Ahorra un 25 % (o incluso más) en tus costes de Kafka | Acepta el reto del ahorro con Kafka de Confluent
Restoring Balance to the Cluster: Self-Balancing Clusters in Confluent Platform 6.0
Apache Kafka® scales well. A Kafka cluster can grow to tens or hundreds of brokers and easily sustain tens of GB per second of read and write traffic. But scaling Apache Kafka—the operational aspects of growing a cluster and dealing with load changes—is not so easy; the tooling that Apache Kafka comes with handles low-level operations well but leaves data placement decisions up to operators. There have been many third party tools developed to simplify this process, but they involve more software to install, more configurations to manage, more clusters to run, and still usually require operators to notice the cluster imbalance and then run the tools to rebalance. Confluent Platform’s new Self-Balancing Clusters feature, which shipped with Confluent Platform 6.0, handles these operational difficulties by moving them where they belong, into Kafka itself.
Self-Balancing Clusters (SBC) are built to make cluster scaling as automatic and unobtrusive as possible. SBC is built into Kafka, running on the cluster controller node, continuously collecting metrics about the state of the cluster—partition layout and broker load. When the cluster detects a load imbalance or broker overload, Self-Balancing Clusters compute a reassignment plan to adjust the partition layout and execute the plan. Plan execution is carefully monitored and throttled to ensure that the act of moving data to prevent overload doesn’t inadvertently cause it.
You may ask yourself: How did my cluster get here?
Cluster imbalance can arise for all sorts of reasons. Cluster load tends to grow, and a growing cluster will hit the limits of its existing brokers and need more capacity, leading you to add brokers. While Apache Kafka will happily place new topics and partitions on a new broker, it won’t move existing ones. Or maybe it’s time to upgrade the physical brokers, decommissioning the old machines with a rolling upgrade onto new ones, with no downtime. Maybe the traffic on a cluster has (gasp!) gone down and you don’t need quite as many brokers as you once did. Or there’s just the natural lifespan of topics: New topics are created, old ones go fallow, traffic on existing topics rises and falls—and the initial partition placement doesn’t match how traffic is flowing now. Self-Balancing Clusters can deal with all of these situations.
If your cluster needs to grow, just start up the new broker(s). As soon as an empty broker joins the cluster, SBC will detect it and start the process of migrating data onto the new broker. Add one or several brokers—Self-Balancing Clusters will detect them and make sure the cluster’s existing load is balanced onto the new brokers, no action required on your part.
If old brokers need to go away, either for a full decommission or just a replacement, tell SBC and it’s taken care of. Using either Confluent Control Center or the new kafka-remove-brokers command, SBC will shut down Kafka on the old broker and ensure that all replicas on that broker are migrated away. (Note that broker removals take priority over additions and will override them.)
Sometimes the brokers take the decision out of your hands and fail on their own—usually at 3:00 a.m. Don’t worry about the early-morning page, though; if you’ve set confluent.balancer.heal.broker.failure.threshold.ms (it defaults to one hour), Self-Balancing Clusters detect the broker failure and, after that threshold timeout, automatically migrate replicated partitions off the failed broker. You can stroll in the next morning and replace the failed machine at your leisure, rather than hoping more machines won’t fail.
And of course, load changes. Because load changes are unpredictable, and rebalances do consume resources that are shared with your cluster’s traffic (network and disk bandwidth or broker CPU), balancing on uneven load is not enabled by default. You should make this decision based on your cluster’s load and your cluster’s needs. If confluent.balancer.heal.uneven.load.trigger is set to ANY_UNEVEN_LOAD, when some of the metrics that SBC monitors are out of balance, then a rebalance is triggered and load is migrated.
To understand these operations better, let’s talk about “cluster balance.” Cluster balance is…complicated.
So, what is balance?
