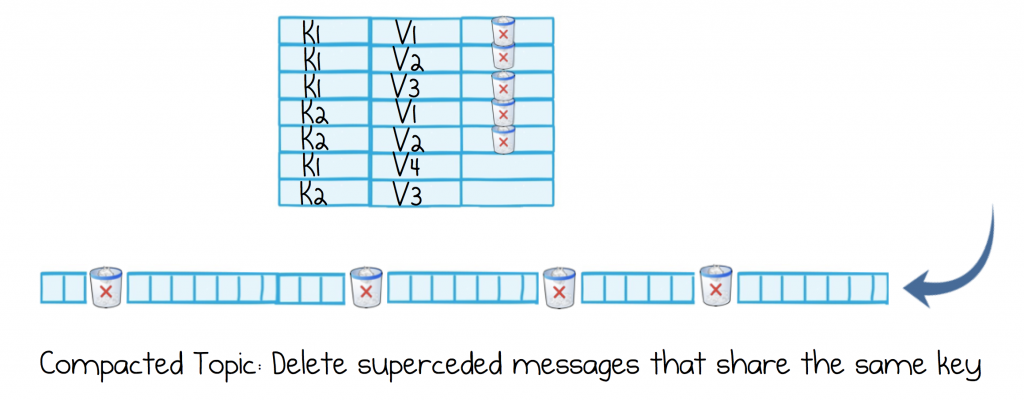
Compacted topics let us make a couple of optimisations. Firstly they reduce how quickly a dataset grows (as superseded events are removed), but we do this in a data-specific way, one that relates to the data itself, rather than say simply removing messages older than two weeks. Secondly, by making datasets smaller, it’s easier to move them from machine to machine.
So say a service wishes to load the latest version of the Product Catalogue, and we have Products stored in a compacted topic in Kafka, the load can be performed quicker and more efficiently if it doesn’t have to load the whole ‘versioned history’ as well (as would be the case with a regular topic).
This keeps load times down when we want to reprocess whole topics from scratch, load Event Sourced datasets, or load data into Kafka Streams. We’ll be looking at this a lot more closely later in the series as we introduce approaches for data automation and streaming services.
Holding Data in Kafka Long-Term
One of the bigger differences between Kafka and other messaging systems is that it can be used as a storage layer. There are a couple of patterns used for this. One is Event Sourcing, where we store each state change our service makes in a topic, which can be replayed in full. The second approach optimizes this to only keep the latest event, for each key, using a compacted topic (discussed above). The final approach is to hold both, linked via a Kafka Streams process. This gives you the best of both worlds.
So imagine our service wants to expose JMX metrics that track a variety of operational measures, like the number of orders processed each day. We might keep the running totals for these in memory, then store these values periodically back to Kafka. When the service starts it would load these intermediary values back into memory. As we’ll see in the next post, we can use Kafka’s Transactions feature to do this in an accurate and repeatable way.
For small datasets, stored in compacted topics, it’s useful to reduce the default segment size (log.segment.bytes) as the most recent segment of a compacted topic is never compacted.
Finally, the Kafka Streams API actually provides richer semantics for data storage via its State Store feature. These layer RocksDB in front of a compacted Kafka topic and automate the flushing of data back to Kafka. We’ll cover these in more detail later in this series.
Segregate Public and Private Topics
When using Kafka for Event Sourcing or Stream Processing, in the same cluster through which different services communicate, we typically want to segregate private, internal topics from shared, business topics.
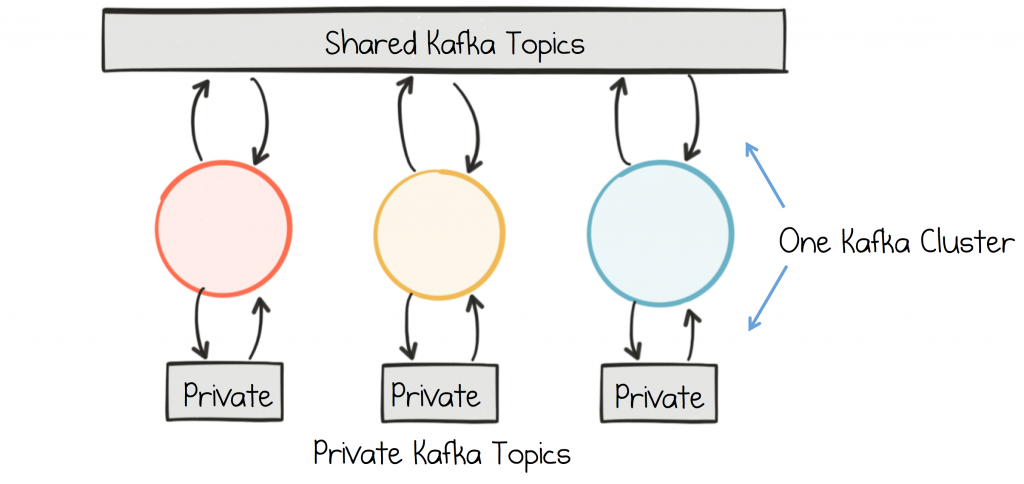
Some teams prefer to do this by convention, but a stricter segregation can be applied using the authorization interface. Essentially you assign read/write permissions, for your internal topics, only to the services that own them. This can be implemented through simple runtime validation, or alternatively fully secured via TLS or SASL.
Use Schemas to Manage the Evolution of Data in Time
It’s typically preferable to use schemas to wrap the messages services exchange. Schemas provide a contract that defines what a message should look like. This is pretty intuitive. Importantly though, most schema technologies provide a mechanism for validating whether schemas are backwards compatible. So say you added a ‘returns code’ field to an Order schema. This would be a backwards compatible change, as old programs can still read the previous version of the schema as is, but new programs can also read the new ‘return code’ field.
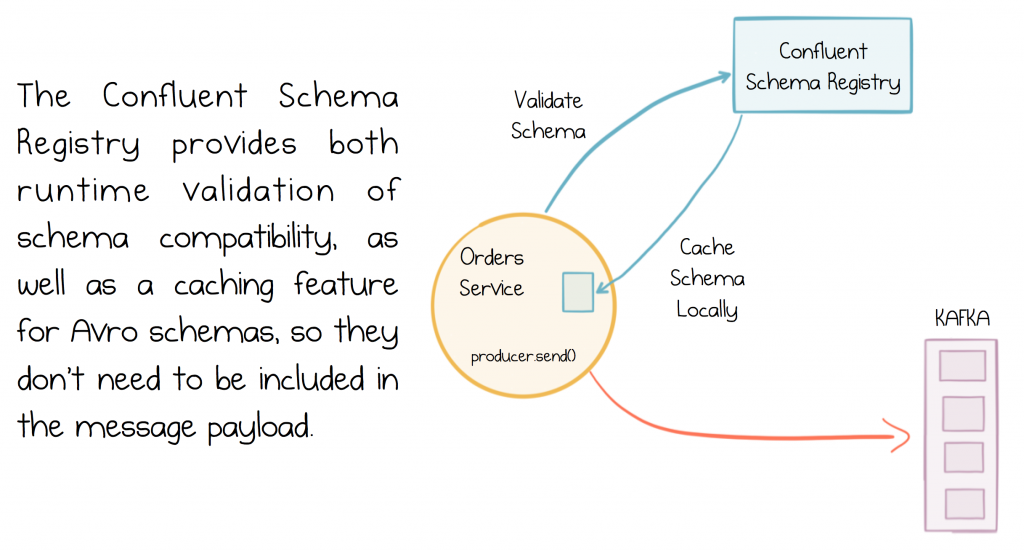
There are a fair few options available for this: Protobuf, JsonSchema etc but most projects in the Kafka space use Avro. Confluent provides the Confluent Schema Registry, which adds a level of runtime validation to Avro encoded messages, ensuring that incompatible messages will fail on publication, thus protecting the system from invalid data. If you use the Confluent Platform distribution, Kafka is bundled with the Schema Registry ready for you to use.
How to Break Backwards Compatibility
Most of the time, when we’re evolving and releasing our services, we maintain backwards compatibility between schemas. This keeps releases simple. Periodically however message formats will need to be changed in incompatible ways, most commonly when a whole schema needs to be reworked.
Say we want to change the way an Order is modelled. Rather than being a single element, Cancels, Returns and Reorders are all to be modelled in the same schema. This kind of change would likely break backwards compatibility because the structure of the whole schema has to be changed.
The most common approach for handling breaking changes like these is to create two topics: orders-v1 and orders-v2, for messages with the old and new schemas respectively. Assuming Orders are mastered by the Orders Service, this gives us a couple of options:
- The Orders service can dual-publish in both schemas at the same time.