For Self-Balancing Clusters, cluster balance is measured on several different dimensions; there isn’t a single, simple metric to identify a balanced cluster—although an unbalanced cluster is usually easy to spot. SBC monitors a set of the same metrics that you are probably already watching:
- Replica counts: Every partition replica on a broker consumes internal resources (OS file handles or replica fetchers for follower replicas), and because replica counts change infrequently, keeping this fixed cost relatively consistent across brokers is important. But the traffic coming into different partitions can vary widely, so just balancing replica counts can result in a cluster that is unbalanced in other ways.
- Leader counts: Partition leadership puts extra resource demands on a broker, as the partition leader is responsible for handling all writes to the partition and all management of the in-sync replicas set. Just as with overall replica counts, it’s important to balance leadership across all brokers but not pay too much attention to just the counts.
- Disk usage: The disk space consumed by a single partition is the summation of all the partition’s traffic for the duration of the topic’s retention period—it changes slowly and the effects linger. Because disk usage is a direct reflection of network activity, balancing disk usage also balances steady-state network usage. While exceeding a broker’s disk capacity is clearly bad, short-term traffic changes will disappear within the retention period. Tiered Storage in Confluent Platform reduces the impact of disk usage, but partitions with large hotsets are still applying extra load to brokers and need to be balanced out.
- Network usage: Network usage is directly related to client traffic and can change frequently. Also, once a network traffic surge is over, it’s over—there is no lingering effect on the cluster (well, except for the disk space usage, but we already considered that). Making sure that the network usage stays within broker capacity is clearly important, but because the impacts are short lived, network usage balancing should be lower priority than disk usage or replica counts.
Self-Balancing Clusters don’t just consider metric equality. A reassignment that balances network load and makes the cluster less fault tolerant or one that overloads a broker is clearly a bad reassignment. If broker rack awareness is enabled, Self-Balancing Clusters ensure that partitions are spread across racks and that no reassignment ever violates this property. If a cluster uses replica placement guidelines to build stretch clusters and limit network replication costs, Self-Balancing Clusters honor those as well and automatically take care of the necessary reassignments whenever the constraints change. Operators can also define capacity limits for brokers in terms of maximum disk usage, network usage, and replica counts.
Self-Balancing Clusters adjudicate among the various dimensions by:
- Enforcing data placement constraints (rack awareness and replica placement)
- Enforcing defined capacity limits (network bandwidth, disk usage, and replica counts)
- Balancing low-frequency-change metrics (disk usage, replica, and leader counts)
- Balancing high-frequency change metrics (network usage)
Because of these competing priorities, a “balanced” cluster might not look so balanced based on one graph or one moment in time, as seen in the example below where three brokers get added to a large cluster. Replica counts and disk usage normalize across the cluster, while network utilization is still not completely consistent across the cluster.
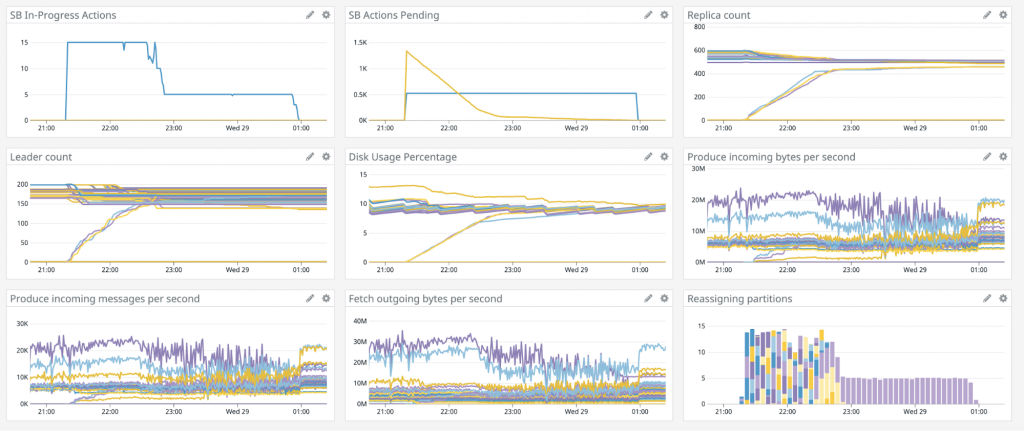
No free lunch
Balancing the cluster requires resources as partitions are moved. SBC controls resource usage by limiting the amount of bandwidth that can be used for reassignment traffic and the number of partitions that can be reassigned into or out of a broker at any one time. By default, any given broker is constrained to 10 MB/sec of reassignment bandwidth—a value that’s easily adjustable with the confluent.balancer.throttle.bytes.per.second property. (It’s too high if there are under-replicated partitions during reassignment and too low if rebalancing takes too long.) Using Tiered Storage will also help here, as it reduces the amount of data that actually needs to be moved between brokers. The lowest-impact data movement is data that doesn’t need to be moved.