- We can add a process that down-converts from orders-v2 topic to orders-v1 topic. A simple KStreams job is typically used to do this kind of down-conversion.
Both approaches achieve the same goal: to give services a window in which they can upgrade, but the KStreams method has the advantage that it’s also easy to port any historic messages from the v1 to the v2 topics.
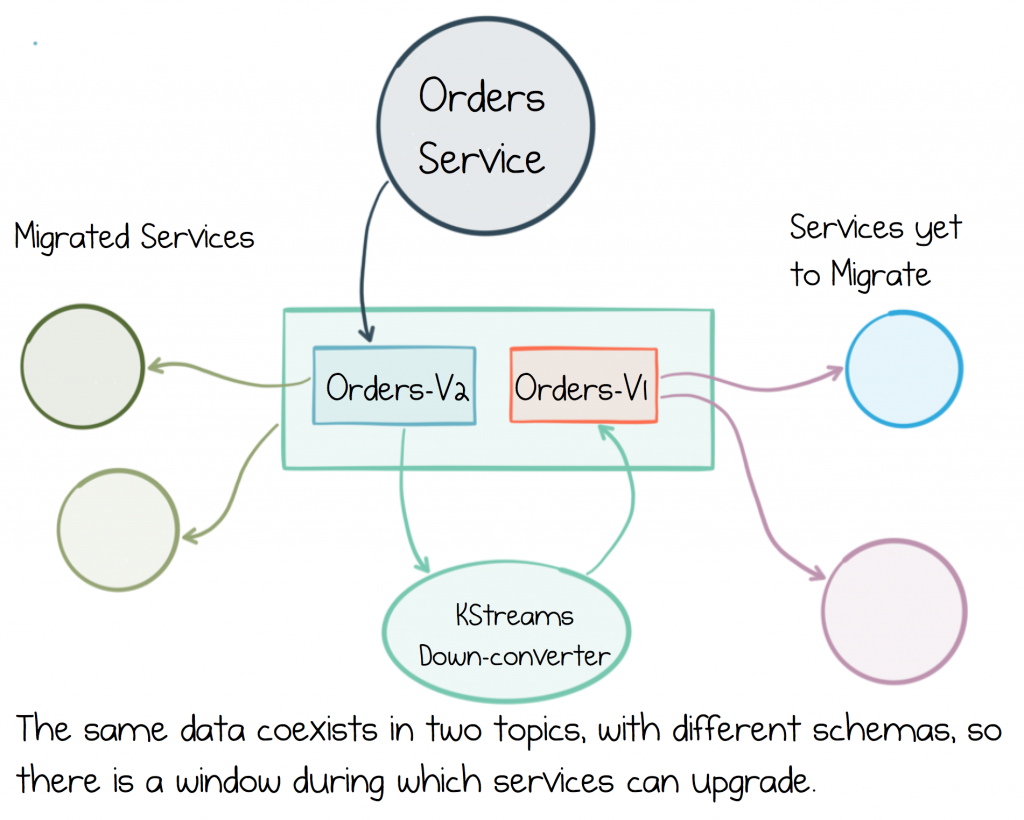
Services continue in this dual-topic mode until all services have fully migrated to the v2 topic, at which point the v1 topic can be archived or deleted as appropriate.
As an aside, in the last post we discussed applying the single writer principle. One of the reasons for doing this is it makes schema upgrades simpler. If we had three different services writing Orders it would be much harder to schedule a non-backward compatible upgrade without a conjoined release.
Chain Services with Exactly-Once Guarantees
One benefit of Kafka is it ships with an exactly once processing feature built in. This makes it very easy to chain together services, without the overhead of implementing idempotence manually. This particular feature is discussed in some detail in the next post.
Prefer Events over Commands or Queries
Kafka is used in a wide range of use cases, but like most technologies it has its sweet spot. It works very well for event-driven systems. However sometimes a request-response style is more appropriate, so what do you do?
Say you need a way for the Orders service to query a stock count from the Stock Service. You can synthesise such a request over any asynchronous channel. This is typically done by creating two topics, a request topic and a response topic.
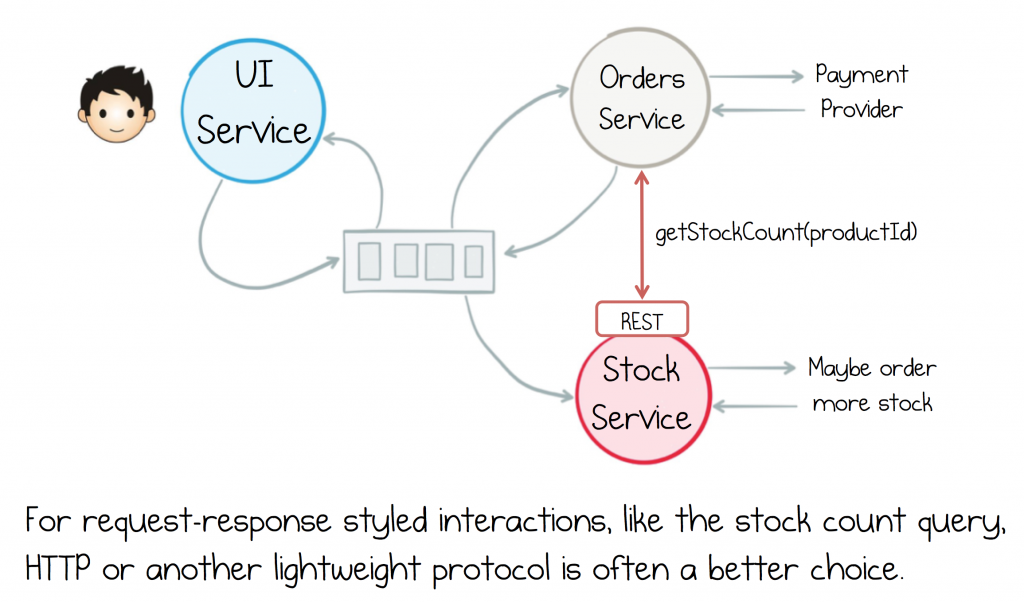
Using Kafka for commands and queries is not uncommon, but it also isn’t its sweet spot. Kafka topics are more heavyweight than, say, HTTP. But you shouldn’t forget that, while HTTP is a lightweight protocol, real implementations need to worry about retries, circuit-breaking, rate-limiting, monitoring etc. (which is where service meshes often come in) but Kafka provides all these features out of the box. So it’s a tradeoff.
If you choose to use commands or queries via Kafka use single partition topics and reduce the segment and retention sizes to keep the overhead low.
Another alternative is to mix in a stateless protocol like HTTP, layered over a backbone of events. For example with a gateway. Alternatively you can open separate interfaces in each service, one for events and another for request response. This is a great pattern, and probably the most commonly used one we see. So Events are created for all state changes and HTTP is used for all request response. See figure below. This pattern makes a lot of sense because events are, after all, the dataset of your system (so Kafka works well). Queries are more like ephemeral chit-chat (so HTTP is perfect). We covered more event-driven design patterns in the last post.
Building a Simple Event-Based System
The most common pattern for smaller service implementations is to mix protocols: Kafka is used for moving data from service to service via event-carried state transfer, triggering services into action or being used as an event store. REST, or some other RPC protocol, is used for queries etc.