But it’s not just reassignment that has a cost; the act of measuring the cluster and deciding if it’s in or out of balance consumes resources as well. Metrics are continuously gathered and stored, and Self Balancing Clusters are regularly weighing how much load any given partition applies to a particular broker. Computing a rebalance plan in a large cluster with thousands of partitions is computationally intense…isn’t it?
Fortunately, it turns out that neither metric collection nor plan computation concerns are a real issue. Reassignment plans, even on clusters with tens of thousands of partitions and tens of brokers, usually compute in seconds. Metric collection and analysis has been tuned to use less than 6% of CPU even on large clusters. There ain’t no such thing as a free lunch, but with Self-Balancing Clusters, you might get pretty close.
Making it safe
Since rebalancing cluster load involves moving data around the cluster, it’s essential that Self-Balancing Clusters always take great care to protect that data. Kafka’s rigorous testing culture has enabled Confluent to deliver a high-quality feature. We started SBC by building upon Kafka’s existing, production-validated metrics and partition reassignment mechanisms to monitor the cluster and move data. If you already use dashboards and kafka-reassign-partitions, you are doing exactly what SBC does (just not as tirelessly).
After the design comes testing. Every build of Confluent Platform runs hundreds of unit and integration tests to validate SBC’s operation and reassignment plan generation. Nightly runs of our system test framework do full end-to-end validation of rebalancing scenarios on real Kafka clusters. We’ve validated SBC’s performance and scaling abilities both by building intense, highly variable synthetic workloads that induce frequent load changes, as well as by talking to some of our customers to identify their usage patterns.
Multiple aspects of SBC’s configuration are dynamic, which enables rapid adjustments without having to edit configuration files and rolling the cluster. You can enable and disable both automatic load rebalancing and Self-Balancing Clusters dynamically should the need arise. Disabling Self-Balancing Clusters will automatically cancel any ongoing reassignments.
Conclusion
Self-Balancing Cluster’s management tools enable dynamic and elastic Confluent Platform deployments, letting you scale your clusters in response to changing loads rather than always planning for the worst case. The automatic monitoring and load balancing features of SBC mean that you don’t have to constantly monitor and compute adjustments for your clusters due to dynamic changes. With Self-Balancing Clusters, you can focus on having your Confluent Platform capacity be exactly what you need.
Want to learn more?
- See the Confluent Platform documentation on Self-Balancing Clusters
- Try the Docker demo (hosted on demo-scene) or the hands-on tutorial showcasing Self-Balancing Clusters
Many thanks to Gwen Shapira, Victoria Bialas, Stanislav Kozlovski, Vikas Singh, Bob Barrett, Aishwarya Gune, David Mao, and Javier Redondo for their advice and feedback on this post, and to the SBC engineers for helping build a feature that was so easy to write about. Thank you for reading this, and enjoy Self-Balancing Clusters!
¿Te ha gustado esta publicación? Compártela ahora
Suscríbete al blog de Confluent



Customer Intelligence Hub: A Single Pane of Glass for Customer Insight and Action
Customer Intelligence Hub unifies customer signals into a real-time, AI-powered view that helps GTM teams prioritize risk, identify opportunity, and act faster with contextual insights.