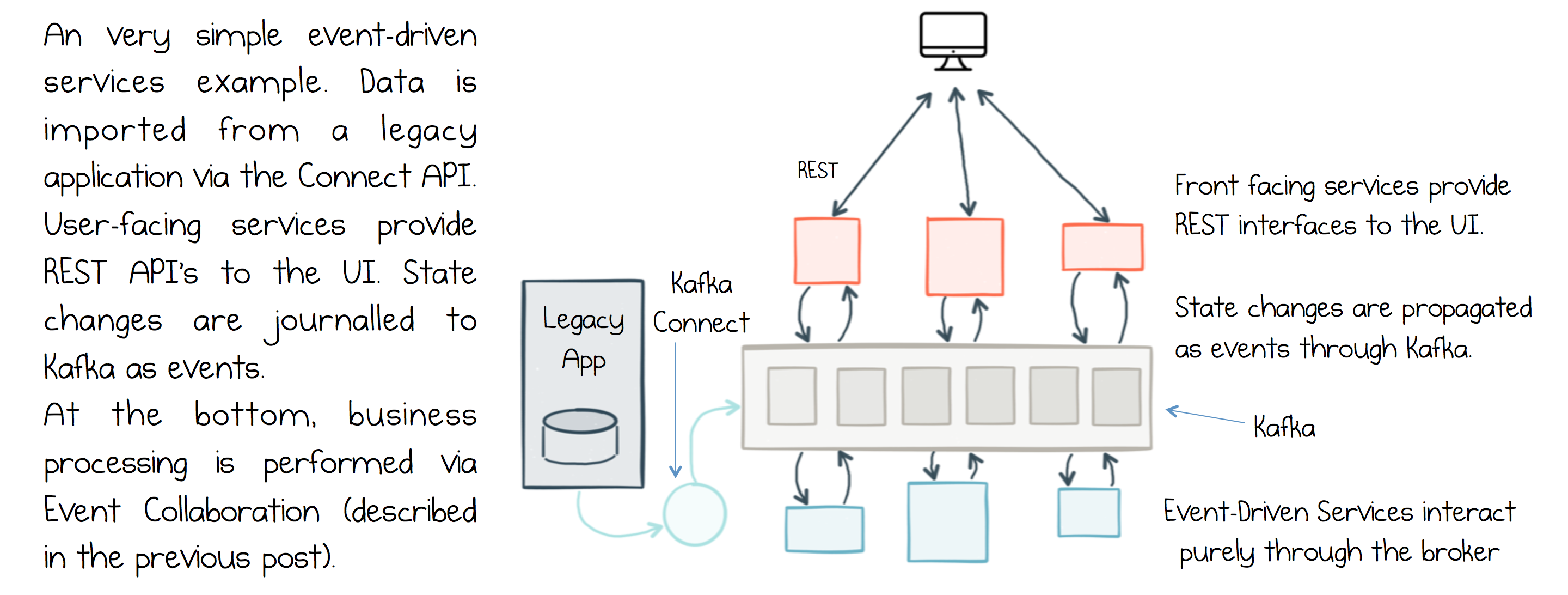
But we should be careful with this pattern as our system grows. For larger, corporate-sized architectures, a pattern like the clustered context model (discussed in the last post) can be a better fit, as it promotes the use of event-carried state transfer while compartmentalizing remote queries. But for smaller service applications, the pattern described above is a simple and effective compromize.
Summing Up
Kafka is a little different from your average messaging technology. Being designed as a distributed, scalable infrastructure component makes it an ideal backbone through which services exchange and buffer events. There are obviously a number of unique elements to the technology itself but the ones that stand out are its ability to scale, its ability to run always on and its ability to retain datasets long term.
We can use the patterns and features discussed in this post to build a wide variety of architectures, from fine-grained service-based systems right up to hulking corporate conglomerates. The approach is safe, pragmatic, and follows a tried and tested path.
In the next post we’ll dig into the one major topic we couldn’t cover here: Kafka’s transactional guarantees. These are something of a game changer for service-based systems. The rest of this series will layer in the other elements of Streaming Platforms. We’ll bring in the Kafka Streams API. A rich, general-purpose interface for joining and processing datasets emitted from different services in real time. It takes a little extra effort, when compared with the simplicity of the pure event-driven approach discussed so far, but it is effort that is almost always worth making.
Posts in this Series:
Part 1: The Data Dichotomy: Rethinking the Way We Treat Data and Services
Part 2: Build Services on a Backbone of Events
Part 3: Using Apache Kafka as a Scalable, Event-Driven Backbone for Service Architectures
Part 4: Chain Services with Exactly Once Guarantees (Read Next)
Part 5: Messaging as the Single Source of Truth
Part 6: Leveraging the Power of a Database Unbundled
Part 7: Building a Microservices Ecosystem with Kafka Streams and KSQL
Confluent Resources:
Apache Kafka® for Microservices: A Confluent Online Talk Series
Microservices for Apache Kafka Whitepaper
Event sourcing, CQRS, stream processing and Apache Kafka: What’s the connection?
Putting Apache Kafka To Use: A Practical Guide to Building a Streaming Platform (Part 1)
Putting Apache Kafka To Use: A Practical Guide to Building a Streaming Platform (Part 2)
Kafka Streams API Landing Page
Other Resources:
“Understanding Message Brokers” by Jakub Korab
“What do you mean by Event Driven” by Martin Fowler
Avez-vous aimé cet article de blog ? Partagez-le !
Abonnez-vous au blog Confluent





